SVM(支持向量机)简介与基础理解
SVM(支持向量机)主要用于分类问题,主要的应用场景有字符识别、面部识别、行人检测、文本分类等领域。原文地址:https://zhuanlan.zhihu.com/p/21932911?refer=baina
通常SVM用于二元分类问题,对于多元分类通常将其分解为多个二元分类问题,再进行分类。下面我们首先讨论一下二元分类问题。
- 线性可分数据集与线性不可分数据集
对于二元分类问题,如果存在一个分隔超平面能够将不同类别的数据完美的分隔开(即两类数据正好完全落在超平面的两侧),则称其为线性可分。反之,如果不存在这样的超平面,则称其为线性不可分。
所谓超平面,是指能够将n维空间划分为两部分的分隔面,其形如。简单来说,对于二维空间(指数据集有两个特征),对应的超平面就是一条直线;对于三维空间(指数据集拥有三个特征),对应的超平面就是一个平面。可以依次类推到n维空间。
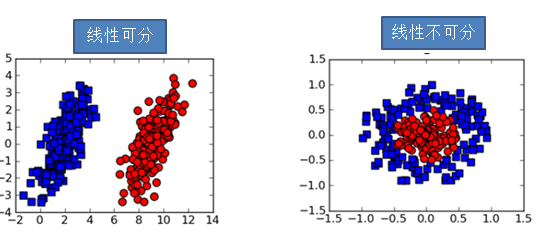
在下面的图片中,左边的图表示二维空间的一个线性可分数据集,右图表示的是二维空间的一个线性不可分数据集。可以直观的看到,对于左图,我们很容易找到这样一条直线将红色点和蓝色点完全分隔开。但是对于右图,我们无法找到这样的直线。
线性不可分出现的原因:
(1)数据集本身就是线性不可分隔的。上图中右图就是数据集本身线性不可分的情况。这一点没有什么疑问,主要是第二点。
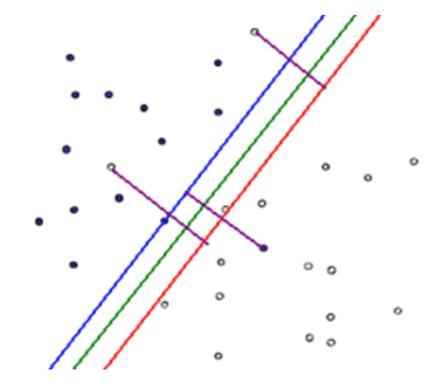
(2)由于数据集中存在噪声,或者人工对数据赋予分类标签出错等情况的原因导致数据集线性不可分。下图展示的就是由于噪声或者分错出错导致线性不可分的情况。
现在,只关注图中的实心点、空心点,以及绿色线段。可以看到实心点和空心点大致分布在绿色线段的两侧,但是在实心点的一侧混杂了两个空心点,在空心点的一侧混杂了一个实心点,即此时绿色直线并没有完全将数据分为两类,即该数据集是线性不可分的。在后面我们会提到通过修正线性可分模型以使得模型能够“包容”数据集中的噪点,以使得SVM能够处理这种类型的线性不可分情况。
SVM的目标就是找到这样的一个超平面(对于上图来说,就是找到一条直线),使得不同类别的数据能够落在超平面的两侧。
2. 分类效果好坏
对于线性可分数据集,有时我们可以找到无数多条直线进行分隔,那么如何判断哪一个超平面是最佳的呢?
我们先来看一个简单的例子。图中‘x’和‘o’分别代表数据的两种不同类型。可以看到存在图中这样一条直线将数据划分成两类。对于图中的A、B、C三点,虽然它们都被划分在了‘x’类,但是我们A、B、C真正属于‘x’类的把握却是不一样的,直觉上我们认为有足够大的把握A点确实属于'x'类,但是对于C点我们却没有足够的把握,因为图中分隔直线的稍稍偏离,C点有可能就被划分到了直线的另一侧。

