Java容器解析系列(12) LinkedHashMap 详解
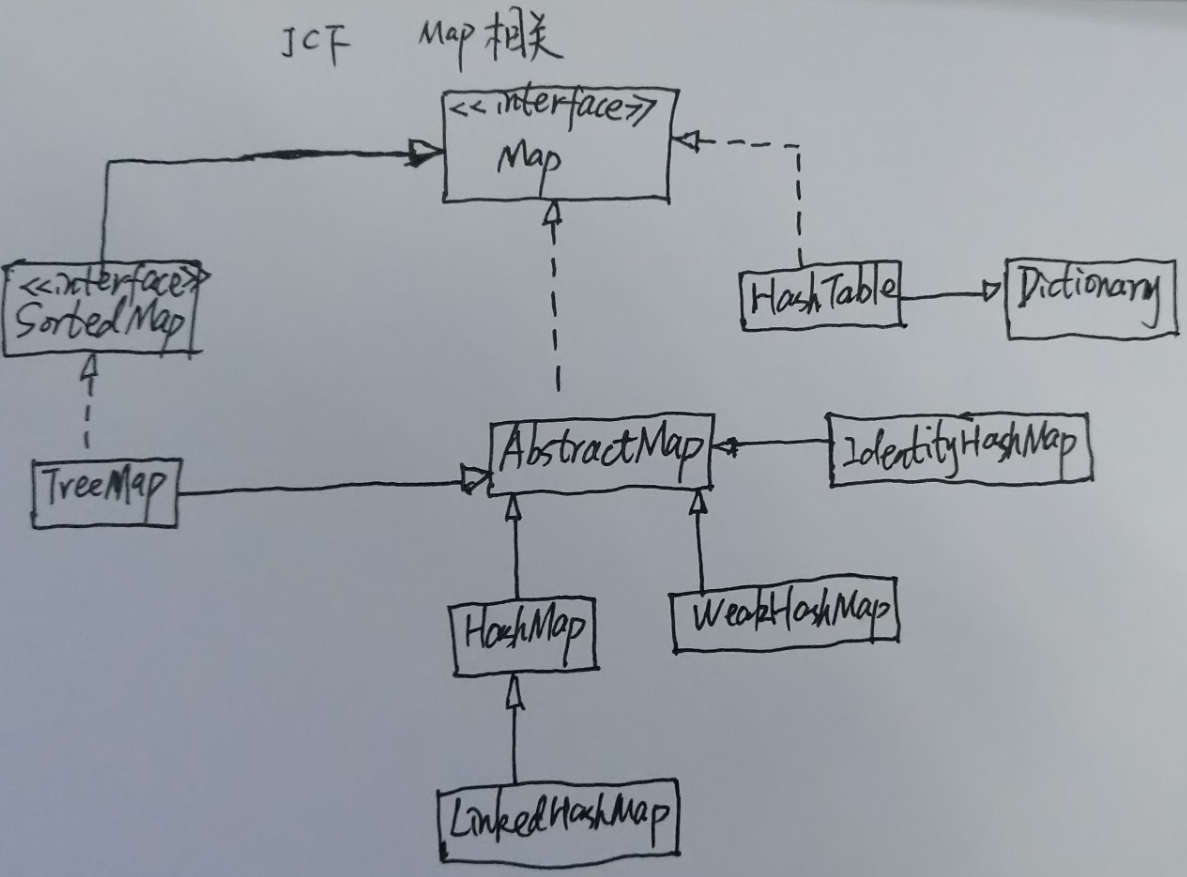
LinkedHashMap继承自HashMap,除了提供HashMap的功能外,LinkedHashMap还是维护一个双向链表(实际为带头结点的双向循环链表),持有所有的键值对的引用:
- 这个双向链表定义了迭代器的迭代顺序,默认按
插入顺序迭代; - 也可以在构造时设置为按照
LRU方式(访问顺序)迭代(from least-recently accessed to most-recently access-order),最近最少访问的键值对放在链表最前(头结点之后的第一个结点);
废话不多说,直接看源码:
// @since 1.4
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
private static final long serialVersionUID = 3801124242820219131L;
// 双向循环链表的头结点
private transient Entry<K,V> header;
// 迭代的顺序,按访问顺序(access-order)时为true,按插入顺序(insertion-order)时为false
private final boolean accessOrder;
public LinkedHashMap(int initialCapacity,float loadFactor){
super(initialCapacity,loadFactor);
// 默认为按插入顺序
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder){
super(initialCapacity,loadFactor);
this.accessOrder = accessOrder;
}
// 各种构造方法,省略...
