MapReduce编程系列 — 1:计算单词
1、代码:
package com.mrdemo; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000");
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2、准备测试数据。
hello hadoop
jobtracker
maptracker
reducetracker
task
namenode
datanode
block
beautiful world
hadoop:
HDFS
MapReduce
3、命令
hdfs://localhost:9000/user/yyq/output01
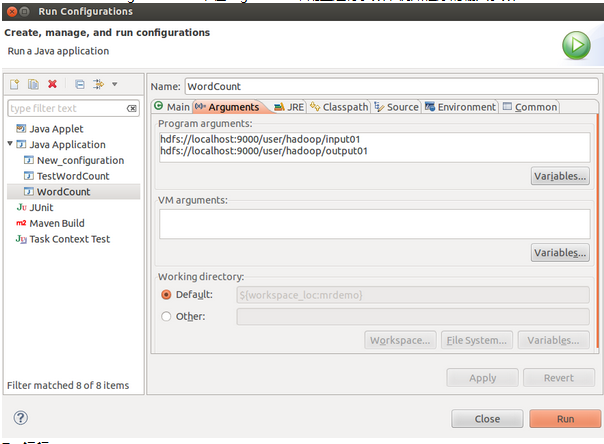
4、配置运行参数
Run As → Run Configurations… ,在Arguments中配置运行参数,例如程序的输入参数:
MapReduce编程系列 — 1:计算单词的更多相关文章
- MapReduce编程系列 — 2:计算平均分
1.项目名称: 2.程序代码: package com.averagescorecount; import java.io.IOException; import java.util.Iterator ...
- 【原创】MapReduce编程系列之二元排序
普通排序实现 普通排序的实现利用了按姓名的排序,调用了默认的对key的HashPartition函数来实现数据的分组.partition操作之后写入磁盘时会对数据进行排序操作(对一个分区内的数据作排序 ...
- MapReduce编程系列 — 6:多表关联
1.项目名称: 2.程序代码: 版本一(详细版): package com.mtjoin; import java.io.IOException; import java.util.Iterator; ...
- MapReduce编程系列 — 5:单表关联
1.项目名称: 2.项目数据: chile parentTom LucyTom JackJone LucyJone JackLucy MaryLucy Ben ...
- MapReduce编程系列 — 4:排序
1.项目名称: 2.程序代码: package com.sort; import java.io.IOException; import org.apache.hadoop.conf.Configur ...
- MapReduce编程系列 — 3:数据去重
1.项目名称: 2.程序代码: package com.dedup; import java.io.IOException; import org.apache.hadoop.conf.Configu ...
- 【原创】MapReduce编程系列之表连接
问题描述 需要连接的表如下:其中左边是child,右边是parent,我们要做的是找出grandchild和grandparent的对应关系,为此需要进行表的连接. Tom Lucy Tom Jim ...
- MapReduce 编程 系列九 Reducer数目
本篇介绍怎样控制reduce的数目.前面观察结果文件,都会发现通常是以part-r-00000 形式出现多个文件,事实上这个reducer的数目有关系.reducer数目多,结果文件数目就多. 在初始 ...
- MapReduce 编程 系列七 MapReduce程序日志查看
首先,假设须要打印日志,不须要用log4j这些东西,直接用System.out.println就可以,这些输出到stdout的日志信息能够在jobtracker网站终于找到. 其次,假设在main函数 ...
随机推荐
- 再说 extern "C"
早知道 C++ 源文件中要调用C语言函数需要在函数申明时 指定extern "C": 要不然可以编译通过,但连接时提示找不到什么什么符号,原因是C和C++生成的函数名不一样,ext ...
- 基数排序(RadixSort)
1 基数排序的特点是研究多个关键字key,且多个key之间有权重之分, 或者可把单个key建模为含有多个key的排序 而计数排序.桶排序始终只有个一个key,或者说围绕着一个比较规则 Ex:比较 ...
- HTML5之 Microdata微数据
- 为何需要微数据 长篇加累版牍,不好理解 微标记来标注其中内容,让其容易识辨 - RDFa Resource Description Framework http://www.w3.org/TR/m ...
- 关于C++引用的一些注意点
C++的引用首先跟指针的最大区别就是引用不是一个对象,而指针是一个对象:其次引用在其定义时就要初始化,而指针可以不用. ; int &rval = val; 此时rval就绑定了val,其实就 ...
- Linux 服务器如何禁止 ping 以及开启 ping
Linux 默认是允许 ping 响应的,也就是说 ping 是开启的,但 ping 有可能是网络攻击的开始之处,所以关闭 ping 可以提高服务器的安全系数.系统是否允许 ping 由2个因素决定的 ...
- 用 .htaccess 实现网址规范化
网址规范化在 SEO 中是一个比较重要的环节,同时存在不同的网址版本,不但可能造成内容重复,还不能正确的集中权重.目前大多数网站,绑定的域名都有带 www 和不带两个版本,甚至很多网站同时绑定多个域名 ...
- 最简便的清空memcache的方法
如果要清空memcache的items,常用的办法是什么?杀掉重启?如果有n台memcache需要重启怎么办?挨个做一遍? 很简单,假设memcached运行在本地的11211端口,那么跑一下命令行: ...
- 6个好用的Web开发工具
在过去的几年间,涌现出了很多Web开发工具,它们大多还是比较吸引人的,方便了我们的工作.我们可以学习一下这些新东西,短时间就可以拓宽思路(PHP100推荐:学习10分钟,改变你的程序员生涯).这些应用 ...
- String类源码分析(JDK1.7)
以下学习根据JDK1.7String类源代码做注释 public final class String implements java.io.Serializable, Comparable<S ...
- ubuntu12.04 server + apache2 + wsgi + django1.6 部署
最近在学Python和Django,想自己部署一个服务器试试 环境:ubuntu12.04 server | apache2 | django1.6 | python2.7 | mod_wsgi 在网 ...