Hadoop实战:Hadoop分布式集群部署(一)
一、系统参数优化配置
1.1 系统内核参数优化配置
修改文件/etc/sysctl.conf,使用sysctl -p命令即时生效。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
kernel.shmmax = 500000000
kernel.shmmni = 4096
kernel.shmall = 4000000000
kernel.sem = 250 512000 100 2048
kernel.sysrq = 1
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.msgmni = 2048
net.ipv4.tcp_syncookies = 1
net.ipv4.ip_forward = 0
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.conf.all.arp_filter = 1
net.ipv4.ip_local_port_range = 1025 65535
net.core.netdev_max_backlog = 10000
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
vm.overcommit_memory = 2
|
1.2 修改Linux最大限制
追加到文件/etc/security/limits.conf即可。
|
1
2
3
4
|
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
|
1.3 磁盘I/O优化调整
Linux磁盘I/O调度器对磁盘的访问支持不同的策略,默认的为CFQ,GP建议设置为deadline。
我这里是sda磁盘,所以直接对sda磁盘更改IO调度策略(你需要根据你的磁盘进行设置),如下设置:
|
1
|
$ echo deadline > /sys/block/sdb/queue/scheduler
|
如果想永久生效,加入到/etc/rc.local即可。
PS:都配置完毕后,重启生效即可。
二、安装前环境配置(所有节点)
2.1 测试环境清单
| 角色 | 主机名 | 地址 | 系统 | 硬件 |
| namenode,resourcemanager,datanode,nodemanager,secondarynamenode | hadoop-nn | 10.10.0.186 | CentOS 7.2 | 8核8G |
| datanode,nodemanager | hadoop-snn | 10.10.0.187 | CentOS 7.2 | 8核8G |
| datanode,nodemanager | hadoop-dn-01 | 10.10.0.188 | CentOS 7.2 | 8核8G |
2.2 设置主机名
|
1
2
3
4
5
6
7
8
9
10
11
|
# 10.10.0.186;
$ hostname hadoop-nn
$ echo "hostname hadoop-nn" >> /etc/rc.local
# 10.10.0.187;
$ hostname hadoop-snn
$ echo "hostname hadoop-snn" >> /etc/rc.local
# 10.10.0.188;
$ hostname hadoop-dn-01
$ echo "hostname hadoop-dn-01" >> /etc/rc.local
|
2.3 关闭防火墙
如果想开启防火墙,就需要了解Greenplum所有的端口信息即可。
|
1
2
|
$ systemctl stop firewalld
$ systemctl disable firewalld
|
2.4 关闭SELinux
|
1
2
|
$ setenforce 0
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
|
2.5 添加所有节点到/etc/hosts
|
1
2
3
|
10.10.0.186 hadoop-nn master
10.10.0.187 hadoop-snn slave01
10.10.0.188 hadoop-dn-01 slave02
|
2.6 NTP时间同步
在Hadoop namenode节点安装ntp服务器,然后其他各个节点都同步namenode节点的时间。
|
1
2
3
|
$ yum install ntp
$ systemctl start ntpd
$ systemctl enable ntpd
|
然后在其他节点同步ntp时间。
|
1
|
$ ntpdate hadoop-nn
|
添加一个计划任务,Hadoop需要各个节点时间的时间都是一致的,切记。
三、开始部署Hadoop
3.1 在所有主机安装JAVA
|
1
|
$ yum install java java-devel -y
|
查看java版本,确保此命令没有问题
|
1
2
3
4
|
$ java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
|
另外openjdk安装后,不会默许设置JAVA_HOME环境变量,要查看安装后的目录,可以用命令。
|
1
2
3
4
5
6
7
|
$ update-alternatives --config jre_openjdk
There is 1 program that provides 'jre_openjdk'.
