Django Rest Framework源码剖析(六)-----序列化(serializers)
| 一、简介 |
django rest framework 中的序列化组件,可以说是其核心组件,也是我们平时使用最多的组件,它不仅仅有序列化功能,更提供了数据验证的功能(与django中的form类似)。
便于展现的序列化操作,我们需要在model添加外键、多对多情况。以下是新的models(请删除原有的数据库,重新migrate):
models.py
from django.db import models class UserInfo(models.Model):
user_type_choice = (
(1,"普通用户"),
(2,"会员"),
)
user_type = models.IntegerField(choices=user_type_choice)
username = models.CharField(max_length=32,unique=True)
password = models.CharField(max_length=64)
group = models.ForeignKey(to='UserGroup',null=True,blank=True)
roles = models.ManyToManyField(to='Role') class UserToken(models.Model):
user = models.OneToOneField(to=UserInfo)
token = models.CharField(max_length=64) class UserGroup(models.Model):
"""用户组"""
name = models.CharField(max_length=32,unique=True) class Role(models.Model):
"""角色"""
name = models.CharField(max_length=32,unique=True)
| 二、使用 |
1.基本使用
在urls.py中添加新的角色url,以前的url为了减少干扰,在这里进行注释:
from django.conf.urls import url
from app01 import views urlpatterns = [ # url(r'^api/v1/auth', views.AuthView.as_view()),
# url(r'^api/v1/order', views.OrderView.as_view()),
url(r'^api/v1/roles', views.RoleView.as_view()), # 角色视图
# url(r'^api/(?P<version>[v1|v2]+)/user', views.UserView.as_view(),name="user_view"),
]
views.py
from rest_framework import serializers
from rest_framework.views import APIView
from django.shortcuts import HttpResponse
from app01 import models
import json class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all()
res=RolesSerializer(instance=roles,many=True) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False))
使用浏览器访问http://127.0.0.1:8000/api/v1/roles,结果如下:

2.自定义序列化字段
当数据模型中有外键或者多对多时候,这时候就需要自定义序列化了
新增用户信息url
from django.conf.urls import url
from app01 import views urlpatterns = [ # url(r'^api/v1/auth', views.AuthView.as_view()),
# url(r'^api/v1/order', views.OrderView.as_view()),
url(r'^api/v1/roles', views.RoleView.as_view()),
url(r'^api/v1/userinfo', views.UserinfoView.as_view()), #用户信息
# url(r'^api/(?P<version>[v1|v2]+)/user', views.UserView.as_view(),name="user_view"),
]
UserinfoView和序列化类
from rest_framework import serializers
from rest_framework.views import APIView
from django.shortcuts import HttpResponse
from app01 import models
import json class UserinfoSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同 username=serializers.CharField()
password=serializers.CharField()
#sss=serializers.CharField(source='user_type') #该方法只能拿到user_type的ID
sss=serializers.CharField(source='get_user_type_display') #自定义字段名称,和数据模型不一致,需要指定source本质调用get_user_type_display()方法获取数据
