负载均衡基本原理与lvs
前言:
之前在山西的项目上使用的是lvs下的NAT模式,但另外两个模式并没有涉及,今天系统的整理下关于负载均衡的相关理论与lvs各模式的相关优点与不足,知其然与所以然,而后能针对性的应用:
基本介绍
1.1 负载均衡的由来
在业务初期,我们一般会先使用单台服务器对外提供服务。随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板,当单服务器的性能无法满足业务需求时,就需要把多台服务器组成集群系统提高整体的处理性能。不过我们要使用统一的入口方式对外提供服务,所以需要一个流量调度器通过均衡的算法,将用户大量的请求均衡地分发到后端集群不同的服务器上。这就是我们后边要说的 负载均衡。
1.2 负载均衡的优点
提高了服务的整体性能
提高了服务的扩展性
提高了服务的高可用性
1.3 负载均衡的类型
广义上的负载均衡器大概可以分为 3 类,包括:DNS 方式实现负载均衡、硬件负载均衡、软件负载均衡。
1.3.1 DNS负载均衡
DNS 实现负载均衡是最基础简单的方式。一个域名通过 DNS 解析到多个 IP,每个 IP 对应不同的服务器实例,这样就完成了流量的调度,虽然没有使用常规的负载均衡器,但也的确完成了简单负载均衡的功能。
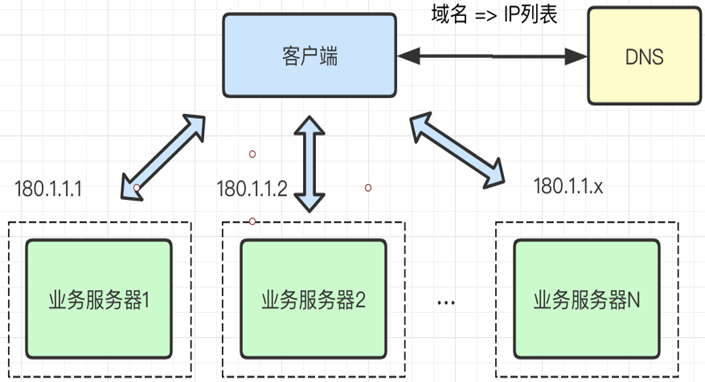
通过 DNS 实现负载均衡的方式的优点:
实现简单,成本低,无需自己开发或维护负载均衡设备,
通过 DNS 实现负载均衡的方式的缺点:
服务器故障切换延迟大
服务器升级不方便。我们知道 DNS 与用户之间是层层的缓存,即便是在故障发生时及时通过 DNS 修改或摘除故障服务器,但中间由于经过运营商的 DNS 缓存,且缓存很有可能不遵循 TTL 规则,导致 DNS 生效时间变得非常缓慢,有时候一天后还会有些许的请求流量。
流量调度不均衡,粒度太粗
DNS 调度的均衡性,受地区运营商 LocalDNS 返回 IP 列表的策略有关系,有的运营商并不会轮询返回多个不同的 IP 地址。另外,某个运营商 LocalDNS 背后服务了多少用户,这也会构成流量调度不均的重要因素。
流量分配策略比较简单,支持的算法较少。DNS 一般只支持 RR 的轮询方式,流量分配策略比较简单,不支持权重、Hash 等调度算法。
DNS 支持的 IP 列表有限制
我们知道 DNS 使用 UDP 报文进行信息传递,每个 UDP 报文大小受链路的 MTU 限制,所以报文中存储的 IP 地址数量也是非常有限的,阿里 DNS 系统针对同一个域名支持配置 10 个不同的 IP 地址。
注:实际上生产环境中很少使用这种方式来实现负载均衡,毕竟缺点很明显。文中之所以描述 DNS 负载均衡方式,是为了能够更清楚地解释负载均衡的概念。一些大公司一般也会利用 DNS 来实现地理级别的负载均衡,实现就近访问,提高访问速度,这种方式一般是入口流量的基础负载均衡,下层会有更专业的负载均衡设备实现的负载架构。
1.3.2 硬件负载均衡
硬件负载均衡是通过专门的硬件设备来实现负载均衡功能,类似于交换机、路由器,是一个负载均衡专用的网络设备。目前业界典型的硬件负载均衡设备有两款:F5 和 A10。这类设备性能强劲、功能强大,但价格非常昂贵,一般只有 “土豪” 公司才会使用此类设备,普通业务量级的公司一般负担不起,二是业务量没那么大,用这些设备也是浪费。
硬件负载均衡的优点:
功能强大:全面支持各层级的负载均衡,支持全面的负载均衡算法。
性能强大:性能远超常见的软件负载均衡器。
稳定性高:商用硬件负载均衡,经过了良好的严格测试,经过大规模使用,稳定性高。
安全防护:除了具备负载均衡外,还具备防火墙、防 DDoS 攻击等安全功能,貌似还支持 SNAT 功能。
硬件负载均衡的缺点:
价格昂贵,就是贵。
扩展性差,无法进行扩展和定制。
调试和维护比较麻烦,需要专业人员。
1.3.3 软件负载均衡
软件负载均衡,可以在普通的服务器上运行负载均衡软件,实现负载均衡功能。目前常见的有 Nginx、HAproxy、LVS,了解到很多大公司使用的 LVS 都是定制版的,做过很多性能方面的优化,比开源版本性能会高出很多,
目前较为熟悉的负载均衡软件是 LVS,且大部分中小型公司使用开源的 LVS 足够满足业务需求;
软件负载均衡的优点:
简单:无论是部署还是维护都比较简单。
便宜:买个 Linux 服务器,装上软件即可。
灵活:4 层和 7 层负载均衡可以根据业务进行选择;也可以根据业务特点,比较方便进行扩展和定制功能。
第2章 基础原理
2.1 Netfilter基本原理
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统,所以要学习 LVS 之前必须要先简单了解 netfilter 基本工作原理。netfilter 其实很复杂也很重要,平时我们说的 Linux 防火墙就是 netfilter,不过我们平时操作的都是 iptables,iptables 只是用户空间编写和传递规则的工具而已,真正工作的是 netfilter。通过下图可以简单了解下 netfilter 的工作机制:
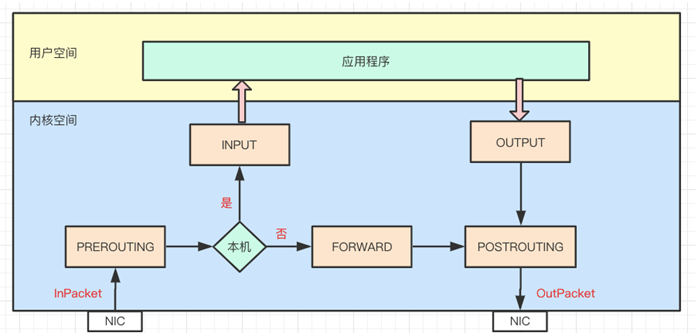
netfilter 是内核态的 Linux 防火墙机制,作为一个通用、抽象的框架,提供了一整套的 hook 函数管理机制,提供诸如数据包过滤、网络地址转换、基于协议类型的连接跟踪的功能。
通俗点讲,就是 netfilter 提供一种机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。netfilter 总共设置了 5 个点,包括:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
