spark使用hadoop native库
默认情况下,hadoop官方发布的二进制包是不包含native库的,native库是用C++实现的,用于进行一些CPU密集型计算,如压缩。比如apache kylin在进行预计算时为了减少预计算的数据占用的磁盘空间,可以配置使用压缩格式。
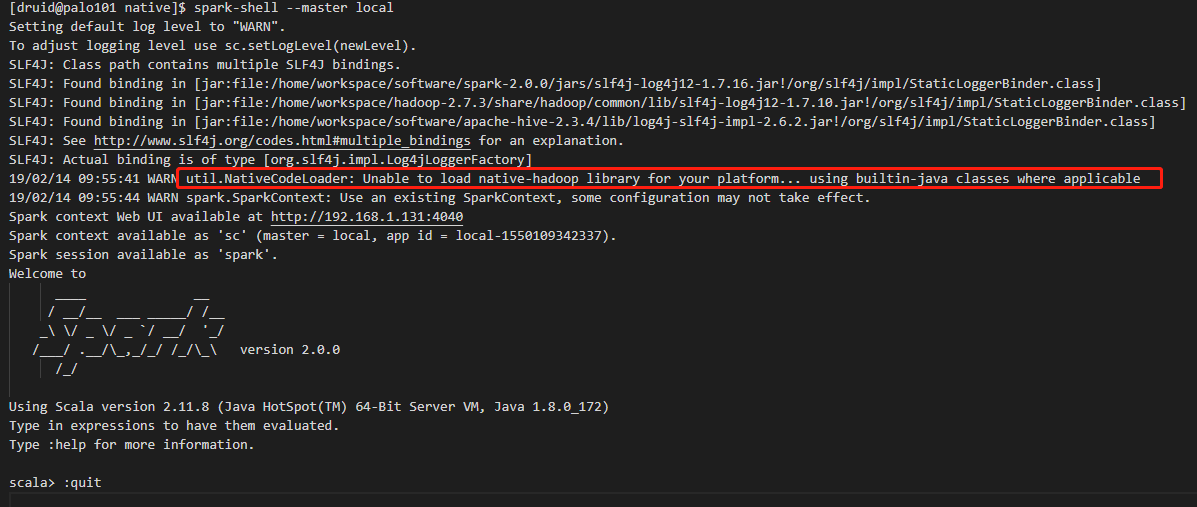
默认情况下,启动spark-shell,会有无法加载native库的警告:
19/02/14 09:55:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1. 编译hadoop源码
具体请参见本人的博文
或者在hadoop源码根目录下,执行ant compile-native 编译本地库(未亲测)
编译好中之后在{hadoop_source_root}/hadoop-dist/target/hadoop-{hadoop_version}/lib/native会存在编译好的native库文件,具体路径,请自己替换为匹配的版本。在本人的机器上显示如下,本人机器上用的是hadoop-2.7.3,所以路径为
{hadoop_source_root}/hadoop-dist/target/hadoop-2.7.3/lib/native
[druid@palo101 native]$ ls -lh
total 4.6M
-rw-rw-r-- druid druid 1.2M Feb : libhadoop.a
-rw-rw-r-- druid druid 1.6M Feb : libhadooppipes.a
lrwxrwxrwx druid druid Feb : libhadoop.so -> libhadoop.so.1.0.
-rwxrwxr-x druid druid 710K Feb : libhadoop.so.1.0.
-rw-rw-r-- druid druid 465K Feb : libhadooputils.a
-rw-rw-r-- druid druid 425K Feb : libhdfs.a
lrwxrwxrwx druid druid Feb : libhdfs.so -> libhdfs.so.0.0.
-rwxrwxr-x druid druid 267K Feb : libhdfs.so.0.0.
2. 部署编译好的hadoop native库
.删除hadoop部署环境下的native库(如果存在的话)
rm -rf $HADOOP_HOME/lib/native
复制编译好的native库到hadoop部署目录
scp -r {hadoop_source_root}/hadoop-dist/target/hadoop-2.7./lib/native {hadoop集群节点IP}:$HADOOP_HOME/lib
注意:复制到集群节点上.
3. 复制libjvm.so文件到$HADOOP_HOME/lib/native目录下
用ldd查看一下生成的native二进制文件的信息,发现libjvm.so找不到
[druid@palo101 native]$ sudo ldd $HADOOP_HOME/lib/native/libhadoop.so
linux-vdso.so. => (0x00007ffe12bad000)
libdl.so. => /lib64/libdl.so. (0x00007fee0127c000)
libjvm.so => not found
libc.so. => /lib64/libc.so. (0x00007fee00eba000)
/lib64/ld-linux-x86-.so. (0x00007fee016ba000)

所以我们在每台机器上执行下面脚本,把libjvm.so文件复制到hadoop native lib目录下
cp $JAVA_HOME/jre/lib/amd64/server/libjvm.so $HADOOP_HOME/lib/native
复制过去后,再执行一下下面的命令检查一下二进制native库
sudo ldd $HADOOP_HOME/lib/native/libhadoop.so
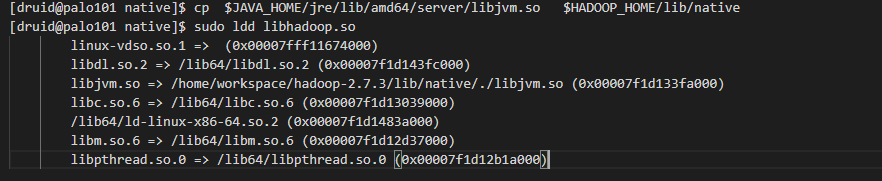
一切正常,说明部署已经没有问题了。下面就来做一下配置
4. 配置使用native库
4.1 hadoop启用native库
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加配置项
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
4.2 添加环境变量
vim /etc/profile
在末尾添加
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
也可以在shell窗口中执行这个命令,但是是临时生效,shell窗口关闭就失效了。
5. 在shell中验证是否成功

发现警告已经消失,成功使用了hadoop本地库.
