【笔记】机器学习 - 李宏毅 - 2 - Regression + Demo
Regression 回归
应用领域包括:Stock Market Forecast, Self-driving car, Recommondation,...
Step 1: Model
对于宝可梦的CP值预测问题,假设为一个最简单的线性模型
y = b + \(\sum w_i x_i\)
\(x_i\): an attribute of input x(feature)
\(w_i\): weight, b: bias
Step 2: Goodness of Function
定义一个Loss Function来评价Function的好坏,
(input: a function, output: how bad it is, L(f) = L(w, b) )
若采用方差来评估,则 L(w, b) = \(\sum_{n=1}^{10}(\hat{y}^n-(b+{w·x_{cp}}^n))^{2}\)
(其中,\(\hat{y}\): 表示正确的,实际观测到的结果)
Step 3: Pick the Best Function
最好的函数就是使L(f)最小的函数,f* = arg \(min_f\)L(f)
w*, b* = arg \(min_{w,b}\)L(w, b) = arg \(min_{w, b}\)\(\sum_{n=1}^{10}(\hat{y}^n-(b+{w·x_{cp}}^n))^{2}\)
如何计算呢?用的就是梯度下降法,Gradient Descent,
如果只考虑 w 一个变量:
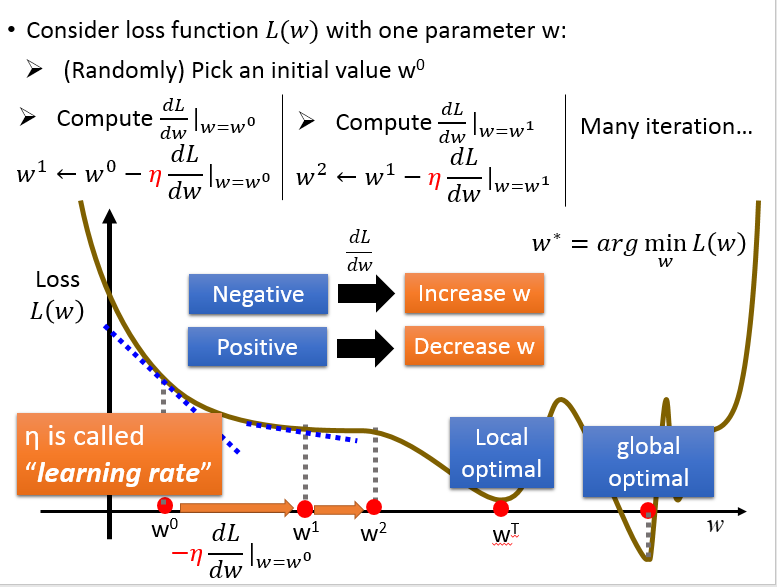
同时考虑 w, b 两个变量:

因为线性回归的损失函数总是一个凸函数,所以不用考虑局部最小,得到的就是全局最小。
对损失函数求导得到:

根据泰勒公式,考虑更多的项,得到如下的结果:(加了高次项依然是linear model,因为\(x_{cp}\)不是参数)

