[2017BUAA软工]结对项目-数独程序扩展
零.github地址
GitHub地址:https://github.com/Liu-SD/SudoCmd (这个地址是命令行模式数独的仓库,包含了用作测试的BIN。DLL核心计算模块地址是:https://github.com/Liu-SD/SudoCore ,UI界面项目地址是:https://github.com/Liu-SD/SudoUi 。)
一.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 100 | |
| · Design Spec | · 生成设计文档 | 100 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | |
| · Design | · 具体设计 | 30 | |
| · Coding | · 具体编码 | 600 | |
| · Code Review | · 代码复审 | 600 | |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 100 | |
| · Size Measurement | · 计算工作量 | 30 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 100 | |
| 合计 | 1980 |
二.说明你们在结对编程中是如何利用“Information Hiding, Interface Design, Loose Coupling”这些方法对接口进行设计的
一开始把命令行参数的处理过程和根据参数执行具体的功能耦合在一起,但是这一次需要实现的功能增加了,而且需要处理的参数的异常和错误情况也增加了很多,所以经过思考和讨论后,决定单独写一个模块,输入是命令行参数,把命令行参数中所包含的命令信息保存在自己预先设计好的结构体中,并处理可能出现的异常和错误情况。
typedef struct request
{
//最后生成的数量
int number;
//数独问题的文件路径
std::string *filepath;
//存是哪种模式
int mode;
//对于挖空的情况,最大空的数量
int upper;
//最小
int lower;
//是不是要求唯一解
bool unique;
//是哪种类型(这里默认有四种类型:1.生成终局-c 2.解决数独 -s 3.生成不同模式 -m -n 4.生成不同挖空数 -r -n (-u))
requests req;
} request;
(保存信息的结构体的定义)
之后根据结构体中的保存好的信息执行对应的接口。
request *req = new request();
memset(req,,sizeof(request));
try {
paraHandle(argc, args, req);
}
catch (format_err &e)
{
e.what();
}
catch(combination_conflict &e)
{
e.what();
}
catch (too_few_para &e)
{
e.what();
}
switch (req->req)
{
case End:
//调用产生数独终局的函数
break;
case Solve:
//调用解决数独的函数
break;
case Mode:
//调用根据游戏模式产生数独游戏的函数