Selection Command
-----------------------------------------------
*+ 1 java-1.8.0-openjdk.x86_64 (/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre)
|
默认jre目录为:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre
设置环境变量,可用编辑/etc/profile.d/java.sh
|
1
2
3
4
5
|
#!/bin/bash
#
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre
export CLASSPATH=$JAVA_HOME/lib/rt.jar:$JAVA_HOME/../lib/dt.jar:$JAVA_HOME/../lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
|
完成这项操作之后,需要重新登录,或source一下profile文件,以便环境变量生效,当然也可以手工运行一下,以即时生效。
3.2 在所有主机创建专门hadoop用户
|
1
2
|
$ useradd hadoop
$ passwd hadoop
|
设置密码,为简单起见,3台机器上的hadoop密码最好设置成一样,比如123456。为了方便,建议将hadoop加入root用户组,操作方法:
|
1
|
$ usermod -g root hadoop
|
执行完后hadoop即归属于root组了,可以再输入id hadoop查看输出验证一下,如果看到类似下面的输出:
|
1
2
|
$ id hadoop
uid=1002(hadoop) gid=0(root) groups=0(root)
|
3.3 在NameNode节点创建秘钥
创建RSA秘钥对
|
1
2
|
$ su - hadoop
$ ssh-keygen
|
在NameNode节点复制公钥到所有节点Hadoop用户目录下,包括自己:
|
1
2
3
|
$ ssh-copy-id hadoop@10.10.0.186
$ ssh-copy-id hadoop@10.10.0.187
$ ssh-copy-id hadoop@10.10.0.188
|
3.4 在所有主机解压Hadoop二进制包并设置环境变量
Hadoop二进制包下载自行去国内源或者官网搞定。
|
1
2
|
$ tar xvf hadoop-2.8.0.tar.gz -C /usr/local/
$ ln -sv /usr/local/hadoop-2.8.0/ /usr/local/hadoop
|
编辑环境配置文件/etc/profile.d/hadoop.sh,定义类似如下环境变量,设定Hadoop的运行环境。
|
1
2
3
4
5
6
7
8
|
#!/bin/bash
#
export HADOOP_PREFIX="/usr/local/hadoop"
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
|
创建数据和日志目录
|
1
2
3
4
|
$ mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}
$ chown -R hadoop:hadoop /data/hadoop/hdfs
$ mkdir -pv /var/log/hadoop/yarn
$ chown -R hadoop:hadoop /var/log/hadoop/yarn
|
而后,在Hadoop的安装目录中创建logs目录,并修改Hadoop所有文件的属主和属组。
|
1
2
3
4
|
$ cd /usr/local/hadoop
$ mkdir logs
$ chmod g+w logs
$ chown -R hadoop:hadoop ./*
|
四、配置所有Hadoop节点
4.1 hadoop-nn节点
需要配置以下几个文件。
core-site.xml
core-size.xml文件包含了NameNode主机地址以及其监听RPC端口等信息(NameNode默认使用的RPC端口为8020),对于分布式环境,每个节点都需要设置NameNode主机地址,其简要的配置内容如下所示:
|
1
2
|
$ su - hadoop
$ vim /usr/local/hadoop/etc/hadoop/core-site.xml
|
|
1
2
3
4
5
6
7
|
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<final>true</final>
</property>
</configuration>
|
hdfs-site.xml
hdfs-site.xml主要用于配置HDFS相关的属性,列如复制因子(即数据块的副本数)、NN和DN用于存储数据的目录等。数据块的副本数对于分布式的Hadoop应该为3,这里我设置为2,为了减少磁盘使用。而NN和DN用于村粗的数据的目录为前面的步骤中专门为其创建的路径。另外,前面的步骤中也为SNN创建了相关的目录,这里也一并配置为启用状态。
|
1
2
|
$ su - hadoop
$ vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
|
注意,如果需要其它用户对hdfs有写入权限,还需要在hdfs-site.xml添加一项属性定义:
|
1
2
3
4
|
