【C#数据结构系列】树和二叉树
线性结构中的数据元素是一对一的关系,树形结构是一对多的非线性结构,非常类似于自然界中的树,数据元素之间既有分支关系,又有层次关系。树形结构在现实世界中广泛存在,如家族的家谱、一个单位的行政机构组织等都可以用树形结构来形象地表示。树形结构在计算机领域中也有着非常广泛的应用,如 Windows 操作系统中对磁盘文件的管理、编译程序中对源程序的语法结构的表示等都采用树形结构。在数据库系统中,树形结构也是数据的重要组织形式之一。树形结构有树和二叉树两种,树的操作实现比较复杂,但树可以转换为二叉树进行处理,所以,我们主要讨论二叉树。
一:树
1.1 树的定义
树(Tree)是 n(n≥0)个相同类型的数据元素的有限集合。树中的数据元素叫结点(Node)。n=0 的树称为空树(Empty Tree);对于 n>0 的任意非空树 T 有:
(1)有且仅有一个特殊的结点称为树的根(Root)结点,根没有前驱结点;
(2)若n>1,则除根结点外,其余结点被分成了m(m>0)个互不相交的集合T 1 ,T 2 ,…,T m ,其中每一个集合T i (1≤i≤m)本身又是一棵树。树T 1 ,T 2 ,…,T m
称为这棵树的子树(Subtree)。
由树的定义可知,树的定义是递归的,用树来定义树。因此,树(以及二叉树)的许多算法都使用了递归。
树的形式定义为:树(Tree)简记为 T,是一个二元组,
T = (D, R)
其中:D 是结点的有限集合;
R 是结点之间关系的有限集合。
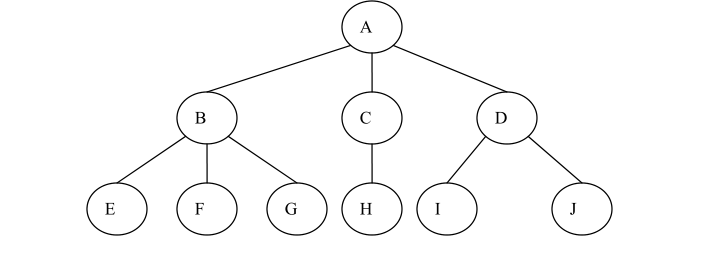
图 1.1
从树的定义和上图的示例可以看出,树具有下面两个特点:
(1)树的根结点没有前驱结点,除根结点之外的所有结点有且只有一个前驱结点。
(2)树中的所有结点都可以有零个或多个后继结点。
实际上,第(1)个特点表示的就是树形结构的“一对多关系”中的“一”,第(2)特点表示的是“多”。
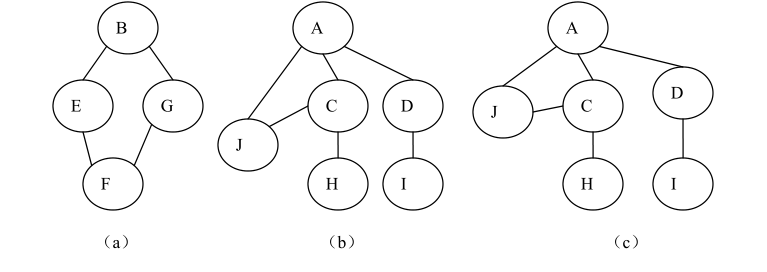
由此特点可知,下图 所示的都不是树。
1.2 树的相关术语
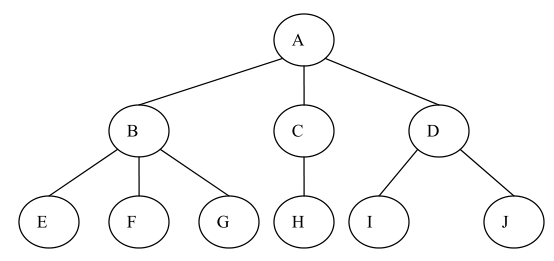
1、结点(Node):表示树中的数据元素,由数据项和数据元素之间的关系组成。在图 1.1中,共有 10 个结点。
2、结点的度(Degree of Node):结点所拥有的子树的个数,在图 1.1 中,结点 A 的度为 3。
3、树的度(Degree of Tree):树中各结点度的最大值。在图 1.1 中,树的度为3。
4、叶子结点(Leaf Node):度为 0 的结点,也叫终端结点。在图 1.1 中,结点 E、F、G、H、I、J 都是叶子结点。
5、分支结点(Branch Node):度不为 0 的结点,也叫非终端结点或内部结点。在图 1.1 中,结点 A、B、C、D 是分支结点。
6、孩子(Child):结点子树的根。在图 1.1 中,结点 B、C、D 是结点 A 的孩子。
7、双亲(Parent):结点的上层结点叫该结点的双亲。在图 1.1 中,结点 B、C、D 的双亲是结点 A。
8、祖先(Ancestor):从根到该结点所经分支上的所有结点。在图 1.1 中,结点 E 的祖先是 A 和 B。
9、子孙(Descendant):以某结点为根的子树中的任一结点。在图 1.1 中,除A 之外的所有结点都是 A 的子孙。
10、兄弟(Brother):同一双亲的孩子。在图 1.1 中,结点 B、C、D 互为兄弟。
11、结点的层次(Level of Node):从根结点到树中某结点所经路径上的分支数称为该结点的层次。根结点的层次规定为 1,其余结点的层次等于其双亲结点的层次加 1。
12、堂兄弟(Sibling):同一层的双亲不同的结点。在图 1.1 中,G 和 H 互为堂兄弟。
13、树的深度(Depth of Tree):树中结点的最大层次数。在图 1.1 中,树的深度为 3。
14、无序树(Unordered Tree):树中任意一个结点的各孩子结点之间的次序构成无关紧要的树。通常树指无序树。
15、有序树(Ordered Tree):树中任意一个结点的各孩子结点有严格排列次序的树。二叉树是有序树,因为二叉树中每个孩子结点都确切定义为是该结点的左孩子结点还是右孩子结点。
16、森林(Forest):m(m≥0)棵树的集合。自然界中的树和森林的概念差别很大,但在数据结构中树和森林的概念差别很小。从定义可知,一棵树有根结点和m 个子树构成,若把树的根结点删除,则树变成了包含 m 棵树的森林。当然,根据定义,一棵树也可以称为森林。
1.3 树的逻辑表示
树的逻辑表示方法很多,下面是常见的表示方法。
1、直观表示法
它象日常生活中的树木一样。整个图就象一棵倒立的树,从根结点出发不断扩展,根结点在最上层,叶子结点在最下面,如图 1.1 所示。
2、凹入表示法
每个结点对应一个矩形,所有结点的矩形都右对齐,根结点用最长的矩形表示,同一层的结点的矩形长度相同,层次越高,矩形长度越短,图 1.1 中的树的凹入表示法如下