PREROUTING :刚刚进入网络层,还未进行路由查找的包,通过此处
INPUT :通过路由查找,确定发往本机的包,通过此处
FORWARD :经路由查找后,要转发的包,在POST_ROUTING之前
OUTPUT :从本机进程刚发出的包,通过此处
POSTROUTING :进入网络层已经经过路由查找,确定转发,将要离开本设备的包,通过此处
数据包大致流经路径:
当一个数据包进入网卡,经过链路层之后进入网络层就会到达 PREROUTING,接着根据目标 IP 地址进行路由查找,如果目标 IP 是本机,数据包继续传递到 INPUT 上,经过协议栈后根据端口将数据送到相应的应用程序;应用程序处理请求后将响应数据包发送到 OUTPUT 上,最终通过 POSTROUTING 后发送出网卡。如果目标 IP 不是本机,而且服务器开启了 forward 参数,就会将数据包递送给 FORWARD 上,最后通过 POSTROUTING 后发送出网卡。
第3章 Lvs负载均衡
Lvs是软件负载均衡,LVS 是基于 netfilter 框架,主要工作于 INPUT 链上,在 INPUT 上注册 ip_vs_in HOOK 函数,进行 IPVS 主流程,大概原理如图所示:

当用户访问网站时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上,IPVS 是工作在 INPUT 链上,会根据访问的 vip+port 判断请求是否 IPVS 服务,如果是则调用注册的 IPVS HOOK 函数,进行 IPVS 相关主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。POSTROUTING 上收到数据包后,根据目标 IP 地址(后端服务器),通过路由选路,将数据包最终发往后端的服务器上。
3.1 基本简介
LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案;
3.2 工作模式
开源 LVS 版本有 3 种工作模式,每种模式工作原理截然不同,说各种模式都有自己的优缺点,分别适合不同的应用场景,不过最终本质的功能都是能实现均衡的流量调度和良好的扩展性。主要包括以下三种模式
DR 模式
NAT 模式
Tunnel 模式
相关术语介绍
CIP:Client IP,表示的是客户端 IP 地址。
VIP:Virtual IP,表示负载均衡对外提供访问的 IP 地址,一般负载均衡 IP 都会通过 Virtual IP 实现高可用。
RIP:RealServer IP,表示负载均衡后端的真实服务器 IP 地址。
DIP:Director IP,表示负载均衡与后端服务器通信的 IP 地址。
CMAC:客户端的 MAC 地址,准确的应该是 LVS 连接的路由器的 MAC 地址。
VMAC:负载均衡 LVS 的 VIP 对应的 MAC 地址。
DMAC:负载均衡 LVS 的 DIP 对应的 MAC 地址。
RMAC:后端真实服务器的 RIP 地址对应的 MAC 地址。
3.2.1 DR模式
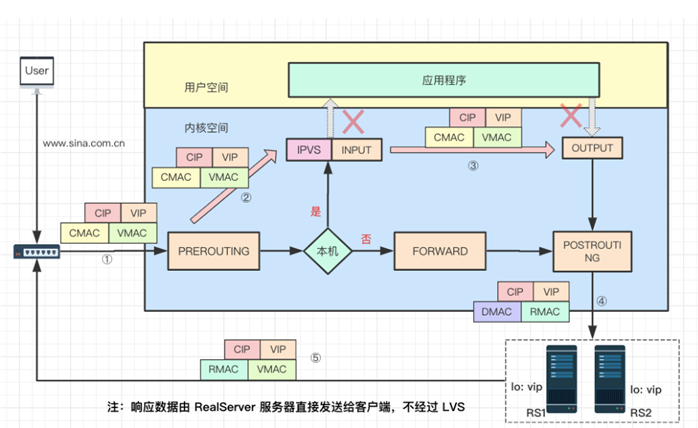
其实 DR 是最常用的工作模式,因为它的强大的性能。下边以一次请求和响应数据流的过程来描述 DR 模式的具体原理:
第一步:
当客户端请求网站主页,经过 DNS 解析到 IP 后,向网站服务器发送请求数据,数据包经过层层网络到达网站负载均衡 LVS 服务器,到达 LVS 网卡时的数据包:源 IP 是客户端 IP 地址 CIP,目的 IP 是新浪对外的服务器 IP 地址,也就是 VIP;此时源 MAC 地址是 CMAC,其实是 LVS 连接的路由器的 MAC 地址(为了容易理解记为 CMAC),目标 MAC 地址是 VIP 对应的 MAC,记为 VMAC。
第二步:
数据包到达网卡后,经过链路层到达 PREROUTING 位置(刚进入网络层),查找路由发现目的 IP 是 LVS 的 VIP,就会递送到 INPUT 链上,此时数据包 MAC、IP、Port 都没有修改。
第三步:
数据包到达 INPUT 链,INPUT 是 LVS 主要工作的位置。此时 LVS 会根据目的 IP 和 Port 来确认是否是 LVS 定义的服务,如果是定义过的 VIP 服务,就会根据配置的 Service 信息,从 RealServer 中选择一个作为后端服务器 RS1,然后以 RS1 作为目标查找 Out 方向的路由,确定下一跳信息以及数据包要通过哪个网卡发出。最后将数据包通过 INET_HOOK 到 OUTPUT 链上(Out 方向刚进入网络层)。
第四步:
数据包通过 POSTROUTING 链后,从网络层转到链路层,将目的 MAC 地址修改为 RealServer 服务器 MAC 地址,记为 RMAC;而源 MAC 地址修改为 LVS 与 RS 同网段的 selfIP 对应的 MAC 地址,记为 DMAC。此时,数据包通过交换机转发给了 RealServer 服务器
第五步:
请求数据包到达 RealServer 服务器后,链路层检查目的 MAC 是自己网卡地址。到了网络层,查找路由,目的 IP 是 VIP(lo 上配置了 VIP),判定是本地主机的数据包,经过协议栈后拷贝至应用程序(比如这里是 nginx 服务器),nginx 响应请求后,产生响应数据包。以目的 VIP 为 dst 查找 Out 路由,确定下一跳信息和发送网卡设备信息,发送数据包。此时数据包源、目的 IP 分别是 VIP、CIP,而源 MAC 地址是 RS1 的 RMAC,目的 MAC 是下一跳(路由器)的 MAC 地址,记为 CMAC(为了容易理解,记为 CMAC)。然后数据包通过 RS 相连的路由器转发给真正客户端。
DR模式的优缺点:
DR 模式的优点
a. 响应数据不经过 lvs,性能高