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
|
mapred-site.xml
mapred-site.xml文件用于配置集群的MapReduce framework,此处应该指定使用yarn,另外的可用值还有local和classic。mapred-site.xml默认不存在,但有模块文件mapred-site.xml.template,只需要将其复制为mapred-site.xml即可。
|
1
2
3
|
$ su - hadoop
$ cp -fr /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
$ vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
|
|
1
2
3
4
5
6
|
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
yarn-site.xml
yarn-site.yml用于配置YARN进程及YARN的相关属性,首先需要指定ResourceManager守护进程的主机和监听的端口(这里ResourceManager准备安装在NameNode节点);其次需要指定ResourceMnager使用的scheduler,以及NodeManager的辅助服务。一个简要的配置示例如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
|
hadoop-env.sh和yarn-env.sh
Hadoop的个各守护进程依赖于JAVA_HOME环境变量,如果有类似于前面步骤中通过/etc/profile.d/java.sh全局配置定义的JAVA_HOME变量即可正常使用。不过,如果想为Hadoop定义依赖到特定JAVA环境,也可以编辑这两个脚本文件,为其JAVA_HOME取消注释并配置合适的值即可。此外,Hadoop大多数守护进程默认使用的堆大小为1GB,但现实应用中,可能需要对其各类进程的堆内存大小做出调整,这只需要编辑此两者文件中相关环境变量值即可,列如HADOOP_HEAPSIZE、HADOOP_JOB_HISTORY_HEADPSIZE、JAVA_HEAP_SIZE和YARN_HEAP_SIZE等。
slaves文件
slaves文件存储于了当前集群的所有slave节点的列表,默认值为localhost。这里我打算在三个节点都安装DataNode,所以都添加进去即可。
|
1
2
3
4
5
|
$ su - hadoop
$ cat /usr/local/hadoop/etc/hadoop/slaves
hadoop-nn
hadoop-snn
hadoop-dn-01
|
到目前为止,第一个节点(Master)已经配置好了。在hadoop集群中,所有节点的配置都应该是一样的,前面我们也为slaves节点创建了Hadoop用户、数据目录以及日志目录等配置。
接下来就是把Master节点的配置文件都同步到所有Slaves即可。
|
1
2
3
|
$ su - hadoop
$ scp /usr/local/hadoop/etc/hadoop/* hadoop@hadoop-snn:/usr/local/hadoop/etc/hadoop/
$ scp /usr/local/hadoop/etc/hadoop/* hadoop@hadoop-dn-01:/usr/local/hadoop/etc/hadoop/
|
五、格式化HDFS
在HDFS的NameNode启动之前需要先初始化其用于存储数据的目录,如果hdfs-site.xml中dfs.namenode.name.dir属性指定的目录不存在,格式化命令会自动创建之;如果事先存在,请确保其权限设置正确,此时格式操作会清除其内部的所有数据并重新建立一个新的文件系统。需要以hdfs用户的身份执行如下命令。
|
1
|
[hadoop@hadoop-nn ~]$ hdfs namenode -format
|
其输出会有大量的信息输出,如果显示出类似”17/06/13 05:56:18 INFO common.Storage: Storage directory /data/hadoop/hdfs/nn has been successfully formatted.“的结果表示格式化操作已然完成。
六、启动Hadoop集群
启动Hadood集群的方法有两种:一是在各节点分别启动需要启动的服务,二是在NameNode节点启动整个集群(推荐方法)。
第一种:分别启动方式
Master节点需要启动HDFS的NameNode、SecondaryName、nodeDataNode服务,以及YARN的ResourceManager服务。
|
1
2
3
4
|
$ sudo -u hadoop hadoop-daemon.sh start namenode
$ sudo -u hadoop hadoop-daemon.sh start secondarynamenode
$ sudo -u hadoop hadoop-daemon.sh start datanode
$ sudo -u hadoop yarn-daemon.sh start resourcemanager
|
各Slave节点需要启动HDFS的DataNode服务,以及YARN的NodeManager服务。
|
1
2
|
$ sudo -u hadoop hadoop-daemon.sh start datanode
$ sudo -u hadoop yarn-daemon.sh start nodemanager