当收集到更多的数据后,会发现可能还有其他未考虑的因素,

可以对模型修正为,y = \(\delta(x_s)·(b + \sum w_i x_i)\),其中 \(\delta(x_s)\) 的取值是二元的。
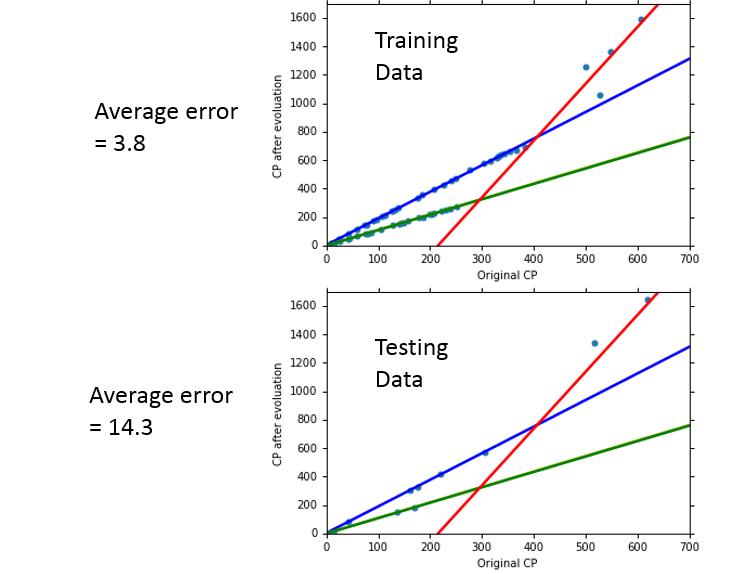
可以看到拟合的效果更好了,但是如果考虑的因素过多,则可能也会出现 Overfitting 的问题。
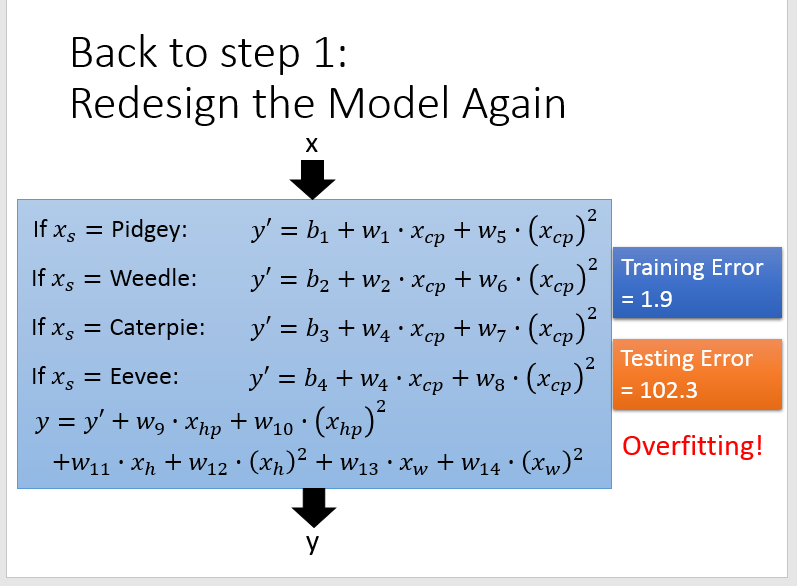
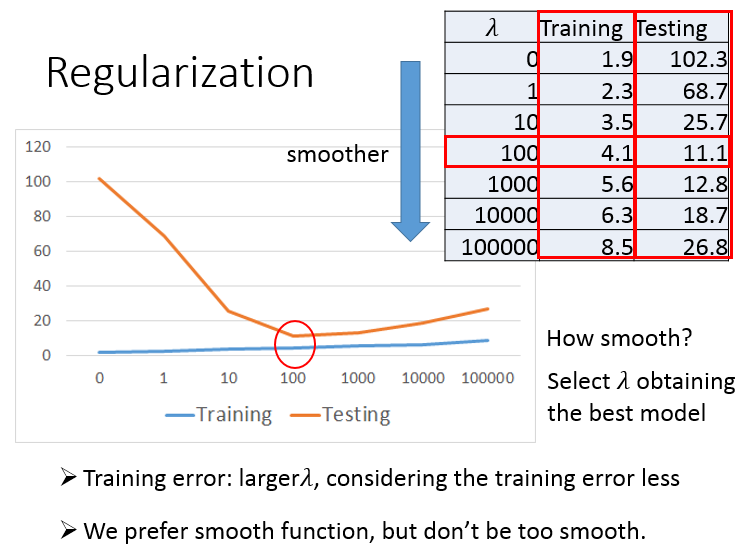
最后,还需要对损失函数做正则化操作,以使其在测试数据上表现更好。

