【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey、groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结:
我的代码实践:https://github.com/wwcom614/Spark
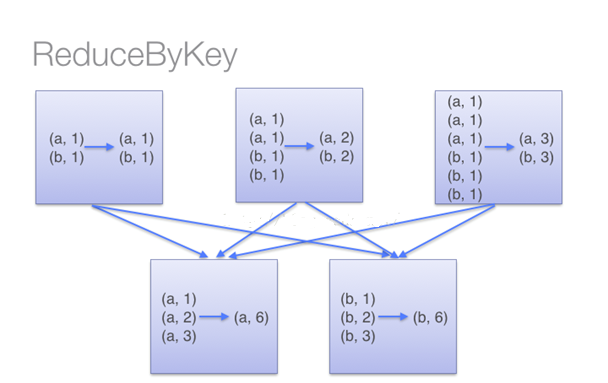
•reduceByKey
用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义;
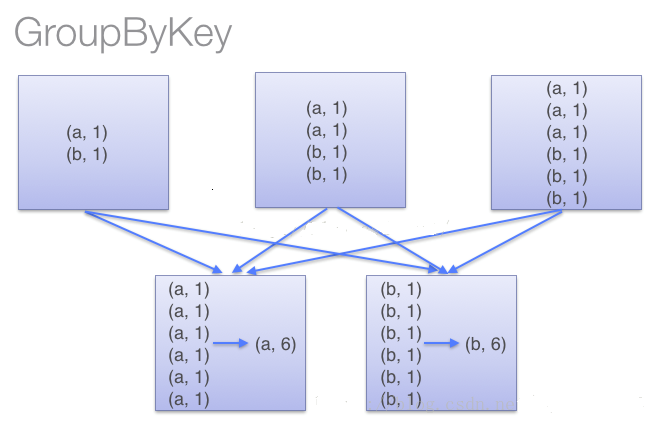
•groupByKey
也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
使用groupByKey时,spark会将所有的键值对进行移动,不会进行局部merge,会导致集群节点之间的开销很大,导致传输延时。
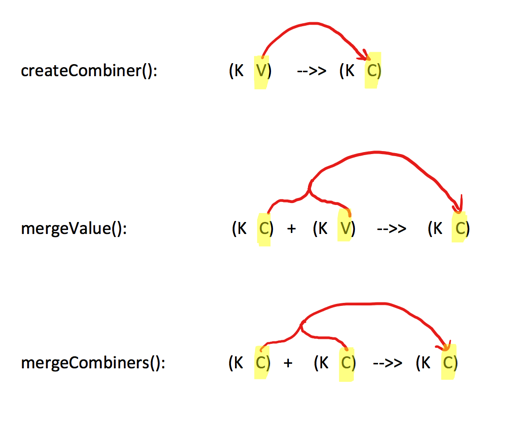
•combineByKey
一个相对底层的基于键进行聚合的基础方法(因为大多数基于键聚合的方法,例如reduceByKey,groupByKey都是用它实现的),所以感觉这个方法还是挺重要的。
该方法的入参主要为前三个:
- createCombiner:遍历一个分区中每个元素,如果不存在,createCombiner创建累加器C,把原变量V放入,对相同K,把V合并成一个集合,例如将(key,88),映射建立集合(key,(88,1))
- mergeValue:遍历一个分区中每个元素,如果已存在,将相同的值累加,例如将(key,(88,1)),(key,(88,1)),mergeValue累加集合为(key,(88,2))
- mergeCombiners:createCombiner 和 mergeValue 是处理单个分区中数据, mergeCombiners是每个分区处理完了,多个分区合并数据使用,例如分区1累加集合值为(key,(88,2)),分区2累加集合值为(key,(88,3)),mergeCombiners累加集合为(key,(88,5))
写个求每个学生的平均成绩的例子
//2个学生及他们的成绩
val scoreList = Array(("ww1", 88), ("ww1", 95), ("ww2", 91), ("ww2", 93), ("ww2", 95), ("ww2", 98)) //将2个学生成绩转为RDD,分2个partition存储
val scoreRDD: RDD[(String, Int)] = sc.parallelize(scoreList, 2)
println("【scoreRDD.partitions.size】:" + scoreRDD.partitions.size)
//分区数,【scoreRDD.partitions.size】:2
println("【scoreRDD.glom.collect】:" + scoreRDD.glom().collect().mkString(",")) //每个分区的内容 //使用combineByKey,按每个学生累积分数和科目数量
val rddCombineByKey: RDD[(String, (Int, Int))] = scoreRDD.combineByKey(v => (v, 1),
(param1: (Int, Int), v) => (param1._1 + v, param1._2 + 1),
(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2))
println("【combineByKey】:" + rddCombineByKey.collect().mkString(","))
//【combineByKey】:(ww2,(377,4)),(ww1,(183,2)) //在map中使用case是scala的用法,按每个学生总成绩/科目数量,得到平均分
val avgScore = rddCombineByKey.map { case (key, value) => (key, value._1 / value._2.toDouble) }
println("【avgScore】:" + avgScore.collect().mkString(","))
//【avgScore】:(ww2,94.25),(ww1,91.5)
说明:
1.首先:各个分区createCombiner 和 mergeValue先干活
第一个分区遍历开始: 数据为
Array(("ww1", 88), ("ww1", 95), ("ww2", 91))
--> 处理(ww1,88), 因为是第一次遇到键“ww1”, 所以调用createCombiner方法 (v)=> (v,1) , 这里就是(ww1,88) =>( ww1, (88,1))
--> 处理(ww1,95),不是第一次遇到键“ww1”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww1,(88,1)),(ww1,95)=>(ww1,(88+95, 1+1))= (ww1,(183,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,91),因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,91) => (ww2, (91,1))
第一个分区遍历结束:返回 (ww1,(183,2) ), ( ww2,(91,1))
第二个分区遍历开始: 数据为
Array(("ww2", 93), ("ww2", 95), ("ww2", 98))
