第22章 项目3:万能的XML
Mix-in:混入类,是一种Python程序设计中的技术,作用是在运行期间动态改变类的基类或类的方法,从而使得类的表现可以发生变化。可以用在一个通用类接口中。
在实践一个解析XML文件的实践中,体会动态改变的格式。
格式一般是:
定义一个基类:
class base:
def startElement(self,prefix,name,*args):
self.callback('Start',name,*args)
def callback(self,prefx,name,*args):
mname = prefix + name
method = getattr(self,mname,None)
if callbale(method): method(*args)
然后定义一个子类,在里面实现prefix+name的方法。
处理xml的内置库:
from xml.sax.hander import ContentHandler
from xml.sax import parse
parse('xmlfile', instanceofContentHandler)
首先检查是否有可用的SAX语法分析器:
from xml.sax import make_parser
parser = make_parser
没有引发任何异常,可以使用。

20-1 用XML文件表示的简单网站 website.xml
<website>
<page name="index" title="Home Page">
<h1>Welcome to My Home Page</h1>
<p>Hi, there. My name is Mr. Gumby, and this is my home page. Here
are some of my interests:</p>
<ul>
<li><a herf="interests/shouting.html">Shouting</a></li>
<li><a herf="interests/sleeping.html">Sleeping</a></li>
<li><a herf="interests/eating.html">Eating</a></li>
</ul>
</page>
<directory name="interests">
<page name="shouting" title="Shouting">
<h1>Mr. Gumby's Shouting Page</h1>
<p>...</p>
</page>
<page name="sleeping" title="Sleeping">
<h1>Mr. Gumby's Sleeping Page </h1>
<p>...</p>
</page>
<page name="eating" title="Eating">
<h1>Mr. Gumby's Eating Page </h1>
<p>...</p>
</page>
</directory>
</website>
最小型的XML语法分析器:web1.py
# coding=utf-8
from xml.sax.handler import ContentHandler
from xml.sax import parse
# ContentHandler是内容处理器,实现了所以需要的事件处理程序(没有任何效果的伪操作)
class TestHandler(ContentHandler): pass
parse('website.xml', TestHandler()) # parse负责读取文件并生成事件
执行之后,未报错也无输出

简单的扩展 web2.py
将def startElement(self, name, attrs):
print name, attrs.keys()
添加到类TestHandler中# coding=utf-8
from xml.sax.handler import ContentHandler
from xml.sax import parse
class TestHandler(ContentHandler):
def startElement(self, name, attrs): # 参数分别是相应的标签名及其特性
print name, attrs.keys()
parse('website.xml', TestHandler())
 输出:
输出:
website []
page [u'name', u'title']
h1 []
p []
ul []
li []
a [u'herf']
li []
a [u'herf']
li []
a [u'herf']
directory [u'name']
page [u'name', u'title']
h1 []
p []
page [u'name', u'title']
h1 []
p []
page [u'name', u'title']
h1 []
p []
建立网站大标题(h1元素列表) web3.py
使用startElement,endElement和characters三种方法
# coding=utf-8
from xml.sax.handler import ContentHandler
from xml.sax import parse
class HeadHandler(ContentHandler):
in_headline = False
def __init__(self, headlines):
ContentHandler.__init__(self)
self.headlines = headlines
self.data = []
def startElement(self, name, attrs):
if name == 'h1':
self.in_headline = True
def endElement(self, name): # endElement只用标签名作为参数
if name == 'h1':
text = ''.join(self.data)
self. data = []
self.headlines.append(text)
self.in_headline = False
def characters(self, string): # characters使用字符串作为参数
if self.in_headline:
self.data.append(string)
headlines = []
parse('website.xml', HeadHandler(headlines))
print 'The following <h1> elements were found:'
for h in headlines:
print h
 输出:
输出:
The following <h1> elements were found:
Welcome to My Home Page
Mr. Gumby's Shouting Page
Mr. Gumby's Sleeping Page
Mr. Gumby's Eating Page
22-2 pagemaker.py
生成4个HTML文件:

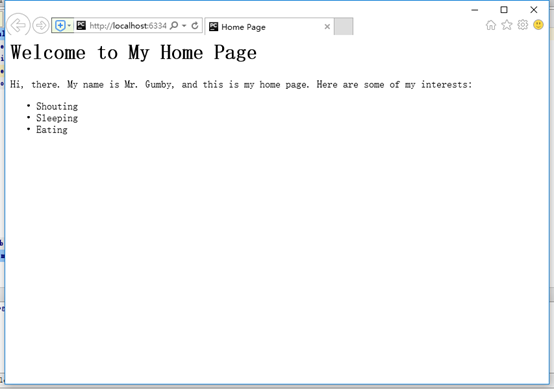
index.html
<html><head>
<title>Home Page</title>
</head><body>
<h1>Welcome to My Home Page</h1>
<p>Hi, there. My name is Mr. Gumby, and this is my home page. Here
are some of my interests:</p>
<ul>
<li><a herf="interests/shouting.html">Shouting</a></li>
<li><a herf="interests/sleeping.html">Sleeping</a></li>
<li><a herf="interests/eating.html">Eating</a></li>
</ul>
</body></html>

22-3 网站构造函数(website.py)
调度程序的混入类
基本事件处理程序:
class Dispatcher:
#...