|
第二种:集群启动方式
集群规模较大时,分别启动各节点的各服务过于繁琐和低效,为此,Hadoop专门提供了start-dfs.sh和stop-dfs.sh来启动及停止整个hdfs集群,以及start-yarn.sh和stop-yarn.sh来启动及停止整个yarn集群。
|
1
2
|
$ sudo -u hadoop start-dfs.sh
$ sudo -u hadoop start-yarn.sh
|
较早版本的Hadoop会提供start-all.sh和stop-all.sh脚本来统一控制hdfs和mapreduce,但Hadoop 2.0及之后的版本不建议再使用此种方式。
我这里都使用集群启动方式。
6.1 启动HDFS集群
|
1
2
3
4
5
6
7
8
|
[hadoop@hadoop-nn ~]$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-hadoop-nn.out
hadoop-nn: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-hadoop-nn.out
hadoop-snn: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-hadoop-snn.out
hadoop-dn-01: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-hadoop-dn-01.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-hadoop-nn.out
|
HDFS集群启动完成后,可在各节点以jps命令等验证各进程是否正常运行,也可以通过Web UI来检查集群的运行状态。
查看NameNode节点启动的进程:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# hadoop-nn;
[hadoop@hadoop-nn ~]$ jps
14576 NameNode
14887 SecondaryNameNode
14714 DataNode
15018 Jps
[hadoop@hadoop-nn ~]$ netstat -anplt | grep java
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 16468/java
tcp 0 0 127.0.0.1:58545 0.0.0.0:* LISTEN 16290/java
tcp 0 0 10.10.0.186:8020 0.0.0.0:* LISTEN 16146/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 16146/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 16290/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 16290/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 16290/java
tcp 0 0 10.10.0.186:32565 10.10.0.186:8020 ESTABLISHED 16290/java
tcp 0 0 10.10.0.186:8020 10.10.0.186:32565 ESTABLISHED 16146/java
tcp 0 0 10.10.0.186:8020 10.10.0.188:11681 ESTABLISHED 16146/java
tcp 0 0 10.10.0.186:8020 10.10.0.187:57112 ESTABLISHED 16146/java
|
查看DataNode节点启动进程:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# hadoop-snn;
[hadoop@hadoop-snn ~]$ jps
741 DataNode
862 Jps
[hadoop@hadoop-snn ~]$ netstat -anplt | grep java
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 1042/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 1042/java
tcp 0 0 127.0.0.1:18975 0.0.0.0:* LISTEN 1042/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 1042/java
tcp 0 0 10.10.0.187:57112 10.10.0.186:8020 ESTABLISHED 1042/java
|
|
1
2
3
4
|
# hadoop-dn-01;
[hadoop@hadoop-dn-01 ~]$ jps
410 DataNode
539 Jps
|
通过JPS命令和开启的端口基本可以看出,NameNode、SecondaryNameNode、DataNode进程各自开启的对应端口。另外,可以看到DataNode都正常连接到了NameNode的8020端口。如果相关节点起不来,可能是权限不对,或者相关目录没有创建,具体可以看相关节点的日志:/usr/local/hadoop/logs/*.log。
