hadoop完全分布式部署
1.我们先看看一台节点的hdfs的信息:(已经安装了hadoop的虚拟机:安装hadoophttps://www.cnblogs.com/lyx666/p/12335360.html)
start-dfs 打开hdfs需要启动的服务

然后再浏览器输入http://虚拟机ip地址:50070

问下滑: 可以看到以下相关信息
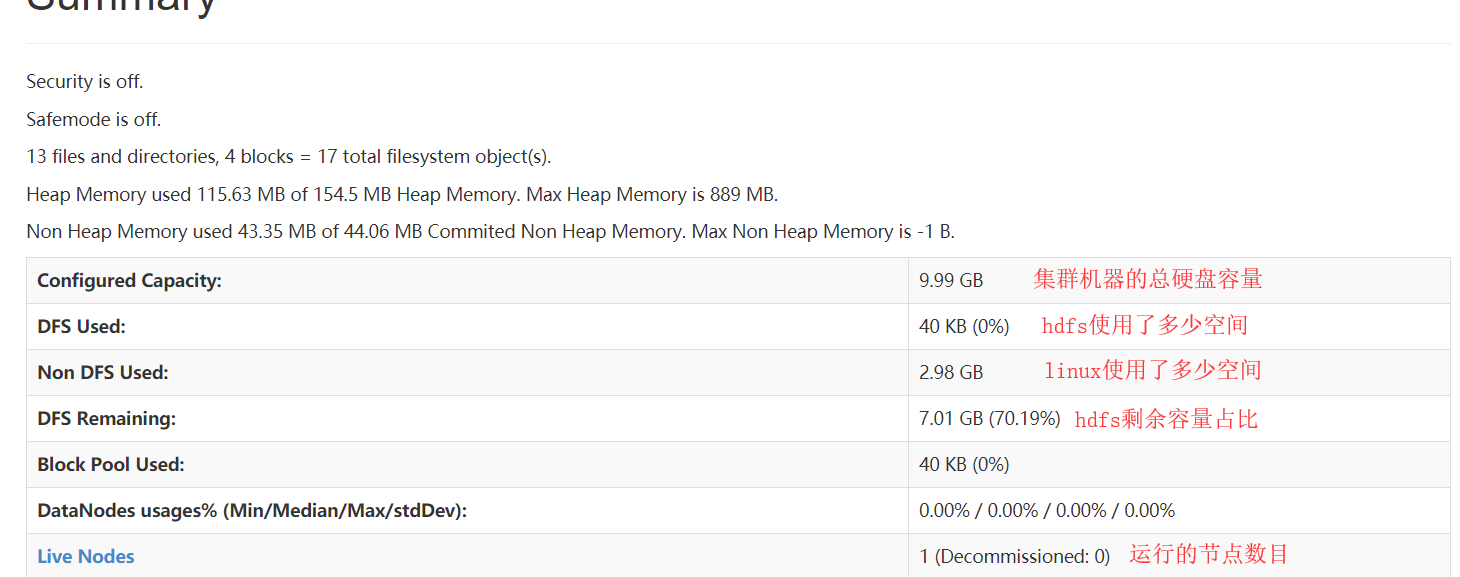
可以看到集群总容量大概为10G,而该集群只有一台机器,所以集群容量=该机器容量,可以看看这台虚拟机的硬盘是不是10G.
df -h / #确实是10G

2.接下来就要扩容该集群的容量,将这台虚拟机克隆(克隆步骤省略)
3.克隆机需要先配置以下
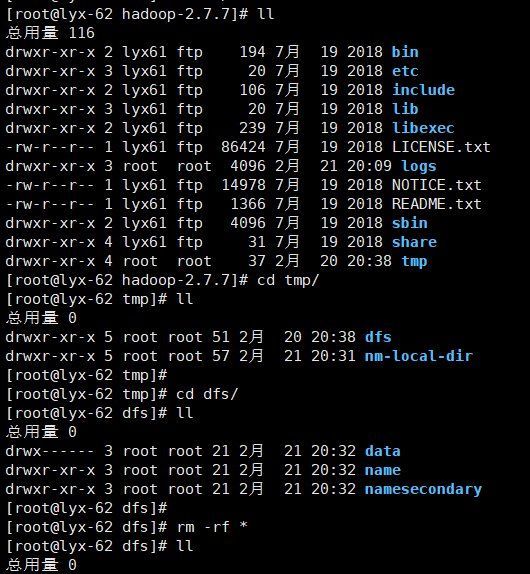
把克隆的dfs文件夹清空
将该文件夹下的数据清空:rm -rf *
网络ip:

BOOTPROTO=static 原本为DHCP
ONBOOT=yes 原本为no
IPADDR=192.168.43.62 ip地址 在网段里就行
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.43.1 网关 需要查看主机的ipv4地址配置
DNS1=8.8.8.8 谷歌的dns解析

改完后重启网络:systemctl restart network
修改主机名
我这里是已经修改好了的,你们原本应该是localhost的主机名,我修改成lyx-62