gp=serializers.CharField(source='group.name') #本质拿到group对象,取对象的name,
#rl=serializers.CharField(source='roles.all.first.name')
rl=serializers.SerializerMethodField() #多对多序列化方法一
def get_rl(self,obj): #名称固定:get_定义的字段名称
"""
自定义序列化
:param obj:传递的model对象,这里已经封装好的
:return:
"""
roles=obj.roles.all().values() #获取所有的角色 return list(roles) #返回的结果一定有道是json可序列化的对象
class UserinfoView(APIView):
"""用户信息"""
def get(self,request,*args,**kwargs):
users=models.UserInfo.objects.all()
res=UserinfoSerializer(instance=users,many=True) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False))
访问http://127.0.0.1:8000/api/v1/userinfo,查看结果:

除了以上的Serializer,还可以使用ModelSerializer,ModelSerializer继承了serializer,其结果和上面示例一样:
class UserinfoSerializer(serializers.ModelSerializer):
id = serializers.IntegerField() # 定义需要提取的序列化字段,名称和model中定义的字段相同
username=serializers.CharField()
password=serializers.CharField()
#sss=serializers.CharField(source='user_type') #该方法只能拿到user_type的ID
sss=serializers.CharField(source='get_user_type_display') #自定义字段名称,和数据模型不一致,需要指定source本质调用get_user_type_display()方法获取数据
#rl=serializers.CharField(source='roles.all.first.name')
gp=serializers.CharField(source='group.name')
rl=serializers.SerializerMethodField() #多对多序列化方法一
def get_rl(self,obj): #名称固定:get_定义的字段名称
"""
自定义序列化
:param obj:传递的model对象,这里已经封装好的
:return:
"""
roles=obj.roles.all().values() #获取所有的角色 return list(roles) #返回的结果一定有道是json可序列化的对象
class Meta:
model = models.UserInfo
fields = ['id', 'username', 'password', 'sss','rl','gp'] #配置要序列化的字段
# fields = "__all__" 使用model中所有的字段 class UserinfoView(APIView):
"""用户信息"""
def get(self,request,*args,**kwargs):
users=models.UserInfo.objects.all()
res=UserinfoSerializer(instance=users,many=True) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False))
3.连表序列化以及深度控制
使用depth进行深度控制,越深其序列化的细读越高
class UserinfoSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
#fields = "__all__" # 使用model中所有的字段
fields = ['id', 'username', 'password', 'group','roles'] # 配置要序列化的字段
depth = 1 #系列化深度,1~10,建议使用不超过3
class UserinfoView(APIView):
"""用户信息"""
def get(self,request,*args,**kwargs):
users=models.UserInfo.objects.all()
res=UserinfoSerializer(instance=users,many=True) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False))
请求http://127.0.0.1:8000/api/v1/userinfo,结果如下:

4.序列化字段url
urls.py新加入组url
urlpatterns = [
# url(r'^api/v1/auth', views.AuthView.as_view()),
# url(r'^api/v1/order', views.OrderView.as_view()),
url(r'^api/v1/roles', views.RoleView.as_view()),
url(r'^api/v1/userinfo', views.UserinfoView.as_view()),
url(r'^api/v1/group/(?P<xxx>\d+)', views.GroupView.as_view(),name='gp'), # 新加入组url