3、广义表表示法
用广义表的形式表示根结点排在最前面,用一对圆括号把它的子树结点括起来,子树结点用逗号隔开。图 1.1 的树的广义表表示如下:
(A(B(E,F,G),C(H),D(I,J)))
4、嵌套表示法
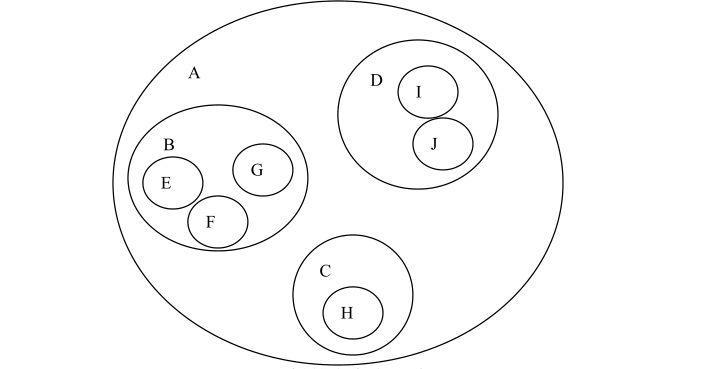
类似数学中所说的文氏图表示法,如下图 所示。
二:二叉树
2.1 二叉树的定义
二叉树(Binary Tree)是 n(n≥0)个相同类型的结点的有限集合。n=0 的二叉树称为空二叉树(Empty Binary Tree);对于 n>0 的任意非空二叉树有:
(1)有且仅有一个特殊的结点称为二叉树的根(Root)结点,根没有前驱结点;
(2)若n>1,则除根结点外,其余结点被分成了 2 个互不相交的集合T L ,T R ,而T L 、T R 本身又是一棵二叉树,分别称为这棵二叉树的左子树(Left Subtree)和右子树(Right Subtree)。
二叉树的形式定义为:二叉树(Binary Tree)简记为 BT,是一个二元组,
BT = (D, R)
其中:D 是结点的有限集合;
R 是结点之间关系的有限集合。
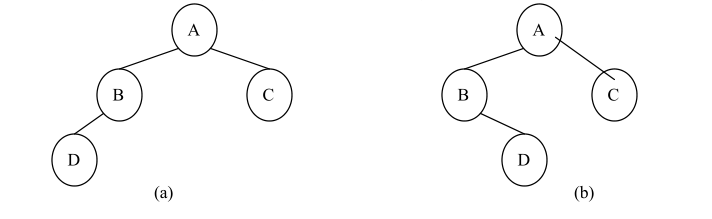
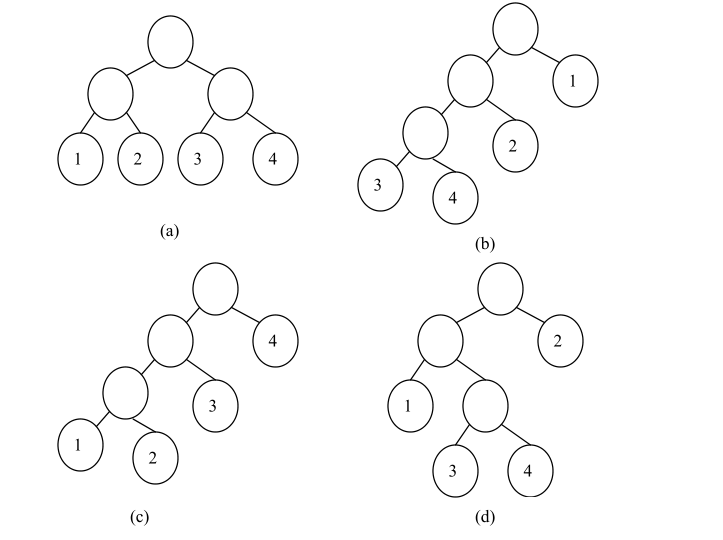
由树的定义可知,二叉树是另外一种树形结构,并且是有序树,它的左子树和右子树有严格的次序,若将其左、右子树颠倒,就成为另外一棵不同的二叉树。因此,图 (a)和图 (b)所示是不同的二叉树。
二叉树的形态共有 5 种:空二叉树、只有根结点的二叉树、右子树为空的二叉树、左子树为空的二叉树和左、右子树非空的二叉树。二叉树的 5 种形态如下图所示。

三种特殊的二叉树:
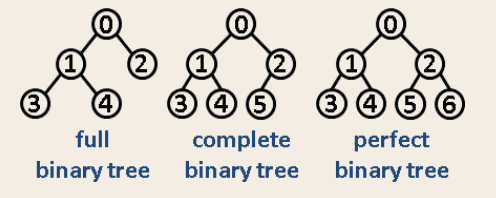
(1)完美二叉树(Perfect Binary Tree):Every node except the leaf nodes have two children and every level (last level too) is completely filled. 除了叶子结点之外的每一个结点都有两个孩子,每一层(当然包含最后一层)都被完全填充。
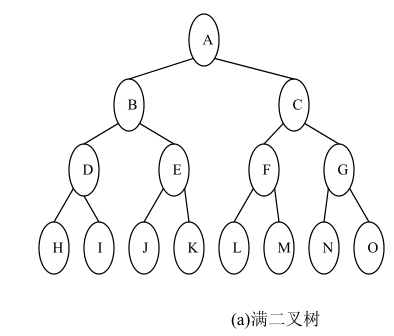
(2)完全二叉树(Complete Binary Tree):Every level except the last level is completely filled and all the nodes are left justified. 除了最后一层之外的其他每一层都被完全填充,并且所有结点都保持向左对齐。
(若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。【来源百度百科】)
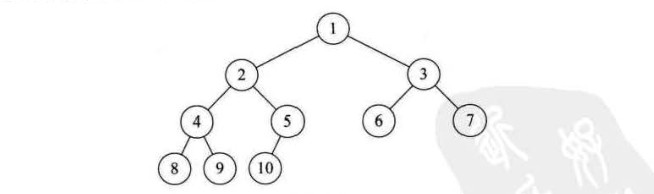
这是一种有些难以理解的特殊二叉树,首先从字面上要区分,“完全”和“满”的差异,满二叉树一定是一棵完全二叉树,但完全二叉树不一定是满的。
(3)完满二叉树(Full Binary Tree):Every node except the leaf nodes have two children. 除了叶子结点之外的每一个结点都有两个孩子结点。
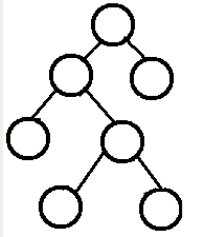
完满(Full)二叉树 v.s. 完全(Complete)二叉树 v.s. 完美(Perfect)二叉树
2.2 二叉树的特性
性质 1 :版本一:若二叉树的层次从0开始,则在二叉树的第i层至多有2^i个结点(i>=0)。【Thomas和Charles等人写的《算法导论》和 Robert Sedgewick所著的《算法》从 level 0 开始定义】
版本二:若二叉树的层次从1开始,则在二叉树的第i层至多有2^(i-1)个结点(i>=1)。【严蔚敏老师的《数据结构》则是从level 1开始定义的】
性质 2: 若规定空树的深度为 0,则深度为k的二叉树最多有 2^k -1 个结点(满二叉树)(k≥0)。
性质 3 :具有n个结点的完全二叉树的深度k为log 2 n+1。
性质 4: 对于一棵非空二叉树,如果叶子结点(度为0)数目为m ,度为 2 的结点数目为n,则有m= n +1。
性质 5: 对于具有 n 个结点的完全二叉树,如果按照从上到下和从左到右的顺序对所有结点从 1 开始编号,则对于序号为 i 的结点,有:
(1)如果 i>1,则序号为 i 的结点的双亲结点的序号为 i/2(“/”表示整除);如果 i=1,则该结点是根结点,无双亲结点。
(2)如果 2i≤n,则该结点的左孩子结点的序号为 2i;若 2i>n,则该结点无左孩子。
(3)如果 2i+1≤n,则该结点的右孩子结点的序号为 2i+1;若 2i+1>n,则该结点无右孩子
2.3 二叉树的存储结构
二叉树的存储结构主要有三种:顺序存储结构、二叉链表存储结构和三叉链表存储结构。
2.3.1:二叉树的顺序存储结构
对于一棵完全二叉树,由性质 5 可计算得到任意结点 i 的双亲结点序号、左孩子结点序号和右孩子结点序号。所以,完全二叉树的结点可按从上到下和从左到右的顺序存储在一维数组中,其结点间的关系可由性质 5 计算得到,这就是二叉树的顺序存储结构。图 (a)所示的二叉树的顺序存储结构为:

但是,对于一棵非完全二叉树,不能简单地按照从上到下和从左到右的顺序存放在一维数组中,因为数组下标之间的关系不能反映二叉树中结点之间的逻辑关系。所以,应该对一棵非完全二叉树进行改造,增加空结点(并不存在的结点)使之成为一棵完全二叉树,然后顺序存储在一维数组中。图 (b)是图 (a)的顺序存储示意图
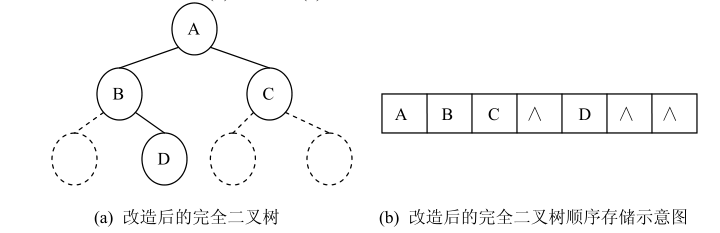
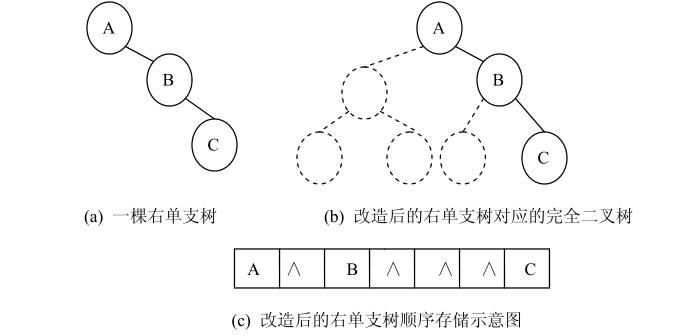
显然,顺序存储对于需增加很多空结点才能改造为一棵完全二叉树的二叉树不适合,因为会造成空间的大量浪费。实际上,采用顺序存储结构,是对非线性的数据结构线性化,用线性结构来表示二叉树的结点之间的逻辑关系,所以,需要增加空间。一般来说,有大约一半的空间被浪费。最差的情况是右单支树,如下图 所示,一棵深度为k的右单支树,只有k个结点,却需要分配 2 k -1 个存储单元。
2.3.2:二叉树的二叉链表存储结构
二叉树的二叉链表存储结构是指二叉树的结点有三个域:一个数据域和两个引用域,数据域存储数据,两个引用域分别存放其左、右孩子结点的地址。当左孩子或右孩子不存在时,相应域为空,用符号 NULL 或∧表示。结点的存储结构如下所示:

下图是图2.3.1(a)所示的二叉树的二叉链表示意图。图 (a)是不带头结点的二叉链表,图 (b)是带头结点的二叉链表。

由上图所示的二叉树有 4 个结点,每个结点中有两个引用,共有 8 个引用,其中 3 个引用被使用,5 个引用是空的。由性质 4 可知:由 n 个结点构成的二叉链表中,只有 n-1 个引用域被使用,还有 n+1 个引用域是空的。
2.3.3:二叉树的三叉链表存储结构
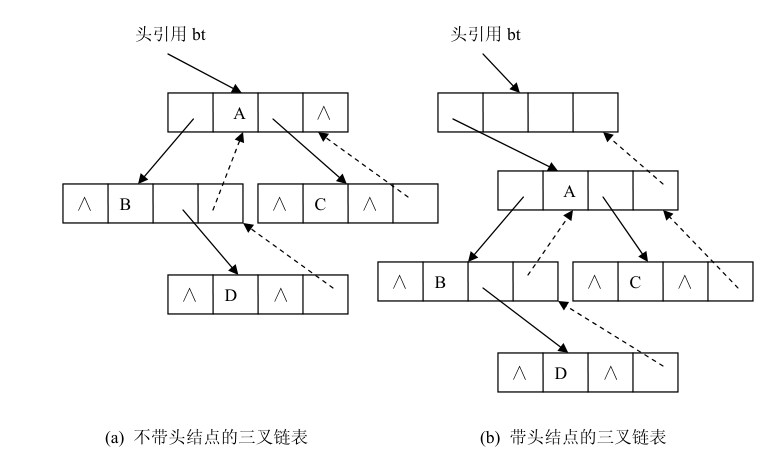
使用二叉链表,可以非常方便地访问一个结点的子孙结点,但要访问祖先结点非常困难。可以考虑在每个结点中再增加一个引用域存放其双亲结点的地址信息,这样就可以通过该引用域非常方便地访问其祖先结点。这就是下面要介绍的三叉链表。
二叉树的三叉链表存储结构是指二叉树的结点有四个域:一个数据域和三个引用域,数据域存储数据,三个引用域分别存放其左、右孩子结点和双亲结点的地址。当左、右孩子或双亲结点不存在时,相应域为空,用符号 NULL 或∧表示。结点的存储结构如下所示:

下图 (a)是不带头结点的三叉链表,图 (b)是带头结点的三叉链表。
2.4 二叉链表存储结构的类实现
二叉树的二叉链表的结点类有 3 个成员字段:数据域字段 data、左孩子引用域字段 lChild 和右孩子引用域字段 rChild。二叉树的二叉链表的结点类的实现如下所示。
public class Node<T>
{
public T Data { get; set; }
public Node<T> LChild { get; set; }
public Node<T> RChild { get; set; } public Node(T data, Node<T> lp, Node<T> rp)
{
Data = data;
LChild = lp;
RChild = rp;
} public Node(Node<T> lp, Node<T> rp)
{
Data = default(T);
LChild = lp;
RChild = rp;
} public Node(T data)
{
Data = data;
LChild = null;
RChild = null;
} public Node()
{
Data = default(T);
LChild = null;
RChild = null;
}
}
不带头结点的二叉树的二叉链表比带头结点的二叉树的二叉链表的区别与不带头结点的单链表与带头结点的单链表的区别一样。下面只介绍不带头结点的二叉树的二叉链表的类 BiTree<T>。BiTree<T>类只有一个成员字段 head 表示头引用。以下是 BiTree<T>类的实现。
public class BiTree<T>
{
//头引用属性
public Node<T> Head { get; set; } //构造器
public BiTree()
{
Head = null;
} //构造器
public BiTree(T val)
{
Node<T> p = new Node<T>(val);
Head = p;
} //构造器
public BiTree(Node<T> lp, Node<T> rp)
{
Node<T> p = new Node<T>(lp, rp);
Head = p;
} //构造器
public BiTree(T val, Node<T> lp, Node<T> rp)
{
Node<T> p = new Node<T>(val, lp, rp);
Head = p;
} //判断是否是空二叉树
public bool IsEmpty()
{
if (Head == null)
{
return true;
}
else
{
return false;
}
} //获取根结点
public Node<T> Root()
{
return Head;
} //获取结点的左孩子结点
public Node<T> GetLChild(Node<T> p)
{
return p.LChild;
} //获取结点的右孩子结点
public Node<T> GetRChild(Node<T> p)
{
return p.RChild;
} //将结点p的左子树插入值为val的新结点,
//原来的左子树成为新结点的左子树
public void InsertL(T val, Node<T> p)
{
Node<T> tmp = new Node<T>(val);
tmp.LChild = p.LChild;
p.LChild = tmp;
} //将结点p的右子树插入值为val的新结点,
//原来的右子树成为新结点的右子树
public void InsertR(T val, Node<T> p)
{
Node<T> tmp = new Node<T>(val);
tmp.RChild = p.RChild;
p.RChild = tmp;
} //若p非空,删除p的左子树
public Node<T> DeleteL(Node<T> p)
{
if ((p == null) || (p.LChild == null))
{
return null;
}
Node<T> tmp = p.LChild;
p.LChild = null;
return tmp;
} //若p非空,删除p的右子树
public Node<T> DeleteR(Node<T> p)
{
if ((p == null) || (p.RChild == null))
{
return null;
}
Node<T> tmp = p.RChild;
p.RChild = null;
return tmp;
} //判断是否是叶子结点
public bool IsLeaf(Node<T> p)
{
if ((p != null) && (p.LChild == null) && (p.RChild == null))
{
return true;
}
else
{
return false;
}
}
}
2.5 二叉树的遍历
实际上,遍历是将二叉树中的结点信息由非线性排列变为某种意义上的线性排列。也就是说,遍历操作使非线性结构线性化。
由二叉树的定义可知,一棵二叉树由根结点、左子树和右子树三部分组成,若规定 D、L、R 分别代表遍历根结点、遍历左子树、遍历右子树,则二叉树的遍历方式有 6 种:DLR、DRL、LDR、LRD、RDL、RLD。由于先遍历左子树和先遍历右子树在算法设计上没有本质区别,所以,只讨论三种方式:DLR(先序遍历)、LDR(中序遍历)和 LRD(后序遍历)。
除了这三种遍历方式外,还有一种方式:层序遍历(Level Order)。层序遍历是从根结点开始,按照从上到下、从左到右的顺序依次访问每个结点一次仅一次。
1、先序遍历(DLR)
先序遍历的基本思想是:首先访问根结点,然后先序遍历其左子树,最后先序遍历其右子树。先序遍历的递归算法实现如下,注意:这里的访问根结点是把根结点的值输出到控制台上。当然,也可以对根结点作其它处理。
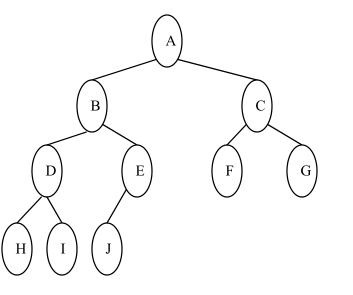
完全二叉树
public static void PreOrder<T>(Node<T> root)
{
//根结点为空
if (root == null)
{
return;
} //处理根结点
Console.WriteLine("{0}", root.Data); //先序遍历左子树
PreOrder(root.LChild); //先序遍历右子树
PreOrder(root.RChild);
}
对于上图所示的完全二叉树,按先序遍历所得到的结点序列为:A B D H I E J C F G
2、中序遍历(LDR)
中序遍历的基本思想是:首先中序遍历根结点的左子树,然后访问根结点,最后中序遍历其右子树。中序遍历的递归算法实现如下:
public static void InOrder<T>(Node<T> root)
{
//根结点为空
if (root == null)
{
return;
}
//中序遍历左子树
InOrder(root.LChild);
//处理根结点
Console.WriteLine("{0}", root.Data);
//中序遍历右子树
InOrder(root.RChild);
}
对于上图所示的完全二叉树,按中序遍历所得到的结点序列为:H D I B J E A F C G
3、后序遍历(LRD)
后序遍历的基本思想是:首先后序遍历根结点的左子树,然后后序遍历根结点的右子树,最后访问根结点。后序遍历的递归算法实现如下:
public void PostOrder<T>(Node<T> root)
{
//根结点为空
if (root == null)
{
return;
} //先序遍历左子树
PostOrder(root.LChild); //先序遍历右子树
PostOrder(root.RChild); //处理根结点
Console.Write("{0} ", root.Data);
}
对于上图所示的二叉树,按后序遍历所得到的结点序列为:H I D J E B F G C A
4、层序遍历(Level Order)
层序遍历的基本思想是:由于层序遍历结点的顺序是先遇到的结点先访问,与队列操作的顺序相同。所以,在进行层序遍历时,设置一个队列,将根结点引用入队,当队列非空时,循环执行以下三步:
(1) 从队列中取出一个结点引用,并访问该结点;
(2) 若该结点的左子树非空,将该结点的左子树引用入队;
(3) 若该结点的右子树非空,将该结点的右子树引用入队;
层序遍历的算法实现如下:
public static void LevelOrder<T>(Node<T> root)
{
//根结点为空
if (root == null)
{
return;
} //设置一个队列保存层序遍历的结点
CSeqQueue<Node<T>> sq = new CSeqQueue<Node<T>>(); //根结点入队
sq.In(root); //队列非空,结点没有处理完
while (!sq.IsEmpty())
{
//结点出队
Node<T> tmp = sq.Out();
//处理当前结点
Console.WriteLine("{0}", tmp.Data);
//将当前结点的左孩子结点入队
if (tmp.LChild != null)
{
sq.In(tmp.LChild);
}
//将当前结点的右孩子结点入队
if (tmp.RChild != null)
{
sq.In(tmp.RChild);
}
}
}
对于上图所示的二叉树,按层次遍历所得到的结点序列为:A B C D E F G H I J
2.6 二叉树的应用
实际场景使用上,用的最多的是二叉平衡树,有种特殊的二叉平衡树就是红黑树,Java集合中的TreeSet和TreeMap,C++STL中的set,map以及LInux虚拟内存的管理,都是通过红黑树去实现的,还有哈弗曼树编码方面的应用,以及B-Tree,B+-Tree在文件系统中的应用。当然二叉查找树可以用来查找和排序。
二叉树在搜索上的优势
数组的搜索比较方便,可以直接使用下标,但删除或者插入就比较麻烦了,而链表与之相反,删除和插入都比较简单,但是查找很慢,这自然也与这两种数据结构的存储方式有关,数组是取一段相连的空间,而链表是每创建一个节点便取一个节点所需的空间,只是使用指针进行连接,空间上并不是连续的。而二叉树就既有链表的好处,又有数组的优点。
2.6.1 二叉查找树
二叉查找树具有很高的灵活性,对其优化可以生成平衡二叉树,红黑树等高效的查找和插入数据结构,后文会介绍。
1: 定义
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
1. 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3. 任意节点的左、右子树也分别为二叉查找树。
4. 没有键值相等的节点(no duplicate nodes)。
如下图,在二叉树的基础上,加上节点之间的大小关系,就是二叉查找树
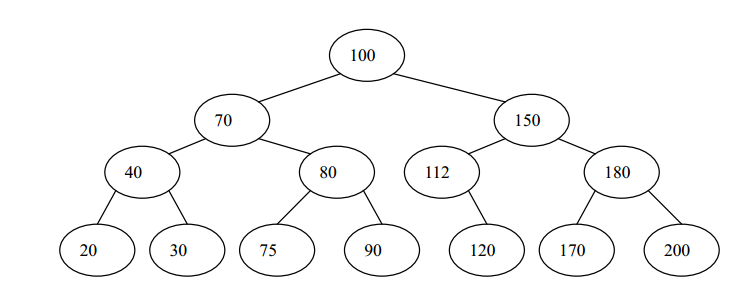
从图中可以看出,二叉查找树中,最左和最右节点即为最小值和最大值
2: 查找
查找操作和二分查找类似,将key和节点的key比较,如果小于,那么就在左节点查找,如果大于,则在右节点查找,如果相等,直接返回Value。
C# 迭代实现
/// <summary>
/// 二叉查找树查找
/// </summary>
/// <param name="bt">二叉树</param>
/// <param name="key">目标值</param>
/// <returns>0:查找成功,1:查找失败</returns>
public int Search(BiTree<int> bt, int key)
{
Node<int> p;
//二叉排序树为空
if (bt.IsEmpty() == true)
{
Console.WriteLine("The Binary Sorting Tree is empty!");
return ;
}
p = bt.Head;
//二叉排序树非空
while (p != null)
{
//存在要查找的记录
if (p.Data == key)
{
Console.WriteLine("Search is Successful!");
return ;
}
//待查找记录的关键码大于结点的关键码
else if (p.Data < key)
{
p = p.RChild;
}
//待查找记录的关键码小于结点的关键码
else
{
p = p.LChild;
}
} return ;
}
3: 插入
插入和查找类似,首先查找有没有和key相同的,如果有,更新;如果没有找到,那么创建新的节点。并更新每个节点的Number值,代码实现如下:
C#实现
/// <summary>
/// 二叉查找树插入
/// </summary>
/// <param name="bt">二叉树</param>
/// <param name="key">目标值</param>
/// <returns>0:查找成功,1:查找失败</returns>
public int Insert(BiTree<int> bt, int key)
{
Node<int> p;
Node<int> parent = new Node<int>();//插入节点的父级
p = bt.Head;
while (p != null)
{
//存在关键码等于key的结点
if (p.Data == key)
{
Console.WriteLine("Record is exist!");
return ;
}
parent = p;
//记录的关键码大于结点的关键码
if (p.Data < key)
{
p = p.RChild;
}
//记录的关键码小于结点的关键码
else
{
p = p.LChild;
}
} p = new Node<int>(key);
//二叉查找树为空
if (parent == null)
{
bt.Head = parent;
}
//待插入记录的关键码小于结点的关键码
else if (p.Data < parent.Data)
{
parent.LChild = p;
}
//待插入记录的关键码大于结点的关键码
else
{
parent.RChild = p;
}
return ;
}
随机插入形成树的动画如下,可以看到,插入的时候树还是能够保持近似平衡状态:

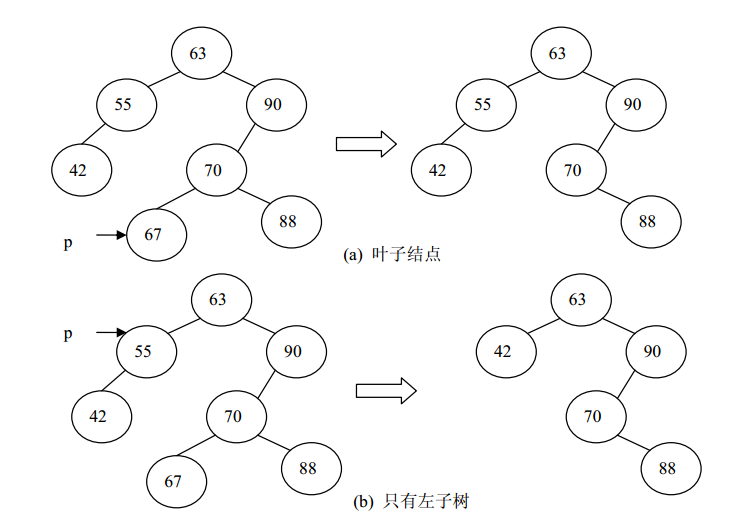
4: 删除
二叉排序树的删除情况如下图所示。


C# 实现
/// <summary>
/// 二叉查找树删除
/// </summary>
/// <param name="bt"></param>
/// <param name="key"></param>
/// <returns></returns>
public int Delete(BiTree<int> bt, int key)
{
Node<int> p;
Node<int> parent = new Node<int>();
Node<int> s = new Node<int>();
Node<int> q = new Node<int>();
//二叉排序树为空
if (bt.IsEmpty() == true)
{
Console.WriteLine("The Binary Sorting is empty!");
return ;
}
p = bt.Head;
parent = p;
//二叉排序树非空
while (p != null)
{
//存在关键码等于key的结点
if (p.Data == key)
{
//结点为叶子结点
if (bt.IsLeaf(p))
{
if (p == bt.Head)
{
bt.Head = null;
}
else if (p == parent.LChild)
{
parent.LChild = null;
}
else
{
parent.RChild = null;
}
}
//结点的右子结点为空而左子结点非空
else if ((p.RChild == null) && (p.LChild != null))
{
if (p == parent.LChild)
{
parent.LChild = p.LChild;
}
else
{
parent.RChild = p.LChild;
}
}
//结点的左子结点为空而右子结点非空
else if ((p.LChild == null) && (p.RChild != null))
{
if (p == parent.LChild)
{
parent.LChild = p.RChild;
}
else
{
parent.RChild = p.RChild;
}
}
//结点的左右子结点均非空
else
{
q = p;
s = p.RChild;
while (s.LChild != null)
{
q = s;
s = s.LChild;
}
p.Data = s.Data;
if (q != p)
{
q.LChild = s.RChild;
}
else
{
q.RChild = s.RChild;
}
}
return ;
}
//待删除记录的关键码大于结点的关键码
else if (p.Data < key)
{
parent = p;
p = p.RChild;
}
else
{
parent = p;
p = p.LChild;
}
}
return -;
}
以上二叉查找树的删除节点的算法不是完美的,因为随着删除的进行,二叉树会变得不太平衡,下面是动画演示。

二叉查找树和二分查找一样,插入和查找的时间复杂度均为lgN,但是在最坏的情况下仍然会有N的时间复杂度。原因在于插入和删除元素的时候,树没有保持平衡。我们追求的是在最坏的情况下仍然有较好的时间复杂度,这就是平衡查找树了。
2.7 树与森林
2.7.1树的存储
树的存储结构包括顺序存储结构和链式存储结构但无论采用哪种存储结构,都要求存储结构不但能存储结点本身的信息,还能存储树中各结点之间的逻辑关系。
1、双亲表示法
从树的定义可知,除根结点外,树中的每个结点都有唯一的一个双亲结点。根据这一特性,可用一组连续的存储空间(一维数组)存储树中的各结点。树中的结点除保存结点本身的信息之外,还要保存其双亲结点在数组中的位置(数组的下标),树的这种表示法称为双亲表示法。
由于树的结点只保存两个信息,所以树的结点用结构体 PNode<T>来表示。结构中有两个字段:数据字段 data 和双亲位置字段 pPos。而树类 PTree<T>只有一个成员数组字段 nodes,用于保存结点。
树的双亲表示法的结点的结构如下所示:

树的双亲表示法的结点的结构体 PNode<T>和树类 PTree<T>的定义如下:
public struct PNode<T>
{
public T data;
public int pPos;
…
}
public class PTree<T>
{
private PNode<T>[] nodes;
…
}
下图分别为树结构和树双亲表示法
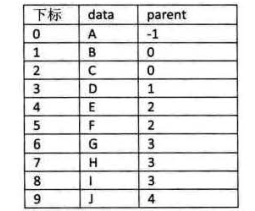
树的双亲表示法对于实现 Parent(t)操作和 Root()操作非常方便。Parent(t)操作可以在常量时间内实现,反复调用 Parent(t)操作,直到遇到无双亲的结点(其 pPos值为-1)时,便找到了树的根,这就是 Root()操作的执行过程。但要实现查找孩子结点和兄弟结点等操作非常困难,因为这需要查询整个数组。要实现这些操作,需要在结点结构中增设存放第1个孩子在数组中的序号的域和存放第1个兄弟在数组中的序号的域。
2、孩子链表表示法
孩子链表表示法也是用一维数组来存储树中各结点的信息。但结点的结构与双亲表示法中结点的结构不同,孩子链表表示法中的结点除保存本身的信息外,不是保存其双亲结点在数组中的序号,而是保存一个链表的第一个结点的地址信息。这个链表是由该结点的所有孩子结点组成。每个孩子结点保存有两个信息,一个是每个孩子结点在一维数组中的序号,另一个是下一个孩子结点的地址信息。
孩子结点的结构如下所示:
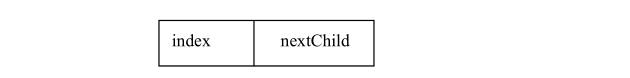
孩子结点类 ChildNode 的定义如下
public class ChildNode
{
private int index;
private ChildNode nextChild;
…
}
树结构和树孩子链表表示法如下图:
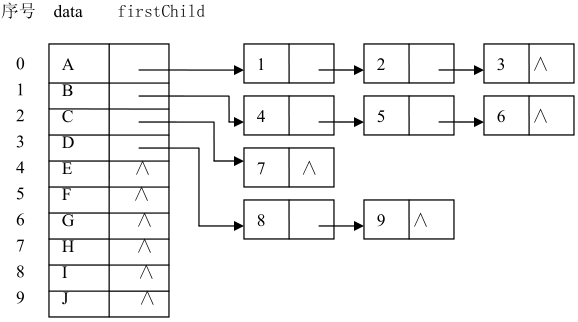
树的孩子链表表示法对于实现查找孩子结点等操作非常方便,但对于实现查找双亲结点、兄弟结点等操作则比较困难。
3、孩子兄弟表示法
这是一种常用的数据结构,又称二叉树表示法,或二叉链表表示法,即以二叉链表作为树的存储结构。每个结点除存储本身的信息外,还有两个引用域分别存储该结点第一个孩子的地址信息和下一个兄弟的地址信息。树类 CSTree<T>只有一个成员字段 head,表示头引用。
树的孩子兄弟表示法的结点的结构如下所示:

树的孩子兄弟表示法的结点类 CSNode<T>的定义如下:
public class CSNode<T>
{
private T data;
private CSNode<T> firstChild;
private CSNode<T> nextSibling;
…
}
树类 CSTree<T>的定义如下:
public class CSTree<T>
{
private CSNode<T> head;;
…
}
树的孩子兄弟表示法如下