break;
case Empty:
//调用根据挖空数产生数独游戏的函数
break;
default:
break;
}
return ;
这样,就把命令行参数的处理过程和具体功能的实现过程耦合性解开了。通过一个中间结构体request来实现从不同的命令行参数到不同的功能实现的信息传递过程。我觉得设计很像在《Head First 设计模式》中所看到的命令模式,但感觉其实比书上的命令模式的实现还少了很多,例如这里在实现时并没有把不同的功能放在一个基类下面。
这里我又想到了OO课之前所做的出租车调度以及电梯调度,当时也是通过设计require类,来实现控制台输入--->信息保存在一个require对象里--->根据这个require对象来实现电梯调度或者出租车调度。这里通过设计这个request结构体,实现控制台输入--->信息保存在request结构体里--->根据这个结构体来实现具体的功能。
所以这个设计把命令的发出者(控制台)和命令的执行者(具体功能实现)解耦了。
三.关键函数的流程图和算法解释
0.这里我没有设计很多类,很多函数方法并没有封装到类中,所以这里简要说明一下重要的函数之间的关系吧:
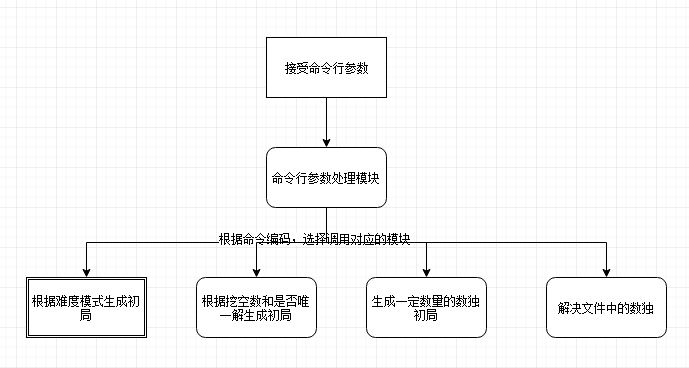
1.命令行处理参数的逻辑解释:
上面已经解释了信息的保存,命令行参数的处理模块除了需要保存好相应命令的信息外,还需要处理可能发生的各种异常错误。
我觉得这里可能产错误可以分为①功能性参数(-c -m -n等)的组合错误②内容型参数(-n后面的数字,-m后面的123等)的内容错误
对于①,采用的检查错误的办法是,每个功能性参数对应一个flag,
1.可以检测是否重复输入了这个功能性参数,具体办法就是在检测到是这个参数比如-c后,在设置c_flag之前,检查一下c_flag是不是已经被设置了
2.可以检测是否组合错误,具体办法是:目前仅有四种功能性组合①-c代表的产生终局②-s代表的解决③-m和-n代表的产生不同模式的游戏④-r-n(和-u)代表的
不同挖空数游戏,那么我在遍历完所有命令行参数后,检测这四种组合是否出现,如果都没出现,那么说明这个组合有问题,具体实现下面详细说。
对于②,就是定义各种具体的异常,比如字符串中含数字,数字范围不符合要求等等,一旦检测到了,那么抛出异常就好
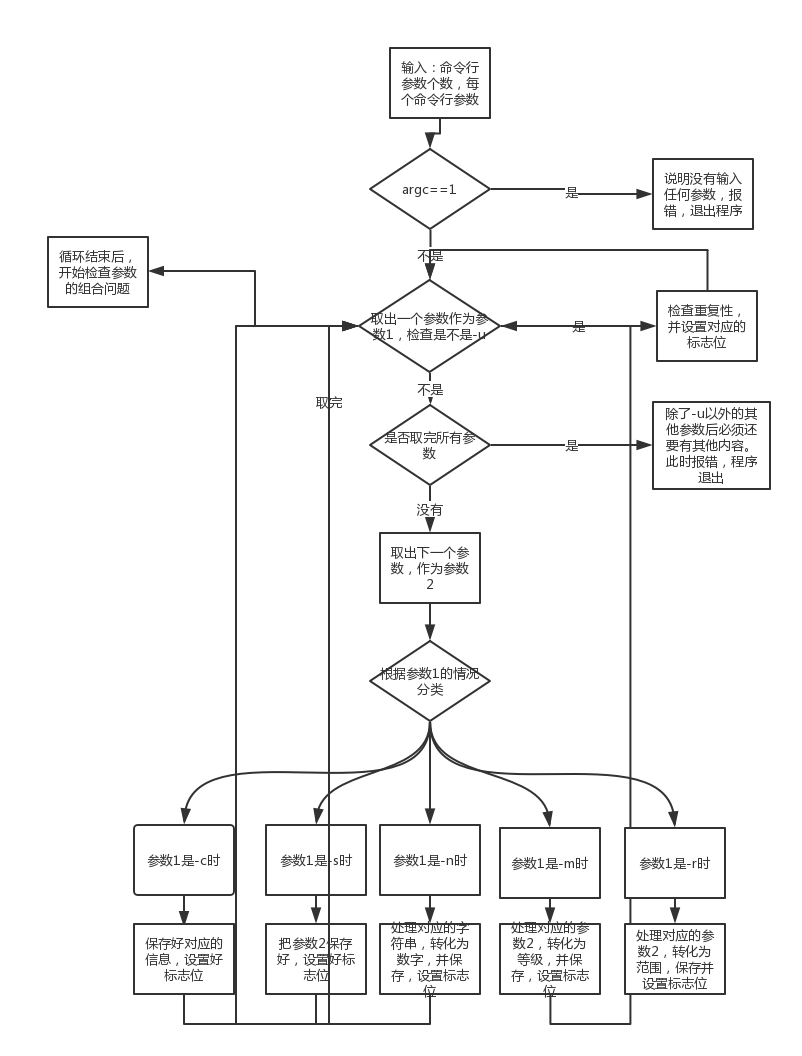
上面的逻辑图保证了大部分的错误都可以被检测出来,根据之前分好的错误类型,目前还有一类错误没有检测,就是参数的组合还需要检测是不是有问题。
参数的组合错误中,重复性在之前的逻辑也能被检测出来,这里简要说一下如何保证参数的组合没问题:
bool c_flag = false;
bool s_flag = false;
bool n_flag = false;
bool m_flag = false;
bool r_flag = false;
bool u_flag = false;
一开始有6个标志位,都先设置为false,每次检测到一个参数的输入,就把对应的标志位设置为true
所以这样在一开始遍历参数列表时就可以检测重复性:如果在设置一个参数比如-c的标志位发现已经为true了,那么就意味着这个参数-c重复出现了,这时就会抛出异常,输出错误信息,并结束程序。
