并发编程:GIL,线程池,进程池,阻塞,非阻塞,同步,异步
一 GIL(global interpreter lock)
GIL中文叫全局解释器锁,我们执行一个文件会产生一个进程,那么我们知道进程不是真正的执行单位,而是资源单位,所以进程中放有解释器(cpython)和py文件,也就是解释器需要解释的文件,即CPU要运行的文件。
GIL:
GIL本质上是一个互斥锁,是一个加在解释器身上的互斥锁, 在同一个进程内,所有的线程要想执行都必须要先抢到GIL锁,才能执行解释器代码。 优点: 保证cpython解释器内存管理的线程安全。保证同一时间只有一个线程运行。 缺点: 同一进程内所有的线程同一时刻只能有一个执行,运行效率低,也就是说cpython解释器的多线程无法实现并行,但是可以实现并发。
实现并发的原理:一个线程遇到I/O操作就切换线程,同时强制释放该线程的GIL,给其他线程使用。
GIL与互斥锁:
1.100个线程去抢GIL锁,即抢执行权限
2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,
即释放GIL
4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
三个需要注意的点:
#1.线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,即便是拿到执行权限GIL也要立刻交出来 #2.join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,要想保证数据安全的根本原理在于让并发变成串行,join与互斥锁都可以实现,毫无疑问,互斥锁的部分串行效率要更高 #3. 一定要看本小节最后的GIL与互斥锁的经典分析
复制代码
GIL VS Lock 机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock? 首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据 然后,我们可以得出结论:保护不同的数据就应该加不同的锁。 最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock 过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限 线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果 既然是串行,那我们执行 t1.start() t1.join t2.start() t2.join() 这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。 因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
GIL与lock与join之间的关系
我们通过一个图来进一步了解这个过程:
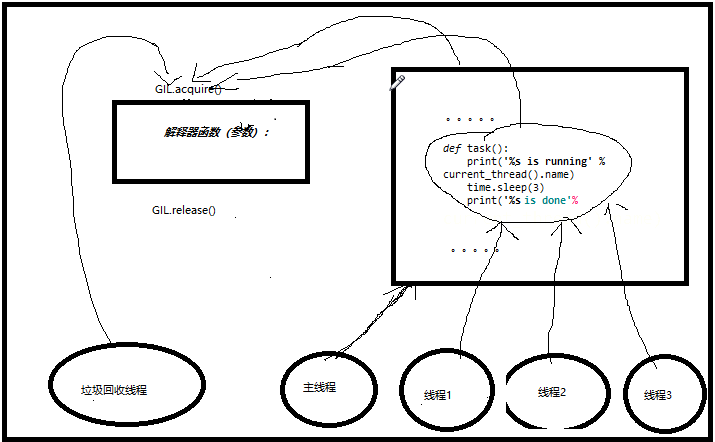
二 线程池与进程池:
首先我们明确一点:进程与线程都不能无限开!!!!我们的内存是一定的。
那么池的作用是什么:用来限制并发的任务数目,限制我们的计算机在一个自己可以控制的范围,去并发的执行任务。
池内进程:用于计算密集型。
池内线程:用于IO密集型。
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time def task():
print('%s is running')
time.sleep(2)
if __name__ == '__main__':
for i in range(10):
进程池:p=ProcessPoolExecutor(max_workers=5)#当我们不在里面填值的时候默认开启的进程数为CPU的核数。我们一般CPU为4核。 线程池:p=ThreadPoolExecutor(max_workers=10)#当我们不填值时,默认开启的线程数是CPU核数的五倍也就是:cpu*5
程序的运行状态:
阻塞:程序运行过程遇到I/O,程序变为阻塞状态,释放CPU资源。 非阻塞: 在运行态或则就绪态:没有遇到I/O或则通过某种手段让程序即使遇到I/O也不会停在原地,继续执行其他的操作,尽可能的多占用cpu。
提交任务的两种方式:或则调用任务的两种方式
同步:效率低
提交任务后就在原地等待,直到任务运行完毕后拿到任务的返回值才会继续执行下一行代码,强调一点。同步的等待与阻塞的等待是不一样的,
同步的等待可能也会遇到I/O操作,但是并不是阻塞,程序还是在运行状态的,因为这个时候程序还是在执行同步的任务。 异步:效率高
提交任务后,不在原地等,直接执行下一行代码。等到任务运行结束后会通知异步,任务结束。
并发编程:GIL,线程池,进程池,阻塞,非阻塞,同步,异步的更多相关文章
- Python 并发编程(管道,事件,信号量,进程池)
管道 Conn1,conn2 = Pipe() Conn1.recv() Conn1.send() 数据接收一次就没有了 from multiprocessing import Process,Pip ...
