logstash 统计告警
在实际的项目中需要对线上日志做实时分析跟统计,这一套方案可以用现有的ELK(ElasticSearch, Logstash, Kibana)方案既可以满足,关于这个方案的具体的步骤可以参考网上的解决方案。但如果只想统计某个错误码(http状态码,业务错误码)在指定时间内出现多少次然后就触发一个告警或者某个指令动作(邮件或者是调用已经写好的http接口,例如例如微信平台来通知告警信息等),这种需求可以用logstash进行实现,并且这种方案比较轻量级,很容易实现。这里以在linux平台为主。
下载
首先下载 最新的logstash 压缩包,https://download.elastic.co/logstash/logstash/logstash-2.3.2.zip ,下载后用unzip命令进行解压只指定的目录,解压后会生成一个目录logstash-2.3.2 这个目录,里面包含下面这些文件:
基本配置
开始可以通过一个小的介绍了解logstash是怎么回事,链接里面有一些基本的demo,有兴趣可以参考里面的写一下。链接如下:
http://udn.yyuap.com/doc/logstash-best-practice-cn/get_start/hello_world.html
运行命令如下:
假设在与logstash 平级目录新建一个 配置文件,sample.conf ,这个配置文件就是定义 input filter output 这3块,其主要表示 input的来源是什么(文件或命令之类的),filter 代表对于输入的内容按照规则怎么来过滤,output 就是按照过滤的规则进行输出 。
最简单的写法如下:
# bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
如果是在sample.conf 中写入则如下:
input {
stdin{}
}
filter {
}
output {
stdout {}
}
# bin/logstash -f sample.conf
特殊配置
在实际的业务中可能往往要对日志做过滤,然后根据某些关键字段进行统计,通过统计结果来决定需要做什么。logstash 本身对于syslog,redis等日志在过滤的时候一般不需要自己写正则表达式去过滤,这些都是通用的,在filter中可以直接通过%{定义的常量}来获取日志内容,已经自动支持的过滤的日志包含下面这些:
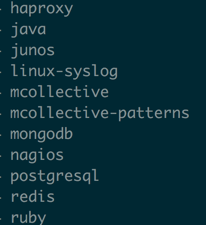
这个列表不全,对于已经支持的这些可以直接到github 上进行搜索(https://github.com/logstash/logstash/tree/v1.4.2/patterns),上面都有这些日志过滤的正则表达式,这些是属于通用配置。
往往在业务日志中,所打印的业务关键错误码以及格式并非与通用格式相匹配,那么此时就需要自己针对自己的业务日志格式,写出正则表达式来过滤自己想要的信息。
这里就以日志中的errno 来为例,所实现的目的就是 当这个错误码在30s内出现3次就把这个错误输出出来或告警。
在logstash中正则表达式叫做grok表达式,其规则跟perl与ruby的正则表达式一样。 也有在线的grok正则表达式校验工具:http://grokdebug.herokuapp.com/
这里就以下面的日志格式为例:log.txt
begin 10001 end
begin 10001 end
begin 10001 end
在sample.conf 中,grok 是写在filter 中的,这里既可以直接写正则表达式,也可以引用外部文件的正则表达。
方式1:
grok {
match => {
"message" => "\s+(?<code>\d+?)\s+"
}
}
方式2就是预先在 patterns/ 目录下创建一个文件,这个文件里面含有正则表达式,例如创建文件的名称为 test ,内容如下:
ERRORCODE \s+(?<code>\d+?)\s+
grok {
patterns_dir => "../../patterns/test"
match => ["message", "%{ERRORCODE:code:int}"]
}:
很显然这里我们习惯采用方式2,因为正则匹配相关的可以单独在一个文件,在sample.conf 就直接引用正则匹配中字段值,例如上面就直接用"ERRORCODE", message 中%后面花括号中的写法规则如下:
%{PATTERN_NAME:capture_name:data_type}
以上面完子为例,完整的 sample.conf 内容如下:
input {
# 以日志文件作为来源
file {
# 文件路径
path => "../../log.txt"
}
}
filter {
# 正则解析
grok {
# 增加自定义的正则,这里我把自定义的正则文件,加在了这个目录下
patterns_dir => "../../patterns/test"
# 从message字段中解析出 code
match => ["message", "%{ERRORCODE:code:int}"]
# 删除原来的message字段
remove_field => [ "message" ]
# 增加WARN,作为标记
add_tag => "warn"
}
# 计数
metrics {
# 计数器数据保存的字段名 code的值就是上面解析出来的
meter => "events_%{code}"
# 增加"metric",作为标记
add_tag => "metric"
# 3秒内的message数据才统计,避免延迟
# ignore_older_than =>
# 每隔300秒统计一次
flush_interval => ""
# 每301秒清空计数器
clear_interval => ""
}
# 如果event中标记为“metric”的
if "metric" in [tags] {
# 执行ruby代码
ruby {
# 如果count为10001的数量小于3条,就忽略此事件(即不发送任何消息)。
code => "event.cancel if event['events_10001']['count'] < 3"
}
}
}
output {
# 输出到console
stdout {
codec => rubydebug
}
}
上面配置结束后,由于开启 debug 模式,所以当每次往 log.txt 写入 "begin 10001 end" 在控制台下都会有输出,输入内容下:
{
"@version" => "",
"@timestamp" => "2016-11-14T13:14:14.374Z",
"path" => "../../log.txt",
"host" => "xxxx",
"code" => "",
"tags" => [
[] "warn"
]
}
当在30s内输入的次数大于3次的时候,输出的内容如下:
{
"@version" => "",
"@timestamp" => "2016-11-14T13:14:20.148Z",
"message" => "xxx",
"events_" => {
"WARN" => {
"count" => ,
"rate_1m" => 2.1864058457089883,
"rate_5m" => 3.814999397602868,
"rate_15m" => 4.1951645878441255
}
},
"tags" => [
[] "metric"
]
}
通过上面的结构可以看出我们在输出的时候还可以写表达式,例如只有当30s内大于3次才输出信息的话可以在 output 中加一个判断,逻辑如下:
output {
# 如果event中标记为“metric”,表示只发送计数的消息。
if "metric" in [tags] {
# 执行一个简单的命令
exec {
command => "echo \"hello: %{events_10001.count}\""
}
}
}
到这里已经结束,关于logstash中的 统计相关的规则可以参考:http://udn.yyuap.com/doc/logstash-best-practice-cn/filter/metrics.html
输出的形式也是多种的 可以对接ES,触发http接口,这里就以输出为例。
logstash 统计告警的更多相关文章
- [elk]logstash统计api访问失败率
处理原始日志 日志从moogoo导出来的 { "mobile" : "13612345678", "isp" : "中国移动_广东 ...