修改后记得重启这台虚拟机:reboot
配置ip和主机名映射 还需要加上被克隆的虚拟机的ip和主机映射 【注意:这里两台都要添加修改】


修改后记得重启这两台虚拟机:reboot
配置ssh免密通信
(lyx-62)ssh-keygen #创建密钥对#
(lyx-62)ssh-copy-id lyx-62 #将公钥复制到lyx-62 也就是本机
注意这里另一台也需要(lyx-61):ssh-copy-id lyx-62 这样两台就能免密通信
修改hdfs-site.xfs配置文件 副本数修改为3【注意两台机器都需要修改】
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
将克隆机主机名添加到slaves配置文件中 也就是加入到集群中 这里修改的是【被克隆的】slaves.xml文件

3.只启动被克隆的hdfs需要的服务
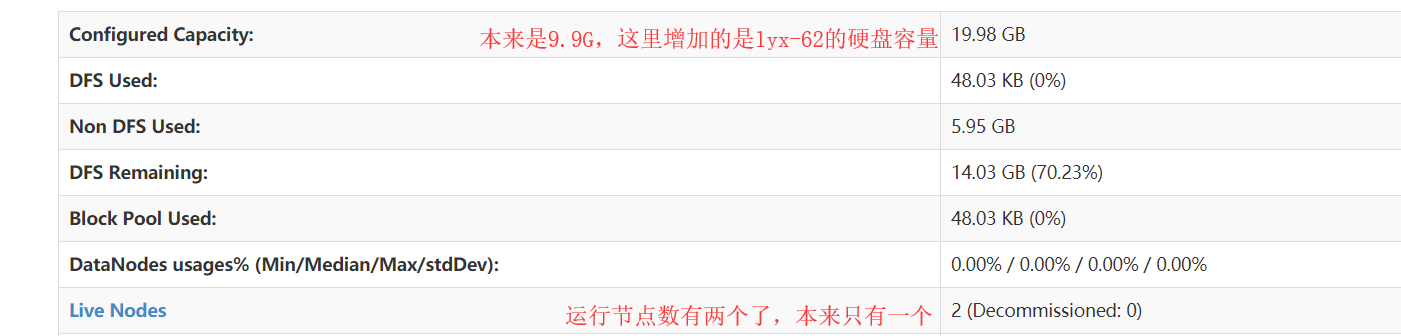
start-dfs.sh #可以看到lyx-62启动了datanode服务,说明它已经加入到这个集群了 所以它的硬盘也被加入到集群了

接下来我们在回过头来看看集群信息 可以发现硬盘容量增加了,说明lyx-62这台也被加入到集群了。
hadoop完全分布式部署的更多相关文章
- ubuntu下hadoop完全分布式部署
三台机器分别命名为: hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27 ...
- Hadoop 完全分布式部署
完全分布式部署Hadoop 分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4)安装hadoop 5)配置环境变量 6)安装ssh 7)集群时间同步 7 ...
- Hadoop 完全分布式部署(三节点)
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群.其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因 ...
- Hadoop伪分布式部署
一.Hadoop组件依赖关系: 步骤 1)关闭防火墙和禁用SELinux 切换到root用户 关闭防火墙:service iptables stop Linux下开启/关闭防火墙的两种方法 1.永久性 ...
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop+HBase分布式部署
test 版本选择
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Apache Hadoop 2.9.2 完全分布式部署
Apache Hadoop 2.9.2 完全分布式部署(HDFS) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.操作平台 [root@node101.y ...
随机推荐
- test api formdata
- Linux网络文件共享服务之NFS
一.NFS服务简介 NFS全称network file system 网络文件系统,基于内核的文件系统,有sun公司开发,通过使用NFS,用户和程序可以像访问本地文件一样访问远端系统上的文件,它基于r ...
- 前端 network
控制台 :https://blog.csdn.net/m0_37724356/article/details/79884006 原文链接:https://segmentfault.com/a/1190 ...
- SpringCloud与微服务Ⅶ --- Feign负载均衡
官方文档:https://projects.spring.io/spring-cloud/spring-cloud.html#spring-cloud-feign 一.Feign是什么 Feign是一 ...
- 导出表格数据到excel并下载(HSSFWorkbook版)
这里主要前面是通过一个全局变量,在layui的done回调里拿到数据,然后将该数据导出到excel,这里要注意一点,下载excel不能用ajax方式,如果采用ajax下载默认会读取response返回 ...
- python3中的继承和多态
*继承 当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类.父类或超类(Base class.Super clas ...
- 十五 awk文本处理
Awk 语法和基础命令 以行为处理单位 对数据进行逐行处理 处理完当前行,把当前行的处理结果输出后自动对下一行进行处理 直到文件中所有行处理完为止 创造者:Aho.Weinberger.Kernigh ...
- Android Webview实现有道电子词典
毕业设计android电子词典,先实现的一个小小的demo. 所谓的毕业设计就是用最短的时间学习一门语言,做出一个小的project. activity_main.xml <LinearLayo ...
- windows 使用ssh连接docker容器
在Windows上搭建docker服务器需要在Windows模拟一个Linux平台,然后在Linux平台上搭建的docker服务器,所以在使用ssh工具连接docker容器的时候,使用的ip地址不是d ...
- pandas 使用总结
import pandas as pd import numpy as np ## 从字典初始化df ipl_data = {'Team': ['Riders', 'Riders', 'Devils' ...