# url(r'^api/(?P<version>[v1|v2]+)/user', views.UserView.as_view(),name="user_view"),
]
views.py
class UserinfoSerializer(serializers.ModelSerializer):
group=serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='xxx')
#view_name,urls.py目标url的视图别名(name),这里是UserGroup的视图别名
#lookup_field 给url传递的参数,也就是正则匹配的字段
#lookup_url_kwarg,url中正则名称,也就是kwargs中的key
class Meta:
model = models.UserInfo
#fields = "__all__" # 使用model中所有的字段
fields = ['id', 'username', 'password','roles','group'] # 配置要序列化的字段
depth = 1 #系列化深度,1~10,建议使用不超过3
class UserinfoView(APIView):
"""用户信息"""
def get(self,request,*args,**kwargs):
users=models.UserInfo.objects.all()
res=UserinfoSerializer(instance=users,many=True,context={'request': request}) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
#若需生成超链接字段,则需要加context={'request': request}
return HttpResponse(json.dumps(res.data,ensure_ascii=False)) class UserGroupSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserGroup
fields = "__all__"
depth = 0 class GroupView(APIView):
def get(self,request,*args,**kwargs): group_id=kwargs.get('xxx')
group_obj=models.UserGroup.objects.get(id=group_id)
res=UserGroupSerializer(instance=group_obj,many=False) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False))
此时访问组信息:http://127.0.0.1:8000/api/v1/group/1,结果如下:

在查看用户信息,此时生成的组就是超链接形式了(便于查看json数据,这里用postman发请求):
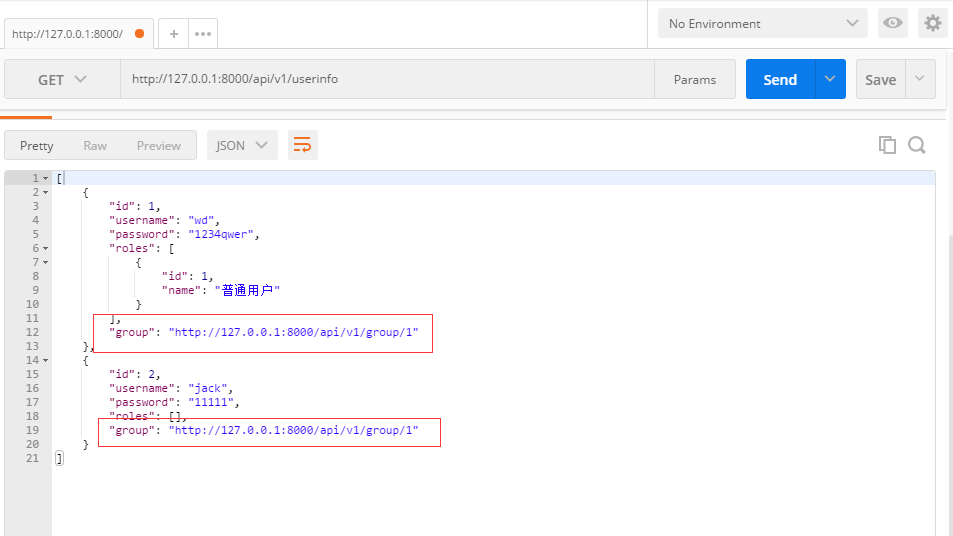
| 三、源码剖析 |
1.类的基本知识
类是实例化之前会执行__new__方法,用于控制一个类生成实例的过程
- 子类没有__new__方法执行父类的__new__方法
- __new__方法执行完以后执行__init__构造方法
2.以ModelSerializer为例,无__new__方法,其父类Serializer也没有,在往上父类BaseSerializer中含有__new__方法,分析请看注释,下面是源码部分:
class BaseSerializer(Field):
"""
The BaseSerializer class provides a minimal class which may be used
for writing custom serializer implementations. Note that we strongly restrict the ordering of operations/properties
that may be used on the serializer in order to enforce correct usage. In particular, if a `data=` argument is passed then: .is_valid() - Available.
.initial_data - Available.
.validated_data - Only available after calling `is_valid()`
.errors - Only available after calling `is_valid()`
.data - Only available after calling `is_valid()` If a `data=` argument is not passed then: .is_valid() - Not available.
.initial_data - Not available.
.validated_data - Not available.
.errors - Not available.
.data - Available.
""" def __init__(self, instance=None, data=empty, **kwargs): # many=False后执行的构造方法
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super(BaseSerializer, self).__init__(**kwargs) def __new__(cls, *args, **kwargs):