- ELK之logstash收集日志写入redis及读取redis
logstash->redis->logstash->elasticsearch 1.安装部署redis cd /usr/local/src wget http://download ...
- python3.x 多路IO复用补充asyncio
asyncio模块是python之父写的模块,按说应该是靠谱的,python3.6版本定义为稳定版本. 说明书:https://docs.python.org/3/library/asyncio.ht ...
- 关于ETH/BTC区块的监控
此次我写的是一个小型的shell, 链接钉钉的机器人, 使用过的应该会比较娴熟的了,下面就简述一下把 主要的功能就是, 当发现本地数据库区块跟网络上的区块差距相差较大的时候就代表, 数据同步有问题, ...
- 运维和shell
什么是运维 术语名词 IDC--(Internet Data Center)互联网数据中心,主要服务包括整机租用.服务器托管.机柜租用.机房租用.专线接入和网络管理服务等.广义上的IDC业务,实际上就 ...
- 李阳:京东零售OLAP平台建设和场景实践
导读: 今天和大家分享京东零售OLAP平台的建设和场景的实践,主要包括四大部分: 管控面建设 优化技巧 典型业务 大促备战 -- 01 管控面建设 1. 管控面介绍 管控面可以提供高可靠高效可持续运维 ...
- Zabbix中获取各用户告警媒介分钟级统计
任务内容: 获取Zabbix各用户告警媒介分钟级统计,形成趋势图,便于观察各用户在每分钟收到的告警数量,在后续处理中,可以根据用户在某时间段内(例如3分钟内)收到的邮件总数,来判断是否有告警洪水的现象 ...
- 用logstash 作数据的聚合统计
用logstash 作数据的聚合统计 以spark-streaming 处理消费数据,统计日志经spark sql存储在mysql中 日志写入方式为append val wordsDataFrame ...
- 自动统计zabbix过去一周监控告警
# -*- coding:utf-8 -*-import jsonimport requestsimport time,datetimeimport csv,chardetdef getToken(u ...
随机推荐
- star
Astronomers often examine star maps where stars are represented by points on a plane and each star h ...
- 如何将你自己的Python package发布到PyPI上
零.前言 最近做了一个小工具,查询IP或者域名的归属地.做完之后想发布到PyPI上,这样大家就可以通过pip来安装了. 在发布的过程中遇到了一些问题,也学到了很多东西.记录到这篇文章中.希望对大家有所 ...
- VMware系统运维(十六)部署虚拟化桌面 Horizon View Manager 5.2 配置池
1.点击"添加",打开添加池界面,选择"自动池",点击"下一步" 2.选择"专用,启动自动分配",点击"下一步 ...
- 分享一款简洁的jQuery轮播源码
<html xmlns="http://www.w3.org/1999/xhtml" > <head> <title>无标题页</titl ...
- 服务器调用JS
服务器控件调用JS一.两类JS的触发设计1.提交之前的JS -- 加js的事件例:<script language="javascript"> // 构造函数 func ...
- loadrunner协议的选择
1. 任何高级协议的底层都是用Winsocket通信 2. 不管你系统中有多少个服务器,lr录制的始终是客户端与第一个服务器之间的通信内容, 客户端用IE访问的一般都选http协议(对于常见的,b ...
- Macbook之用brew安装Python
1. brew install python 2.If you don't have ~/.bash_profile, add ~/.bash_profile by touch ~/.bash_pro ...
- WebStorm10下载、安装
WebStorm是最专业的前端IDE开发工具 官网下载:http://www.jetbrains.com/webstorm/ 配置和快捷键
- ado模版不会自动生成
从数据库中更新模版的时候,其他文件都更新了,只有tt文件下的cs文件是没有更新的,没有添加也没有修改,在网上找了很久都没有这方面的信息. 其实只要删掉,重建一个ado模版就好.根本就不需要纠结.最后还 ...
- Programmer's Jokes
1. 一天, 下着小雨, 和同事们一起去上班,一位同事差点滑倒,另一位同事笑话说:如果人走路用爬的就不会摔倒了! 遂反问他:能用两行代码搞定的事情为什么要用4行呢? 2. 有趣的公式( Fr ...