所以如果能运行到遍历结束,就说明:之前的每个参数都只出现了一次。此时如何用这些标志位检测参数的组合是否有问题呢?这里我又想起计组里的一个小思想,计组里控制器首先需要确定一条32位指令是哪个指令,怎么确定?通过指令的“标志位”即前6位和后6位或者其他的标志位来唯一确定它。即每条不同的计组指令和它的这些标志位的编码是一一对应的。而这里我可以确定四种正确的组合情况:
①仅有-c
②仅有-s
③有-m和-n
④有-r和-n,可能还有-u
上面这四种情况是互相独立的事件,所以我们可以将它们分别用上面说的6个标志位表示好:
bool c_func = c_flag && !(s_flag || m_flag || r_flag || u_flag || n_flag);
bool s_func = s_flag && !(c_flag || m_flag || r_flag || u_flag || n_flag);
bool m_func = m_flag&&n_flag && !(c_flag || s_flag || r_flag || u_flag);
bool r_func = r_flag&&n_flag && !(c_flag || s_flag || m_flag);
最后这四个标志位因为四个事件是相互独立的,所以最多仅可能有一个是真的,但是如果最后这四个没有一个是真的,那么就意味着出现了这四个组合以外的其他的参数组合,此时报错就好。而且这样也不需要考虑参数之间的顺序。
所以以上就是我的整个命令行参数处理模块的逻辑描述。
2.根据输入的挖空数来产生数独游戏的generate逻辑
void generate(int number, int lower, int upper, bool unique, int[][] result)
这里挖空其实很简单,每行适当的挖几个空就好,但是如果还要求唯一解,那就需要思考如何挖空才能哇足够多的空还能保证唯一解。
关于挖空算法我也查了很多资料,但是仅仅只能找到“一边挖,一边判断是否唯一解”的随机性的算法。所以之后也是用这样的随机挖空然后判断的算法。
一开始我犯了错误,我总是在全部挖完后才判断是否满足唯一解,如果不满足,我又重新挖完然后重新判断。然而这样挖完空才判断会导致往往挖完的数独无法满足唯一解,而且很浪费时间,导致我的算法一开始的时候速度及其的慢!而且对于很多的数独终局,往往无论怎么挖都得不到唯一解的游戏。
之后我改正了这个错误,改为每一行每一行挖空,起初我还在想是不是要一个空一个空挖,挖完判断,但是这样做不但不好控制空的“均匀分布”,而且判断次数过多还可能导致时间过长。所以我还是选择了每行选择几个空挖,挖完判断,如果当前仍然满足唯一解就继续挖下一行,如果不满足那么重新挖这一行。
但是这样做又出现了新问题,就是发现很多时候对于很多数独终局,你在确定上面几行的挖空情况后,对于将要挖的这一行无论怎么挖可能都无法满足唯一解了,或者说很难满足唯一解。导致了死循环或者说挖空循环次数太多的问题。
然后我就加入了“栈”,用来保存之前几行的挖空情况,包括挖了几个空和挖了哪些空,如果发现这一行在重新挖空超过一定数量后仍然无法满足唯一解,那么可能我们需要重新随机挖上一行才能更快的解决问题。所以我加入了一个记录变量,记录当前这一行重新挖空的次数,如果超过了给定次数,就重新挖上一行的空,这样通过不断的随机挖空调整,每个数独终局总能“挖”出唯一解的游戏。