def startElement(self, name, attrs):
self.dispatch('start', name, attrs)
def endElement(self, name):
self.dispatch('end', name)
dispatch()方法:
查找合适的处理程序,构造参数元组,然后使用这些参数调用处理程序。
def dispatch(self, prefix, name, attrs=None):
mname = prefix + name.capitalize()
dname= 'default' + prefix.capitalize()
method =getattr(self, mname, None)
if callable(method): args = ()
else:
method = getattr(self, dname, None)
args = name
if prefix == 'start': args += attrs,
if callable(method) :method(*args)
以上程序是这样构造的:首先获取组合函数名(mname,dname),然后判断是否存在这样的函数(callable),存在就是startname,endname否则是defaultname
内容处理程序:
class TestHandler(Dispatcher, ContentHandler):
def startPage(self, attrs):
print 'Begining page', attrs['name']
def endPage(self):
print 'Ending page'
以上内容写入webTest.py
# coding=utf-8
from xml.sax.handler import ContentHandler
class Dispatcher:
#查找合适的处理程序,构造参数元组,然后使用这些参数调用处理程序。
def dispatch(self, prefix, name, attrs=None):
mname = prefix + name.capitalize()
dname = 'default' + prefix.capitalize()
method = getattr(self, mname, None)
if callable(method):
args = ()
else:
method = getattr(self, dname, None)
args = name
if prefix == 'start': args += attrs,
if callable(method): method(*args)
# 基本事件处理程序:
def startElement(self, name, attrs):
self.dispatch('start', name, attrs)
def endElement(self, name):
self.dispatch('end', name)
# 内容处理程序
class TestHeanler(Dispatcher, ContentHandler):
def startPage(self, attrs):
print 'Begining page', attrs['name']
def endPage(self):
print 'Ending page'
运行无输出,也没有报错。
该调度程序混入类实现了大部分的探测功能,下面添加更多功能。
22-3 网站构造函数 website.py
# coding=utf-8
from xml.sax.handler import ContentHandler
from xml.sax import parse
import os
class Dispatcher:
"""
是一个混合类,和第一个项目中有相似之处,因为要处理不同的标记,所以
通过前缀名来指定处理函数更加方便。利用混合类管理一些细节也很容易
"""
# dispatch()方法,用于查找合适的处理程序,构造参数元组,然后使用这些参数调用处理程序。
def dispatch(self, prefix, name, attrs=None):
"""
在调用各种处理方法时,先判断这个方法是否存在,有则直接调用相应的函数,没有就把属性和名称都添加到一个元组中,
并调用一个默认函数,也就是说忽略其他的标签,不做特殊处理,直接按原样输出即可。
"""
mname = prefix + name.capitalize()
dname= 'default' + prefix.capitalize()
method = getattr(self, mname, None)
if callable(method): args = ()
else:
method = getattr(self, dname, None)
args = name,
if prefix == 'start': args += attrs, # 这里需要注意,要加上逗号
if callable(method): method(*args)
# 基本事件处理程序:
def startElement(self, name, attrs):
self.dispatch('start', name, attrs)
def endElement(self, name):
self.dispatch('end', name)
class WebsiteConstructor(Dispatcher, ContentHandler):
"""
内容处理程序:
在利用SAX在解析XML文件时,要用到Parser这个函数,这个函数在读取文件以及处理这些文件时,要相应的利用一些时间处理程序。
继承CotentHandler是因为这个类中实现了几乎所有时间处理程序,当然也可以在本程序中重写里面的时间处理函数来进行覆盖使用。