# We override this method in order to automagically create
# `ListSerializer` classes instead when `many=True` is set.
if kwargs.pop('many', False): # many参数,如果有则执行cls.many_init,没有则执行super(BaseSerializer).__new__
return cls.many_init(*args, **kwargs) # many=True,表示对QuerySet进行处理,走该逻辑,
return super(BaseSerializer, cls).__new__(cls, *args, **kwargs) # many = False ,表示对单独的对象进行处理
执行玩__new__方法接着执行__init__构造方法,此时有根据many值不同执行不同的构造方法,当many=True时候执行cls.many_init方法,
@classmethod
def many_init(cls, *args, **kwargs): # many=True,执行该方法
"""
This method implements the creation of a `ListSerializer` parent
class when `many=True` is used. You can customize it if you need to
control which keyword arguments are passed to the parent, and
which are passed to the child. Note that we're over-cautious in passing most arguments to both parent
and child classes in order to try to cover the general case. If you're
overriding this method you'll probably want something much simpler, eg: @classmethod
def many_init(cls, *args, **kwargs):
kwargs['child'] = cls()
return CustomListSerializer(*args, **kwargs)
"""
allow_empty = kwargs.pop('allow_empty', None)
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
if allow_empty is not None:
list_kwargs['allow_empty'] = allow_empty
list_kwargs.update({
key: value for key, value in kwargs.items()
if key in LIST_SERIALIZER_KWARGS
})
meta = getattr(cls, 'Meta', None)
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
return list_serializer_class(*args, **list_kwargs) # 最后使用ListSerializer进行实例化
从上面源码中我们知道,对于单独的对象,采用的是Serializer类进行处理,若对象是QuerySet类型(多个对象列表),采用LIstSeriallizer处理,此时我们调用对象的data属性获取结果(示例中这使用的是res.data),下面是源码(寻找时候先从子类找,无该属性就去父类找):
@property
def data(self):
ret = super(Serializer, self).data # 执行父类data属性
return ReturnDict(ret, serializer=self)
父类BaseSerialize的属性方法data源码:
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'): #数据验证时候使用
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg) if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):# 判断有无错误,无错误进行序列化
self._data = self.to_representation(self.instance) # 将instance(QuerySet对象)传入,开始序列化
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else: self._data = self.get_initial() return self._data
从以上源码中可以看出,序列化方法是通过调用类的self.to_representation方法进行序列化,下面我们看Serializer类的to_representation方法
def to_representation(self, instance):
"""
Object instance -> Dict of primitive datatypes.
"""
ret = OrderedDict() #先将instance转化为有序字典
fields = self._readable_fields for field in fields: # 循环定义的字段,这个字段可以是我们自己定义的,也可以是model中的字段
try:
attribute = field.get_attribute(instance) #调用字段的get_attribute方法(参数是对象),在示例中可以理解为group.get_attribute(group_obj),
except SkipField:
continue # We skip `to_representation` for `None` values so that fields do
# not have to explicitly deal with that case.
#
# For related fields with `use_pk_only_optimization` we need to
# resolve the pk value.
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute) return ret
以上源码中,调用field.get_attribute(instance)方法获取每个字段的数据,下面是field.get_attribute(instance)源码(在Field中)
def get_attribute(self, instance):
"""
Given the *outgoing* object instance, return the primitive value
that should be used for this field.
"""
try:
return get_attribute(instance, self.source_attrs) # 执行get_attribute函数,用于根据定义的字段属性,获取不同的数据,
注意该方法没有带self,是一个函数,并不是类方法。
self.source_attrs:以'.'分割的列表,会被使用为反射获取属性
except (KeyError, AttributeError) as exc:
if self.default is not empty:
return self.get_default()
if self.allow_null:
return None
if not self.required:
raise SkipField()
msg = (
'Got {exc_type} when attempting to get a value for field '
'`{field}` on serializer `{serializer}`.\nThe serializer '
'field might be named incorrectly and not match '
'any attribute or key on the `{instance}` instance.\n'
'Original exception text was: {exc}.'.format(
exc_type=type(exc).__name__,
field=self.field_name,
serializer=self.parent.__class__.__name__,
instance=instance.__class__.__name__,
exc=exc
)
)
raise type(exc)(msg)
调用get_attribute函数,进一步出来,需要分析self.source_attrs参数,下面是self.source_attrs部分源码:
if self.source == '*':
self.source_attrs = []
else:
self.source_attrs = self.source.split('.')
#self.source是我们自定义字段传入的source参数,如:gp=serializers.CharField(source='group.name'),sss=serializers.CharField(source='get_user_type_display')
最后分割变成['group','name']
以上分析self.source_attrs是一个列表(由source参数按点分割而来),继续回到get_attribute函数,下面是其源码:
def get_attribute(instance, attrs):
"""
Similar to Python's built in `getattr(instance, attr)`,
but takes a list of nested attributes, instead of a single attribute. Also accepts either attribute lookup on objects or dictionary lookups.