- py 并发编程(线程、进程、协程)
一.操作系统 操作系统是一个用来协调.管理和控制计算机硬件和软件资源的系统程序,它位于硬件和应用程序之间. 程序是运行在系统上的具有某种功能的软件,比如说浏览器,音乐播放器等.操作系统的内核的定义:操 ...
- 深入理解java:2.3.4. 并发编程concurrent包 之容器ConcurrentLinkedQueue(非阻塞的并发队列---循环CAS)
1. 引言 在并发编程中我们有时候需要使用线程安全的队列. 如果我们要实现一个线程安全的队列有两种实现方式:一种是使用阻塞算法,另一种是使用非阻塞算法. 使用阻塞算法的队列可以用一个锁(入队和出 ...
- java并发编程(8)原子变量和非阻塞的同步机制
原子变量和非阻塞的同步机制 一.锁的劣势 1.在多线程下:锁的挂起和恢复等过程存在着很大的开销(及时现代的jvm会判断何时使用挂起,何时自旋等待) 2.volatile:轻量级别的同步机制,但是不能用 ...
- python 之 并发编程(进程池与线程池、同步异步阻塞非阻塞、线程queue)
9.11 进程池与线程池 池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务 池子内什么时候装进程:并发的任务属于计算密集型 池子内什么时候装线程:并发的任务属于I ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- GIL 线程池 进程池 同步 异步 阻塞 非阻塞
1.GIL 是一个全局解释器锁,是一种互斥锁 为什么需要GIL锁:因为一个python.exe进程中只有一份解释器,如果这个进程开启了多个线程都要执行代码 多线程之间要竞争解释器,一旦竞争就有可能出现 ...
- Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就 ...
- Python并发编程之线程池&进程池
引用 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我 ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
随机推荐
- lua C++ wrapper
背景 最近在研究lua的c++绑定库,使用过一下几个 luabind 问题:没人维护 https://github.com/vinniefalco/LuaBridge https://github.c ...
- mongo之 前后台创建索引 --noIndexBuildRetry
在数据量超大的情形下,任何数据库系统在创建索引时都是一个耗时的大工程.MongoDB也不例外.因此,MongoDB索引的创建有两个选择,一个是前台方式,一个是后台方式.那这两种方式有什么差异呢,在创建 ...
- requestAnimationFrame 知识点
与setTimeout相比,requestAnimationFrame最大的优势是由系统来决定回调函数的执行时机.具体一点讲,如果屏幕刷新率是60Hz,那么回调函数就每16.7ms被执行一次,如果刷新 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- ubuntu-docker入门到放弃(二)docker初探(基本用法及命令)
一.使用公共镜像 docker有一个开源的镜像管理系统,上面有很多常见的images,如mysql,nginx,tomcat等,可以直接根据自己的需求下载下来用,还有系统images,如redhat, ...
- SpringCloud之网关 Zuul(四)
一 Zuul简介 zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet应用. Zuul 在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架.Z ...
- java中的自定义注解的使用
https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html
- bzoj5017: [Snoi2017]炸弹
Description 在一条直线上有 N 个炸弹,每个炸弹的坐标是 Xi,爆炸半径是 Ri,当一个炸弹爆炸时,如果另一个炸弹所在位置 Xj 满足: Xi−Ri≤Xj≤Xi+Ri,那么,该炸弹也会被 ...
- bzoj5003: 与链 5004: 开锁魔法II 5005:乒乓游戏
www.lydsy.com/JudgeOnline/upload/task.pdf 第一题题意可以转为选一个长度k的序列,每一项二进制的1的位置被下一项包含,且总和为1,考虑每个二进制位的出现位置,可 ...
- spring4.3新注解之:@RequestMapping变种(@GetMapping,@PostMapping,@PutMapping,@DeleteMapping,@PatchMapping)
Spring 4.3 中引进了下面的注解 @RequestMapping 在方法层级的变种,来帮助简化常用 HTTP 方法的映射,并更好地表达被注解的方法的语义.比如,@GetMapping可以读作 ...