所以,SVM的目标是使得训练集中的所有数据点都距离分隔平面足够远,更确切地说是,使距离分隔平面最近的点的距离最大。
3. 距离衡量标准
上面提到了SVM的中心思想,即,使距离分隔平面最近的点的距离最大。那么这个距离如何衡量呢?
通常采用几何间隔作为距离度量的方式。简单来说,就是点到超平面的几何距离。
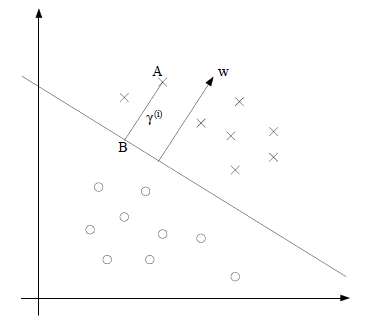 例如,在上图的二维空间中,点A到分隔超平面(直线)的距离即为线段AB的长度。
例如,在上图的二维空间中,点A到分隔超平面(直线)的距离即为线段AB的长度。
几何间隔的计算公式如下:

其中,y表示数据点的类别标签,w和b分别是超平面的参数。
注:
(1)在SVM的二元分类中,通常将数据分为“1”类(也称为正类或正例)和“-1”类(也称为负类负例)。通常对于数据点,如果
,则其被分为正类,反之,如果
则被分为负类。那么通过在几何间隔的计算中加入乘法因子y,即可保证只要数据点被分在了正确的类别,那么其几何间隔一定是一个正值。
(2)其中通常也称为函数间隔。当w的模||w||等于1时,函数间隔和几何间隔相等。函数间隔存在的一个问题是:等比放大w和b,函数间隔也会等比增大,而分隔超平面却不会发生变化。几何间隔可以看做是函数间隔的“正规化”。几何间隔不会随着w和b的等比缩放而变化。
4. 支持向量的概念和最优间隔分类器
所谓SVM,即支持向量机,那么到底什么是支持向量呢?
如下图所示,实心点和空心点分别代表数据的两种类别,他们被黄色区域中间的直线分隔成两部分。被蓝色和红色圆圈圈出的点即为支持向量。所谓支持向量,就是指距离分隔超平面最近的点。

那么:要最大化最近的点到分隔超平面的距离,就是最大化支持向量到超平面的距离。
则我们要优化的目标就是:(具体推导这里不具体详述,可以参考附录中的参考资料)
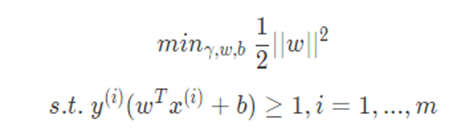
这就是最大间隔分类器的模型,也是SVM的雏形,其可以利用二次优化软件(QP)直接求解。但是计算效率不高(甚至可以说非常低)。
5.通过拉格朗日对偶法优化最优间隔分类器模型
为了提高计算效率以及方便使用核函数,采用拉格朗日对偶,将原始优化模型变成了如下对偶形式: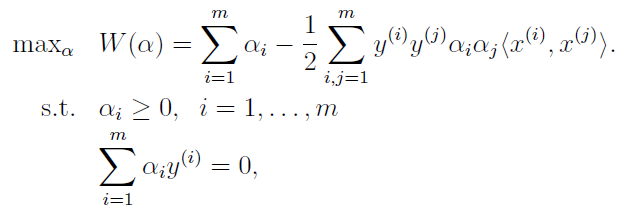
公式的推导非常复杂,这里也不再赘述,详细参考后面给出的资料。
这里只需要知道,alpha仅在支持向量处为非零值。也就是说实际计算时,公式右边有大量零值,非常节省计算量。
6. 模型修正和线性不可分的处理
在第二部分,我们提到:在分类问题中,并不是训练集的分类函数越“完美”越好,因为数据集中本来就存在噪声,且可能存在人工添加分类标签出错的情况。过于“完美”反而会导致过拟合,使得模型失去一般性(可推广性)。

