VPGAME的Kubernetes迁移实践
VPGAME 是集赛事运营、媒体资讯、大数据分析、玩家社群、游戏周边等为一体的综合电竞服务平台。总部位于中国杭州,在上海和美国西雅图分别设立了电竞大数据研发中心和 AI 研发中心。本文将讲述 VPGAME 将服务器迁移至 Kubernetes 的过程。
背景
随着容器技术的日趋成熟,公司近期计划将服务迁移至容器环境,通过 Kubernetes 对容器进行调度、编排和管理。并借此机会,对服务进行标准化,优化整个 CI/CD 的流程,提高服务部署的效率。
CI/CD 工具的选择
CI/CD 工具上,我们选择了 GitLab-CI。GitLab-CI 就是一套配合 GitLab 使用的持续集成系统,以完成代码提交之后的安装依赖、编译、单元测试、lint、镜像构建以及发布等工作。
GitLab-CI 完美地和 GitLab 进行集成,在使用的时候只需要安装配置 gitlab-runner 即可。GitLab-Runner 在向 GitLab 完成注册后可以提供进行 CI/CD 操作的环境,负责从 GitLab 中拉取代码,根据代码仓库中配置的 gitlab-ci.yml ,执行相应的命令进行 CI/CD 工作。
相比于 Jenkins,GitLab-CI 配置简单,只需在工程中配置 gitlab-ci.yml 文件完成 CI/CD 流程的编写,不需要像在 Jenkins 里一样配置 webhook 回调地址,也不需要 Jenkins 新建这个项目的编译配置。并且个人认为 GitLab 的 CI/CD 过程显示比 Jenkins 更加美观。当然 Jenkins 依靠它丰富的插件,可以配置很多 GitLab-CI 不存在的功能。按照现在我们的需求, GitLab-CI 简单易用,在功能也满足我们的需求。
服务运行环境
容器环境优点
传统的服务部署方式是在操作系统中安装好相应的应用依赖,然后进行应用服务的安装,这种部署方式的缺点是将服务的程序、配置、依赖库以及生命周期与宿主机操作系统紧密地耦合在一起,对服务的升级、扩缩容、迁移等操作不是十分便利。
容器的部署方式则是以镜像为核心,在代码进行编译构建时,将应用程序与应用程序运行所需要的依赖打包成一个镜像,在部署阶段,通过镜像创建容器实例完成服务的部署和运行。从而实现以应用为中心的管理,容器的隔离性实现了资源的隔离,由于容器不需要依赖宿主机的操作系统环境,所以可以很好地保证开发、测试和生产环境的一致性。此外,由于构建好的镜像是不可变的,并且可以通过 tag 进行版本控制,所以可以提供可靠、频繁的容器镜像构建和部署,亦可方便及快速进行回滚操作。
Kubernetes 平台功能
Kubernetes(简称 k8s),作为一个容器调度、编排和管理平台,可以在物理或虚拟机集群上调度和运行应用程序容器,提供了一个以容器为核心的基础架构。通过 Kubernetes,对容器进行编排和管理,可以:
- 快速、可预测地部署服务
- 拥有即时扩展服务的能力
- 滚动升级,完成新功能发布
- 优化硬件资源,降低成本
阿里云容器服务优势
我们在服务迁移中选用了阿里云的容器服务,它基于原生 Kubernetes 进行适配和增强,简化集群的搭建和扩容等工作,整合阿里云虚拟化、存储、网络和安全能力,打造云端最佳的 Kubernetes 容器化应用运行环境。在便捷性上,可以通过 Web 界面一键完成 Kubernetes 集群的创建、升级以及节点的扩缩容。功能上,在网络、存储、负载均衡和监控方面与阿里云资源集成,在迁移过程中可以最小化减少迁移带来的影响。
此外,在选择集群创建时,我们选择了托管版 Kubernetes,只需创建 Worker 节点,Master 节点由容器服务创建并托管。如此一来,我们在 Worker 节点的规划与资源隔离上还是具备自主性和灵活性的同时不需要运维管理 Kubernetes 集群 Master 节点,可以将更多的精力关注在应用服务上。
GitLab Runner 部署
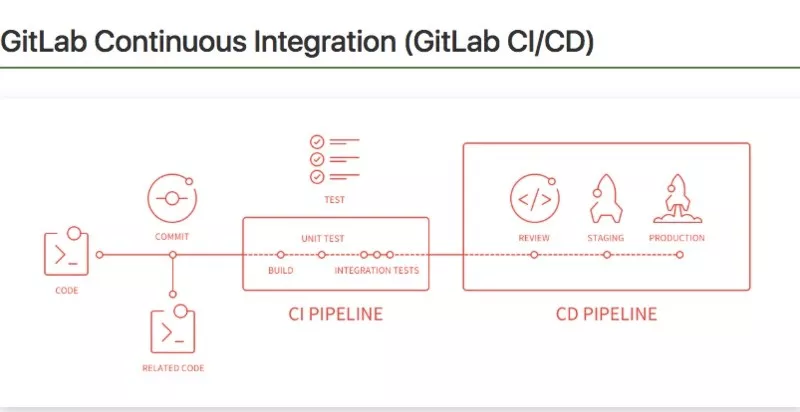
GitLab CI 工作流程
GitLab CI 基本概念
在介绍 GitLab CI 之前,首先简单介绍一下 GitLab CI 里的一些基本概念,具体如下:
- Pipeline:Gitlab CI 里的流水线,每一次代码的提交触发 GitLab CI 都会产生一个 Pipeline。
- Stage:每个 Pipeline 由多个 Stage 组成,并且每个 Stage 是有先后顺序的。
- Job:GitLab CI 里的最小任务单元,负责完成具有一件事情,例如编译、测试、构建镜像等。每个 Job 都需要指定 Stage ,所以 Job 的执行顺序可以通过制定不同的 Stage 来实现。
- GitLab Runner:是具体执行 Job 的环境,每个 Runner 在同一时间只能执行一个 Job。
- Executor:每个 Runner 在向 GitLab 注册的时候需要指定 Executor,来决定通过何种类型的执行器来完成 Job。
GitLab CI 的工作流程
当有代码 push 到 GitLab 时,就会触发一个 Pipeline。然后进行编译,测试和镜像构建等操作等操作,其中每一步操作都为一个 Job。在 CD 阶段,会将 CI 阶段构建出来的结果根据情况部署到测试环境或生产环境。
GitLab Runner 介绍
Gitlab Runner 分类
GitLab 中有三种类型的 Runner ,分别为:
- shared:所有项目使用
- group:group下项目使用
- specific:指定项目使用
我们可以根据需要向 GitLab 注册不同类型的 Runner,注册的方式是相同的。
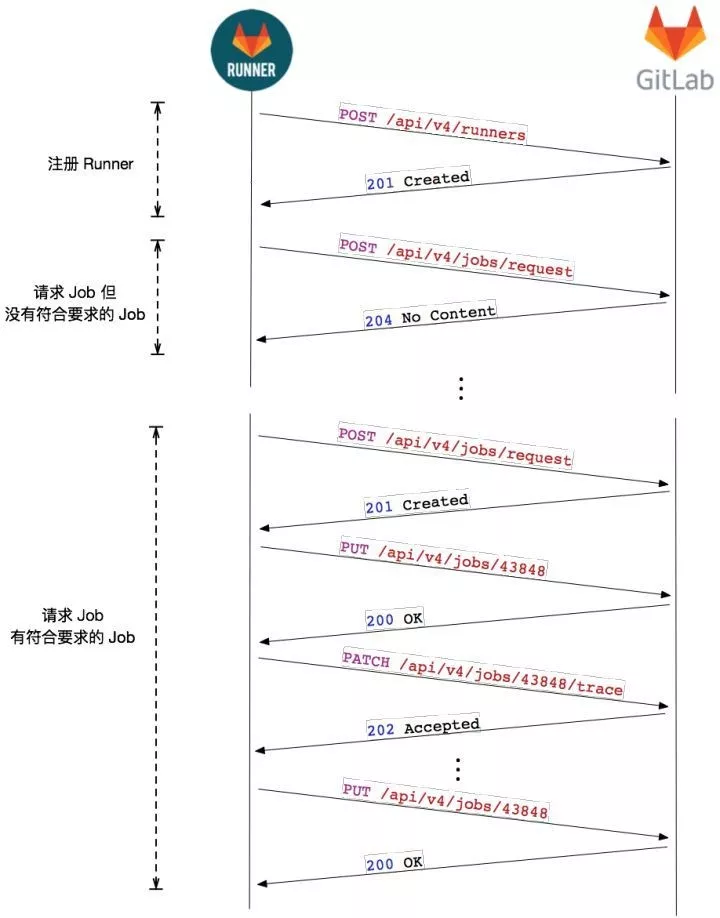
Gitlab Runner 工作过程
Runner 首先会向 GitLab 发起注册请求,请求内容中包含 token、tag 等信息,注册成功后 GitLab 会向 Runner 返回一个 token,后续的请求,Runner 都会携带这个请求。