通过NameNode节点的http://hadoop-nn:50070访问Web UI界面:
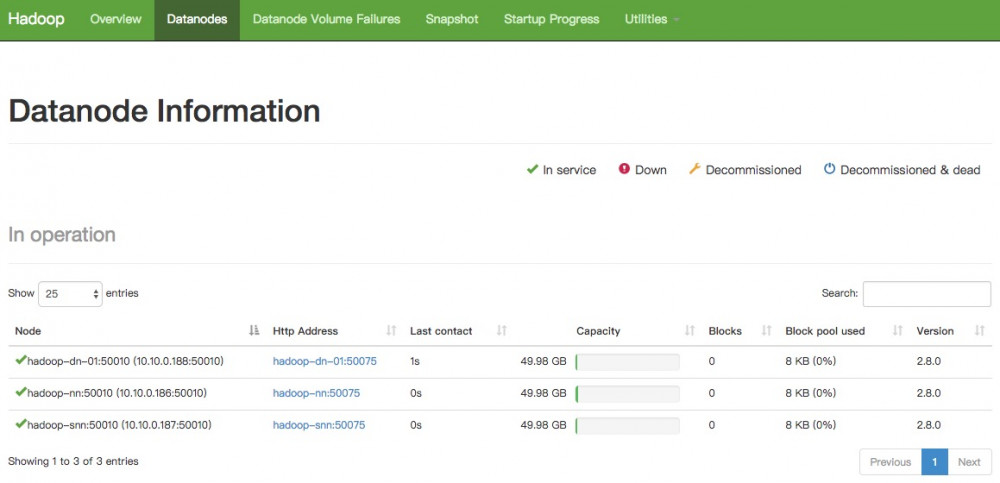 可以看到3个DataNode节点都运行正常。
可以看到3个DataNode节点都运行正常。
此时其实HDFS集群已经好了,就可以往里面存储数据了,下面简单使用HDFS命令演示一下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 在HDFS集群创建目录;
[hadoop@hadoop-nn ~]$ hdfs dfs -mkdir /test
# 上传文件到HDFS集群;
[hadoop@hadoop-nn ~]$ hdfs dfs -put /etc/fstab /test/fstab
[hadoop@hadoop-nn ~]$ hdfs dfs -put /etc/init.d/functions /test/functions
# 查看HDFS集群的文件;
[hadoop@hadoop-nn ~]$ hdfs dfs -ls /test/
Found 2 items
-rw-r--r-- 2 hadoop supergroup 524 2017-06-14 01:49 /test/fstab
-rw-r--r-- 2 hadoop supergroup 13948 2017-06-14 01:50 /test/functions
|
然后我们再看一下Hadoop Web UI界面:
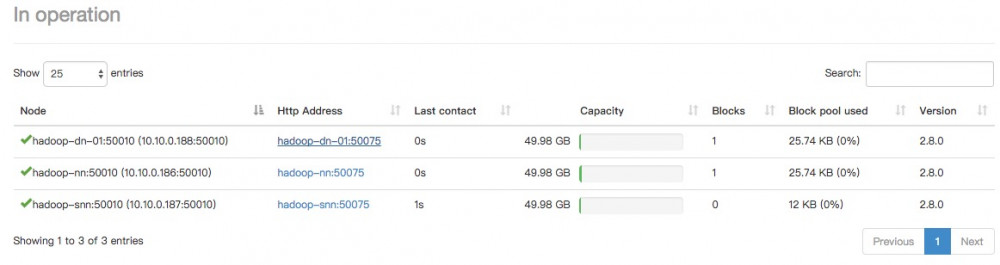
可以看到Blocks字段,在Hadoop-dn和hadoop-nn节点各自占用一个块,HDFS默认未64M一个块大小。由于我们上传的文件太小,所以也没有做切割,我们再启动集群时设置的是2个副本,所以这里就相当于存储了两份。
HDFS集群管理命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
[hadoop@hadoop-nn ~]$ hdfs
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
classpath prints the classpath
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
debug run a Debug Admin to execute HDFS debug commands
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies list/get/set block storage policies
version print the version
|
6.2 启动YARN集群
|
1
2
3
4
5
6
|
[hadoop@hadoop-nn ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-hadoop-nn.out
hadoop-nn: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-hadoop-nn.out
hadoop-dn-01: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-hadoop-dn-01.out
hadoop-snn: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-hadoop-snn.out
|
YARN集群启动完成后,可在各节点以jps命令等验证各进程是否正常运行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# hadoop-nn;
[hadoop@hadoop-nn ~]$ jps
10674 SecondaryNameNode
10342 NameNode
10487 DataNode
15323 ResourceManager
15453 NodeManager
15775 Jps
# hadoop-snn;
[hadoop@hadoop-snn ~]$ jps
10415 NodeManager
11251 Jps
9984 DataNode
# hadoop-dn-01;
10626 NodeManager
10020 DataNode
11423 Jps
|
通过JPS命令和开启的端口基本可以看出ResourceManager、NodeManager进程都各自启动。另外,NodeManager会在对应的DataNode节点都启动。
通过ResourceManager节点的http://hadoop-nn:8088访问Web UI界面:
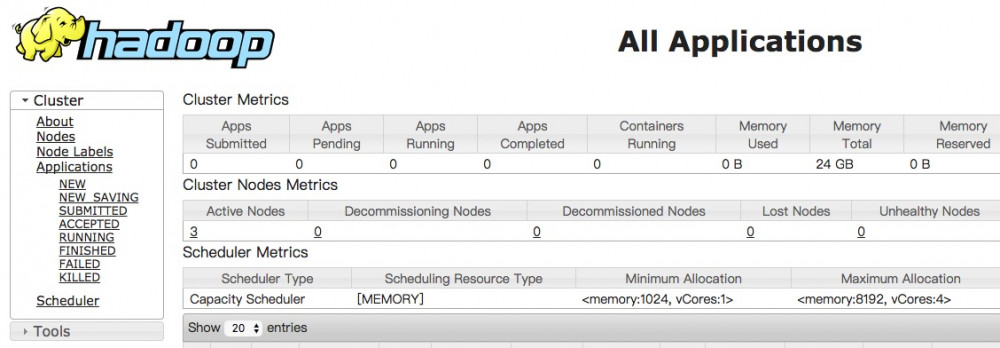
YARN集群管理命令
YARN命令有许多子命令,大体可分为用户命令和管理命令两类。直接运行yarn命令,可显示其简单使用语法及各子命令的简单介绍:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
[hadoop@hadoop-nn ~]$ yarn
Usage: yarn [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
resourcemanager run the ResourceManager
Use -format-state-store for deleting the RMStateStore.