树的孩子兄弟表示法对于实现查找孩子、兄弟等操作非常方便,但对于实现查找双亲结点等操作则非常困难。如果在树的结点中再增加一个域来存储孩子的双亲结点的地址信息,则就可以较方便地实现上述操作了。
2.7.2 树、森林与二叉树的转换
从树的孩子兄弟表示法可知,树可以用二叉链表进行存储,所以,二叉链表可以作为树和二叉树之间的媒介。也就是说,借助二叉链表,树和二叉树可以相互进行转换。从物理结构来看,它们的二叉链表是相同的,只是解释不同而已。并且,如果设定一定的规则,就可用二叉树来表示森林,森林和二叉树也可以相互进行转换。
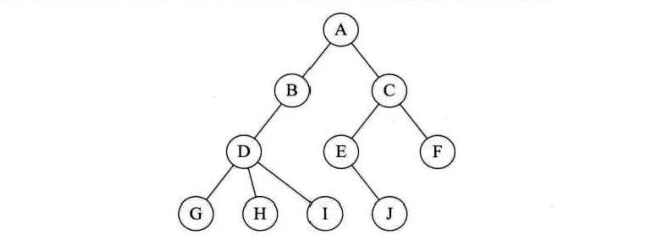
1、树转换为二叉树
由于二叉树是有序的,为了避免混淆,对于无序树,我们约定树中的每个结点的孩子结点按从左到右的顺序进行编号。如上图所示的树,根结点 A 有三个孩子 B、C、D,规定结点 B 是结点 A 的第一个孩子,结点 C 是结点 A 的第 2个孩子,结点 D 是结点 A 的第 3 个孩子。
将树转换成二叉树的步骤是:
(1)加线。就是在所有兄弟结点之间加一条连线;
(2)抹线。就是对树中的每个结点,只保留他与第一个孩子结点之间的连
线,删除它与其它孩子结点之间的连线;
(3)旋转。就是以树的根结点为轴心,将整棵树顺时针旋转一定角度,使
之结构层次分明。
下图是树转换为二叉树的转换过程示意图。

2、森林转换为二叉树
森林是由若干棵树组成,可以将森林中的每棵树的根结点看作是兄弟,由于每棵树都可以转换为二叉树,所以森林也可以转换为二叉树。
将森林转换为二叉树的步骤是:
(1)先把每棵树转换为二叉树;
(2)第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子结点,用线连接起来。当所有的二叉树连接起来后得到的二叉树就是由森林转换得到的二叉树。
森林转换为二叉树的转换过程示意图如下:

3、二叉树转换为树
二叉树转换为树是树转换为二叉树的逆过程,其步骤是:
(1)若某结点的左孩子结点存在,将左孩子结点的右孩子结点、右孩子结
点的右孩子结点……都作为该结点的孩子结点,将该结点与这些右孩子结点用线
连接起来;
(2)删除原二叉树中所有结点与其右孩子结点的连线;
(3)整理(1)和(2)两步得到的树,使之结构层次分明。
二叉树转换为树的过程示意图如下:
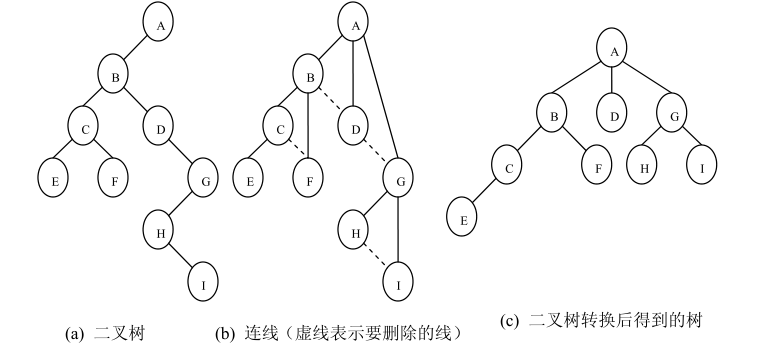
4、二叉树转换为森林
二叉树转换为森林比较简单,其步骤如下:
(1)先把每个结点与右孩子结点的连线删除,得到分离的二叉树;
(2)把分离后的每棵二叉树转换为树;
(3)整理第(2)步得到的树,使之规范,这样得到森林。
2.7.3 树和森林的遍历
1、树的遍历
树的遍历通常有两种方式:
(1)先序遍历,即先访问树的根结点,然后依次先序遍历树中的每棵子树。
(2)后序遍历,即先依次后序遍历树中的每棵子树,然后访问根结点。
对上图中的树所示的树进行先序遍历所得到的结点序列为:A B E F G C H D I J
对此树进行后序遍历得到的结点序列为:E F G B H C I J D A
根据树与二叉树的转换关系以及二叉树的遍历定义可以推知,树的先序遍历与其转换的相应的二叉树的先序遍历的结果序列相同;树的后序遍历与其转换的二叉树的中序遍历的结果序列相同;树的层序遍历与其转换的二叉树的后序遍历的结果序列相同。因此,树的遍历算法可以采用相应的二叉树的遍历算法来实现。
2、森林的遍历
森林的遍历有两种方式。
(1)先序遍历,即先访问森林中第一棵树的根结点,然后先序遍历第一棵树中的每棵子树,最后先序遍历除第一棵树之后剩余的子树森林。
(2)中序遍历,即先中序遍历森林中第一棵树的根结点的所有子树,然后访问第一棵树的根结点,最后中序遍历除第一棵树之后剩余的子树森林。
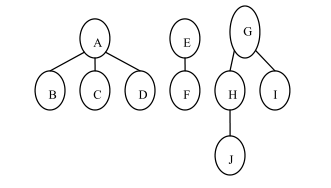
上图所示的森林的先序遍历的结点序列为:A B C D E F G H J I
此森林的中序遍历的结点序列为:B C D A F E J H I G
由森林与二叉树的转换关系以及森林与二叉树的遍历定义可知,森林的先序遍历和中序遍历与所转换得到的二叉树的先序遍历和中序遍历的结果序列相同。
2.8 哈夫曼树
2.8.1 哈夫曼树的基本概念
首先给出定义哈夫曼树所要用到的几个基本概念。
(1)路径(Path):从树中的一个结点到另一个结点之间的分支构成这两个结点间的路径。
(2)路径长度(Path Length):路径上的分支数。
(3)树的路径长度(Path Length of Tree):从树的根结点到每个结点的路径长度之和。在结点数目相同的二叉树中,完全二叉树的路径长度最短。
(4)结点的权(Weight of Node):在一些应用中,赋予树中结点的一个有实际意义的数。
(5)结点的带权路径长度(Weight Path Length of Node):从该结点到树的根结点的路径长度与该结点的权的乘积。
(6)树的带权路径长度(WPL):树中所有叶子结点的带权路径长度之和记为
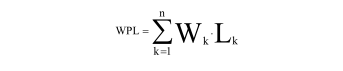
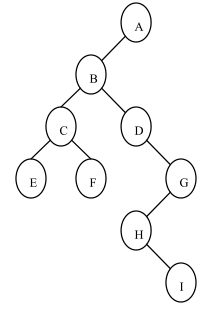
其中,W k 为第k个叶子结点的权值,L k 为第k个叶子结点的路径长度。在下图所示的二叉树中,结点B的路径长度为 1,结点C和D的路径长度为 2,结点E、F和G的路径长度为 3,结点H的路径长度为 4,结点I的路径长度为 5。该树的路径长度为:1+2*2+3*3+4+5=23。如果结点B、C、D、E、F、G、H、I的权分别是 1、2、3、4、5、6、7、8,则这些结点的带权路径长度分别是 1*1、2*2、2*3、3*4、3*5、3*6、4*7、5*8,该树的带权路径长度为 3*5+3*6+5*8=73。
2.8.2 :哈夫曼树(Huffman Tree)
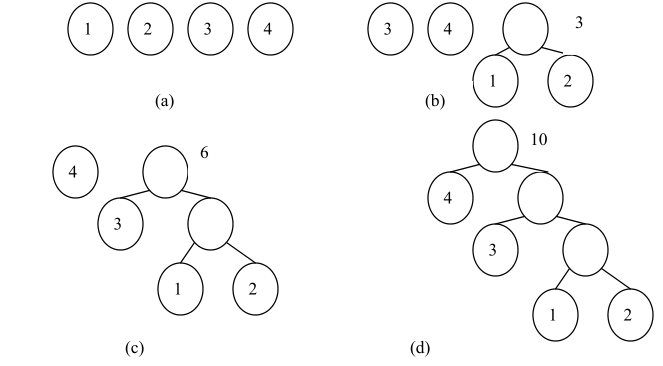
哈夫曼树(Huffman Tree),又叫最优二叉树,指的是对于一组具有确定权值的叶子结点的具有最小带权路径长度的二叉树。在下图所示的的四棵二叉树,都有 4 个叶子结点,其权值分别为 1、2、3、4,它们的带权路径长度分别为:
(a)WPL=1×2+2×2+3×2+4×2=20
(b)WPL=1×1+2×2+3×3+4×3=28
(c)WPL=1×3+2×3+3×2+4×1=19
(d)WPL=2×1+1×2+3×3+4×3=29
其中,图 (c)所示的二叉树的带权路径长度最小,这棵树就是哈夫曼树。可以验证,哈夫曼树的带权路径长度最小。
那么,如何构造一棵哈夫曼树呢?哈夫曼最早给出了一个带有一般规律的算法,俗称哈夫曼算法。现叙述如下:
(1)根据给定的n个权值{w 1 ,w 2 ,…,w n },构造n棵只有根结点的二叉树集合F={T 1 ,T 2 ,…,T n };
(2)从集合 F 中选取两棵根结点的权最小的二叉树作为左右子树,构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左、右子树根结点权值之和。
(3)在集合 F 中删除这两棵树,并把新得到的二叉树加入到集合 F 中;
(4)重复上述步骤,直到集合中只有一棵二叉树为止,这棵二叉树就是哈夫曼树。
由二叉树的性质 4 和哈夫曼树的特点可知,一棵有 n 个叶子结点构造的哈夫曼树共有 2n-1 个结点。
哈夫曼树的构造过程:
2.8.3 哈夫曼树类的实现
由哈夫曼树的构造算法可知,用一个数组存放原来的 n 个叶子结点和构造过程中临时生成的结点,数组的大小为 2n-1。所以,哈夫曼树类 HuffmanTree 中有两个成员字段:data 数组用于存放结点,leafNum 表示哈夫曼树叶子结点的数目。结点有四个域,一个域 weight,用于存放该结点的权值;一个域 lChild,用于存放该结点的左孩子结点在数组中的序号;一个域 rChild,用于存放该结点的右孩子结点在数组中的序号;一个域 parent,用于判定该结点是否已加入哈夫曼树中。哈夫曼树结点的结构为。