注册成功后,Runner 就会不停的向 GitLab 请求 Job,时间间隔是 3s。若没有请求到 Job,GitLab 返回 204 No Content。如果请求到 Job,GitLab 会把 Job 信息返回回来,Runner 在接收到 Job 之后,会向 GitLab 发送一个确认请求,同时更新任务的状态。之后,Runner 开始 Job 的执行, 并且会定时地将中间数据,以 Patch 请求的方式发送给 GitLab。
GitLab Runner 的 Executor
Runner 在实际执行 Job 时,是通过调用 Executor 来完成的。Runner 在注册时提供了 SSH、Shell、Docker、docker-ssh、VirtualBox、Kubernetes 等不同类型的 Executor 来满足不同的场景和需求。
其中我们常用的有 Shell 和 Docker 等 Executor,Shell 类型主要是利用 Runner 所在主机的环境进行 Job的执行。而 Docker 类型的 Executor 在每个 Job 开始时,拉取镜像生产一个容器,在容器里完成 Job,在 Job 完成后,对应的容器就会被销毁。由于 Docker 隔离性强、轻量且回收,我们在使用时选用 Docker 类型的 Executor 去执行 Job,我们只要提前做好 Job 所需环境的 Docker 镜像,在每个 Job 定义好 image 即可使用对应的环境,操作便捷。
GitLab Runner 安装与配置
Docker 安装
由于我们需要使用 Docker 类型的 Executor,所以需要在运行 Runnner 的服务器上先安装 Docker,具体步骤如下(CentOS 环境):
安装需要的软件包,yum-util 提供 yum-config-manager 功能,另外两个是 DeviceMapper 驱动依赖:
yum install -y yum-utils device-mapper-persistent-data lvm2
设置 yum 源:
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装 Docker:
yum install docker-ce -y
启动并加入开机启动:
systemctl start dockersystemctl enable docker
Gitlab runner 安装与启动
执行下面的命令进行 GitLab Runner 的安装和启动:
`curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh | sudo bash
sudo yum install gitlab-runner -y
gitlab-runner start`
GitLab Runner 注册与配置更新
启动 GitLab Runner 后还需要向 GitLab 进行注册,在注册前需要从 GitLab 里查询 token。不同类型的 Runner 对应的 token 获取的路径不同。shared Runner 需要 admin 权限的账号,按如下方式可以获取对应的 token。
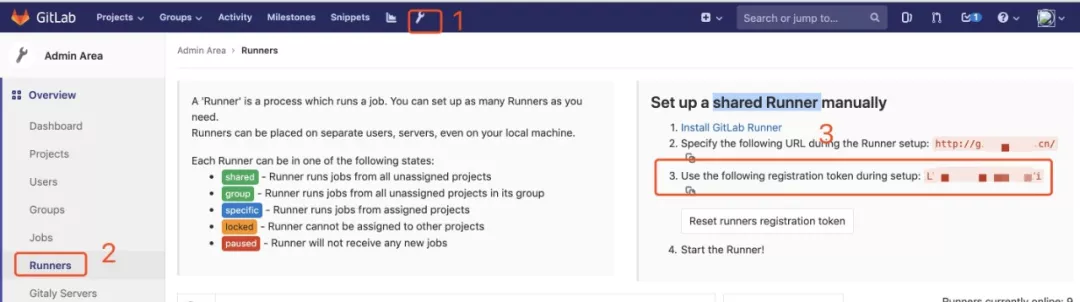
其他两种类型在对应的页面下( group 或 project 主页)的 setting—>CI/CD—>Runner 可以获取到 token。
Runner 的注册方式分为交互式和非交互式两种。其中交互式注册方式,在输入 gitlab-runner register 命令后,按照提示输入注册所需要的信息,包括 gitlab url、token 和 Runner 名字等。这边个人比较推荐非交互式命令,可以事先准备好命令,完成一键注册,并且非交互式注册方式提供了更多的注册选项,可以满足更多样化的需求。
按如下示例即可完成一个 Runner 的注册:
gitlab-runner register --non-interactive \--url "http://git.xxxx.cn" \--registration-token "xxxxxxxxxxx" \--executor "docker" \--docker-image alpine:latest \--description "base-runner-docker" \--tag-list "base-runner" \--run-untagged="true" \--docker-privileged="true" \--docker-pull-policy "if-not-present" \--docker-volumes /etc/docker/daemon.json:/etc/docker/daemon.json \--docker-volumes /etc/gitlab-runner/key/docker-config.json:/root/.docker/config.json \--docker-volumes /etc/gitlab-runner/find_diff_files:/usr/bin/find_diff_files \--docker-volumes /etc/gitlab-runner/key/id_rsa:/root/.ssh/id_rsa \--docker-volumes /etc/gitlab-runner/key/test-kube-config:/root/.kube/config
我们可以通过 --docker-pull-policy 指定 Executor 执行 Job 时 Dokcer 镜像下载策略。--docker-volumes 指定容器与宿主机(即 Runner 运行的服务器)的文件挂载映射关系。上面挂载的文件主要是用于 Runner 在执行 Job 时,运用的一些 key,包括访问 GitLab、Docker Harbor 和 Kubernetes 集群的 key。当然,如果还有其他文件需要共享给容器,可以通过 --docker-volumes 去指定。
/etc/docker/daemon.json 文件主要为了可以以 http 方式访问 docker horbor 所做的设置:
{ "insecure-registries" : ["http://docker.vpgame.cn"] }
完成注册后,重启 Runner 即可:
gitlab-runner restart