Use -remove-application-from-state-store <appId> for
removing application from RMStateStore.
nodemanager run a nodemanager on each slave
timelineserver run the timeline server
rmadmin admin tools
sharedcachemanager run the SharedCacheManager daemon
scmadmin SharedCacheManager admin tools
version print the version
jar <jar> run a jar file
application prints application(s)
report/kill application
applicationattempt prints applicationattempt(s)
report
container prints container(s) report
node prints node report(s)
queue prints queue information
logs dump container logs
classpath prints the class path needed to
get the Hadoop jar and the
required libraries
cluster prints cluster information
daemonlog get/set the log level for each
daemon
top run cluster usage tool
|
这些命令中,jar、application、node、logs、classpath和version是常用的用户命令,而resourcemanager、nodemanager、proxyserver、rmadmin和daemonlog是较为常用的管理类命令。
八、运行YARN应用程序
YARN应用程序(Application)可以是一个简单的shell脚本、MapReduce作业或其它任意类型的作业。需要运行应用程序时,客户端需要事先生成一个ApplicationMaster,而后客户端把application context提交给ResourceManager,随后RM向AM分配内存及运行应用程序的容器。大体来说,此过程分为六个阶段。
- Application初始化及提交;
- 分配内存并启动AM;
- AM注册及资源分配;
- 启动并监控容器;
- Application进度报告;
- Application运行完成;
下面我们来利用搭建好的Hadoop平台处理一个任务,看一下这个流程是怎样的。Hadoop安装包默认提供了一下运行示例,如下操作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[hadoop@hadoop-nn ~]$ yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
|
我们找一个比较好理解的wordcount进行测试,还记得我们刚开始提供一个funcations文件到了HDFS集群中,下面我们就把funcations这个文件进行单词统计处理,示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
[hadoop@hadoop-nn ~]$ yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /test/fstab /test/functions /test/wc
17/06/14 04:26:02 INFO client.RMProxy: Connecting to ResourceManager at master/10.10.0.186:8032
17/06/14 04:26:03 INFO input.FileInputFormat: Total input files to process : 2
17/06/14 04:26:03 INFO mapreduce.JobSubmitter: number of splits:2
17/06/14 04:26:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1497424827481_0002
17/06/14 04:26:03 INFO impl.YarnClientImpl: Submitted application application_1497424827481_0002
17/06/14 04:26:03 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1497424827481_0002/
17/06/14 04:26:03 INFO mapreduce.Job: Running job: job_1497424827481_0002
17/06/14 04:26:09 INFO mapreduce.Job: Job job_1497424827481_0002 running in uber mode : false
17/06/14 04:26:09 INFO mapreduce.Job: map 0% reduce 0%
17/06/14 04:26:14 INFO mapreduce.Job: map 100% reduce 0%
17/06/14 04:26:19 INFO mapreduce.Job: map 100% reduce 100%
17/06/14 04:26:19 INFO mapreduce.Job: Job job_1497424827481_0002 completed successfully
17/06/14 04:26:19 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1272