但是在测试挖空数为55,即最大挖空数时,发现还是会有挖空一直挖不出唯一解的情况,一直在循环。而且我还发现,对于一些数独终局,很轻易的就能把唯一解的数独给挖出来,而对于一些数独终局,往往需要循环挖空很多次才能挖出一个唯一解的数独,甚至等了很长时间也没有结果。所以我又采取了一个措施:我设置了另一个记录变量,这个记录变量记录了在挖空过程中每一行挖空次数超过最大次数失败然后回溯的次数,如果发现这个次数大于了自己设定的最大值,那么说明这个数独很难生成唯一解终局,直接放弃这个终局,接受下一个终局挖。
在经历了上面的一系列改进后,终于我的算法可以以还不错的速度随机生成唯一解的数独初局。但是我觉得还有改进的地方,注意到我之前设置了两个记录变量,第一个记录变量不如就记为trycount,记录了当前这一行挖空失败的次数,如果trycount大于了设定值k_maxtry,那么就会恢复上一行重新挖上一行,另一个记录变量记为backcount,每一次恢复上一行,这个变量就加1,然后当backcount大于设定值k_maxback后,这个数独终局停止挖空,放弃,选择下一个数独终局来进行挖空。所以说上面所说的k_maxtry决定了你会给某一行多少次挖空机会,而k_maxback决定了你给这个数独几次回溯重挖的机会。这两者共同决定了你在这个数独终局上愿意花多长时间尝试挖出一个唯一解的空。如果这两个数字设置过大,那么你可能会在一些很难挖出唯一解的终局上浪费时间,如果设置过小,那么你可能会错过一些再试一试就可以挖出唯一解的终局。
所以这两个数字的调整是很重要的,下面性能改进上详细说明。
四.UML图:
我们这次的设计感觉还是没有过多涉及继承多态什么的,所以UML图没有继承关系,所以这里简单画一下本次实现的uml图:
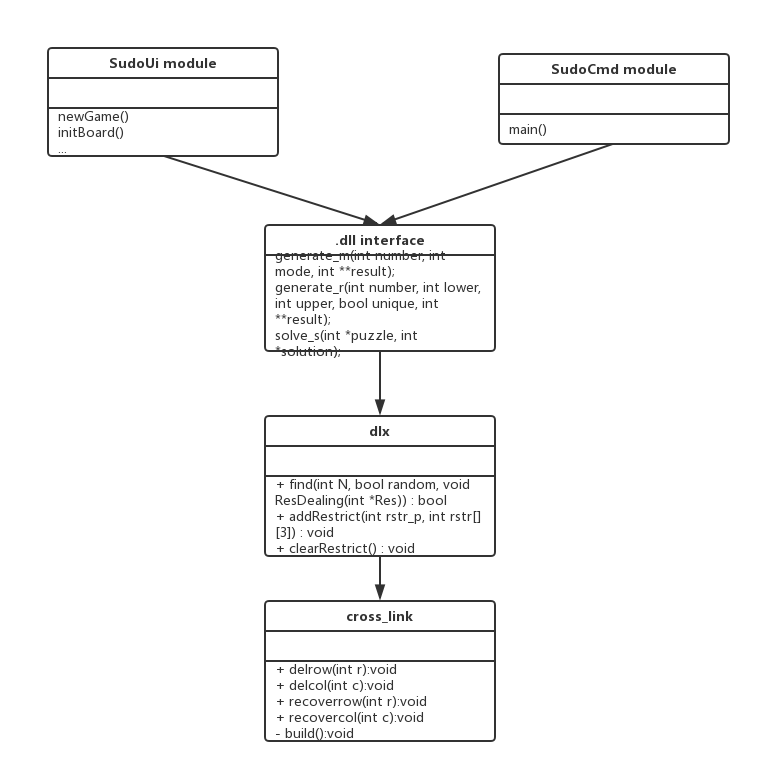
五.计算模块接口部分的性能改进
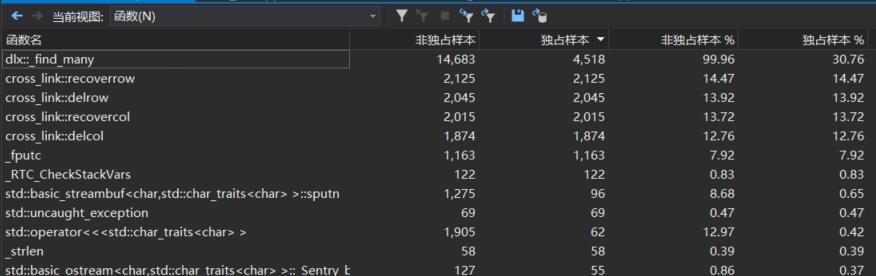
之前对于dlx的性能提升已经做了很多工作了,所以这里没有在这个上面花太多时间。
之前说过k_maxtry和k_maxback决定了你会在每个数独终局上尝试挖空的次数,如果这两个数字设置的过大,那么可能会在一些很难挖出唯一解的数独上浪费时间,如果这两个数字设置过小, 那么可能会造成生成数独的次数过多。所以我尝试了很多组参数来测试其生成1000个唯一解挖空数为55的数独需要多长时间。下面是一些数据:
|
k_maxtry |
10 | 7 | 5 | 3 | 10 | 7 | 5 | 3 | 10 | 7 | 5 | 3 | 10 | 7 | 5 | 3 |
| k_maxback | 10 | 10 | 10 | 10 | 7 | 7 | 7 | 7 | 5 | 5 | 5 | 5 | 3 | 3 | 3 | 3 |
| 耗时 | 1:32 | 1:19 | 1:13 | 1:17 | 1:16 | 1:19 | 1:17 | 1:24 | 1:22 | 1:16 | 1:16 | 1:32 | 1:14 | 1:09 | 1:32 | 1:18 |
从测试的结果看,(k_maxtry=7,k_maxback=3)组合的耗时最小,原来的组合是(5,5)所以性能提升了一点,但是并不多。
六.契约式编程的优缺点
在看了Design by Contract的相关资料后,我觉得这个“契约式编程”就和之前OO课上所讲的“规格”有很大的关系。
在OO课上一开始我是很反感写那么多规格的,但是随着学习的深入,我愈发觉得提前写好这些规格无论是对整体设计还是程序的完备性都是有很大的改善和帮助的。契约式编程讲究“前置条件”,“后置条件”和“不变性”。对于每个方法,我们先检验输入是否符合我们提前定义好的“前置条件”,然后保证这个方法对于符合前置条件的输入可以做到我们之前定义好的结果,那么这种规定可以有效的保证编程的规范性和正确性。