所以,结点类 Node 有 4 个成员字段,weight 表示该结点的权值,lChild 和rChild 分别表示左、右孩子结点在数组中的序号,parent 表示该结点是否已加入哈夫曼树中,如果 parent 的值为-1,表示该结点未加入到哈夫曼树中。当该结点已加入到哈夫曼树中时,parent 的值为其双亲结点在数组中的序号。
结点类 Node 的定义如下:
public class HuffmanNode
{
private int weight;//结点权值
private int lChild;///左孩子结点
private int rChild; //右孩子结点
private int parent; //父结点 public int Weight { get; set; }
public int LChild { get; set; }
public int RChild { get; set; }
public int Parent { get; set; } //构造器
public HuffmanNode()
{
weight = ;
lChild = -;
rChild = -;
parent = -;
} //构造器
public HuffmanNode(int w, int lc, int rc, int p)
{
weight = w;
lChild = lc;
rChild = rc;
parent = p;
}
}
哈夫曼树类 HuffmanTree 中只有一个成员方法 Create,它的功能是输入 n 个叶子结点的权值,创建一棵哈夫曼树。哈夫曼树类 HuffmanTree 的实现如下。
public class HuffmanTree
{
private HuffmanNode[] data;//结点数组
private int leafNum;//叶子结点数目 //索引器
public HuffmanNode this[int index]
{
get
{
return data[index];
}
set
{
data[index] = value;
}
} //叶子结点数目属性
public int LeafNum { get; set; } public HuffmanTree(int n)
{
data = new HuffmanNode[ * n - ];
for (int i = ; i < * n - ; i++)
{
data[i] = new HuffmanNode();
}
leafNum = n;
} //创建哈夫曼树
public HuffmanNode[] Create(List<int> list)
{
int max1;
int max2;
int tmp1;
int tmp2;
// 输入 n 个叶子结点的权值
for (int i = ; i < this.leafNum; ++i)
{
data[i].Weight = list[i];
} //处理 n 个叶子结点,建立哈夫曼树
for (int i = ; i < this.leafNum - ; ++i)
{
max1 = max2 = Int32.MaxValue;
tmp1 = tmp2 = ;
//在全部结点中找权值最小的两个结点
for (int j = ; j < this.leafNum + i; ++j)
{
if ((data[j].Weight < max1) && (data[j].Parent == -))
{
max2 = max1;
tmp2 = tmp1;
tmp1 = j;
max1 = data[j].Weight;
}
else if ((data[j].Weight < max2) && (data[j].Parent == -))
{
max2 = data[j].Weight;
tmp2 = j;
}
}
data[tmp1].Parent = this.leafNum + i;
data[this.leafNum + i].Weight = data[tmp1].Weight + data[tmp2].Weight;
data[this.leafNum + i].LChild = tmp1;
data[this.leafNum + i].RChild = tmp2;
}
return data; }
}
2.8.4 哈夫曼编码
在数据通信中,通常需要把要传送的文字转换为由二进制字符 0 和 1 组成的二进制串,这个过程被称之为编码(Encoding)。例如,假设要传送的电文为DCBBADD,电文中只有 A、B、C、D 四种字符,若这四个字符采用表 下图(a)所示的编码方案,则电文的代码为 11100101001111,代码总长度为 14。若采用表 5-1(b) 所示的编码方案,则电文的代码为 0110101011100,代码总长度为 13。

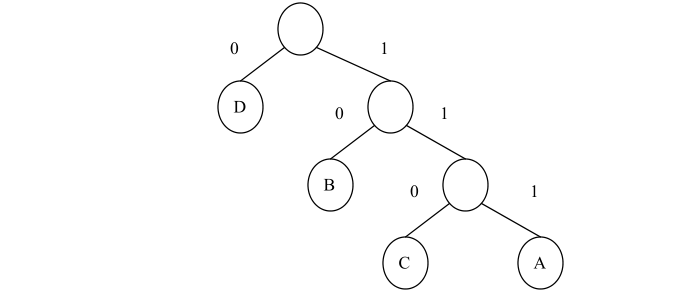
哈夫曼树可用于构造总长度最短的编码方案。具体构造方法如下:设需要编码的字符集为{d 1 ,d 2 ,…,d n },各个字符在电文中出现的次数或频率集合为{w 1 ,w 2 ,…,w n }。以d 1 ,d 2 ,…,d n 作为叶子结点,以w 1 ,w 2 ,…,w n 作为相应叶子结点的权值来构造一棵哈夫曼树。规定哈夫曼树中的左分支代表 0,右分支代表 1,则从根结点到叶子结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码就是哈夫曼编码(Huffman Encoding)。
下图 就是电文 DCBBADD 的哈夫曼树,其编码就是表 (b)。在建立不等长编码中,必须使任何一个字符的编码都不是另一个编码的前缀,这样才能保证译码的唯一性。例如,若字符 A 的编码是 00,字符 B 的编码是 001,那么字符 A 的编码就成了字符 B 的编码的后缀。这样,对于代码串001001,在译码时就无法判定是将前两位码 00 译成字符 A 还是将前三位码 001译成 B。这样的编码被称之为具有二义性的编码,二义性编码是不唯一的。而在哈夫曼树中,每个字符结点都是叶子结点,它们不可能在根结点到其它字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了译码的非二义性。
2.9 C#中的树
C#中的树很多。比如,Windows Form 程序设计和 Web 程序设计中都有一种被称为 TreeView 的控件。TreeView 控件是一个显示树形结构的控件,此树形结构与 Windows 资源管理器中的树形结构非常类似。不同的是,TreeView 可以由任意多个节点对象组成。每个节点对象都可以关联文本和图像。另外,Web 程序设计中的 TreeView 的节点还可以显示为超链接并与某个 URL 相关联。每个节点还可以包括任意多个子节点对象。包含节点及其子节点的层次结构构成了TreeView 控件所呈现的树形结构。
DOM(Document Object Model)是 C#中树形结构的另一个例子。文档对象模型 DOM 不是 C#中独有的,它是 W3C 提供的能够让程序和脚本动态访问和更新文档内容、结构和样式的语言平台。DOM 被分为不同的部分(Core DOM,XML DOM和 HTML DOM)和不同的版本(DOM 1/2/3),Core DOM 定义了任意结构文档的标准对象集合,XML DOM 定义了针对 XML 文档的标准对象集合,而 HTML DOM 定义了针对 HTML 文档的标准对象集合。C#提供了一个标准的接口来访问并操作 HTML和 XML 对象集。后面将以 XML 对象集为例进行说明,对 HTML 对象集的操作类似。DOM 允许将 XML 文档的结构加载到内存中,由此可以获得在 XML 文档中执行更新、插入和删除操作的能力。DOM 是一个树形结构,文件中的每一项都是树中的一个结点。每个结点下面还有子结点。还可以用结点表示数据,并且数据和元素是不同的。在 C#中使用很多类来访问 DOM,主要的类见下表所示。

