python爬虫 scrapy1-安装及创建第一个项目
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频)

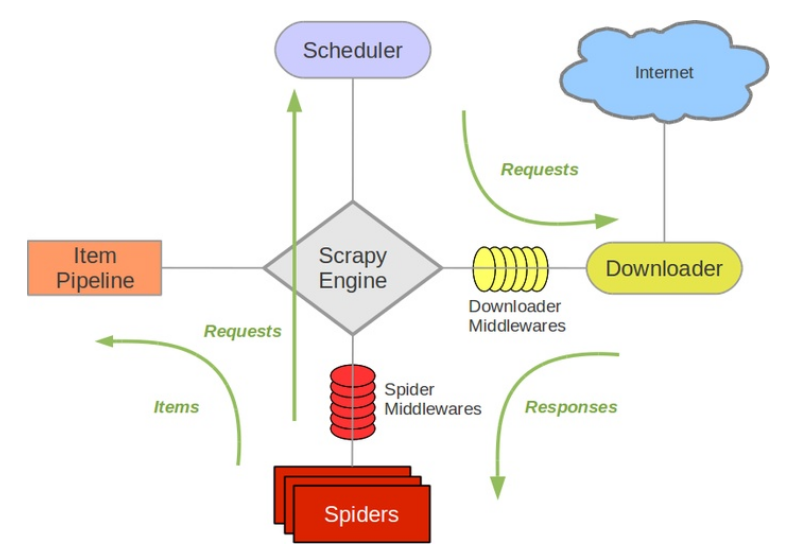
架构概览
各组件作用
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
此组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流(Data flow)
引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下一个要爬取的URL。
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
1. 安装scrapy
cmd 管理员权限进去
pip install scrapy 会出错
用conda install scrapy 安装,解决依赖关系,成功安装
2.创建爬虫项目
在桌面上创建一个Python_project文件夹
cmd 切换目录到Python_project文件夹
在开始爬取之前,首先要创建一个新的Scrapy项目。这里以爬取我的博客为例,进入你打算存储代码的目录中,运行下列命令:
crapy startproject scrapyspider然后就会生成scrapyspider文件到Python_project文件夹里
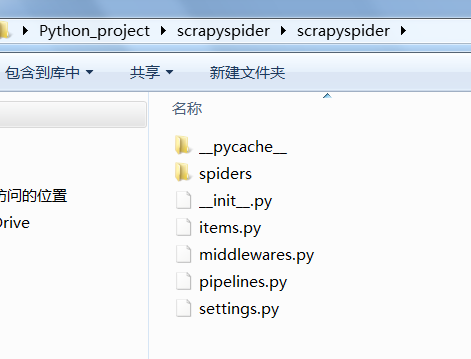
该命令将会创建包含下列内容的scrapyspider目录:
scrapyspider/
scrapy.cfg
scrapyspider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- scrapyspider/: 该项目的python模块。之后您将在此加入代码。
- scrapyspider/items.py: 项目中的item文件。
- scrapyspider/pipelines.py: 项目中的pipelines文件。
- scrapyspider/settings.py: 项目的设置文件。
- scrapyspider/spiders/: 放置spider代码的目录。
3.编写第一个爬虫(Spider)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
以下为我们的第一个Spider代码,保存在scrapyspider/spiders目录下的blog_spider.py文件中:
from scrapy.spiders import Spider class BlogSpider(Spider):
name = 'woodenrobot'
start_urls = ['http://woodenrobot.me'] def parse(self, response):
titles = response.xpath('//a[@class="post-title-link"]/text()').extract()
for title in titles:
print title.strip()
4.启动爬虫
打开终端进入项目所在路径(即:scrapyspider路径下)运行下列命令:
scrapy crawl woodenrobot
启动爬虫后就可以看到打印出来当前页所有文章标题了。

python爬虫 scrapy1-安装及创建第一个项目的更多相关文章
- Angular安装及创建第一个项目
Angular简介 AngularJS 诞生于2009年,由Misko Hevery 等人创建,后为Google所收购.是一款优秀的前端JS框架,已经被用于Google的多款产品当中.AngularJ ...