FILE: Number of bytes written=411346
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1183
HDFS: Number of bytes written=470
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=4582
Total time spent by all reduces in occupied slots (ms)=2651
Total time spent by all map tasks (ms)=4582
Total time spent by all reduce tasks (ms)=2651
Total vcore-milliseconds taken by all map tasks=4582
Total vcore-milliseconds taken by all reduce tasks=2651
Total megabyte-milliseconds taken by all map tasks=4691968
Total megabyte-milliseconds taken by all reduce tasks=2714624
Map-Reduce Framework
Map input records=53
Map output records=142
Map output bytes=1452
Map output materialized bytes=1278
Input split bytes=206
Combine input records=142
Combine output records=86
Reduce input groups=45
Reduce shuffle bytes=1278
Reduce input records=86
Reduce output records=45
Spilled Records=172
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=169
CPU time spent (ms)=1040
Physical memory (bytes) snapshot=701403136
Virtual memory (bytes) snapshot=6417162240
Total committed heap usage (bytes)=529530880
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=977
File Output Format Counters
Bytes Written=470
|
我们把统计结果放到HDFS集群的/test/wc目录下。另外,注意当输出目录存在时执行任务会报错。
任务运行时,你可以去Hadoop管理平台(8088端口)看一下会有如下类似的输出信息,包括此次应用名称,运行用户、任务名称、应用类型、执行时间、执行状态、以及处理进度。

然后我们可以看一下/test/wc目录下有什么:
|
1
2
3
4
|
[hadoop@hadoop-nn ~]$ hdfs dfs -ls /test/wc
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2017-06-14 04:26 /test/wc/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 470 2017-06-14 04:26 /test/wc/part-r-00000
|
看一下单词统计结果:
|
1
2
3
4
5
6
7
8
9
10
11
|
[hadoop@hadoop-nn ~]$ hdfs dfs -cat /test/wc/part-r-00000
# 8
'/dev/disk' 2
/ 2
/boot 2
/data 2
/dev/mapper/centos-root 2
/dev/mapper/centos-swap 2
/dev/sdb 2
/etc/fstab 2
......
|
九、开启历史服务
当运行过Yarn任务之后,在Web UI界面可以查看其状态信息。但是当ResourceManager重启之后,这些任务就不可见了。所以可以通过开启Hadoop历史服务来查看历史任务信息。
Hadoop开启历史服务可以在web页面上查看Yarn上执行job情况的详细信息。可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
|
1
2
3
4
5
6
7
8
|
[root@hadoop-nn ~]# jps
23347 DataNode
23188 NameNode
23892 NodeManager
20597 QuorumPeerMain
24631 Jps
24264 JobHistoryServer
23534 SecondaryNameNode
|
JobHistoryServer开启后,可以通过Web页面查看历史服务器:
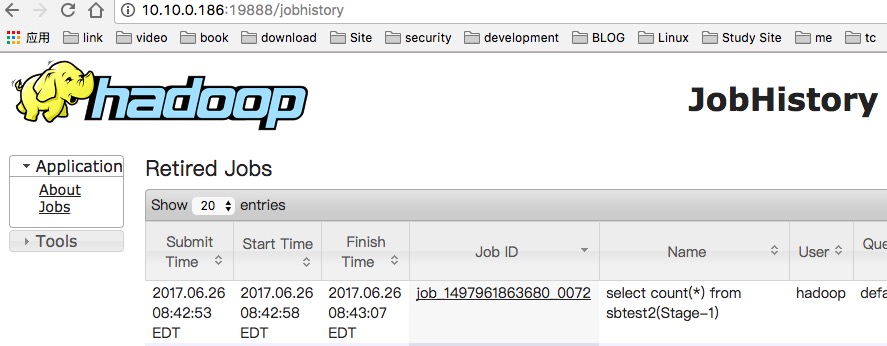
历史服务器的Web端口默认是19888,可以查看Web界面。你可以多执行几次Yarn任务,可以通过History点击跳到历史页面,查看其任务详情。
但是在上面所显示的某一个Job任务页面的最下面,Map和Reduce个数的链接上,点击进入Map的详细信息页面,再查看某一个Map或者Reduce的详细日志是看不到的,是因为没有开启日志聚集服务。
十、开启日志聚集
MapReduce是在各个机器上运行的,在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在HDFS上,这个过程就是日志聚集。
配置日志聚集功能,Hadoop默认是不启用日志聚集的,在yarn-site.xml文件里配置启用日志聚集。
|
1
2
3
4
5
6
7
8
