Scrapy 框架(二)数据的持久化
scrapy数据的持久化(将数据保存到数据库)
一、建立项目
1、scrapy startproject dushu
2、进入项目
cd dushu
执行:scrapy genspider -t crawl read www.dushu.com
查看:read.py
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1175.html']

注:项目更改了默认模板,使其具有递归性
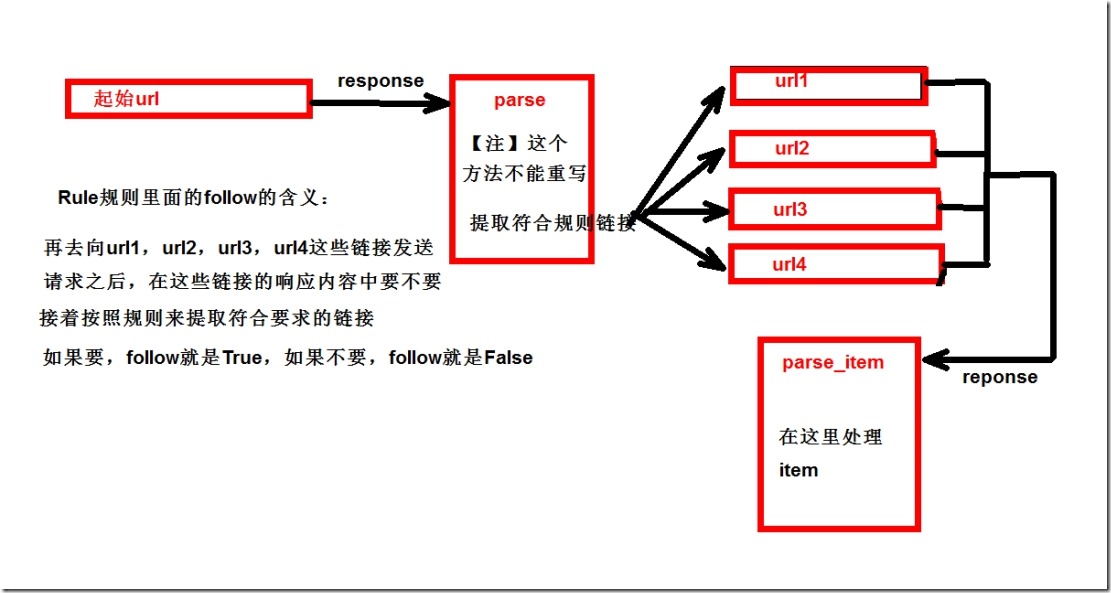
3、模板CrawlSpider具有以下优点:
1)继承自scrapy.Spider;
2)CrawlSpider可以定义规则
在解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求;