b. 对数据包修改小,信息保存完整(携带客户端源 IP)
DR 模式的缺点
a. lvs 与 rs 必须在同一个物理网络(不支持跨机房)
b. rs 上必须配置 lo 和其它内核参数
c. 不支持端口映射
DR 模式的使用场景
如果对性能要求非常高,可以首选 DR 模式,而且可以透传客户端源 IP 地址
3.2.2 NAT模式
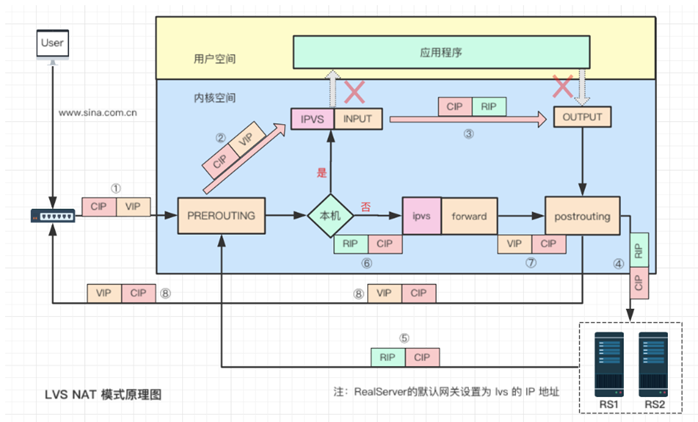
第一步:
用户请求数据包经过层层网络,到达 lvs 网卡,此时数据包源 IP 是 CIP,目的 IP 是 VIP。
经过网卡进入网络层 prerouting 位置,根据目的 IP 查找路由,确认是本机 IP,将数据包转发到 INPUT 上,此时源、目的 IP 都未发生变化。
第二步:
到达 lvs 后,通过目的 IP 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 RS 作为后端服务器,将数据包目的 IP 修改为 RIP,并以 RIP 为目的 IP 查找路由信息,确定下一跳和出口信息,将数据包转发至 output 上。
第三步:
修改后的数据包经过 postrouting 和链路层处理后,到达 RS 服务器,此时的数据包源 IP 是 CIP,目的 IP 是 RIP。
第四步:
到达 RS 服务器的数据包经过链路层和网络层检查后,被送往用户空间 nginx 程序。nginx 程序处理完毕,发送响应数据包,由于 RS 上默认网关配置为 lvs 设备 IP,所以 nginx 服务器会将数据包转发至下一跳,也就是 lvs 服务器。此时数据包源 IP 是 RIP,目的 IP 是 CIP。
第五步:
lvs 服务器收到 RS 响应数据包后,根据路由查找,发现目的 IP 不是本机 IP,且 lvs 服务器开启了转发模式,所以将数据包转发给 forward 链,此时数据包未作修改。
第六步:
lvs 收到响应数据包后,根据目的 IP 和目的 port 查找服务和连接表,将源 IP 改为 VIP,通过路由查找,确定下一跳和出口信息,将数据包发送至网关,经过复杂的网络到达用户客户端,最终完成了一次请求和响应的交互。
NAT模式的优缺点:
NAT 模式优点
a. 能够支持 windows 操作系统
b. 支持端口映射。如果 rs 端口与 vport 不一致,lvs 除了修改目的 IP,也会修改 dport 以支持端口映射。
NAT 模式缺点
a. 后端 RS 需要配置网关
b. 双向流量对 lvs 负载压力比较大
NAT 模式的使用场景
如果你是 windows 系统,使用 lvs 的话,则必须选择 NAT 模式了。
3.2.3 Tunnel模式
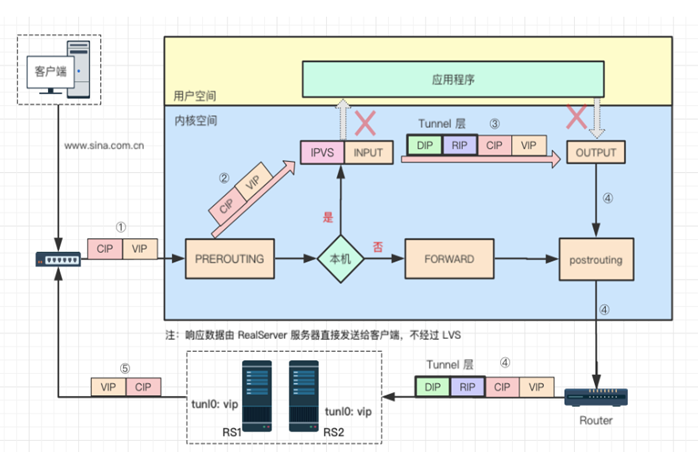
第一步:
用户请求数据包经过多层网络,到达 lvs 网卡,此时数据包源 IP 是 cip,目的 ip 是 vip。
第二步:
经过网卡进入网络层 prerouting 位置,根据目的 ip 查找路由,确认是本机 ip,将数据包转发到 input 链上,到达 lvs,此时源、目的 ip 都未发生变化。
第三步:
到达 lvs 后,通过目的 ip 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 rs 作为后端服务器,以 rip 为目的 ip 查找路由信息,确定下一跳、dev 等信息,然后 IP 头部前边额外增加了一个 IP 头(以 dip 为源,rip 为目的 ip),将数据包转发至 output 上。
第四步:
数据包根据路由信息经最终经过 lvs 网卡,发送至路由器网关,通过网络到达后端服务器。
第五步:
后端服务器收到数据包后,ipip 模块将 Tunnel 头部卸载,正常看到的源 ip 是 cip,目的 ip 是 vip,由于在 tunl0 上配置 vip,路由查找后判定为本机 ip,送往应用程序。应用程序 nginx 正常响应数据后以 vip 为源 ip,cip 为目的 ip 数据包发送出网卡,最终到达客户端。
Tunnel 模式的优点
a. 单臂模式,对 lvs 负载压力小
b. 对数据包修改较小,信息保存完整
c. 可跨机房(不过在国内实现有难度)
Tunnel 模式的缺点
a. 需要在后端服务器安装配置 ipip 模块
b. 需要在后端服务器 tunl0 配置 vip
c. 隧道头部的加入可能导致分片,影响服务器性能
d. 隧道头部 IP 地址固定,后端服务器网卡 hash 可能不均
e. 不支持端口映射
Tunnel 模式的使用场景
理论上,如果对转发性能要求较高,且有跨机房需求,Tunnel 可能是较好的选择。
3.3 调度算法
3.3.1 轮询调度
轮询调度(Round Robin 简称'RR')算法就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是实现简单。轮询算法假设所有的服务器处理请求的能力都一样的,调度器会将所有的请求平均分配给每个真实服务器。
3.3.2 加权轮询调度
加权轮询(Weight Round Robin 简称'WRR')算法主要是对轮询算法的一种优化与补充,LVS会考虑每台服务器的性能,并给每台服务器添加一个权值,如果服务器A的权值为1,服务器B的权值为2,则调度器调度到服务器B的请求会是服务器A的两倍。权值越高的服务器,处理的请求越多。
3.3.3 最小连接调度
最小连接调度(Least Connections 简称'LC')算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态的调度算法,它通过服务器当前活跃的连接数来估计服务器的情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中断或者超时,其连接数减1。