部署完成后,可以在 GitLab 的 Web 管理界面查看到不同 Runner 的信息。
此外,如果一台服务需要注册多个 Runner ,可以修改 /etc/gitlab-runner/config.toml 中的 concurrent 值增加 Runner 的并发数,修改完之后同样需要重启 Runner。
Docker 基础镜像制作
为了满足不同服务对运行环境的多样化需求,我们需要为不同语言的服务提前准备不同的基础镜像用于构建镜像阶段使用。此外,CI/CD 所需要的工具镜像也需要制作,作为 Runner 执行 Job 时生成容器所需要的 Docker 镜像。
所有的镜像都以编写 Dockerfile 的形式通过 GitLab 进行管理,并且我们编写了 .gitlab-ci.yml 文件,使得每次有 Dockerfile 新增或者修改就会触发 Pipeline 进行镜像的构建并上传到 Harbor 上。这种管理方式有以下优点:
- 按照一定规则自动构建镜像,可以快速便捷地新建和更新镜像
- 根据规则可以找到镜像对应的 Dockerfile,明确镜像的具体组成
- 团队成员可以通过提交 Merge Request 自由地构建自己需要的镜像
镜像分类
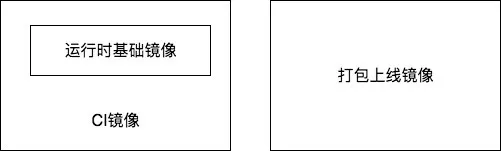
- 运行时基础镜像:提供各个语言运行时必须的工具和相应的 package。
- CI 镜像:基于运行时基础镜像,添加单元测试、lint、静态分析等功能,用在 CI/CD 流程中的 test 环节。
- 打包上线镜像:用在 CI/CD 流程中的 build 和 deploy 环节。
Dockerfile目录结构
每个文件夹都有 Dockerfile 来描述镜像的基本情况,其中包含了 Java、PHP、Node 和 Go 等不同语言的运行时基础镜像和 CI 镜像,还有 docker-kubectl 这类工具镜像的 Dockerfile。
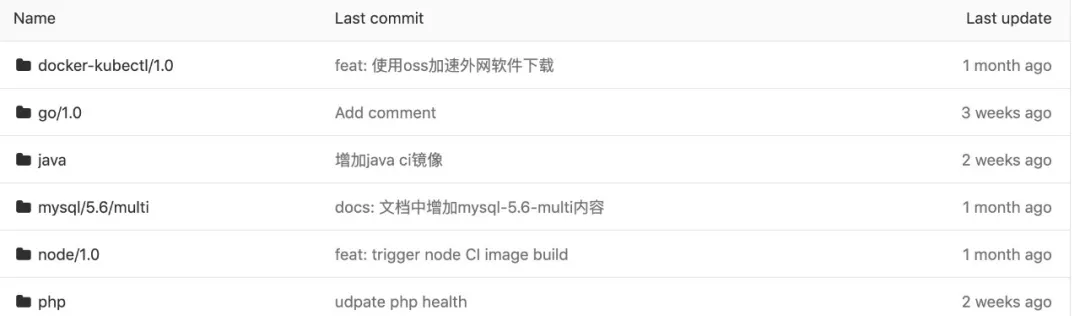
以 PHP 镜像为例:
php/├── 1.0│ ├── Dockerfile│ ├── ci-1.0│ │ └── Dockerfile│ ├── php.ini│ ├── read-zk-config│ ├── start_service.sh│ └── www.conf└── nginx├── Dockerfile├── api.vpgame.com.conf└── nginx.conf

该目录下有一个名为 1.0 的文件夹,里面有一个 Dockerfile 用来构建 php fpm 运行时基础进行镜像。主要是在 php:7.1.16-fpm-alpine3.4 加了我们自己定制化的文件,并指定工作目录和容器初始命令。
FROM php:7.1.16-fpm-alpine3.4RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories\&& apk upgrade --update && apk add --no-cache --virtual build-dependencies $PHPIZE_DEPS \tzdata postgresql-dev libxml2-dev libmcrypt libmcrypt-dev libmemcached-dev cyrus-sasl-dev autoconf \&& apk add --no-cache freetype libpng libjpeg-turbo freetype-dev libpng-dev libjpeg-turbo-dev libmemcached-dev \&& cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \&& echo "Asia/Shanghai" > /etc/timezone \&& docker-php-ext-configure gd \--with-gd \--with-freetype-dir=/usr/include/ \--with-png-dir=/usr/include/ \--with-jpeg-dir=/usr/include/ \&& docker-php-ext-install gd pdo pdo_mysql bcmath opcache \&& pecl install memcached apcu redis \&& docker-php-ext-enable memcached apcu redis \&& apk del build-dependencies \&& apk del tzdata \&& rm -rf /var/cache/apk/* \&& rm -rf /tmp/* \&& rm -rf /working/* \&& rm -rf /usr/local/etc/php-fpm.d/*COPY start_service.sh /usr/local/bin/start_service.shCOPY read-zk-config /usr/local/bin/read-zk-configCOPY php.ini /usr/local/etc/php/php.iniCOPY www.conf /usr/local/etc/php-fpm.d/www.confWORKDIR /workCMD ["start_service.sh"]
在 1.0/ci-1.0 还有一个 Dockerfile,是用来构建 PHP 在进行单元测试和 lint 操作时所使用的 CI 镜像。可以看到它基于上面的基础运行时镜像增加其他工具来进行构建的。