为了修正这些分类错误的情况,需要修正模型,加上惩罚系数C。其中表示错误分类的点到正确边界的距离。(即图中的紫色线段长度)
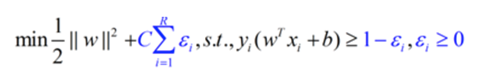 修正后的模型,可以“容忍”模型错误分类的情况,并且通过惩罚系数的约束,使得模型错误分类的情况尽可能合理。
修正后的模型,可以“容忍”模型错误分类的情况,并且通过惩罚系数的约束,使得模型错误分类的情况尽可能合理。
7.核函数
在线性不可分的情况下的另一种处理方式是使用核函数,其基本思想是:将原本的低维特征空间映射到一个更高维的特征空间,从而使得数据集线性可分。
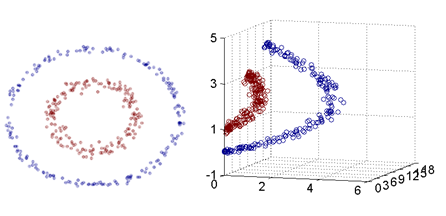
在上面的图中,左侧的图是一个二维特征空间中的线性不可分数据集,其具有两个特征(x1,x2)。
通过特征映射:
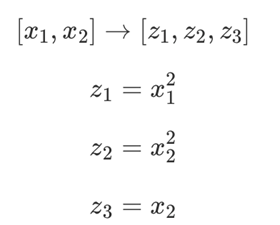
我们可以得到右侧的图,其是一个三维特征空间中的线性可分数据集,具有三个特征(z1,z2,z3)。
即:我们通过特征映射,将一个二维的线性不可分数据集成功映射到了三维空间的线性可分数据集。
关于核函数有一个形象的解释:世界上本来没有两个完全一样的物体,对于所有的两个物体,我们可以通过增加维度来让他们最终有所区别,比如说两本书,从(颜色,内容)两个维度来说,可能是一样的,我们可以加上作者这个维度,是在不行我们还可以加入页码,可以加入 拥有者,可以加入 购买地点,可以加入 笔记内容等等。当维度增加到无限维的时候,一定可以让任意的两个物体可分了。
这与核函数将低维特征映射到高维特征的思想基本类似。
常用的核函数有:
(1)多项式核函数

(2)高斯核函数
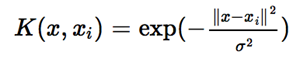
那么如何应用核函数呢?
回顾上面我们构建的模型: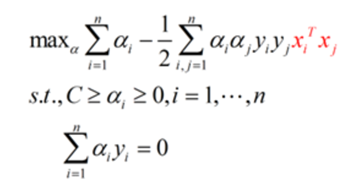
注意到公式红色部分,表示两个和
做内积,要应用核函数,我们只需要将这个部分替换为对应的核函数即可。
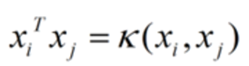
8. SMO算法
SMO算法就是为了高效计算上述优化模型而提出的。其是由坐标上升算法衍生而来。
所谓坐标上升算法,就是指:对于含有多个变量的优化问题:每次只调整一个变量,而保证其他变量不变,来对模型进行优化,直到收敛。
举一个最简单的例子,对于如下优化问题:
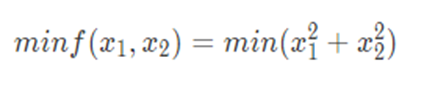
从任意点开始应用坐标上升算法,结果都会收敛到(0,0)。
不妨假设我们选择初始点(5,8),首先我们只调整x1的值,而保证x2的值不变,得到解(0,8);然后我们只调整x2的值,而保证x1的值不变,得到解(0,0);进一步,我们再次只调整x1的值,而保证x2的值不变,发现结果仍然是(0,0),说明收敛,算法结束,最终结果为(0,0)。
SMO的思想类似,由于约束条件 的存在,如果按照坐标上升算法,每次只修改一个
的值,是不可行的(因为
的值完全取决于剩下的m-1个
值)。所以每次至少改变一对a的值。
因而,类似坐标上升,SMO算法每次选择一对可以进行优化的a值进行优化,直到收敛。
9. SVM在多分类问题中的应用
SVM模型可以非常方便的进行二元分类问题的处理,不过也有许多方法将其扩展到多元分类问题中去。
常用的方法有一对其余法、一对一法等。详细可以参考一下这里。
10. SVM应用实例
(1)SVM在手写识别中的应用
问题定义:如何利用SVM算法识别出数字0-9。在这里我们只讨论二元分类的情况,即判断一个手写数字是两个数字中的哪一个(例如,判断其是1还是9,在后面,我们会简要给出将其扩展到多元分类的方法)
手写体的获取和处理:采集数字1和9的手写体,并将其转换为字符点阵。如下图所示,是一个手写数字1的字符点阵。其是一个32*32的点阵。