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的;
3)模拟使用:
a: 正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
b: xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
c:css用法:links3 = LinkExtractor(restrict_css='.x')
4、更改模板后rules参数解释:
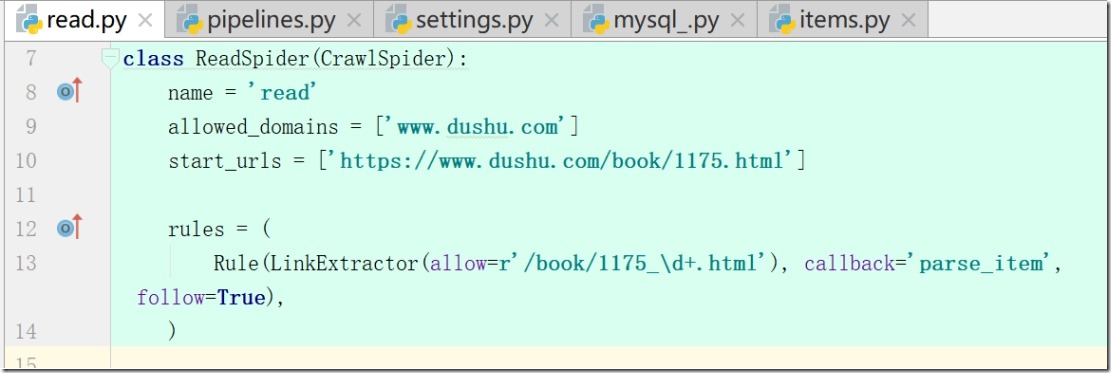
a:参数一 (allow=r'/book/1175_\d+.html') 匹配规则;
b: 参数二 callback='parse_item' ,数据回来之后调用多方法
c: 参数三,True,从新的页面中继续提取链接
注:False,当前页面中提取链接,当前页面start_urls