spark使用hadoop native库的更多相关文章
- Hadoop支持的压缩格式对比和应用场景以及Hadoop native库
对于文件的存储.传输.磁盘IO读取等操作在使用Hadoop生态圈的存储系统时是非常常见的,而文件的大小等直接影响了这些操作的速度以及对磁盘空间的消耗. 此时,一种常用的方式就是对文件进行压缩.但文件被 ...
- 更改hadoop native库文件后datanode故障
hadoop是用cloudra的官方yum源安装的,服务器是CentOS6.3 64位操作系统,自己写的mapreduce执行的时候hadoop会提示以下错误: WARN util.NativeCod ...
- 4、解决native库不兼容
解决native库不兼容 现象: 报警告 [root@hadoop1 hadoop-]# bin/hdfs dfs -ls /input // :: WARN util.NativeCodeLoade ...
- 对于spark以及hadoop的几个疑问(转)
Hadoop是啥?spark是啥? spark能完全取代Hadoop吗? Hadoop和Spark属于哪种计算计算模型(实时计算.离线计算)? 学习Hadoop和spark,哪门语言好? 哪里能找到比 ...
- Spark与Hadoop计算模型的比较分析
http://tech.it168.com/a2012/0401/1333/000001333287.shtml 最近很多人都在讨论Spark这个貌似通用的分布式计算模型,国内很多机器学习相关工作者都 ...
- Spark入门(1-1)什么是spark,spark和hadoop
一.Spark是什么? Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,可用来构建大型的.低延迟的数据分析应用程序. Spark是UC Berkeley AMP lab (加 ...
- [hadoop] hadoop native libraries 编译
安装hadoop启动之后总有警告:Unable to load native-hadoop library for your platform... using builtin-Javaclasses ...
- Spark和hadoop的关系
1. Spark VSHadoop有哪些异同点? Hadoop:分布式批处理计算,强调批处理,常用于数据挖掘和数据分析. Spark:是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速, ...
- Spark和Hadoop作业之间的区别
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的. 熟悉Hadoop的人应该都知道 ...
随机推荐
- Unity API 解析 (陈泉宏著)
1 Application类 2 Camera类 3 GameObject类 4 HideFlags类 5 Mathf类 6 Matrix4x4类 7 Object类 8 Quaternion类 9 ...
- C#中如何实现json转化时只处理部分属性
把对象转化为json字符串,很常用,但如果因为现在大部分项目都是用了ORM映射,导致一个对象的属性特别多,如果前台只需要部分属性如何实现? 当然最简单是所有属性都json化,前台只处理需要的属性,多余 ...
- webpack 4:默认配置
webpack 4:默认配置 entry 默认: ./src/index.js(注意: 路径必须带上./): entry: './src/index.js', output 默认最后路径: ./dis ...
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
使用Docker Compose部署基于Sentinel的高可用Redis集群 https://yq.aliyun.com/articles/57953 Docker系列之(五):使用Docker C ...
- Usbhub驱动编译
在3g 4g的usb驱动基础上,加入以下部分,就可以驱动hub了 kmod-usb-hid 3.3.8-1 kmod-usbip 3.3.8-1 kmod-usbip-client 3.3.8-1 k ...
- 【转】mysql给root开启远程访问权限,修改root密码
好记性不如烂笔头,偶然用一直忘.... mysql给root开启远程访问权限,修改root密码 1.MySql-Server 出于安全方面考虑只允许本机(localhost, 127.0.0.1) ...
- innobackupex
time innobackupex --defaults-file=/data/mysql/3306/my.cnf --user=root --password=123456 \--rsync --p ...
- C# .NET 4.5 将多个文件添加到压缩包中
string zipFilePath = @"d:\test.zip"; string file1 = @"D:\门头照处理\门店照片2018-3-19 wuxl\门店照 ...
- PHP 数据运算类型都有哪些?
四种标量类型:布尔型 boolean $bo=TRUE; $bo=FALSE;整型 integer $bo=1; $bo=-12;浮点型 float/double $bo=1.001; $bo=3 ...
- 对poi-Excel导入的浅层理解
本文即将对POI方式导入excel文件最核心的步骤予以说明,为的是简单,也是为了阐明文件导入的原理. 文件导入有一个很明显的线索: 1.首先是我们知道硬盘中的文件,即:文件对象File file 2. ...