FROM docker.vpgame.cn/infra/php-1.0ENV PATH="/root/.composer/vendor/bin:${PATH}"ENV COMPOSER_ALLOW_SUPERUSER=1RUN mkdir -p /etc/ssh && echo "StrictHostKeyChecking no" >> /etc/ssh/ssh_configRUN apk --update add --no-cache make libc-dev autoconf gcc openssh-client git bash &&\echo "apc.enable_cli=1" >> /usr/local/etc/php/conf.d/docker-php-ext-apcu.iniRUN pecl install xdebug && docker-php-ext-enable xdebug &&\echo -e "\nzend_extension=xdebug.so" >> /usr/local/etc/php/php.iniRUN wget https://vp-infra.oss-cn-beijing.aliyuncs.com/gitlab-ci/software/download/1.6.5/composer.phar -O /bin/composer && \chmod +x /bin/composer && \composer config -g -q repo.packagist composer https://packagist.laravel-china.orgRUN composer global require -q phpunit/phpunit:~5.0 squizlabs/php_codesniffer:~3.0WORKDIR /CMD ["/bin/bash"]
另外 Nginx 目录下同样有 Dockerfile,来定制化我们 PHP 项目所需要的 Nginx 镜像。
在 GitLab 里第一次增加新的 Dockerfile 或者更改 Dockerfile 时,会触动 Pipeline 自动进行镜像的构建并上传的我们私有的 Docker Harbor 上。
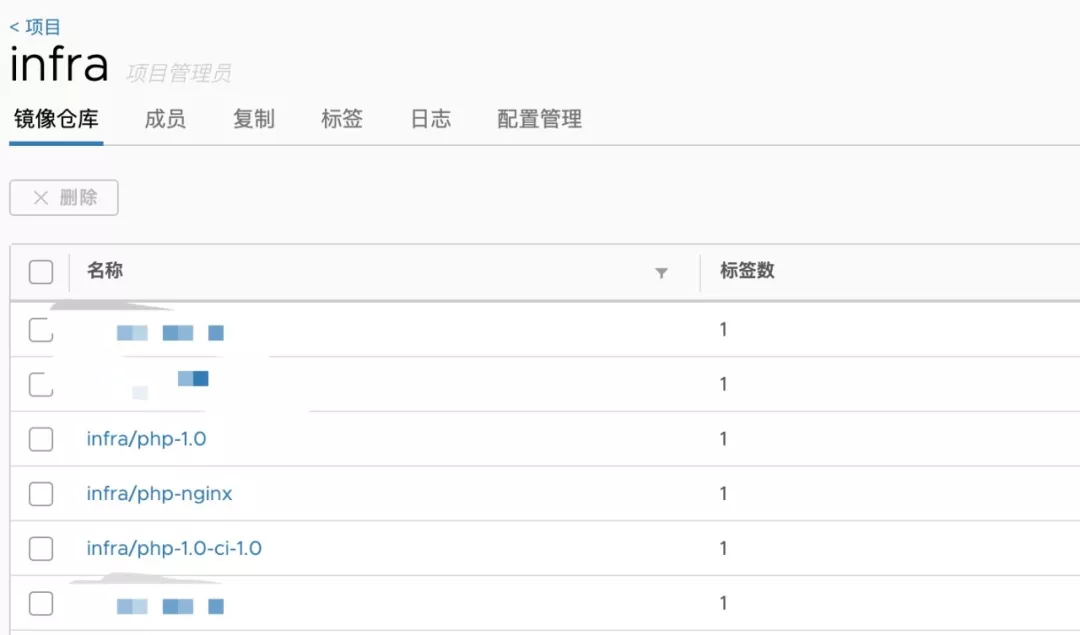
镜像自动构建基本原理
由于各个镜像通过 Dockerfile 进行管理, Master 分支有新的合并,可以通过 git diff 命令找出合并前后新增或更新的 Dockerfile,然后根据这些 Dockerfile 依据一定的命名规则构建镜像,并上传到 Docker Harbor 上。
上面命令中 finddifffiles 基于 git diff 命令找出合并前后有差异的文件。
加速 tips
- Alpine Linux Package Management(APK)镜像地址:http://mirrors.aliyun.com
- 一些海外软件下载会比较慢,可以先下载下来上传至阿里云 OSS 后下载。Dockerfile 使用阿里云 OSS 作为下载源,减少构建镜像时间。
基于 .gitlab-ci.yml 的 CI/CD 流程
在完成 GitLab Runner 以及 Docker 基础镜像的制作之后,我们便可以进行 CI/CD 流程来完成代码更新之后的单元测试、lint、编译、镜像打包以及部署等工作。通过 GitLab CI 进行 CI/CD 的操作只需要在代码仓库里编辑和维护一个 .gitlab-ci.yml 文件,每当代码有更新,GitLab CI 会读取 .gitlab-ci.yml 里的内容,生成一条 Pipeline 进行 CI/CD 的操作。.gitlab-ci.yml 的语法比较简单,基于 yaml 语法进行 Job 的描述。我们把 CI/CD 流程中所需要完成的任务拆分成文件里的 Job,只要对每个 Job 完成清晰的定义,便可形成一套合适高效并具有普适性的 CI/CD 流程。
定义 stages
stages 是一个非常重要的概念, 在 .gitlab-ci.yml 中进行全局定义, 在定义 Job 时指定其中的值来表明 Job 所处的 stage。而在 stages 里元素的顺序定义了 Job 的执行顺序:所有在相同 stage 的 Job 会并行执行,只有当前 stage 的所有成功完成后,后面 stage 的 Job 才会去执行。
例如,定义如下 stages:
`stages:
- build
- test
- deploy`
- 首先,所有 build 里的 Job 会并行执行;
- 当 build 里所有 Job 执行成功, test 里所有 Job 会并行执行;
- 如果 test 里所有 Job 执行成功, deploy 里所有 Job 会并行执行;
- 如果 deploy 里所有 Job 执行成功, 当前 Pipeline 会被标记为 passed;
- 当某个 stage 的 Job 执行失败, Pipeline 会标记为为 failed,其后续stage 的 Job 都不会被执行。
Job 的描述
Job 是 .gitlab-ci.yml 文件中最重要的组成部分,所有的 CI/CD 流程中所执行的任务均可以需要通过定义 Job 来实现。具体来说,我们可以通过关键字来对每一个 Job 进行描述。由于 Job 中的关键字众多,并且用法比较丰富,这边针对我们自己实战中的一个 Job 来进行说明。
unittest:stage: testimage: docker.vpgame.cn/infra/php-1.0-ci-1.1services:- name: docker.vpgame.cn/infra/mysql-5.6-multialias: mysql- name: redis:4.0alias: redis_defaultscript:- mv .env.tp .env- composer install --no-dev- phpunit -v --coverage-text --colors=never --coverage-html=coverage --stderrartifacts:when: on_successpaths:- vendor/- coverage/expire_in: 1 hourcoverage: '/^\s*Lines:\s*\d+.\d+\%/'only:- branches- tagstags:- base-runner
上面的 Job 主要完成了单元测试的功能,在起始行定义了 Job 的名称。下面我们来解释 Job 每个关键字的具体含义。
stage,定义了 Job 所处的 stage,值为定义在全局中 stages 里的值。
image,指定了 Runner 运行所需要的镜像,这个镜像是我们之前制作的基本镜像。通过该镜像运行的 Docker 即是 Job 运行的环境。