5、 修改start_urls
start_urls = ['https://www.dushu.com/book/1175.html']
写 def parse_item(self, response)
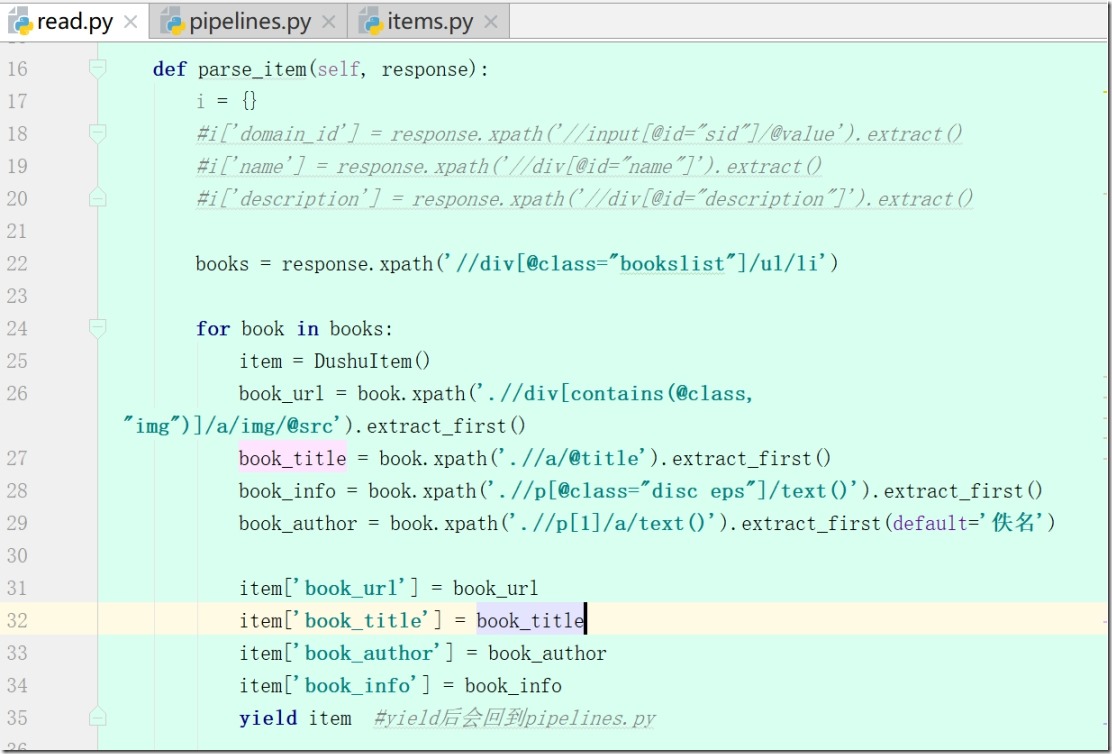
6、items.py
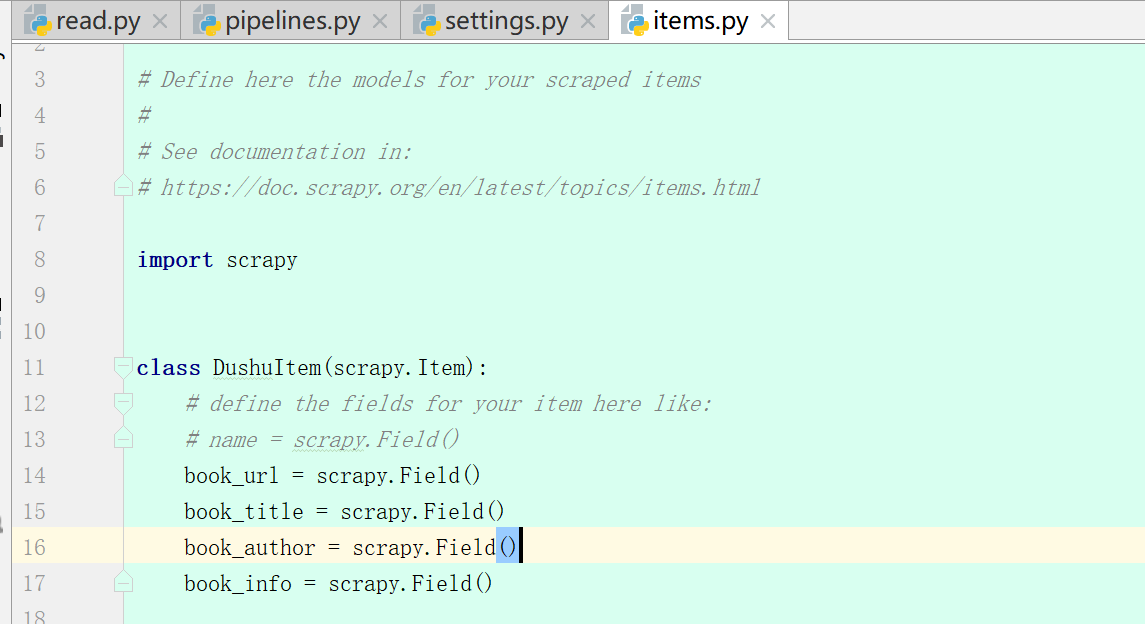
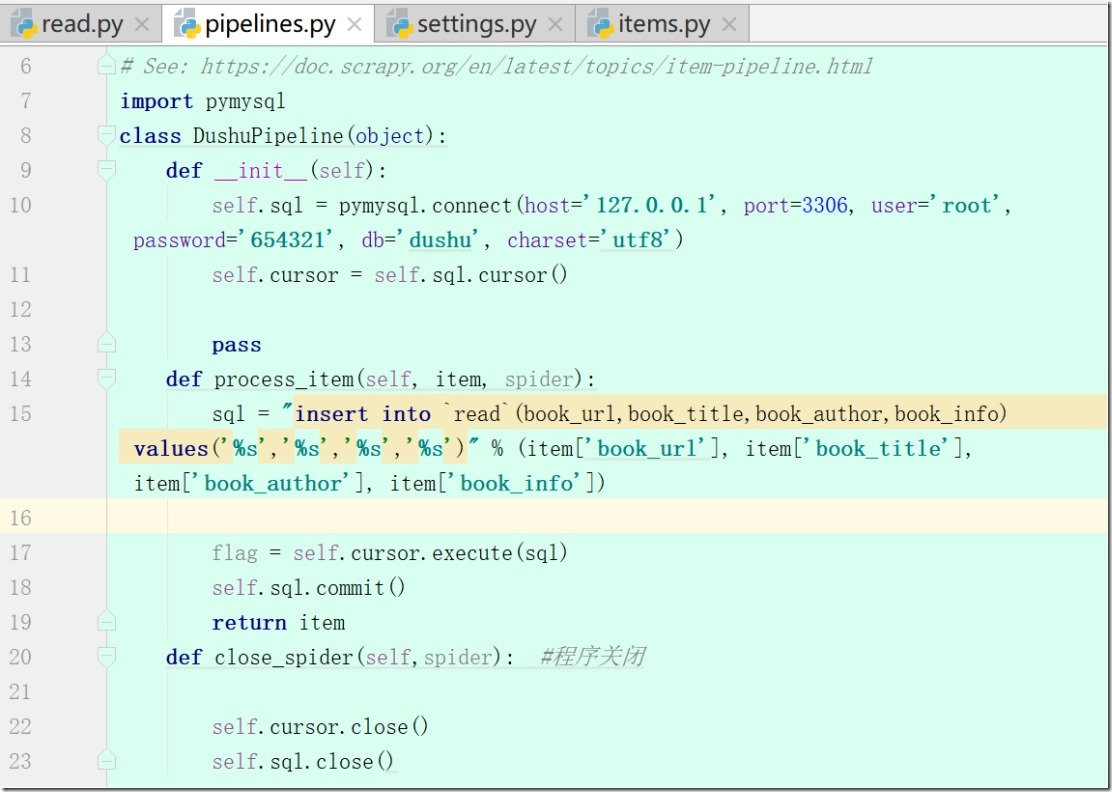
7、pipelines.py(yield后会回到pipelines.py)
1)写def __init__(self): 和 def close_spider(self,spider):
2)连接mysql,保存数据
3)启动mysql (Navicat)
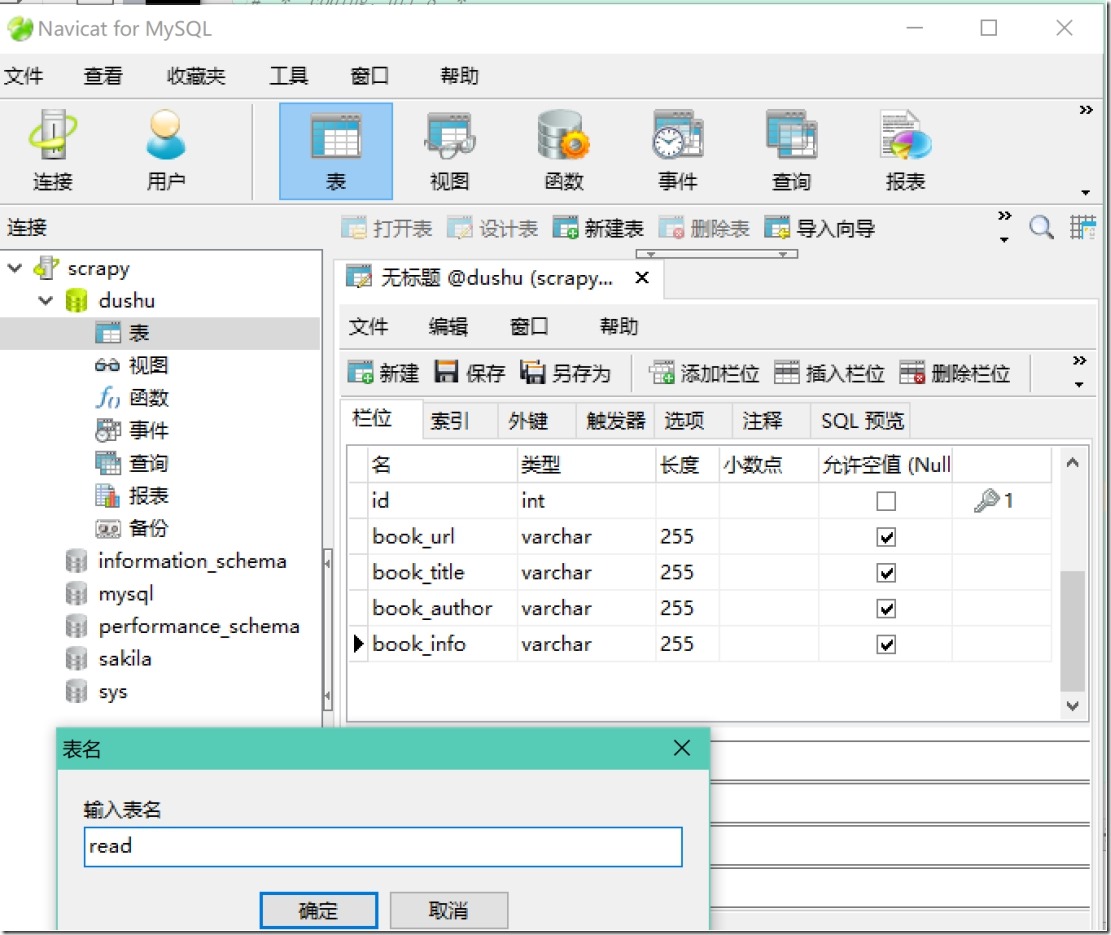
4) 连接数据库def process_item(self, item, spider)
5)setting(robots、USER_AGENT、ITEM_PIPELINES)
6)read.py(修改rules)
8、执行scrapy crawl read,将数据写入数据库
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


Scrapy 框架(二)数据的持久化的更多相关文章
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- scrapy框架基于管道的持久化存储
scrapy框架的使用 基于管道的持久化存储的编码流程 在爬虫文件中数据解析 将解析到的数据封装到一个叫做Item类型的对象 将item类型的对象提交给管道 管道负责调用process_item的方法 ...