对于结对编程来讲,这个规范是特别有用的。因为在结对编程时,两人合作经常会出现一方需要调用另一方的方法,但是因为这个方法不是自己亲手写的,调用方不知道调用后会不会返回正确的结果,而被调用方又会担心调用方传入的参数可能不合法然后导致崩溃,所以这时就需要一种“契约”来提前规定好每一个方法的合法输入和具体效果,这样不仅双方在调用时可以放心的使用对方的方法,而且提前规定好输入和方法效果有利于更好的设计。
所以总的来说我觉得优点有:
1.提高合作变成的效率
2.提高代码的准确性
我觉得缺点可能就是需要提前规定好规则,可能需要花费很多时间。而且因为目前编程经验的不足,可能提前做好的设计在实际编程时又需要改动,造成很多时间浪费。
但是我觉得在大量编程经验和时间允许的条件下,“契约式编程”对提高编程效率和编程的准确性来说是特别有帮助的。
七.单元测试代码及覆盖率展示:
可以看到测试程序的覆盖率都达到了90%以上。

测试数据思路:
这里主要说一下我所测试的模块:void generate(int number, int lower, int upper, bool unique, int[][] result)
这个模块输入参数是:number,lower,upper,unique,需要往result数组中写入结果,据此我构造了如下的测试代码:
int uppers[] = { ,,,,,,,,, };
int lowers[] = { ,,,,,,,,, };
这里根据upper和lower的不同取值选择了10组upper和lower
for (int j = ; j<; j++) {
bool unique = true;
int upper = uppers[j];
int lower = lowers[j];
int number =
//这里可以把数字调小点,如果时间慢的话
int **result = new int*[number] {};
for (int i = ; i < number; i++)
{
result[i] = new int[]{ };
}
generate(number, lower, upper, unique, result);
for (int i = ; i < number; i++) {
int rstr[][] = { };
int rstr_p = ;
for (int j = ; j < ; j++) {
if (result[i][j])
{
rstr[rstr_p][] = result[i][j];
//bug 2 下标都写错为了0
rstr[rstr_p][] = j / + ;
rstr[rstr_p][] = j % + ;
++rstr_p;
}
}
这里需要测试两项:
DLX.addRestrict(rstr_p, rstr);
//1.挖空数量是否足够
assert(rstr_p >= ( - upper) && rstr_p <= ( - lower));
//2.是否满足唯一解要求
if (!unique)
{
assert(DLX.find(, false, NULL));
}
else {
assert(!DLX.find(, false, NULL));
}
DLX.clearRestrict();