|
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
|
yarn.log-aggregation-enable:是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds:设置日志保留时间,单位是秒。
将配置文件分发到其他节点:
|
1
2
3
|
[hadoop@hadoop-nn ~]$ su - hadoop
[hadoop@hadoop-nn ~]$ scp /usr/local/hadoop/etc/hadoop/* hadoop@hadoop-snn:/usr/local/hadoop/etc/hadoop/
[hadoop@hadoop-nn ~]$ scp /usr/local/hadoop/etc/hadoop/* hadoop@hadoop-dn-01:/usr/local/hadoop/etc/hadoop/
|
重启Yarn进程:
|
1
2
|
[hadoop@hadoop-nn ~]$ stop-yarn.sh
[hadoop@hadoop-nn ~]$ start-yarn.sh
|
重启HistoryServer进程:
|
1
2
|
[hadoop@hadoop-nn ~]$ mr-jobhistory-daemon.sh stop historyserver
[hadoop@hadoop-nn ~]$ mr-jobhistory-daemon.sh start historyserver
|
测试日志聚集,运行一个demo MapReduce,使之产生日志:
|
1
|
[hadoop@hadoop-nn ~]$ yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /test/fstab /test/wc1
|
运行Job后,就可以在历史服务器Web页面查看各个Map和Reduce的日志了。
十一、内存调整
|
1
2
3
4
5
6
7
8
|
# [hadoop] 512 - 4096
$ /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_PORTMAP_OPTS="-Xmx4096m $HADOOP_PORTMAP_OPTS"
export HADOOP_CLIENT_OPTS="-Xmx4096m $HADOOP_CLIENT_OPTS"
# [yarn] 2048 - 4096
$ /usr/local/hadoop/etc/hadoop/yarn-env.sh
JAVA_HEAP_MAX=-Xmx4096m
|
Ambari——大数据平台的搭建利器:https://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html
Hadoop实战:Hadoop分布式集群部署(一)的更多相关文章
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- Minio分布式集群部署——Swarm
最近研究minio分布式集群部署,发现网上大部分都是单服务器部署,而minio官方在github上现在也只提供了k8s和docker-compose的方式,网上有关与swarm启动minio集群的文章 ...
随机推荐
- Luogu P3227 [HNOI2013]切糕
%%ZZKdalao上课讲的题目,才知道网络流的这种玄学建模 我们先想一想,如果没有D的限制,那么想当于再每一根纵轴上选一个权值最小的点再加起来 我们对应在网络流上就是每一根纵轴上的点向它下方的点用权 ...
- CS229笔记:线性回归
线性回归问题 首先做一些符号上的说明: \(x^{(i)}\):特征(feature) \(y^{(i)}\):目标变量(target variables) \(\mathcal{X}\):特征空间 ...
- 洛咕3312 [SDOI2014]数表
洛咕3312 [SDOI2014]数表 终于独立写出一道题了...真tm开心(还是先写完题解在写的) 先无视a的限制,设\(f[i]\)表示i的约数之和 不妨设\(n<m\) \(Ans=\su ...
- 搭建CodeReivew 工具 Phabricator
简介 现在项目成本投入高了,自然对项目的质量要求也愈来愈高,像发布好还发现明显的 bug,或性能低下这种问题已不能接受. 由于产品的质量和代码质量密切相关,而开发团队里并不是每个人都是大神,大家的经验 ...
- Js_实现3D球体旋转
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 【原创】CA证书申请+IIS配置HTTPS+默认访问https路径
一.CA证书申请 (一). 新StartSSL注册帐号 1. StartSSL官网 官方网站:https://www.startssl.com/ 2. 进入到StartSSL后,直接点击注 ...
- java后台面试知识点总结
本文主要记录在准备面试过程中遇到的一些基本知识点(持续更新) 一.Java基础知识 1.抽象类和接口的区别 接口和抽象类中都可以定义变量,但是接口中定义的必须是公共的.静态的.Final的,抽象类中的 ...
- 在HTML中为JavaScript传递变量
在html中为JavaScript传递变量是一个关键步骤,然后就可以通过对JavaScript变量操作,实现想要达到的目的 本节代码主要使用了JavaScript中的document对象中的getEl ...
- Java实验报告(实验二)
课程:Java程序设计 班级: 1351 姓名:王玮怡 学号:20135116 成绩: 指导教师:娄嘉鹏 实验日期: ...
- Linux内核分析——第六周学习笔记20135308
第六周 进程的描述和进程的创建 一.进程描述符task_struct数据结构 1.操作系统三大功能 进程管理 内存管理 文件系统 2.进程控制块PCB——task_struct 也叫进程描述符,为了管 ...