- Python项目--Scrapy框架(二)
本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息 环境 win8, python3.7, pycharm 正文 1. 创建scrapy项目文件 在cmd命令行中任意目录下执行 ...
- (六--二)scrapy框架之持久化操作
scrapy框架之持久化操作 基于终端指令的持久化存储 基于管道的持久化存储 1 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过 ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- scrapy框架的另一种分页处理以及mongodb的持久化储存以及from_crawler类方法的使用
一.scrapy框架处理 1.分页处理 以爬取亚马逊为例 爬虫文件.py # -*- coding: utf-8 -*- import scrapy from Amazon.items import ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- c++类内存分布解析
首先使用Visual Studio工具查看类的内存分布,如下: 先选择左侧的C/C++->命令行,然后在其他选项这里写上/d1 reportAllClassLayout,它可以看到所有相关类的内 ...
- js点击获取标签元素
14.数组去重 方法一:利用冒泡 function elementName(evt){ evt = evt|| window.event; // IE: window.event // IE用src ...
- django-缓存的应用
为什么需要缓存? django中文文档: 通常,计算值是昂贵的(即资源匮乏和缓慢),因此将值保存到可快速访问的缓存中可以有巨大的好处,为下一次需要做好准备. 这是一个足够重要和强大的技术,Django ...
- easyui+webuploader+ckeditor实现插件式多图片上传
需求:在ckeditor编辑器上实现多图片上传并要求另外单独选择ckeditor上传的图片作为封面 页面效果说明: 动态效果图: 第一步:页面布局 <html xmlns="http: ...
- BCG库的一个bug
作者:朱金灿 来源:http://blog.csdn.net/clever101 同事在使用BCG库图表组件(BCG库的版本为BCGCBPRO1510)时遇到一个问题,就是图表标题总是出现乱码, ...
- 葡萄城报表模板库再次更新!补充医院Dashboard及房地产销售行业报表
新增模板介绍 近日,葡萄城报表再次对报表模板库进行了更新,除了补充医院用于整体运营监控的5张 Dashboard 报表外,还增加了房地产销售场景中常见的12张报表. 5张 Dashboard 报表模板 ...
- Android--根据子控件的大小自动换行的ViewGroup
1.自定义ViewGroup /** * Created by Administrator on 2016/2/26. * * --------自动换行的ViewGroup----------- */ ...
- 【疑难杂症02】ResultSet.next() 效率低下问题解决
今天帮同事解决了一个问题,记录一下,帮助有需要的人. 一.问题解决经过 事情的经过是这样的,下午我在敲代码的时候,一个同事悄悄走到我身边,问我有没有用没用过Oracle,这下我蒙了,难道我在他们眼中这 ...
- matlab练习程序(异或分类)
clear all; close all; clc; %生成两组已标记数据 randn(); mu1=[ ]; S1=[; 0.5]; P1=mvnrnd(mu1,S1,); mu2=[ ]; S2= ...
- python 流程控制(条件语句)
1,python流程控制单条件基本语句 2,python流程流程多条件控制语句 3,三元运算 1,python流程控制单条件基本语句 if 判断条件: 执行语句…… else: 执行语句…… 判断条件 ...