(集群系统的真实服务器具有相近的系统性能,采用最小连接调度算法可以比较好地均衡负载。)
3.3.4 加权最小连接调度
加权最少连接(Weight Least Connections 简称'WLC')算法是最小连接调度的超集,各个服务器相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.3.5 基于局部的最少连接
基于局部的最少连接调度(Locality-Based Least Connections 简称'LBLC')算法是针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和Cache命中率,从而提升整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则使用'最少连接'的原则选出一个可用的服务器,将请求发送到服务器。
3.3.6 带复制的基于局部性的最少连接
带复制的基于局部性的最少连接(Locality-Based Least Connections with Replication 简称'LBLCR')算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统,它与LBLC算法不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。按'最小连接'原则从该服务器组中选出一一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按'最小连接'原则从整个集群中选出一台服务器,将该服务器加入到这个服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
3.3.7 目标地址散列调度
目标地址散列调度(Destination Hashing 简称'DH')算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。
3.3.8 源地址散列调度U
源地址散列调度(Source Hashing 简称'SH')算法先根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同,它的算法流程与目标地址散列调度算法的基本相似。
3.3.9 最短的期望的延迟
最短的期望的延迟调度(Shortest Expected Delay 简称'SED')算法基于WLC算法。举个例子吧,ABC三台服务器的权重分别为1、2、3 。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用SED算法后会进行一个运算
A:(1+1)/1=2 B:(1+2)/2=3/2 C:(1+3)/3=4/3 就把请求交给得出运算结果最小的服务器。
3.3.10 最少队列调度
最少队列调度(Never Queue 简称'NQ')算法,无需队列。如果有realserver的连接数等于0就直接分配过去,不需要在进行SED运算。
第1章 基本介绍
1.1 负载均衡的由来
在业务初期,我们一般会先使用单台服务器对外提供服务。随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板,当单服务器的性能无法满足业务需求时,就需要把多台服务器组成集群系统提高整体的处理性能。不过我们要使用统一的入口方式对外提供服务,所以需要一个流量调度器通过均衡的算法,将用户大量的请求均衡地分发到后端集群不同的服务器上。这就是我们后边要说的 负载均衡。
1.2 负载均衡的优点
提高了服务的整体性能
提高了服务的扩展性
提高了服务的高可用性
1.3 负载均衡的类型
广义上的负载均衡器大概可以分为 3 类,包括:DNS 方式实现负载均衡、硬件负载均衡、软件负载均衡。
1.3.1 DNS负载均衡
DNS 实现负载均衡是最基础简单的方式。一个域名通过 DNS 解析到多个 IP,每个 IP 对应不同的服务器实例,这样就完成了流量的调度,虽然没有使用常规的负载均衡器,但也的确完成了简单负载均衡的功能。
通过 DNS 实现负载均衡的方式的优点:
实现简单,成本低,无需自己开发或维护负载均衡设备,
通过 DNS 实现负载均衡的方式的缺点:
服务器故障切换延迟大
服务器升级不方便。我们知道 DNS 与用户之间是层层的缓存,即便是在故障发生时及时通过 DNS 修改或摘除故障服务器,但中间由于经过运营商的 DNS 缓存,且缓存很有可能不遵循 TTL 规则,导致 DNS 生效时间变得非常缓慢,有时候一天后还会有些许的请求流量。
流量调度不均衡,粒度太粗
DNS 调度的均衡性,受地区运营商 LocalDNS 返回 IP 列表的策略有关系,有的运营商并不会轮询返回多个不同的 IP 地址。另外,某个运营商 LocalDNS 背后服务了多少用户,这也会构成流量调度不均的重要因素。
流量分配策略比较简单,支持的算法较少。DNS 一般只支持 RR 的轮询方式,流量分配策略比较简单,不支持权重、Hash 等调度算法。
DNS 支持的 IP 列表有限制
我们知道 DNS 使用 UDP 报文进行信息传递,每个 UDP 报文大小受链路的 MTU 限制,所以报文中存储的 IP 地址数量也是非常有限的,阿里 DNS 系统针对同一个域名支持配置 10 个不同的 IP 地址。
注:实际上生产环境中很少使用这种方式来实现负载均衡,毕竟缺点很明显。文中之所以描述 DNS 负载均衡方式,是为了能够更清楚地解释负载均衡的概念。一些大公司一般也会利用 DNS 来实现地理级别的负载均衡,实现就近访问,提高访问速度,这种方式一般是入口流量的基础负载均衡,下层会有更专业的负载均衡设备实现的负载架构。
1.3.2 硬件负载均衡