services,Runner 所运行的 Docker 所需要的连接依赖,在这边分别定义了 MySQL 和 Redis,在 Job 运行时会去连接这两个镜像生成的 Docker。
script,Job 运行的具体的命令 ,通过 Shell 来描述。此 Job 中的 script 主要完成了代码的编译和单元测试。
artifacts,主要是将此 Job 中完成的结果打包保存下来,可以通过 when 指定何时保存,path 定义了保存的文件路径, expire_in 指定了结果保存的有效期。与之对应的是 dependencies 参数,如果其他 Job 需要此 Job 的 artifacts ,只需要在 Job 按照如下定义即可。
`dependencies:
- unittest`
only 关键字指定了 Job 触发的时机,该例子中说明只有分支合并或者打 tag 的情况下,该 Job 才会被触发。
与 only 相对还有 except 关键字来排除触发 Job 某些情况。此外 only 还支持正则表达式,比如:
job:only:- /^issue-.*$/except:- branches
这个例子中,只有以 issue- 开头 tag 标记才会触发 Job。如果不加 except 参数,以 issue- 开头的分支 或者 tag 标记会会触发 Job。
tags,tags关键字主要是用来指定运行的 Runner 类型。在我们实际运用中,部署测试环境和生产环境所采用的 Runner 是不一样的,它们是通过不同的 tag 去标识区分。
所以,我们在 Job 定义中,通过 tags 指定 Runner 的值,来指定所需要的 Runner。
我们可以看到 Job 的定义非常的清晰和灵活,关于 Job 的使用远不止这些功能,更详细的用法可以参考 GitLab CI/CD 官方文档。
CI/CD 流程编排
在清楚了如何描述一个 Job 之后,我们通过定义一个个 Job,并进行编排形成 Pipelines。因为我们可以描述设定 Job 的触发条件,所以通过不同的条件可以触发形成不一样的 Pipelines。
在 PHP 项目 Kubernetes 上线过程中,我们规定了合并 Master 分支会进行 lint、unitest、build-test 以及 deploy-test 四个 Job。
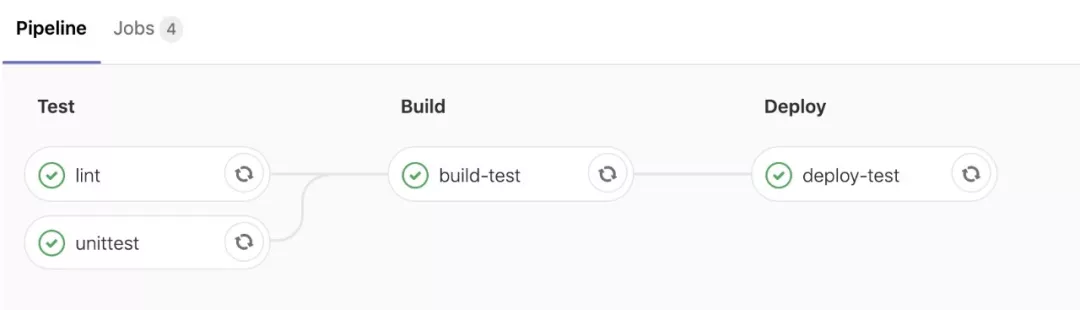
在测试环境验证通过之后,我们再通过打 tag 进行正式环境的上线。此处的 Pipelines 包含了 unittest、build-pro 和 deploy-pro 三个 Job。
build stage:
\# Build stage.build-op:stage: builddependencies:- unittestimage: docker.vpgame.cn/infra/docker-kubectl-1.0services:- name: docker:dindentrypoint: ["dockerd-entrypoint.sh"]script:- echo "Image name:" ${DOCKER_IMAGE_NAME}- docker build -t ${DOCKER_IMAGE_NAME} .- docker push ${DOCKER_IMAGE_NAME}tags:- base-runnerbuild-test:extends: .build-opvariables:DOCKER_IMAGE_NAME: ${DOCKER_REGISTRY_PREFIX}/${CI_PROJECT_PATH}:${CI_COMMIT_REF_SLUG}-${CI_COMMIT_SHORT_SHA}only:- /^testing/- masterbuild-prod:extends: .build-opvariables:DOCKER_IMAGE_NAME: ${DOCKER_REGISTRY_PREFIX}/${CI_PROJECT_PATH}:${CI_COMMIT_TAG}only:- tags
在这边,由于 build 阶段中测试环境和生产环境进行镜像打包时基本操作时是相同的,都是根据 Dockerfile 进行镜像的 build 和镜像仓库的上传。这里用到了一个 extend 参数,可以减少重复的 Job 描述,使得描述更加地简洁清晰。
我们先定义一个 .build-op 的 Job,然后 build-test 和 build-prod 都通过 extend 进行继承,可以通过定义关键字来新增或覆盖 .build-op 中的配置。比如 build-prod 重新定义了变量( variables)DOCKER_IMAGE_NAME以及触发条件(only)更改为了打 tag 。
这边我们还需要注意到的是在定义 DOCKER_IMAGE_NAME 时,我们引用了 GitLab CI 自身的一些变量,比如 CI_COMMIT_TAG 表示项目的 commit 的 tag 名称。我们在定义 Job 变量时,可能会引用到一些 GitLab CI 自身变量,关于这些变量的说明可以参考 GitLab CI/CD Variables 中文文档。
deploy stage:
\# Deploy stage.deploy-op:stage: deployimage: docker.vpgame.cn/infra/docker-kubectl-1.0script:- echo "Image name:" ${DOCKER_IMAGE_NAME}- echo ${APP_NAME}- sed -i "s~__NAMESPACE__~${NAMESPACE}~g" deployment.yml service.yml- sed -i "s~__APP_NAME__~${APP_NAME}~g" deployment.yml service.yml- sed -i "s~__PROJECT_NAME__~${CI_PROJECT_NAME}~g" deployment.yml- sed -i "s~__PROJECT_NAMESPACE__~${CI_PROJECT_NAMESPACE}~g" deployment.yml- sed -i "s~__GROUP_NAME__~${GROUP_NAME}~g" deployment.yml- sed -i "s~__VERSION__~${VERSION}~g" deployment.yml- sed -i "s~__REPLICAS__~${REPLICAS}~g" deployment.yml- kubectl apply -f deployment.yml- kubectl apply -f service.yml- kubectl rollout status -f deployment.yml- kubectl get all,ing -l app=${APP_NAME} -n $NAMESPACE\# Deploy test environmentdeploy-test:variables:REPLICAS: 2VERSION: ${CI_COMMIT_REF_SLUG}-${CI_COMMIT_SHORT_SHA}extends: .deploy-openvironment:name: testurl: http://example.comonly:- /^testing/- mastertags:- base-runner\# Deploy prod environmentdeploy-prod:variables:REPLICAS: 3VERSION: ${CI_COMMIT_TAG}extends: .deploy-openvironment:name: produrl: http://example.comonly:- tagstags:- pro-deploy
与 build 阶段类似,先先定义一个 .deploy-op 的 Job,然后 deploy-test 和 deploy-prod 都通过 extend 进行继承。
.deploy-op 主要完成了对 Kubernetes Deployment 和 Service 模板文件的一些变量的替换,以及根据生成的 Deployment 和 Service 文件进行 Kubernetes 服务的部署。
deploy-test 和 deploy-prod 两个 Job 定义了不同变量(variables)以及触发条件(only)。除此之外, deploy-prod 通过 tags 关键字来使用不同的 Runner,将部署的目标集群指向给生产环境的 Kubernetes。
这里还有一个关键字 environment 需要特别说明,在定义了 environment 之后,我们可以在 GitLab 中查看每次部署的一些信息。除了查看每次部署的一些信息之外,我们还可以很方便地进行重新部署和回滚。
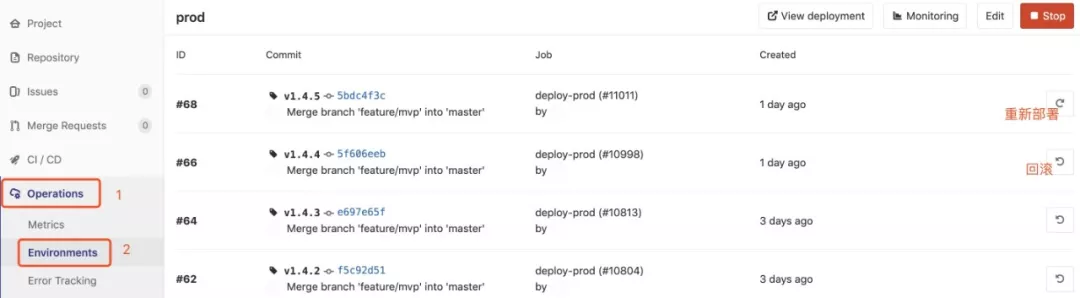
可以看到,通过对 Job 的关键字进行配置,我们可以灵活地编排出我们所需要的 CI/CD 流程,非常好地满足多样化的场景。
Deployment 与 Service 配置
在 CI/CD 流程中完成 Docker 镜像的打包任务之后需要将服务所对应的镜像部署到 Kubernetes 集群中。Kubernetes 提供了多种可以编排调度的资源对象。首先,我们简单了解一下 Kubernetes 中的一些基本资源。
Kubernetes 基本资源对象概览
Pod
Pod 作为无状态应用的运行实体是其中最常用的一种资源对象, Kubernetes 中资源调度最小的基本单元,它包含一个或多个紧密联系的容器。这些容器共享存储、网络和命名空间,以及如何运行的规范。
在 Kubernetes 中, Pod 是非持久的,会因为节点故障或者网络不通等情况而被销毁和重建。所以我们在 Kubernetes 中一般不会直接创建一个独立的 Pod,而是通过多个 Pod 对外提供服务。
ReplicaSet
ReplicaSet 是 Kubernetes 中的一种副本控制器,控制由其管理的 Pod,使 Pod 副本的数量维持在预设的个数。ReplicaSets 可以独立使用,但是在大多数场景下被 Deployments 作为协调 Pod 创建,删除和更新的机制。
Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义方法。通过在 Deployment 中进行目标状态的描述,Deployment controller 会将 Pod 和 ReplicaSet 的实际状态改变为所设定的目标状态。Deployment 典型的应用场景包括:
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续 Deployment
Service
在 Kubernetes 中,Pod 会被随时创建或销毁,每个 Pod 都有自己的 IP,这些 IP 也无法持久存在,所以需要 Service 来提供服务发现和负载均衡能力。Service 是一个定义了一组 Pod 的策略的抽象,通过 Label Selector 来确定后端访问的 Pod,从而为客户端访问服务提供了一个入口。每个 Service 会对应一个集群内部的 ClusterIP,集群内部可以通过 ClusterIP 访问一个服务。如果需要对集群外部提供服务,可以通过 NodePort 或 LoadBalancer 方式。
deployment.yml 配置
deployment.yml 文件用来定义 Deployment。首先通过一个简单的 deployment.yml 配置文件熟悉 Deployment 的配置格式。
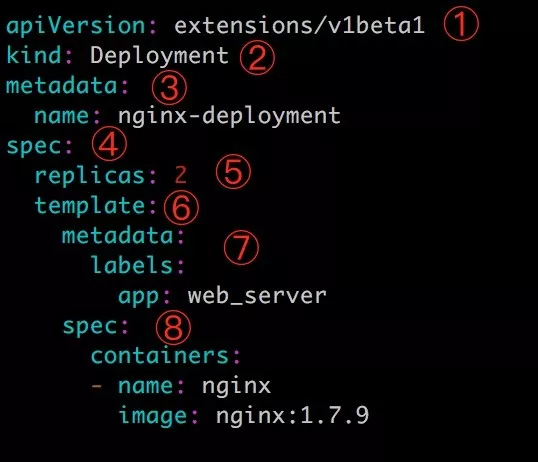
上图中 deployment.yml 分为8个部分,分别如下:
- apiVersion 为当前配置格式的版本
- kind 指定了资源类型,这边当然是 Deployment
- metadata 是该资源的元数据,其中 name 是必需的数据项,还可以指定 label 给资源加上标签
- spec 部分是该 Deployment 的规格说明
- spec.replicas 指定了 Pod 的副本数量
- spec.template 定义 Pod 的基本信息,通过 spec.template.metadata 和 spec.template.spec 指定