""" # attrs:['group','name']或者['get_user_type_display',]
for attr in attrs: # 循环列表
try:
if isinstance(instance, collections.Mapping): #若果是model字段映射(DRF的内部字段转化),直接调用model类的
instance = instance[attr]#重新赋值,此时的instance已经改变
else:
instance = getattr(instance, attr) #否则,使用反射获取结果,如instance=getattr(userinfo_obj,group)
except ObjectDoesNotExist:
return None
if is_simple_callable(instance): #判断是否是可执行,此时如我们示例中的get_user_type_display,其判断过程在类似下面TIPS中,这里不再做过多说明
try:
instance = instance() #重新赋值,加括号进行执行
except (AttributeError, KeyError) as exc:
# If we raised an Attribute or KeyError here it'd get treated
# as an omitted field in `Field.get_attribute()`. Instead we
# raise a ValueError to ensure the exception is not masked.
raise ValueError('Exception raised in callable attribute "{0}"; original exception was: {1}'.format(attr, exc)) return instance
TIPS:判断是否是可执行方法
import types def func(arg):
if isinstance(arg,types.FunctionType,):
print('yes')
arg()
else:
print('NO') func(lambda :1)
func(111) #执行结果:
yes
NO
从上面的源码分析来看,序列化本质是使用了django的orm的QuerSet或者单个model对象特性,利用反射或者方法进行序列化。
| 四、数据验证 |
1.基本验证
DRF的数据验证功能与django的form有点类似,示例:获取数据使用的是全局配置的json解析器,在解析器中已经介绍:
class CheckGroupData(serializers.Serializer):
id=serializers.IntegerField(error_messages={'required':'id不能为空'})
name=serializers.CharField(error_messages={'required':'组名不能为空'})
class GroupView(APIView):
def get(self,request,*args,**kwargs): group_id=kwargs.get('xxx')
group_obj=models.UserGroup.objects.get(id=group_id)
res=UserGroupSerializer(instance=group_obj,many=False) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False)) def post(self,request,*args,**kwargs):
ret=CheckGroupData(data=request.data)#这里配置了全局json解析器,使用request.data直接获取数据
if ret.is_valid():
print(ret.validated_data)
#获取某个字段数据ret.validated_data.get('name')
return HttpResponse('数据验证成功')
else:
print(ret.errors)
return HttpResponse('数据验证失败')
使用postman向http://127.0.0.1:8000/api/v1/group/1,发送json数据,结果如下:
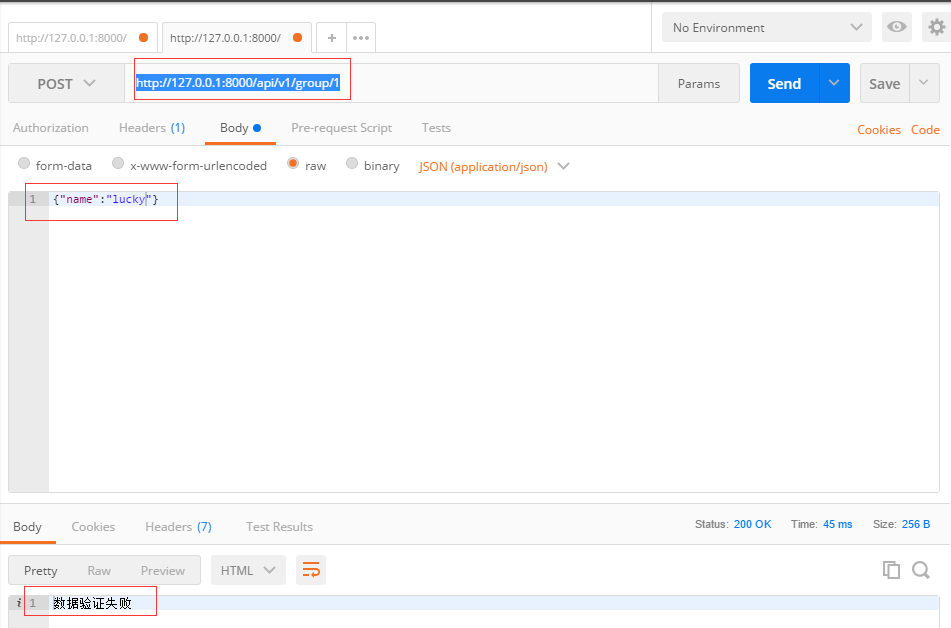
后台结果:
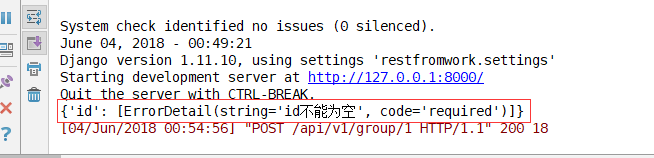
验证流程生效。
2.自定义验证
和django form功能一样,DRF序列化支持自定义数据验证,示例:
#自定义验证规则
class MyValidation(object):
def __init__(self,base):
self.base = base def __call__(self, value): #value是字段值,默认传递
if value == 'wd':
message = "关键字%s不能是%s"%(self.base,value)