- Django 安装、创建第一个项目
一.版本 Django 版本对应的 Python 版本: Django 版本 Python 版本 1.8 2.7, 3.2 , 3.3, 3.4, 3.5 1.9, 1.10 2.7, 3.4, ...
- python+Django创建第一个项目
1.首先搭建好环境 1.1 安装pyhton,Linux系统中,python是系统自带的所以就不用安装 1.2 安装Django框架 使用pip安装: pip install django 1.3 检 ...
- Django 创建第一个项目(转)
转自(http://www.runoob.com/django/django-first-app.html) 前面写了不少python程序,由于之前都是作为工具用,所以命令行就足够了,最近写的测试用例 ...
- 吴裕雄--天生自然Django框架开发笔记:Django 创建第一个项目
Django 管理工具 安装 Django 之后,您现在应该已经有了可用的管理工具 django-admin.可以使用 django-admin 来创建一个项目: 可以来看下django-admin ...
- Python学习之路——pycharm的第一个项目
Python学习之路——pycharm的第一个项目 简介: 上文中已经介绍如何安装Pycharm已经环境变量的配置.现在软件已经安装成功,现在就开始动手做第一个Python项目.第一个“Hello W ...
- 【3】Django创建第一个项目
天地所以能长且久者,以其不自生,故能长生. --老子<道德经> 写在前面:Django在学习的过程中,我们会参考官方文档,从两部分进行讲解,第一部分主要是一个入门项目的搭建开发,第二部分是 ...
- win10本地python第三方库安装成功,但是pycharm项目无法使用解决方案
一.背景win10本地python第三方库安装成功,但是pycharm项目无法使用解决方案如本地安装的python中的request库,在pycharm项目中居然无法使用,比较郁闷 pip list ...
- Ionic学习记录(一):ionic及cordova安装、创建第一个应用、项目结构
目录: 一.ionic的安装 二.创建第一个应用程序 三.浏览器中预览应用 四.项目结构 五.添加页面 一.ionic的安装 使用Ionic创建和开发应用程序主要通过Ionic命令行实用程序(“CLI ...
随机推荐
- 微信小程序云开发之云函数创建
云函数 云函数是一段运行在云端的代码,无需管理服务器,在开发工具内编写.一键上传部署即可运行后端代码. 小程序内提供了专门用于云函数调用的 API.开发者可以在云函数内使用 wx-server-sdk ...
- JS基础内容小结(DOM&&BOM)(二)
元素.childNodes:只读 属性 子节点列表集合 元素.nodeType:只读 属性 当前元素下的节点类型 元素.attributes : 只读 属性 属性列表集合 元素.children: 只 ...
- JQ_下雪特效
这是一个jQuery下雪特效.特效的代码如下: <style>body{background:black;color:white}</style><script>/ ...
- Unity 角色场景传送功能
传送触发器 using System.Collections;using System.Collections.Generic;using UnityEngine;using UnityEngine. ...
- A1046. Shortest Distance(20)
17/20,部分超时. #include<bits/stdc++.h> using namespace std; int N,x,pairs; int a,b; vector<int ...
- [2017BUAA软工助教]个人得分总表(至alpha结束)
一.表 学号 第0次 week1 week2 week3 个人项目 附加1 结对项目 附加2 a团队 a团队得分 a贡献分 总分(不计) 总分(记) 15061119 7 9.5 12 9 45.75 ...
- 跟踪分析Linux内核的启动过程小解
跟踪分析Linux内核的启动过程 “20135224陈实 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029 ...
- 读书笔记(chapter18)
调试 18.1准备开始 18.2内核中的bug 1.从隐藏在源代码中的错误到展现在目击者面前的bug,往往是经历一系列连锁反应的事件才可能触发的 18.3通过打印来调试 1.健壮性 健壮性是print ...
- C/C+ 感触
1. C/C++语言开发的首选利器- C++Test 以前在windows平台下的开发,使用的框架主要是MFC,以及console工程(基于win32SDK),属于纯C/C++ ...
- SDN交换机迁移2
关于迁移过程中迁移目标(被迁移的交换机和目标控制器)的选择 SDN中基于过程优化的交换机竞争迁移算法 通信学报 交换机:请求速率大于域内平均请求速率的交换机集合: 控制器:综合网络中时延.流量和控制器 ...