硬件负载均衡是通过专门的硬件设备来实现负载均衡功能,类似于交换机、路由器,是一个负载均衡专用的网络设备。目前业界典型的硬件负载均衡设备有两款:F5 和 A10。这类设备性能强劲、功能强大,但价格非常昂贵,一般只有 “土豪” 公司才会使用此类设备,普通业务量级的公司一般负担不起,二是业务量没那么大,用这些设备也是浪费。
硬件负载均衡的优点:
功能强大:全面支持各层级的负载均衡,支持全面的负载均衡算法。
性能强大:性能远超常见的软件负载均衡器。
稳定性高:商用硬件负载均衡,经过了良好的严格测试,经过大规模使用,稳定性高。
安全防护:除了具备负载均衡外,还具备防火墙、防 DDoS 攻击等安全功能,貌似还支持 SNAT 功能。
硬件负载均衡的缺点:
价格昂贵,就是贵。
扩展性差,无法进行扩展和定制。
调试和维护比较麻烦,需要专业人员。
1.3.3 软件负载均衡
软件负载均衡,可以在普通的服务器上运行负载均衡软件,实现负载均衡功能。目前常见的有 Nginx、HAproxy、LVS,了解到很多大公司使用的 LVS 都是定制版的,做过很多性能方面的优化,比开源版本性能会高出很多,
目前较为熟悉的负载均衡软件是 LVS,且大部分中小型公司使用开源的 LVS 足够满足业务需求;
软件负载均衡的优点:
简单:无论是部署还是维护都比较简单。
便宜:买个 Linux 服务器,装上软件即可。
灵活:4 层和 7 层负载均衡可以根据业务进行选择;也可以根据业务特点,比较方便进行扩展和定制功能。
第2章 基础原理
2.1 Netfilter基本原理
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统,所以要学习 LVS 之前必须要先简单了解 netfilter 基本工作原理。netfilter 其实很复杂也很重要,平时我们说的 Linux 防火墙就是 netfilter,不过我们平时操作的都是 iptables,iptables 只是用户空间编写和传递规则的工具而已,真正工作的是 netfilter。通过下图可以简单了解下 netfilter 的工作机制:
netfilter 是内核态的 Linux 防火墙机制,作为一个通用、抽象的框架,提供了一整套的 hook 函数管理机制,提供诸如数据包过滤、网络地址转换、基于协议类型的连接跟踪的功能。
通俗点讲,就是 netfilter 提供一种机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。netfilter 总共设置了 5 个点,包括:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
PREROUTING :刚刚进入网络层,还未进行路由查找的包,通过此处
INPUT :通过路由查找,确定发往本机的包,通过此处
FORWARD :经路由查找后,要转发的包,在POST_ROUTING之前
OUTPUT :从本机进程刚发出的包,通过此处
POSTROUTING :进入网络层已经经过路由查找,确定转发,将要离开本设备的包,通过此处
数据包大致流经路径:
当一个数据包进入网卡,经过链路层之后进入网络层就会到达 PREROUTING,接着根据目标 IP 地址进行路由查找,如果目标 IP 是本机,数据包继续传递到 INPUT 上,经过协议栈后根据端口将数据送到相应的应用程序;应用程序处理请求后将响应数据包发送到 OUTPUT 上,最终通过 POSTROUTING 后发送出网卡。如果目标 IP 不是本机,而且服务器开启了 forward 参数,就会将数据包递送给 FORWARD 上,最后通过 POSTROUTING 后发送出网卡。
第3章 Lvs负载均衡
Lvs是软件负载均衡,LVS 是基于 netfilter 框架,主要工作于 INPUT 链上,在 INPUT 上注册 ip_vs_in HOOK 函数,进行 IPVS 主流程,大概原理如图所示:
当用户访问网站时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上,IPVS 是工作在 INPUT 链上,会根据访问的 vip+port 判断请求是否 IPVS 服务,如果是则调用注册的 IPVS HOOK 函数,进行 IPVS 相关主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。POSTROUTING 上收到数据包后,根据目标 IP 地址(后端服务器),通过路由选路,将数据包最终发往后端的服务器上。
3.1 基本简介
LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案;
3.2 工作模式
开源 LVS 版本有 3 种工作模式,每种模式工作原理截然不同,说各种模式都有自己的优缺点,分别适合不同的应用场景,不过最终本质的功能都是能实现均衡的流量调度和良好的扩展性。主要包括以下三种模式
DR 模式
NAT 模式
Tunnel 模式
相关术语介绍
CIP:Client IP,表示的是客户端 IP 地址。
VIP:Virtual IP,表示负载均衡对外提供访问的 IP 地址,一般负载均衡 IP 都会通过 Virtual IP 实现高可用。
RIP:RealServer IP,表示负载均衡后端的真实服务器 IP 地址。
DIP:Director IP,表示负载均衡与后端服务器通信的 IP 地址。
CMAC:客户端的 MAC 地址,准确的应该是 LVS 连接的路由器的 MAC 地址。
VMAC:负载均衡 LVS 的 VIP 对应的 MAC 地址。
DMAC:负载均衡 LVS 的 DIP 对应的 MAC 地址。
RMAC:后端真实服务器的 RIP 地址对应的 MAC 地址。
3.2.1 DR模式
其实 DR 是最常用的工作模式,因为它的强大的性能。下边以一次请求和响应数据流的过程来描述 DR 模式的具体原理:
第一步:
当客户端请求网站主页,经过 DNS 解析到 IP 后,向网站服务器发送请求数据,数据包经过层层网络到达网站负载均衡 LVS 服务器,到达 LVS 网卡时的数据包:源 IP 是客户端 IP 地址 CIP,目的 IP 是新浪对外的服务器 IP 地址,也就是 VIP;此时源 MAC 地址是 CMAC,其实是 LVS 连接的路由器的 MAC 地址(为了容易理解记为 CMAC),目标 MAC 地址是 VIP 对应的 MAC,记为 VMAC。
第二步:
数据包到达网卡后,经过链路层到达 PREROUTING 位置(刚进入网络层),查找路由发现目的 IP 是 LVS 的 VIP,就会递送到 INPUT 链上,此时数据包 MAC、IP、Port 都没有修改。
第三步:
数据包到达 INPUT 链,INPUT 是 LVS 主要工作的位置。此时 LVS 会根据目的 IP 和 Port 来确认是否是 LVS 定义的服务,如果是定义过的 VIP 服务,就会根据配置的 Service 信息,从 RealServer 中选择一个作为后端服务器 RS1,然后以 RS1 作为目标查找 Out 方向的路由,确定下一跳信息以及数据包要通过哪个网卡发出。最后将数据包通过 INET_HOOK 到 OUTPUT 链上(Out 方向刚进入网络层)。
第四步:
数据包通过 POSTROUTING 链后,从网络层转到链路层,将目的 MAC 地址修改为 RealServer 服务器 MAC 地址,记为 RMAC;而源 MAC 地址修改为 LVS 与 RS 同网段的 selfIP 对应的 MAC 地址,记为 DMAC。此时,数据包通过交换机转发给了 RealServer 服务器
第五步:
请求数据包到达 RealServer 服务器后,链路层检查目的 MAC 是自己网卡地址。到了网络层,查找路由,目的 IP 是 VIP(lo 上配置了 VIP),判定是本地主机的数据包,经过协议栈后拷贝至应用程序(比如这里是 nginx 服务器),nginx 响应请求后,产生响应数据包。以目的 VIP 为 dst 查找 Out 路由,确定下一跳信息和发送网卡设备信息,发送数据包。此时数据包源、目的 IP 分别是 VIP、CIP,而源 MAC 地址是 RS1 的 RMAC,目的 MAC 是下一跳(路由器)的 MAC 地址,记为 CMAC(为了容易理解,记为 CMAC)。然后数据包通过 RS 相连的路由器转发给真正客户端。
DR模式的优缺点:
DR 模式的优点
a. 响应数据不经过 lvs,性能高
b. 对数据包修改小,信息保存完整(携带客户端源 IP)
DR 模式的缺点
a. lvs 与 rs 必须在同一个物理网络(不支持跨机房)
b. rs 上必须配置 lo 和其它内核参数
c. 不支持端口映射
DR 模式的使用场景
如果对性能要求非常高,可以首选 DR 模式,而且可以透传客户端源 IP 地址
3.2.2 NAT模式
第一步:
用户请求数据包经过层层网络,到达 lvs 网卡,此时数据包源 IP 是 CIP,目的 IP 是 VIP。
经过网卡进入网络层 prerouting 位置,根据目的 IP 查找路由,确认是本机 IP,将数据包转发到 INPUT 上,此时源、目的 IP 都未发生变化。
第二步:
到达 lvs 后,通过目的 IP 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 RS 作为后端服务器,将数据包目的 IP 修改为 RIP,并以 RIP 为目的 IP 查找路由信息,确定下一跳和出口信息,将数据包转发至 output 上。
第三步:
修改后的数据包经过 postrouting 和链路层处理后,到达 RS 服务器,此时的数据包源 IP 是 CIP,目的 IP 是 RIP。
第四步:
到达 RS 服务器的数据包经过链路层和网络层检查后,被送往用户空间 nginx 程序。nginx 程序处理完毕,发送响应数据包,由于 RS 上默认网关配置为 lvs 设备 IP,所以 nginx 服务器会将数据包转发至下一跳,也就是 lvs 服务器。此时数据包源 IP 是 RIP,目的 IP 是 CIP。
第五步:
lvs 服务器收到 RS 响应数据包后,根据路由查找,发现目的 IP 不是本机 IP,且 lvs 服务器开启了转发模式,所以将数据包转发给 forward 链,此时数据包未作修改。
第六步:
lvs 收到响应数据包后,根据目的 IP 和目的 port 查找服务和连接表,将源 IP 改为 VIP,通过路由查找,确定下一跳和出口信息,将数据包发送至网关,经过复杂的网络到达用户客户端,最终完成了一次请求和响应的交互。
NAT模式的优缺点:
NAT 模式优点
a. 能够支持 windows 操作系统
b. 支持端口映射。如果 rs 端口与 vport 不一致,lvs 除了修改目的 IP,也会修改 dport 以支持端口映射。
NAT 模式缺点
a. 后端 RS 需要配置网关
b. 双向流量对 lvs 负载压力比较大
NAT 模式的使用场景
如果你是 windows 系统,使用 lvs 的话,则必须选择 NAT 模式了。
3.2.3 Tunnel模式
第一步:
用户请求数据包经过多层网络,到达 lvs 网卡,此时数据包源 IP 是 cip,目的 ip 是 vip。
第二步:
经过网卡进入网络层 prerouting 位置,根据目的 ip 查找路由,确认是本机 ip,将数据包转发到 input 链上,到达 lvs,此时源、目的 ip 都未发生变化。
第三步:
到达 lvs 后,通过目的 ip 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 rs 作为后端服务器,以 rip 为目的 ip 查找路由信息,确定下一跳、dev 等信息,然后 IP 头部前边额外增加了一个 IP 头(以 dip 为源,rip 为目的 ip),将数据包转发至 output 上。