特征和类别标签:可以看到,每个数字的形状都是由1024个点描述的,因而训练样例具有1024个特征,每个特征对应字符点阵中的一点。类别标签只需要将同一类数字赋予相同类别即可,例如,将数字1归为“1”类,将数字9归为“-1”类。
模型训练:利用上述SMO算法,得到分类模型。
模型优化:调整核函数参数,以使得模型达到最小的泛化错误。通过交叉验证,以取得最好的参数: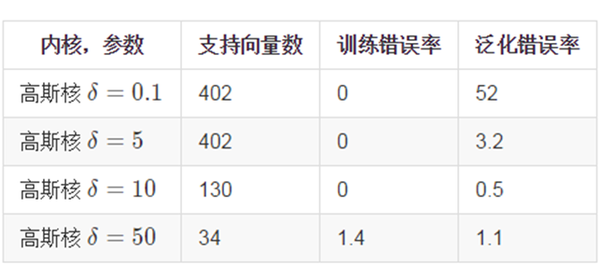
可以看到,当核参数大小在10附近时,具有较优的表现。
(2)鸢尾花的分类
数据来源是UCI数据集iris。下面是数据的特征和不同的类别。
特征:
(1). sepal length in cm 萼片长度
(2). sepal width in cm 萼片宽度
(3). petal length in cm 花瓣长度
(4). petal width in cm 花瓣宽度
类别:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
数据预处理
Shuffle操作:
UCI上的该数据集是按类别顺序排列的,为了方便建模和交叉验证,需要随机打乱顺序,使其无序化。这样做的目的是:避免训练数据集中全部出现的是同一类数据。
左图和右图分别是打乱前后的数据集。
 SVM建模
SVM建模
实现SMO算法,使用高斯核函数,分别实现Iris Setosa - NON_Iris Setosa分类器,Iris Versicolour – NON_Iris Versicolour 分类器。并保存模型参数到文件中。
参数alpha(部分):可以看到,105个训练样例中,只有4个alpha为非零值。即只有4个支持向量。(支持向量数远远小于样例数。)
 参数b:
参数b:

多元分类处理
采用了类似决策树的方式。(这种方式存在的不足是:如果上层分类出现误差,那么误差会累积到下层分类,不过在这个分类问题中,采用这种方式效果还可以。)

模型效果
训练错误率(模型对训练数据集中的数据分类的错误率):7.6%
泛化错误率(模型对测试数据集中的数据分类的错误率) :6.7%
 模型优化
模型优化
在这里,我主要是修改核参数:
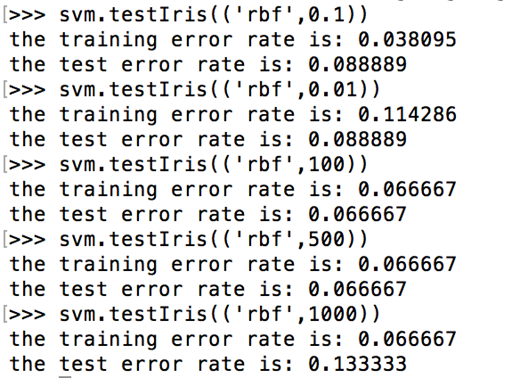
可以看到,调整不同的参数值,可以得到不同的训练错误率和泛化错误率。
其他可能可以进行优化的地方
(a)增大数据集
(b)改变惩罚参数C
(c)使用其他的多分类策略
9.附录
(1)支持向量机SVM基础:这个讲解比较简洁清晰,基本不涉及公式证明,详见这里。
(2)吴恩达教授机器学习课程,可以在coursera或者网易公开课上观看。
(3)支持向量机通俗导论(理解SVM的三层境界):比较全面,但是个人感觉一开始比较难以看懂。详见这里。
原文地址:https://zhuanlan.zhihu.com/p/21932911?refer=baina

