T-SQL 无参数的存储过程的创建和执行
- use StudentManager
- go
- if exists(select * from sysobjects where name='usp_ScoreQuery')
- drop procedure usp_ScoreQuery
- go
- create procedure usp_ScoreQuery --创建存储过程
- as
- --查询考试信息
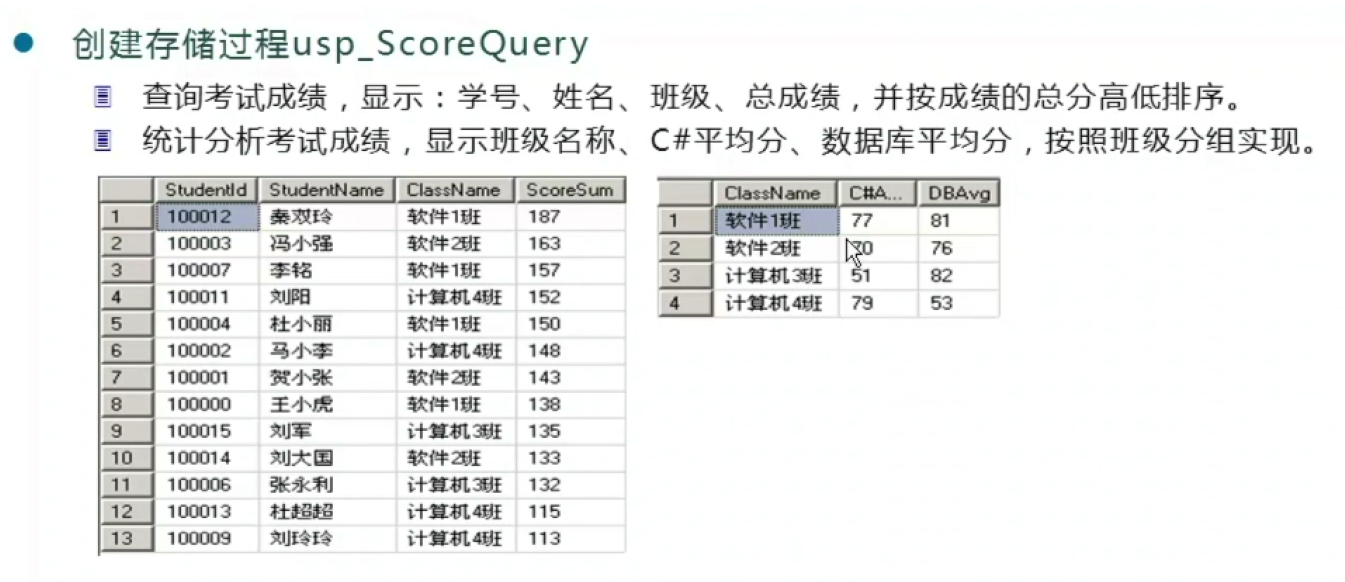
- select Students.StudentId,StudentName,ClassName,
- ScoreSum=(CSharp+SQLServerDB) from Students
- inner join StudentClass on StudentClass.ClassId=Students.ClassId
- inner join ScoreList on Students.StudentId=ScoreList.StudentId
- order by ScoreSum DESC
- --统计分析考试信息
- select StudentClass.ClassId,C#Avg=avg(CSharp),DBAvg=avg(SQLServerDB) into #scoreTemp
- from StudentClass
- inner join Students on StudentClass.ClassId=Students.ClassId
- inner join ScoreList on ScoreList.StudentId=Students.StudentId
- group by StudentClass.ClassId order by ClassId
- select ClassName,C#Avg,DBAvg from #scoreTemp
- inner join StudentClass on StudentClass.ClassId=#scoreTemp.ClassId
- go
- exec usp_ScoreQuery --调用存储过程
- 这里的 into #scoreTemp 是把查询的数据放入到临时表中
T-SQL 无参数的存储过程的创建和执行的更多相关文章
- sqlserver 带输出参数的存储过程的创建与执行
创建 use StudentManager go if exists(select * from sysobjects where name='usp_ScoreQuery4') drop proce ...