raise serializers.ValidationError(message) class MySerializer(serializers.Serializer):
name = serializers.CharField(validators=[MyValidation(base='name_field'),]) class GroupView(APIView):
def get(self,request,*args,**kwargs): group_id=kwargs.get('xxx')
group_obj=models.UserGroup.objects.get(id=group_id)
res=UserGroupSerializer(instance=group_obj,many=False) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False)) def post(self,request,*args,**kwargs):
ret=MySerializer(data=request.data)#这里配置了全局json解析器,使用request.data直接获取数据
if ret.is_valid():
print(ret.validated_data)
#获取某个字段数据ret.validated_data.get('name')
return HttpResponse('数据验证成功')
else:
print(ret.errors)
return HttpResponse('数据验证失败')
发送{"name":"wd"}数据进行验证结果如下:

3.钩子函数
对于自定义验证来说,DRF和django的form组件一样也给我们内置了钩子函数,用于验证。
验证流程:
is_valid-->self.run_validation-->to_internal_value-->to_internal_value-->validate_字段名称(执行字段验证,钩子方法)-->validate_method(钩子验证方法)
validate_字段名称钩子方法验证示例:
class MySerializer(serializers.Serializer):
name = serializers.CharField() def validate_name(self,value): # 验证的字段值
if value.startswith("w"):
raise serializers.ValidationError('name字段不能以w开头')
else:
return value #注意通过验证,必须返回其值 class GroupView(APIView):
def get(self,request,*args,**kwargs): group_id=kwargs.get('xxx')
group_obj=models.UserGroup.objects.get(id=group_id)
res=UserGroupSerializer(instance=group_obj,many=False) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return HttpResponse(json.dumps(res.data,ensure_ascii=False)) def post(self,request,*args,**kwargs):
ret=MySerializer(data=request.data)#这里配置了全局json解析器,使用request.data直接获取数据
if ret.is_valid():
print(ret.validated_data)
#获取某个字段数据ret.validated_data.get('name')
return HttpResponse('数据验证成功')
else:
print(ret.errors)
return HttpResponse('数据验证失败')
同样发送json数据{"name":"wd"}进行验证,结果如下:

Django Rest Framework源码剖析(六)-----序列化(serializers)的更多相关文章
- Django Rest Framework源码剖析(八)-----视图与路由
一.简介 django rest framework 给我们带来了很多组件,除了认证.权限.序列化...其中一个重要组件就是视图,一般视图是和路由配合使用,这种方式给我们提供了更灵活的使用方法,对于使 ...
- Django Rest Framework源码剖析(三)-----频率控制
一.简介 承接上篇文章Django Rest Framework源码剖析(二)-----权限,当服务的接口被频繁调用,导致资源紧张怎么办呢?当然或许有很多解决办法,比如:负载均衡.提高服务器配置.通过 ...
- Django Rest Framework源码剖析(七)-----分页
一.简介 分页对于大多数网站来说是必不可少的,那你使用restful架构时候,你可以从后台获取数据,在前端利用利用框架或自定义分页,这是一种解决方案.当然django rest framework提供 ...