SVM(支持向量机)简介与基础理解的更多相关文章
- 支持向量机通俗导论(理解SVM的三层境地)
支持向量机通俗导论(理解SVM的三层境地) 作者:July :致谢:pluskid.白石.JerryLead.出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vector ...
- 支持向量机通俗导论(理解SVM的三层境界)(ZT)
支持向量机通俗导论(理解SVM的三层境界) 原文:http://blog.csdn.net/v_JULY_v/article/details/7624837 作者:July .致谢:pluskid.白 ...
- 支持向量机通俗导论(理解SVM的三层境界)【非原创】
支持向量机通俗导论(理解SVM的三层境界) 作者:July :致谢:pluskid.白石.JerryLead. 出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vecto ...
- 支持向量机通俗导论(理解SVM的三层境界) by v_JULY_v
支持向量机通俗导论(理解SVM的三层境界) 前言 动笔写这个支持向量机(support vector machine)是费了不少劲和困难的,原因很简单,一者这个东西本身就并不好懂,要深入学习和研究下去 ...
- 支持向量机通俗导论(理解SVM的三层境界)[转]
作者:July .致谢:pluskid.白石.JerryLead.说明:本文最初写于2012年6月,而后不断反反复复修改&优化,修改次数达上百次,最后修改于2016年11月.声明:本文于201 ...
- 机器学习:SVM(基础理解)
一.基础理解 1)简介 SVM(Support Vector Machine):支撑向量机,既可以解决分类问题,又可以解决回归问题: SVM 算法可分为:Hard Margin SVM.Soft Ma ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- 【CSS简介、基础选择器、字体属性、文本属性、引入方式】前端小抄(2) - Pink老师自学笔记
[CSS简介.基础选择器.字体属性.文本属性.引入方式]前端小抄(2) 本学习笔记是个人对 Pink 老师课程的总结归纳,转载请注明出处! 一.CSS简介 CSS 的主要使用场景就是布局网页,美化页面 ...
- APP接口自动化测试JAVA+TestNG(二)之TestNG简介与基础实例
前言 继上篇环境篇后,本篇主要对TestNG进行介绍,给出最最基础的两个实例,通过本文后,学会并掌握TestNG测试用例的编写与运行,以及生成美化后的报告.下一篇为HTTP接口实战(国家气象局接口自动 ...
随机推荐
- 添加网络ADB的方法(含以太网和无线)
将下面代码添加至packages/apps/Settings/src/com/android/settings/DevelopmentSettings.java 结合之前的添加wifi adb的博客 ...
- i2c设备驱动注册
Linux I2C设备驱动编写(二) 原创 2014年03月16日 23:26:50 在(一)中简述了Linux I2C子系统的三个主要成员i2c_adapter.i2c_driver.i2c ...
- TensorFlow 实现 RNN 入门教程
转子:https://www.leiphone.com/news/201705/zW49Eo8YfYu9K03J.html 最近在看RNN模型,为简单起见,本篇就以简单的二进制序列作为训练数据,而不实 ...
- Mathtype批量修改公式
(1)将模板中的公式直接打开 (2)将需要修改好的公式复制黏贴到模板中 (3)再复制黏贴出,即可 PS: (1)统一设置公式格式 (2)统一设置公式大小
- 20155205 2016-2017-2 《Java程序设计》第9周学习总结
20155205 2016-2017-2 <Java程序设计>第9周学习总结 教材学习内容总结 第十六章 JDBC简介 厂商在实现JDBC驱动程序时,依方式可将驱动程序分为四种类型: JD ...
- python读取并写入mat文件
用matlab生成一个示例mat文件: clear;clc matrix1 = magic(5); matrix2 = magic(6); save matData.mat 用python3读取并写入 ...
- (转)mysql command line client打不开(闪一下消失)的解决办法
转自:http://www.2cto.com/database/201209/153858.html 网上搜索到的解决办法: 1.找到mysql安装目录下的bin目录路径. 2.打开cmd,进入到bi ...
- mac版win10装eclipse图标太小了,解决办法(2k显示屏+win10)
安装了Eclipse并且打开之后,发现图标显示极其细小,肉眼几乎无法看清了.这是由于Eclipse对高分屏没有作适配导致的. Windows 10本身对于高分屏的支持已是相当不错,苏菲4的屏幕分辨率为 ...
- QOpenglWidget 与QGLWidget的选择
1. QGLWidget 是Qt OpenGL模块,但是从其官方说明,推荐在Qt5.4 之后,使用QOpenglWidget版本,具体说明如下: Note: This class is part of ...
- 声笔飞码GB2312单字效率分析
-----------------------声笔飞码强字方式单字效率分析-------------------------- 2 keys: 567 items, 381900209 ...