--> 处理(ww2,93), 因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,93 )=>(ww2, (93,1))
--> 处理(ww2,95),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(93,1)),(ww2,95)=>(ww2,(93+95, 1+1))= (ww2,(188,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,98),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(188,2)),(ww2,98)=>(ww2,(188+98, 2+1))= (ww2,(286,3) ) ---(成绩相加,科目数量+1)
第二个分区遍历结束:返回 (ww2,(286,3) )
2.然后:各个分区干完了, mergeCombiners方法汇总处理
--> 处理分区1的ww1,(183,2) ww2,(91,1) ,分区2的ww2,(286,3) , 会调用mergeCombiners方法(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2)),这里就是
( (ww1,(183,2)),(ww2,(91,1)) , (ww2,(286,3)) )=> ( (ww1,(183,2)) , (ww2,(91+286,1+3)) ) = ( (ww1,(183,2)) , (ww2,(377,4)) )
【Spark算子】:reduceByKey、groupByKey和combineByKey的更多相关文章
- Spark算子--reduceByKey
reduceByKey--Transformation类算子 代码示例 result
- (转)Spark 算子系列文章
http://lxw1234.com/archives/2015/07/363.htm Spark算子:RDD基本转换操作(1)–map.flagMap.distinct Spark算子:RDD创建操 ...
- Spark算子总结及案例
spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key-Value数据类型的Tran ...
- Spark算子总结(带案例)
Spark算子总结(带案例) spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- spark算子之DataFrame和DataSet
前言 传统的RDD相对于mapreduce和storm提供了丰富强大的算子.在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功 ...
随机推荐
- IDEA导入MySQL包
点击[Project Structure] 点击[Modules] 在点击下面的界面 找到自己下载的MySQL包就OK了
- 2019.02.09 codeforces451 E. Devu and Flowers(容斥原理)
传送门 题意简述:给出n堆花,对于第j堆,有f[j]朵花,每堆花的颜色不同,现在要从中选出s朵,求方案数. 思路: 假设所有花没有上限直接插板法,现在有了上限我们用容斥扣掉多算的 状压一下再容斥:fi ...
- 系统当前时间system.currenttimemillis与new Date().getTime() 区别
system.currenttimemillis //取到毫秒数,并且执行效率高 new Date().getTime()没他精确
- GAME PROGRAMM
SetConsoleTextAttribute consolehwnd = GetStdHandle(STD_OUTPUT_HANDLE); GetStdHandle(nStdHandle)//是返回 ...
- mysql学习之路_联合查询与子查询
联合查询 联合查询:将多次查询(多条select语句)在记录上进行拼接(字段不会增加). 语法:多条select语句构成,每条select语句获取的字段必须严格一致(但是字段类型无关). Select ...
- Tensorflow RNN_LSTM实例
RNN的一种类型模型被称为长短期记忆网络(LSTM).我觉得这是一个有趣的名字.它听起来也意味着:短期模式长期不会被遗忘. LSTM的精确实现细节不在本文的范围之内.相信我,如果只学习LSTM模型会分 ...
- HDMI ip中的时钟 vid_clk与ls_clk
由TMDS_Bit_clock_Ratio.TMDS_clk和色彩深度,就可以确定出tmds_clk,cdr_clk,vid_clk和ls_clk之间的关系. 1.Tmds_clk时钟频率的确定: 原 ...
- Ubuntu Server 命令行下的默认语言改为英语en_US.UTF-8
源文链接:http://tonychiu.blog.51cto.com/656605/393131 如果Ubuntu Server在安装过程中,选择的是中文(很多新手都会在安装时选择中文,便于上手), ...
- Java数组、集合
Vector类 类似C#的ArrayList.可扩展的数组,带有一些特定方法 Hashtable类 与C#的类似 Enumeration接口 类似C#的枚举器
- Beta阶段第四篇Scrum冲刺博客-Day3
1.站立式会议 提供当天站立式会议照片一张 2.每个人的工作 (有work item 的ID),并将其记录在码云项目管理中: 昨天已完成的工作. 张晨晨:学习新的测试模块需要的东西 郭琪容:学习复习模 ...