- spec.template.metadata 定义 Pod 的元数据。至少需要定义一个 label 用于 Service 识别转发的 Pod, label 是通过 key-value 形式指定的
- spec.template.spec 描述 Pod 的规格,此部分定义 Pod 中每一个容器的属性,name 和 image 是必需项
在实际应用中,还有更多灵活个性化的配置。我们在 Kubernetes 的部署实践中制定了相关的规范,在以上基础结构上进行配置,得到满足我们实际需求的 deployment.yml 配置文件。
在 Kubernetes 的迁移实践中,我们主要在以下方面对 Deployment 的配置进行了规范的约定:
文件模板化
首先我们的 deployment.yml 配置文件是带有变量的模版文件,如下所示:
apiVersion: apps/v1beta2kind: Deploymentmetadata:labels:app: __APP_NAME__group: __GROUP_NAME__name: __APP_NAME__namespace: __NAMESPACE__
APPNAME__、__GROUPNAME 和 NAMESPACE 这种形式的变量都是在 CI/CD 流程中会被替换成 GitLab 每个 project 所对应的变量,目的是为了多了 project 用相同的 deployment.yml 文件,以便在进行 Kubernetes 迁移时可以快速复制,提高效率。
服务名称
- Kubernetes 中运行的 Service 以及 Deployment 名称由 GitLab 中的 groupname 和 projectname 组成,即 {{groupname}}-{{projectname}},例:microservice-common。此名称记为 app_name,作为每个服务在 Kubernetes 中的唯一标识。这些变量可以通过 GitLab-CI 的内置变量中进行获取,无需对每个 project 进行特殊的配置。
- Lables 中用于识别服务的标签与 Deployment 名称保持一致,统一设置为 app:{{app_name}}。
资源分配
节点配置策略,以项目组作为各项目 Pod 运行在哪些 Node 节点的依据,属于同一项目组的项目的 Pod 运行在同一批 Node 节点。具体操作方式为给每个 Node 节点打上形如 group:__GROUP_NAME__ 的标签,在 deployment.yml 文件中做如下设置进行 Pod 的 Node 节点选择:
...spec:...template:...spec:...affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: groupoperator: Invalues:- __GROUP_NAME__...
资源请求大小,对于一些重要的线上应用,limit 和 request 设置一致,资源不足时 Kubernetes 会优先保证这些 Pod 正常运行。为了提高资源利用率。对一些非核心,并且资源不长期占用的应用,可以适当减少 Pod 的 request,这样 Pod 在调度时可以被分配到资源不是十分充裕的节点,提高使用率。但是当节点的资源不足时,也会优先被驱逐或被 oom kill。
健康检查(Liveness/Readiness)配置
Liveness 主要用于探测容器是否存活,若监控检查失败会对容器进行重启操作。Readiness 则是通过监控检测容器是否正常提供服务来决定是否加入到 Service 的转发列表接收请求流量。Readiness 在升级过程可以发挥重要的作用,防止升级时异常的新版本 Pod 替换旧版本 Pod 导致整个应用将无法对外提供服务的情况。
每个服务必须提供可以正常访问的接口,在 deployment.yml 文件配置好相应的监控检测策略。
...spec:...template:...spec:...containers:- name: fpmlivenessProbe:httpGet:path: /__PROJECT_NAME__port: 80initialDelaySeconds: 3periodSeconds: 5readinessProbe:httpGet:path: /__PROJECT_NAME__port: 80initialDelaySeconds: 3periodSeconds: 5......
升级策略配置
升级策略我们选择 RollingUpdate 的方式,即在升级过程中滚动式地逐步新建新版本的 Pod,待新建 Pod 正常启动后逐步 kill 掉老版本的 Pod,最终全部新版本的 Pod 替换为旧版本的 Pod。
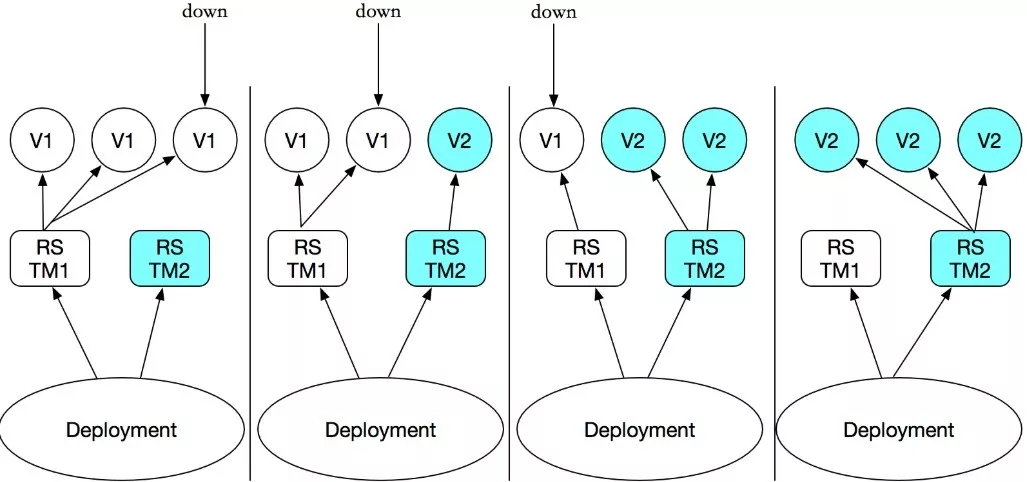
我们还可以设置 maxSurge 和 maxUnavailable 的值分别控制升级过程中最多可以比原先设置多出的 Pod 比例以及升级过程中最多有多少比例 Pod 处于无法提供服务的状态。
日志配置
采用 log-tail 对容器日志进行采集,所有服务的日志都上报到阿里云日志服务的一个 log-store中。在 deployment.yml 文件里配置如下:
...spec:...template:...spec:...containers:- name: fpmenv:- name: aliyun_logs_vpgamevalue: stdout- name: aliyun_logs_vpgame_tagsvalue: topic=__APP_NAME__......
通过设置环境变量的方式来指定上传的 Logstore 和对应的 tag,其中 name 表示 Logstore 的名称。通过 topic 字段区分不同服务的日志。
监控配置
通过在 Deployment 中增加 annotations 的方式,令 Prometheus 可以获取每个 Pod 的业务监控数据。配置示例如下:
...spec:...template:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "80"prometheus.io/path: /{{ project_name }}/metrics...