"""
passthrough= False # 设定布尔变量,处理特殊标签时由于要忽略一些内部标签及特殊处理,需要判断文件解析器是否要停止处理。
# 构造函数,网站的根目录作为参数
def __init__(self, directory):
self.directory = [directory]
self.ensureDirectory()
# 这个函数主要利用os模块中对文件操作的特性,为xml文件中每一个页面都创建一个相应目录存放html文件,确保当前目录存在
def ensureDirectory(self):
path = os.path.join(*self.directory)
if not os.path.isdir(path): os.makedirs(path) # 如果没有这个路径就创建
def characters(self, chars):
if self.passthrough: self.out.write(chars)
# 使用defaultStart和defaultEnd对XHTML进行处理,两个默认的函数都是处理页面标签中的一些其他标签。
# 这些页面中的所有标签在这里都做了忽略处理
def defaultStart(self, name, attrs):
if self.passthrough:
self.out.write('<' + name)
for key, val in attrs.items():
self.out.write(' %s="%s"' % (key, val,))
self.out.write('>')
def defaultEnd(self, name):
if self.passthrough:
self.out.write('</%s>' % name)
# 目录处理程序,使用directory和ensureDirectory方法。这两个函数是为了在xml文件中碰见不同的目录要进行创建,
# 但是创建之后要删除,避免不同目录的页面最后出现在同样的目录下面
def startDirectory(self, attrs):
self.directory.append(attrs['name'])
self.ensureDirectory()
def endDirectory(self):
self.directory.pop()
# 页面处理程序,使用writeHeader和writeFooter方法,设定passthrough变量,打开和关闭与页面关联的文件。
# 两个函数要处理页面,创建这个页面的html文件,然后添加上标题,打开这个文件,写入文件之后在关闭
def startPage(self, attrs):
filename = os.path.join(*self.directory + [attrs['name'] + '.html'])
self.out = open(filename, 'w')
self.writeHeader(attrs['title'])
self.passthrough = True
def endPage(self):
self.passthrough = False
self.writeFooter()
self.out.close()
# 简单的首部和页脚
def writeHeader(self, title):
self.out.write('<html>\n <head>\n <title>')
self.out.write(title)
self.out.write('</title>\n </head>\n <body>\n')
def writeFooter(self):
self.out.write('\n </body>\n</html>\n')
parse('website.xml', WebsiteConstructor('public_html'))
首先是从parse('website.xml', WebsiteConstructor('public_html'))开始,然后是进入WebsiteConstructor中,首先执行__init__函数创建public_html目录,然后开始startElement函数,并调用dispatch判断WebsiteConstructor是否有所需的函数,判断后进行程序运行,其中name为directory则创建目录,否则就在文档里面写入语句,对于在文档中写入语句的多少依据passthrough判断。控制函数为characters函数。
运行输出:index.html和public文件夹及包括eating.html、shouting.html、sleepting.html的interests子文件夹

打开public_html/index.html
第22章 项目3:万能的XML的更多相关文章
- 转 web项目中的web.xml元素解析
转 web项目中的web.xml元素解析 发表于1年前(2014-11-26 15:45) 阅读(497) | 评论(0) 16人收藏此文章, 我要收藏 赞0 上海源创会5月15日与你相约[玫瑰里 ...
- [Real World Haskell翻译]第22章 扩展示例:Web客户端编程
第22章 扩展示例:Web客户端编程 至此,您已经看到了如何与数据库交互,解析一些数据,以及处理错误.现在让我们更进了一步,引入Web客户端库的组合. 在本章,我们将开发一个真正的应用程序:一个播客下 ...
- 安卓权威编程指南-笔记(第22章 深入学习intent和任务)
本章,我们会使用隐式intent创建一个替换android默认启动器的应用.名为NerdLauncher. NerdLauncher应用能列出设备上的其他应用,点选任意列表项会启动相应应用. 1. 解 ...