// 构造器和伪构造器(包括clone(),readObject())中会调用该方法
void init(){
// 头结点
header = new Entry<>(-1,null,null,null);
header.before = header.after = header;
}
// 扩容时会调用该方法
void transfer(HashMap.Entry[] newTable,boolean rehash){
int newCapacity = newTable.length;
// 这里通过链表遍历,重新计算每个的hash值,而不是遍历hash表;
// 在扩容时,链表并没有发生变化;
for(Entry<K,V> e = header.after;e != header;e = e.after){
if(rehash){
e.hash = (e.key == null) ? 0 : hash(e.key);
}
int index = indexFor(e.hash,newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
// 通过链表来查找是否存在指定元素,这样更快一点
public boolean containsValue(Object value){
if(value == null){
for(Entry e = header.after;e != header;e = e.after)
if(e.value == null){
return true;
}
}else{
for(Entry e = header.after;e != header;e = e.after)
if(value.equals(e.value)){
return true;
}
}
return false;
}
public V get(Object key){
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if(e == null){
return null;
}
// 被访问的entry,在链表中排序
e.recordAccess(this);
return e.value;
}
// 清除所有元素时,也要将所有的entry从链表中删除,不再持有这些entry的引用
public void clear(){
super.clear();
header.before = header.after = header;
}
private static class Entry<K,V> extends HashMap.Entry<K,V>{
// 组成双向链表的指针
Entry<K,V> before, after;
Entry(int hash,K key,V value,HashMap.Entry<K,V> next){
super(hash,key,value,next);
}
// 在双向链表中移除当前结点
private void remove(){
before.after = after;
after.before = before;
}
// 在双向链表中指定结点之前插入当前结点
private void addBefore(Entry<K,V> existingEntry){
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
// 当map中的一个已有的entry的值被访问(get())或修改(put()修改已有key的value)时被调用
void recordAccess(HashMap<K,V> m){
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
// 如果LinkedHashMao是按访问顺序,这里会将被修改的entry移到链表最后面(头结点的前面);
// 否则什么都不干;
// 也就是最近被访问的,放在链表的最后;最近最少访问的(LRU),放在链表最前;
if(lm.accessOrder){
lm.modCount++;
remove();
addBefore(lm.header);
}
}
// 当前entry被从map中移除时被调用,在这里将当前结点从双向链表中移除
void recordRemoval(HashMap<K,V> m){
remove();
}
}
private abstract class LinkedHashIterator<T> implements Iterator<T>{
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
int expectedModCount = modCount;
public boolean hasNext(){
return nextEntry != header;
}
public void remove(){
if(lastReturned == null){
throw new IllegalStateException();
}
if(modCount != expectedModCount){
throw new ConcurrentModificationException();
}
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
// 通过链表顺序迭代
Entry<K,V> nextEntry(){
if(modCount != expectedModCount){
throw new ConcurrentModificationException();
}
if(nextEntry == header){
throw new NoSuchElementException();
}
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
private class KeyIterator extends LinkedHashIterator<K>{
public K next(){ return nextEntry().getKey(); }
}
private class ValueIterator extends LinkedHashIterator<V>{
public V next(){ return nextEntry().value; }
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>>{
public Map.Entry<K,V> next(){ return nextEntry(); }
}
Iterator<K> newKeyIterator(){ return new KeyIterator(); }
Iterator<V> newValueIterator(){ return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator(){ return new EntryIterator(); }
// put()会调用该方法
void addEntry(int hash,K key,V value,int bucketIndex){
super.addEntry(hash,key,value,bucketIndex);
Entry<K,V> eldest = header.after;
// 判断是否移除"最老"的元素;可以通过修改removeEldestEntry()的返回值来改变这一特性
// 默认不移除
if(removeEldestEntry(eldest)){
removeEntryForKey(eldest.key);
}
}
// put()中的addEntry()会调用该方法,将添加的entry放到链表尾
// 不管是按什么顺序(accessOrder),添加一个新entry时,都会将添加的entry放到链表尾,
// 因为新添加的entry即是最后插入的,也是是最近访问的
void createEntry(int hash,K key,V value,int bucketIndex){
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash,key,value,old);
table[bucketIndex] = e;
// 添加到链表尾
e.addBefore(header);
size++;
}
// 如果希望每次put()时,移除"最老"的结点,返回true,默认返回false
// "最老"的结点:如果为访问顺序,则为最久没被访问的结点;如果为插入顺序,则为最早被添加的元素;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest){
return false;
}
}
有上述源码可以看出,LinkedHashMap在HashMap的基础上,添加了如下特点:
- 插入的元素保持有序,使得遍历时是有序的;且这种顺序可以按照需要,配置为如下2种之一:
按
访问顺序:最近最少访问的在最前,最近访问的元素在最后;按
插入顺序:最早插入的元素在最前,最后添加的元素在最后;默认为按
插入顺序;
- 因为可以按照
访问顺序有序,所以可以用来支持LRU算法; - 可配置删除
最老的结点,在每次添加结点的时候,判断是否将链表最前的结点删除;
Java容器解析系列(12) LinkedHashMap 详解的更多相关文章
- Java容器解析系列(11) HashMap 详解
本篇我们来介绍一个最常用的Map结构--HashMap 关于HashMap,关于其基本原理,网上对其进行讲解的博客非常多,且很多都写的比较好,所以.... 这里直接贴上地址: 关于hash算法: Ha ...