- Django Rest Framework源码剖析(五)-----解析器
一.简介 解析器顾名思义就是对请求体进行解析.为什么要有解析器?原因很简单,当后台和前端进行交互的时候数据类型不一定都是表单数据或者json,当然也有其他类型的数据格式,比如xml,所以需要解析这类数 ...
- Django Rest Framework源码剖析(四)-----API版本
一.简介 在我们给外部提供的API中,可会存在多个版本,不同的版本可能对应的功能不同,所以这时候版本使用就显得尤为重要,django rest framework也为我们提供了多种版本使用方法. 二. ...
- Django Rest Framework源码剖析(二)-----权限
一.简介 在上一篇博客中已经介绍了django rest framework 对于认证的源码流程,以及实现过程,当用户经过认证之后下一步就是涉及到权限的问题.比如订单的业务只能VIP才能查看,所以这时 ...
- Django Rest Framework源码剖析(一)-----认证
一.简介 Django REST Framework(简称DRF),是一个用于构建Web API的强大且灵活的工具包. 先说说REST:REST是一种Web API设计标准,是目前比较成熟的一套互联网 ...
- Django REST framework 源码剖析
前言 Django REST framework is a powerful and flexible toolkit for building Web APIs. 本文由浅入深的引入Django R ...
- 跨站请求伪造(csrf),django的settings源码剖析,django的auth模块
目录 一.跨站请求伪造(csrf) 1. 什么是csrf 2. 钓鱼网站原理 3. 如何解决csrf (1)思路: (2)实现方法 (3)实现的具体代码 3. csrf相关的装饰器 (1)csrf_p ...
随机推荐
- 【mpvue】使用Mpvue撸一个简单的小程序
一.快速创建一个mpvue项目 全局安装 vue-cli (如果有就不需要装了) 创建一个基于mpvue-quickstart模板的新项目,记得选择安装vuex vue init mpvue/ ...
- Python 基于Python实现Ftp文件上传,下载
基于Python实现Ftp文件上传,下载 by:授客 QQ:1033553122 测试环境: Ftp客户端:Windows平台 Ftp服务器:Linux平台 Python版本:Python 2.7 ...
- FileWriter写数据路径问题及关闭和刷新方法的区别
package com.itheima_01; import java.io.FileWriter; import java.io.IOException; /* * 输出流写数据的步骤: * A:创 ...
- springboot 1.3.5升级1.5.9后 默认使用tomcat 8.5版本 get请求报400 异常信息为 The valid characters are defined in RFC 7230 and RFC 3986
1.springboot 1.3.5升级1.5.9后 默认使用tomcat 8.5版本而之前用的是tomcat7 get请求报400 异常信息为 The valid characters are ...
- nginx 配置 非80 的其他 端口
如果nginx的监听端口不是默认的80端口,改为其他非80端口后,后端服务tomcat中的request.getServerPort()方法无法获得正确的端口号,仍然返回到80端口.在response ...
- ADB三个进阶使用
adb通过Wi-Fi连接手机 背景知识 Android系统底层运行着一个服务(adbd),也就是在手机系统内部,用于响应.管理大家在电脑端的adb命令连接,这个服务在启动时候会根据手机的配置监听USB ...
- python新生类和经典类简单说明
经典类: #!/usr/bin/env python #*-* coding:utf-8 *-* class A(): def __init__(self): print 'my name is GF ...
- MSSQL在线文件还原脚本
在线文件还原:如果比较大的MSSQL数据库的损坏只是集中在其中某一个文件或者文件组上,使用在线文件还原技术,只是把坏掉的数据文件或者文件组重建,能节约很多时间.以下是测试脚本(假设损坏的文件时Trn0 ...
- orcl 复杂查询
测试环境: create table bqh6 (xm varchar2(10),bmbh number(2),bmmc varchar2(15),gz int);insert into bqh6 v ...
- python的学习之路day7-socket网络编程
python基础部分学习完了,时间也已经过了两个月左右,感觉没学到什么,可能是我学习之后忘记的太多了. 由于没钱买书,要是去培训就更没钱了,所以在网上找了一本书,感觉还不错,讲的比较好,比较详细. P ...