- Maven项目中的pom.xml详解【转】
什么是pom? pom作为项目对象模型.通过xml表示maven项目,使用pom.xml来实现.主要描述了项目:包括配置文件:开发者需要遵循的规则,缺陷管理系统,组织和licenses,项目的url, ...
- 举例android项目中的string.xml出现这个The character reference must end with the ';' delimiter.错误提示的原因及解决办法
今天在一个android项目中的string.xml中写这样一个字符串时出现了下面这个错误提示: The reference to entity "说明" must end wit ...
- 第22章 职责链模式(Chain of Responsibility)
原文 第22章 职责链模式(Chain of Responsibility) 职责链模式 导读:职责链模式是一个既简单又复杂的设计模式,刚开始学习这个设计模式的时候光示例都看了好几遍.就为了理清里面的 ...
- Gradle 1.12用户指南翻译——第四十一章. 项目报告插件
本文由CSDN博客万一博主翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- IntelliJ IDEA中项目报错org.xml.sax.SAXParseException; lineNumber: 3; columnNumber: 8 或maven操作compile报resource使用utf8这样的编码错
问题:项目开发工具已经setting成utf-8 并且项目各方面的配置文件包括maven这些的pom.xml里的配置都已经设置为utf-8 但是还报错 IntelliJ IDEA中项目报错org.xm ...
- 【RL-TCPnet网络教程】第22章 RL-TCPnet之网络协议IP
第22章 RL-TCPnet之网络协议IP 本章节为大家讲解IP(Internet Protocol,网络协议),通过前面章节对TCP和UDP的学习,需要大家对IP也有个基础的认识. (本章 ...
随机推荐
- Debian 8 安装 Nvidia 显卡驱动
sudo apt-get install linux-headers-$(uname -r|sed 's,[^-]*-[^-]*-,,') nvidia-kernel-dkms 正在读取软件包列表.. ...
- leetcode 题解Merge Two Sorted Lists(有序链表归并)
题目: Merge two sorted linked lists and return it as a new list. The new list should be made by splici ...
- BZOJ 1040: [ZJOI2008]骑士 基环加外向树
1040: [ZJOI2008]骑士 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1190 Solved: 465[Submit][Status] ...
- LPSTR、LPCSTR、LPWSTR、LPCWSTR、LPTSTR、LPCTSTR的来源及意义
1. Unicode字符集: 它是用两个字节表示一个字符的方法.比如字符'A'在ASCII下面是一个字符,可'A'在UNICODE下面是两个字符,高字符用0填充,而且汉字'程'在ASCII下面是两个字 ...
- 如何优雅地制作精排 ePub —— 个人电子书制作规范及基本样式表
随着大数据时代的到来,多种移动阅读终端方兴未艾 —— Amazon Kindle不再小众.各互联网巨头纷纷推出旗下的电子书阅读软件.有了阅读的软件/硬件支持,必不可少的就是阅读什么的问题了.ePub格 ...
- asp.net Calendar 日历控件用法
asp.net Calendar 是微软自带的一款日历控件,除了简单显示日期时间外, 还可以绑定一些需要的事件. Calendar_DayRender 事件,是在加载都去时间日期时候的方法,用此方法可 ...
- 表数据转换为insert语句
/* 对象:导出物理表数据为Insert语句 描述:可以传递条件精确导出sql 加条件的前提是只知道相应的字段名及类型 */ from sysobjects where name ='proc_ins ...
- js使用CSS将图片转换成黑白(灰色、置灰)
详细内容请点击 可能早就知道,像汶川这种糟糕的日子网站全灰在IE下是可以轻松实现的(filter: gray;),不过,当时,其他浏览器是无解的. 不过,时代发展,如今,CSS3的逐步推进,我们也开始 ...
- django 学习-15 .Django文件上传(用户注册)
1.vim blog/views.py from django.shortcuts import render_to_responsefrom django.http import HttpR ...
- 布料解算插件 Qualoth 重点参数分享
前言 Qualoth是韩国FXGear公司推出的一款布料模拟插件,可以计算出很自然的衣褶以及动态效果,并且能应对大幅度动作的碰撞解算,可以和Houdini的Cloth Solver相媲美: 目前这款插 ...