其中 prometheus.io/scrape: "true" 表示可以被 Prometheus 获取,prometheus.io/port 表示监控数据的端口,prometheus.io/path 表示获取监控数据的路径。
service.yml 配置
service.yml 文件主要对 Service 进行了描述。
apiVersion: v1kind: Servicemetadata:annotations:service.beta.kubernetes.io/alicloud-loadbalancer-address-type: intranetlabels:app: __APP_NAME__name: __APP_NAME__namespace: __NAMESPACE__spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: __APP_NAME__type: LoadBalancer
对 Service 的定义相比于 Deoloyment 要简单的多,通过定义 spec.ports 的相关参数可以指定 Service 的对外暴露的端口已经转发到后端 Pod 的端口。spec.selector 则是指定了需要转发的 Pod 的 label。
另外,我们这边是通过负载均衡器类型对外提供服务,这是通过定义 spec.type 为 LoadBalancer 实现的。通过增加 metadata.annotations 为 service.beta.kubernetes.io/alicloud-loadbalancer-address-type: intranet 可以在对该 Service 进行创建的同时创建一个阿里云内网 SLB 作为对该 Service 请求流量的入口。

如上图所示,EXTERNAL-IP 即为 SLB 的 IP。
总结
在以上工作的基础上,我们对各个服务划分为几类(目前基本上按照语言进行划分),然后为每一类中的服务通过 .gitlab-ci.yml 制定一套统一的 CI/CD 流程,与此相同的,同一类中的服务共用一个 Deployment 和 Service 模板。这样我们在进行服务迁移到 Kubernetes 环境时可以实现快速高效地迁移。
当然,这只是迁移实践路上迈出的第一步,在 Kubernetes 中的服务的稳定性、性能、自动伸缩等方面还需要更深入地探索和研究。
本文作者: 伍冲斌
本文为云栖社区原创内容,未经允许不得转载。
VPGAME的Kubernetes迁移实践的更多相关文章
- VPGAME 的 Kubernetes 迁移实践
作者 | 伍冲斌 VPGAME 运维开发工程师 导读:VPGAME 是集赛事运营.媒体资讯.大数据分析.玩家社群.游戏周边等为一体的综合电竞服务平台.总部位于中国杭州,在上海和美国西雅图分别设立了电 ...
- 【译】Kubernetes监控实践(2):可行监控方案之Prometheus和Sensu
本文介绍两个可行的K8s监控方案:Prometheus和Sensu.两个方案都能全面提供系统级的监控数据,帮助开发人员跟踪K8s关键组件的性能.定位故障.接收预警. 拓展阅读:Kubernetes监控 ...
- 利用Kettle进行SQLServer与Oracle之间的数据迁移实践
Kettle简介 Kettle(网地址为http://kettle.pentaho.org/)是一款国外开源的ETL工具,纯java编写,可以在Windows.Linux.Unix上运行,数据抽取高效 ...
- Kubernetes性能测试实践
本文由 网易云 发布. 概述 随着容器技术的发展,容器服务已经成为行业主流,然而想要在生产环境中成功部署和操作容器,关键还是容器编排技术.市场上有各种各样的容器编排工具,如Docker原生的Swar ...
- 微服务 + Docker + Kubernetes 入门实践 目录
微服务 + Docker + Kubernetes 入门实践: 微服务概念 微服务的一些基本概念 环境准备 Ubuntu & Docker 本文主要讲解在 Ubuntu 上安装和配置 Dock ...
- 02 | 健康之路 kubernetes(k8s) 实践之路 : 生产可用环境及验证
上一篇< 01 | 健康之路 kubernetes(k8s) 实践之路 : 开篇及概况 >我们介绍了我们的大体情况,也算迈出了第一步.今天我们主要介绍下我们生产可用的集群架设方案.涉及了整 ...
- 【转帖】从 Oracle 到 PostgreSQL ,某保险公司迁移实践 技术实践
从 Oracle 到 PostgreSQL ,某保险公司迁移实践 http://www.itpub.net/2019/11/08/4108/ 信泰人寿保险股份有限公司 摘要:去O一直是金融保险行业永恒 ...
- kafka数据迁移实践
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:mikealzhou 本文重点介绍kafka的两类常见数据迁移方式:1.broker内部不同数据盘之间的分区数据迁移:2.不同broker ...
- 01 | 健康之路 kubernetes(k8s) 实践之路 : 开篇及概况
近几年容器相关的技术大行其道,容器.docker.k8s.mesos.service mesh.serverless等名词相信大家多少都有听过,国内互联网公司无一不接触和使用相关技术. 健康之路早在2 ...
随机推荐
- 自学Oracle心得
基本术语: global name 全局数据库名 service name 服务名 SID 实例名 常用命令: 1. s ...
- C预处理之宏定义
#include <stdio.h> //定义不带参数的宏 #define PI 3.14 /*********************************************** ...
- BOM的构成
1.DOM 和 BOM 的区别 DOM:文档对象模型,把[文档]当做一个[对象]来看待,DOM的顶级对象是document 主要学习的是操作页面元素,DOM 是 W3C 的标准规范 BOM:浏览器对象 ...
- VS2017编译Qt x64
1.打开VS本机工具命令提示vcvars64.bat. 2.进入Qt源码目录 cd E:\qt-everywhere-opensource-src- mkdir qt-build && ...
- Java判断链表是否为回文链表
请判断一个链表是否为回文链表. 示例 1: 输入: 1->2 输出: false 示例 2: 输入: 1->2->2->1 输出: true 思路:1.通过快慢指针,来遍历链表 ...
- thinkphp 入口绑定
入口绑定是指在应用的入口文件中绑定某个模块,甚至还可以绑定某个控制器和操作,用来简化URL地址的访问. 绑定模块 例如,我们定义了一个入口文件admin.php,希望可以直接访问Admin模块,那么我 ...
- 第k小团+bitset优化——牛客多校第2场D
模拟bfs,以空团为起点,用堆维护当前最小的团,然后进行加点更新 在加入新点时要注意判重,并且用bitset来加速判断和转移构造 #include<bits/stdc++.h> #incl ...
- Delphi如何实现无边框窗体的移动
在控件的MouseDown事件中加入if (ssleft in Shift) then begin ReleaseCapture; Perform(WM_syscommand, $F012, 0);e ...
- NXOpenC#_Training_2(cn)【转载】
- ACM-ICPC 2018 沈阳赛区网络预赛-B,F,G
学长写的 F. Fantastic Graph "Oh, There is a bipartite graph.""Make it Fantastic." X ...