第四步:
数据包根据路由信息经最终经过 lvs 网卡,发送至路由器网关,通过网络到达后端服务器。
第五步:
后端服务器收到数据包后,ipip 模块将 Tunnel 头部卸载,正常看到的源 ip 是 cip,目的 ip 是 vip,由于在 tunl0 上配置 vip,路由查找后判定为本机 ip,送往应用程序。应用程序 nginx 正常响应数据后以 vip 为源 ip,cip 为目的 ip 数据包发送出网卡,最终到达客户端。
Tunnel 模式的优点
a. 单臂模式,对 lvs 负载压力小
b. 对数据包修改较小,信息保存完整
c. 可跨机房(不过在国内实现有难度)
Tunnel 模式的缺点
a. 需要在后端服务器安装配置 ipip 模块
b. 需要在后端服务器 tunl0 配置 vip
c. 隧道头部的加入可能导致分片,影响服务器性能
d. 隧道头部 IP 地址固定,后端服务器网卡 hash 可能不均
e. 不支持端口映射
Tunnel 模式的使用场景
理论上,如果对转发性能要求较高,且有跨机房需求,Tunnel 可能是较好的选择。
3.3 调度算法
3.3.1 轮询调度
轮询调度(Round Robin 简称'RR')算法就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是实现简单。轮询算法假设所有的服务器处理请求的能力都一样的,调度器会将所有的请求平均分配给每个真实服务器。
3.3.2 加权轮询调度
加权轮询(Weight Round Robin 简称'WRR')算法主要是对轮询算法的一种优化与补充,LVS会考虑每台服务器的性能,并给每台服务器添加一个权值,如果服务器A的权值为1,服务器B的权值为2,则调度器调度到服务器B的请求会是服务器A的两倍。权值越高的服务器,处理的请求越多。
3.3.3 最小连接调度
最小连接调度(Least Connections 简称'LC')算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态的调度算法,它通过服务器当前活跃的连接数来估计服务器的情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中断或者超时,其连接数减1。
(集群系统的真实服务器具有相近的系统性能,采用最小连接调度算法可以比较好地均衡负载。)
3.3.4 加权最小连接调度
加权最少连接(Weight Least Connections 简称'WLC')算法是最小连接调度的超集,各个服务器相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.3.5 基于局部的最少连接
基于局部的最少连接调度(Locality-Based Least Connections 简称'LBLC')算法是针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和Cache命中率,从而提升整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则使用'最少连接'的原则选出一个可用的服务器,将请求发送到服务器。
3.3.6 带复制的基于局部性的最少连接
带复制的基于局部性的最少连接(Locality-Based Least Connections with Replication 简称'LBLCR')算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统,它与LBLC算法不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。按'最小连接'原则从该服务器组中选出一一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按'最小连接'原则从整个集群中选出一台服务器,将该服务器加入到这个服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
3.3.7 目标地址散列调度
目标地址散列调度(Destination Hashing 简称'DH')算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。
3.3.8 源地址散列调度U
源地址散列调度(Source Hashing 简称'SH')算法先根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同,它的算法流程与目标地址散列调度算法的基本相似。
3.3.9 最短的期望的延迟
最短的期望的延迟调度(Shortest Expected Delay 简称'SED')算法基于WLC算法。举个例子吧,ABC三台服务器的权重分别为1、2、3 。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用SED算法后会进行一个运算
A:(1+1)/1=2 B:(1+2)/2=3/2 C:(1+3)/3=4/3 就把请求交给得出运算结果最小的服务器。
3.3.10 最少队列调度
最少队列调度(Never Queue 简称'NQ')算法,无需队列。如果有realserver的连接数等于0就直接分配过去,不需要在进行SED运算。
负载均衡基本原理与lvs的更多相关文章
- LVS负载均衡基本原理
负载均衡基本原理与lvs 基本介绍 1.1 负载均衡的由来 在业务初期,我们一般会先使用单台服务器对外提供服务.随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板,当单 ...