- T-SQL 有参数存储过程的创建与执行
use StudentManager go if exists(select * from sysobjects where name='usp_ScoreQuery2') drop procedur ...
- 2019-03-19 SQL Server简单存储过程的创建 删除 执行
--创建名为 Get 的有输入参数的存储过程 create proc Get --设置默认值 @TrustId int ='001' as begin select * from [DealStruc ...
- ORACLE存储过程的创建和执行的简单示例和一些注意点
此示例的主要目的主要是为了了解在PL/SQL环境下怎么创建和执行存储过程. 存储过程所涉及的DataTable: 第一步:创建游标变量 游标是ORACLE系统在内存中开辟的一个工作区,主要用来存储SE ...
- SQL关于触发器及存储过程的创建
使用T-SQL语句来创建触发器 基本语句如下﹕ create trigger trigger_name on {table_name | view_name} {for | After | Ins ...
- 在PL/SQL中调用Oracle存储过程
存储过程 1 什么是存储过程? 用于在数据库中完成特定的操作或者任务.是一个PLSQL程序块,可以永久的保存在数据库中以供其他程序调用. 2 存储过程的参数模式 存储过程的参数特性: IN类型的参数 ...
- ASP.NET LinqDataSource数据绑定后,遇到[MissingMethodException: 没有为该对象定义无参数的构造函数。]问题。
问题出现的情形:LinqDataSource数据绑定到DetailsView或GridView均出错,错误如下: “/”应用程序中的服务器错误. 没有为该对象定义无参数的构造函数. 说明: 执行当前 ...
- Oracle存储过程的调用和执行
1.什么是存储过程: 用于在数据库中完成特定的操作或者任务.是一个PLSQL程序块,可以永久的保存在数据库中以供其他程序调用. 2.无参存储过程的使用: Normal 0 7.8 磅 0 2 fals ...
- 使用SQL Server2014作业定时执行无参的存储过程
一.存储过程 1.新建存储过程 按照下图找到存储过程,右键“新建”选择”存储过程” 此时在右侧会打开一个窗口,如下图. 2.填写创建存储过程语句 填写存储过程名称,因为是无参的存储过程,所以把参数部分 ...
随机推荐
- rsync入门使用
rsync是用来同步文件的,但是是基于增量同步的,也就是说每次同步时不需要把全部文件数据都传输过去,只需要将不相同的部分(也就是说增量差异内容)传输过去. 其基本命令格式为rsync [option] ...
- replicatedhq-ship 基于Kustomize 项目的快速kubernetes 应用部署工具
replicatedhq-ship 是对Kustomize 项目的扩展,我们可以用它来快速的进行三方应用的管理部署, 可以和helm,kubernetes 清单文件,knative 集成,我们可以方便 ...
- about unit test
Use unify unit test framework CPPUnit 1.12.1/Visual stdio Unit is a class or a function Test per maj ...
- C# to IL 5 Operator Overloading(操作符重载)
Every operator overload that we use in C#, gets converted to a function call in IL. Theoverloaded &g ...
- java BitSet2
15. int nextClearBit(int startIndex)返回第一个设置为 false 的位的索引,这发生在指定的起始索引或之后的索引上. 16. int nextSetBit(int ...
- git忽略已提交的文件或目录
项目中的某个文件或目录已经被commit,并push到远程服务器server了. 这时发现要忽略该文件或目录,在.gitignore文件里面添加规则已经不起作用了.因为.gitignore只对从来没有 ...
- java 迭代
迭代器的作用是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节. java中的很多容器都实现了Iterable接口,容器中的元素都是可以遍历的. 如下例,list容器中存 ...
- Hadoop 目录分析及存储机制
NameNode元数据目录分析 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘: $HADOOP_HOME/bin/hdfs namenode -format ...
- Spark应用HanLP对中文语料进行文本挖掘--聚类详解教程
软件:IDEA2014.Maven.HanLP.JDK: 用到的知识:HanLP.Spark TF-IDF.Spark kmeans.Spark mapPartition; 用到的数据集:http:/ ...
- HanLP中的人名识别分析详解
在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: u u名字识别的问题 #387 u u机构名识别错误 u u关于层叠H ...