调参数 \(\lambda\),\(\lambda\) 越大,曲线越平滑,对noise不那么敏感。
但是 \(\lambda\) 本质上是惩罚项,惩罚项太大,会使得参数空间变小,最后的结果也不会很好。
Demo程序:
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook
y_data, x_data -> \(\hat{y}\) 和 \(x_{cp}\) 值向量
x_data = [338.,333.,328.,207.,226.,25.,170.,60.,208.,606.]
y_data = [640.,633.,619.,393.,428.,27.,193.,66.,226.,1591.]
# ydata = b + w * xdata
x, y -> bias, weight
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
X, Y = np.meshgrid(x, y)
z -> L(w, b)
z = np.zeros((len(x), len(y)))
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
z[j][i] = z[j][i] + (y_data[n] - b - w*x_data[n])**2
z[j][i] = z[j][i] / len(x_data)
b = -120 # initial b
w = -4 # initial w
lr = 1 # learning rate
iteration = 1000000
# store initial value for plotting
b_history = [b]
w_history = [w]
lr_b = 0
lr_w = 0
# iteration
for i in tqdm_notebook(range(iteration)):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n])*1.0
w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n]
# AdaGrad
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
# update parameters
b = b - lr/np.sqrt(lr_b) * b_grad
w = w - lr/np.sqrt(lr_w) * w_grad
# b = b - lr*b_grad
# w = w - lr*w_grad
# store parameters for plotting
b_history.append(b)
w_history.append(w)
# plot the figure
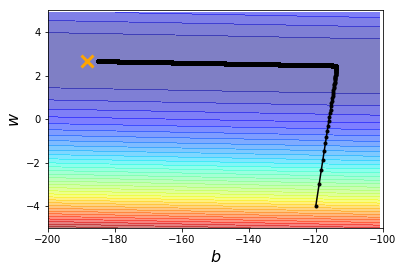
plt.contourf(x, y, z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
【笔记】机器学习 - 李宏毅 - 2 - Regression + Demo的更多相关文章
- 【笔记】机器学习 - 李宏毅 - 9 - Keras Demo
3.1 configuration 3.2 寻找最优网络参数 代码示例: # 1.Step 1 model = Sequential() model.add(Dense(input_dim=28*28 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: ML Lecture 1: Regression - Demo
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 【笔记】机器学习 - 李宏毅 - 6 - Logistic Regression
Logistic Regression 逻辑回归 逻辑回归与线性回归有很多相似的地方.后面会做对比,先将逻辑回归函数可视化一下. 与其所对应的损失函数如下,并将求max转换为min,并转换为求指数形式 ...
- 机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归. 视屏链接1-Introduction 视屏链接2-Regression 该课程将要介绍的内容如下所示: 从最左上角开始看: Regress ...
- [笔记]机器学习(Machine Learning) - 01.线性回归(Linear Regression)
线性回归属于回归问题.对于回归问题,解决流程为: 给定数据集中每个样本及其正确答案,选择一个模型函数h(hypothesis,假设),并为h找到适应数据的(未必是全局)最优解,即找出最优解下的h的参数 ...
- 【笔记】机器学习 - 李宏毅 - 11 - Keras Demo2 & Fizz Buzz
1. Keras Demo2 前节的Keras Demo代码: import numpy as np from keras.models import Sequential from keras.la ...
- 【笔记】机器学习 - 李宏毅 - 10 - Tips for Training DNN
神经网络的表现 在Training Set上表现不好 ----> 可能陷入局部最优 在Testing Set上表现不好 -----> Overfitting 过拟合 虽然在机器学习中,很容 ...
- 【笔记】机器学习 - 李宏毅 - 5 - Classification
Classification: Probabilistic Generative Model 分类:概率生成模型 如果说对于分类问题用回归的方法硬解,也就是说,将其连续化.比如 \(Class 1\) ...
- 【笔记】机器学习 - 李宏毅 - 1 - Introduction & next step
Machine Learning == Looking for a Function AI过程的解释:用户输入信息,计算机经过处理,输出反馈信息(输入输出信息的形式可以是文字.语音.图像等). 因为从 ...
随机推荐
- C语言遇到的关于清除标准输入缓冲区的问题[编程入门]
关于标准输入缓冲区的一个易犯的小错误 之前写了个简易的登录程序,但显然这不像写Java时那么容易(只要思路对,基本没问题).一不留神就出现了小BUG! 以下是错误的源代码: #include < ...
- java核心技术----访问权限
Java支持四种不同的访问权限: 修饰符 说明 public 共有的,对所有类可见 protected 受保护的,对同一包内的类和所有子类可见 private 私有的,在同一类内可见 默认的 在同一包 ...
- java设计模式5——适配器模式
java设计模式5--适配器模式 1.结构型模式介绍 1.1.作用 从程序的结构上实现松耦合,从而可以扩大整体的类结构,用来解决更大的问题. 分类: 适配器模式 代理模式 桥接模式 装饰模式 组合模式 ...
- Ubuntu下安装spark
方法一: jps 查看Java 包 sudo apt-get install openjdk** sudo apt-get install scala 选择安装源然后 sudo wget 下载链接 s ...
- python 使用记录
#print输出后不换行 #python2.x 中末尾加逗号,表示不换行,print 'contents', #python3.x 中默认print('contents',end='\n'),想要输出 ...
- JAVA SOCKET多线程等待接受客户端信息实现
服务端程序: public class Demo { public static void main(String[] args) { // TODO 自动生成的方法存根 try { ServerSo ...
- Docker Compose搭建Redis一主二从三哨兵高可用集群
一.Docker Compose介绍 https://docs.docker.com/compose/ Docker官方的网站是这样介绍Docker Compose的: Compose是用于定义和运行 ...
- PBFT 算法 java实现(下)
PBFT 算法的java实现(下) 在上一篇博客中(如果没有看上一篇博客建议去看上一篇博客),我们介绍了使用Java实现PBFT算法中节点的加入,view的同步等操作.在这篇博客中,我将介绍PBFT算 ...
- Vue子组件和根组件的关系
代码: <script type="text/javascript"> const Foo = Vue.extend({ template: `<div id=& ...
- clr via c# 程序集加载和反射(2)
查看,clr via c# 程序集加载和反射(1) 8,发现类型的成员: 字段,构造器,方法,属性,事件,嵌套类型都可以作为类型成员.其包含在抽象类MemberInfo中,封装了所有类型都有的一组属性 ...