- 高并发负载均衡——nginx与lvs
一.企业级web项目架构 一.企业级web项目架构图 二.架构分析 客户端通过企业防火墙发送请求 在App服务器如tomcat接收客户端请求前,面对高并发大数据量访问的企业架构,会通过加入负载均衡主备 ...
- 高可用性的负载均衡方案之lvs+keepalived和haproxy+heartbeat区别
高可用性的负载均衡方案 目前使用比较多的就是标题中提到的这两者,其实lvs和haproxy都是实现的负载均衡的作用,keepalived和heartbeat都是提高高可用性的,避免单点故障.那么他们为 ...
- 负载均衡层次结构:LVS Nginx DNS CDN
文章地址:http://blog.csdn.net/mindfloating/article/details/51020767 作为后端应用的开发者,我们经常开发.调试.测试完我们的应用并发布到生产环 ...
- RabbitMQ负载均衡方案之LVS
负载均衡的方案有很多,适合RabbitMQ使用的处理HAProxy之外还有LVS.LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件 ...
- linux 负载均衡配置 keepalive lvs 使用nginx转发 CentOS7 搭建LVS+keepalived负载均衡
最近希望能够配置一下负载均衡,在虚拟机上面,但是网上找了很多资料很零散,对于不了解的人,很多不够详细,最近终于做好了,把具体的步骤写下来,方便各位网友查阅学习 这个实验需要安装nginx如果没有安装过 ...
- 负载均衡技术之-lvs
LVS简介 Internet的快速增长使多媒体网络服务器面对的访问数量快速增加,服务器需要具备提供大量并发访问服务的能力,因此对于大负载的服务器来讲, CPU.I/O处理能力很快会成为瓶颈.由于单台服 ...
- Linux负载均衡软件之LVS
一. LVS简介 LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项目,它的官方站点是linuxvirtualserver.org ...
- Linux负载均衡利器(LVS)
LVS是什么? LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统.本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之 ...
随机推荐
- List of the best open source software applications
List of the best open source software applications by Ryan • Oct 25th, 2008 • Category: Featured Art ...
- Mysql 锁表处理
-- 查看正在被锁定的的表 show ; -- 查看进程号 show processlist; -- 杀掉进程 : -- 表级锁次数 show status like 'Table%'; +----- ...
- @codechef - SERSUM@ Series Sum
目录 @description@ @solution@ @part - 1@ @part - 2@ @part - 3@ @accepted code@ @details@ @description@ ...
- 如何把thinkphp 的url改为.html
ThinkPHP支持伪静态URL设置,可以通过设置URL_HTML_SUFFIX参数随意在URL的最后增加你想要的静态后缀,而不会影响当前操作的正常执行.例如,我们设置'URL_HTML_SUFFIX ...
- Element-ui学习笔记1
1.col,row布局注意事项 el-row el-col gutter就是css,span的时候宽度是按boder-box来计算. 将 type 属性赋值为 'flex',可以启用 flex 布局, ...
- Project Euler Problem 5-Smallest multiple
对每个数字分解素因子,最后对每个素因子去其最大的指数,然后把不同素因子的最大指数次幂相乘,得到的就是最小公倍数 python不熟练,代码比较挫 mp = {} def process(n): i = ...
- python命令之m参数
在命令行中使用python时,python支持在其后面添加可选参数. python命令的可选参数有很多,例如:使用可选参数h可以查询python的帮助信息: 可选参数m 下面我们来说说python命令 ...
- 总结thinkphp快捷查询getBy、getField、getFieldBy用法及场景
thinkphp作为国内现阶段最成熟的框架:没有之一: 不得不说是有好些特别方便的方法的: 然而如果初接触thinkphp的时候难免会被搞的有点迷茫: for example这些: getBy get ...
- python基础八之文件操作
python的文件操作 1,打开文件 编码方式要和文件的编码方式相同! #open('路径','打开方式','指定编码方式') f = open(r'E:\pycharm\学习\day8\test', ...
- H3C RIPv2的改进