本章小结
树形结构是一种非常重要的非线性结构,树形结构中的数据元素称为结点,它们之间是一对多的关系,既有层次关系,又有分支关系。树形结构有树和二叉树两种。
树是递归定义的,树由一个根结点和若干棵互不相交的子树构成,每棵子树的结构与树相同,通常树指无序树。树的逻辑表示通常有四种方法,即直观表示法、凹入表示法、广义表表示法和嵌套表示法。树的存储方式有 3 种,即双亲表示法、孩子链表表示法和孩子兄弟表示法。
二叉树的定义也是递归的,二叉树由一个根结点和两棵互不相交的子树构成,每棵子树的结构与二叉树相同,通常二叉树指有序树。重要的二叉树有满二叉树和完全二叉树。二叉树的性质主要有 5 条。二叉树的的存储结构主要有三种:顺序存储结构、二叉链表存储结构和三叉链表存储结构,本书给出了二叉链表存储结构的 C#实现。二叉树的遍历方式通常有四种:先序遍历(DLR)、中序遍历(LDR)、后序遍历(LRD)和层序遍历(Level Order)。
森林是 m(m≥0)棵树的集合。树、森林与二叉树的之间可以进行相互转换。树的遍历方式有先序遍历和后序遍历两种,森林的遍历方式有先序遍历和中序遍历两种。
哈夫曼树是一组具有确定权值的叶子结点的具有最小带权路径长度的二叉树。哈夫曼树可用于解决最优化问题,在数据通信等领域应用很广。
【C#数据结构系列】树和二叉树的更多相关文章
- python数据结构之树和二叉树(先序遍历、中序遍历和后序遍历)
python数据结构之树和二叉树(先序遍历.中序遍历和后序遍历) 树 树是\(n\)(\(n\ge 0\))个结点的有限集.在任意一棵非空树中,有且只有一个根结点. 二叉树是有限个元素的集合,该集合或 ...
- Java数据结构之树和二叉树(2)
从这里始将要继续进行Java数据结构的相关讲解,Are you ready?Let's go~~ Java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来 ...
- Java数据结构之树和二叉树
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ Java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- 【PHP数据结构】树和二叉树
树的概念其实非常地广泛,也非常地常见,大家见到这个词千万不要惊慌,因为真的每天你都能见到树结构在我们生活中的应用.比如说公司的组织结构: 另外像我们家里的族谱,或者说是我们的家庭结构,也是一个典型的树 ...
- 【Java】 大话数据结构(9) 树(二叉树、线索二叉树)
本文根据<大话数据结构>一书,对Java版的二叉树.线索二叉树进行了一定程度的实现. 另: 二叉排序树(二叉搜索树) 平衡二叉树(AVL树) 二叉树的性质 性质1:二叉树第i层上的结点数目 ...
- python数据结构之树(二叉树的遍历)
树是数据结构中非常重要的一种,主要的用途是用来提高查找效率,对于要重复查找的情况效果更佳,如二叉排序树.FP-树. 本篇学习笔记来自:二叉树及其七种遍历方式.python遍历与非遍历方式实现二叉树 介 ...
- javascript实现数据结构: 树和二叉树的应用--最优二叉树(赫夫曼树),回溯法与树的遍历--求集合幂集及八皇后问题
赫夫曼树及其应用 赫夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,有着广泛的应用. 最优二叉树(Huffman树) 1 基本概念 ① 结点路径:从树中一个结点到另一个结点的之间的分支 ...
- javascript实现数据结构: 树和二叉树,二叉树的遍历和基本操作
树型结构是一类非常重要的非线性结构.直观地,树型结构是以分支关系定义的层次结构. 树在计算机领域中也有着广泛的应用,例如在编译程序中,用树来表示源程序的语法结构:在数据库系统中,可用树来组织信息:在分 ...
- SDUST数据结构 - chap6 树与二叉树
判断题: 选择题: 函数题: 6-1 求二叉树高度: 裁判测试程序样例: #include <stdio.h> #include <stdlib.h> typedef char ...
- 数据结构与算法系列研究五——树、二叉树、三叉树、平衡排序二叉树AVL
树.二叉树.三叉树.平衡排序二叉树AVL 一.树的定义 树是计算机算法最重要的非线性结构.树中每个数据元素至多有一个直接前驱,但可以有多个直接后继.树是一种以分支关系定义的层次结构. a.树是n ...
随机推荐
- c# WebApi创建及客户端调用
前段时间学习WebApi的创建与调用,网上的信息千奇百怪(知识有限,看不懂啊),通过查阅资料及借鉴博友实例分析后总结一下,总结一套简单完整的WebApi创建及实例 首先创建一个WebApi服务(流程就 ...
- Nginx 负载均衡和反向代理实践
nginx 以哪个配置文件启动 Nginx 负载均衡和反向代理实践 环境介绍 192.168.1.50 在这台主机上配置Nginx 的反向代理,负载均衡,和web1,web1使用的81号端口 1 ...
- tomcat设置默认欢迎页、server.xml配置文件中的标签理解
一:要求:输入网址,不加文件名便可以访问默认页面 (1)项目中只有静态文件 方法:更改tomcat下的conf目录下的web.xml文件,如下图: <welcom-file-list>元素 ...
- mybatis使用中的记录
一: 常用sql语句: sql顺序:select [distinct] * from 表名 [where group by having order by limit]; 查询某段时间内的数据: ...
- WebForm——JS检测浏览器是否是IE浏览器
function IEVersion() { var userAgent = navigator.userAgent; //取得浏览器的userAgent字符串 && userAgen ...
- vue教程1-08 交互 get、post、jsonp
vue教程1-08 交互 get.post.jsonp 一.如果vue想做交互,引入: vue-resouce 二.get方式 1.get获取一个普通文本数据: <!DOCTYPE html&g ...
- odoo开发笔记 -- 后台代码什么时候需要注意编码格式
(1)首先py文件中的注释 中文汉字 一定要加u' ' (2) 前端视图不是多对一的时候,只是普通的字符字段 后台取值 需要加 str装换 head_node_dic['ManualNo'] = st ...
- Python:使用异常处理来判断运行的平台
try: import termios, TERMIOS 1 except ImportError: try: import msvcrt 2 except ImportError: try: fro ...
- Zookeeper--0300--java操作Zookeeper,临时节点实现分布式锁原理
删除Zookeeper的java客户端有 : 1,Zookeeper官方提供的原生API, 2,zkClient,在原生api上进行扩展的开源java客户端 3, 一.Zookeeper原生API ...
- Quarz.net 设置任务并行和任务串行
如何设置Quarz.net某个任务完成后再继续执行该任务? Quarz.net 的任务有并行和串行两种: 并行:一个定时任务,当执行时间到了的时候,立刻执行此任务,不管当前这个任务是否在执行中: 串 ...