- Java容器解析系列(13) WeakHashMap详解
关于WeakHashMap其实没有太多可说的,其与HashMap大致相同,区别就在于: 对每个key的引用方式为弱引用; 关于java4种引用方式,参考java Reference 网上很多说 弱引用 ...
- Java容器解析系列(7) ArrayDeque 详解
ArrayDeque,从名字上就可以看出来,其是通过数组实现的双端队列,我们先来看其源码: /** 有自动扩容机制; 不是线程安全的; 不允许添加null; 作为栈使用时比java.util.Stac ...
- Java容器解析系列(9) PrioriyQueue详解
PriorityQueue:优先级队列; 在介绍该类之前,我们需要先了解一种数据结构--堆,在有些书上也直接称之为优先队列: 堆(Heap)是是具有下列性质的完全二叉树:每个结点的值都 >= 其 ...
- Java容器解析系列(17) LruCache详解
在之前讲LinkedHashMap的时候,我们说起可以用来实现LRU(least recent used)算法,接下来我看一下其中的一个具体实现-----android sdk 中的LruCache. ...
- Java容器解析系列(14) IdentityHashMap详解
IdentityHashMap,使用什么的跟HashMap相同,主要不同点在于: 数据结构:使用一个数组table来存储 key:value,table[2k] 为key, table[2k + 1] ...
- Java容器解析系列(0) 开篇
最近刚好学习完成数据结构与算法相关内容: Data-Structures-and-Algorithm-Analysis 想结合Java中的容器类加深一下理解,因为之前对Java的容器类理解不是很深刻, ...
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- Java容器解析系列(10) Map AbstractMap 详解
前面介绍了List和Queue相关源码,这篇开始,我们先来学习一种java集合中的除Collection外的另一个分支------Map,这一分支的类图结构如下: 这里为什么不先介绍Set相关:因为很 ...
随机推荐
- 2019-8-31-dotnet-删除只读文件
title author date CreateTime categories dotnet 删除只读文件 lindexi 2019-08-31 16:55:58 +0800 2019-02-28 1 ...
- [vue/no-parsing-error] Parsing error: x-invalid-end-tag.eslint-plugin-vue
[vue/no-parsing-error] Parsing error: x-invalid-end-tag.eslint-plugin-vue 解决方案:vscode里面选择设置->搜索 ...
- 解决win10台式机插入耳机没有声音或者音量不大
没有声音 如果是插入机箱的前面板,尝试切换到后面板,因为有些组装机箱的前面板是不能用的 有声音,单音量不大(注意:并不一定适用于所有情况,但是可以尝试一下) 原因:缺少驱动,可以确定下控制面板是否有这 ...
- Android5_浅谈Java的package机制
当代码量越来越大,类越来越多.尤其会增加同名类的风险.所以对类进行管理就显得非常重要. 包(package)机制是java中管理类的重要手段. 包名的命名方式:业内默认的做法是使用公司的网络域名的倒写 ...
- JLINK、ULINK和STlink仿真器详解
JLink仿真器 德国SEGGER公司推出基于JTAG的仿真器.简单地说,是给一个JTAG协议转换盒,即一个小型USB到JTAG的转换盒,其连接到计算机用的是USB接口,而到目标板内部用的还是jtag ...
- 0012 sublime快捷操作emmet语法
Emmet的前身是Zen coding,它使用缩写,来提高html/css的编写速度. 生成标签 直接输入标签名 按tab键即可 比如 div 然后tab 键, 就可以生成 如果想要生成多个相同标签 ...
- kotlin + springboot启用elasticsearch搜索
参考自: http://how2j.cn/k/search-engine/search-engine-springboot/1791.html?p=78908 工具版本: elasticsearch ...
- docker常用命令(不包括run和build)
docekr 常用命令 :ls 列出容器 $ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE jdk fec5236a803b seconds ...
- 大数据(5)---分布式任务资源调度Yarn
前面也说到过的Yarn是hadoop体系中的资源调度平台.所以在整个hadoop的包里面自然也是有它的.这里我们就简单介绍下,并配置搭建yarn集群. 首先来说Yarn中有两大核心角色Resource ...
- js的class基础
title: js的class基础 date: 2020-01-04 13:34:44 tags: --- 基本写法 let log = console.log; class people { con ...