}
}
根据upper和lower的不同情况选择了10组数据,覆盖了最大挖空数,最小挖空数,正常范围,最大范围和最小范围一致等10种情况,unique也测试了要求唯一解和不要求唯一解两种情况。
最后生成的数独每一个都先检查挖空数是不是在范围内,然后检查是不是满足之前规定的唯一解条件。
八.计算模块部分异常处理说明
在这次异常处理中,除了极少部分的异常,其他的异常我都专门写在了命令行参数的处理模块中,下面我详细的分析一下异常部分的处理。
这次的外部输入,可能就是命令行参数的输入了,而我们这次根据命令行要实现的具体功能就是四个:
- -c 生成数独终局
- -s生解决数独文件中的数独游戏
- -m和-n根据难易程度生成数独游戏
- -r和-n(-u)根据挖空数生成数独游戏
同时根据我之前所定义的错误的两种分类①功能性参数(-c -m -n等)的组合错误②内容型参数(-n后面的数字,-m后面的123等)的内容错误,我们可以从这两个角度很容易的总结出所有可能的异常,思路如下:
1.如果参数的数量不符合规定,那么会报出参数太少的错误。
2.参数的格式需要符合要求,即除了-u以外,其他的在功能性参数后必须要有内容型参数,如果不符合要求,那么抛出参数格式不对的错误
3.参数格式都对了以后,就看参数的内容是不是有问题,这里就要一个功能一个功能分析:
- 对于-c,我们规定它后面的数字字符串转化为数字后必须要在1~100*10000,所以我们需要检验这个数字字符串是不是符合要求,注意这里不仅要保证数字范围不能过大,尤其需要注意的是需要保证这个数字范围不能超过int,这个在OO中已经很熟练了。所以这里可能抛出数字超出范围的错误
- 对于-s,我们规定后面的字符串必须要是有效的文件名,即文件必须存在。这个我并没有在命令行参数的处理模块中规定,因为结对伙伴已经告诉我他在solve接口中判断了,所以这里没有检查文件名是否存在
- 对于-r,我们规定后面必须是“x~y”的格式,所以不符合这个格式的会抛出参数格式不对的错误,而对于x和y不仅需要判断是不是有数字范围超出的错误,还要保证lower必须要小于等于upper,如果不满足需要抛出lower大于upper的错误
- 对于-n,我们需要规定判断后面的数字字符串是不是满足1~10000的范围限制,具体的错误定义和之前的-c一致
- 对于-m,我们同样需要规定后面的数字字符串是不是满足在1~3的范围内
- 对于-u,其实查不出什么错
4.功能性参数都检测好后,接下来需要做的就是检查参数的组合问题,组合不正确需要抛出参数组合错误。
综上,我们可以定义出5种错误:
1.参数太少
命令行输入: sudoku.exe -c
try{
paraHandle(argc,argv,req);
}catch(too_few_para &e){e.what();}
会捕获到对应的异常
2.参数格式不对
命令行输入: sudoku.exe aaa
try{
paraHandle(argc,argv,req);
}catch(format_err &e){e.what();}
3.数字超出范围
命令行输入: sudoku.exe -c 100000000000000
try{
paraHandle(argc,argv,req);
}catch(out_of_range &e){e.what();}
4.lower大于upper
命令行输入: sudoku.exe -r ~ -n
try{
paraHandle(argc,argv,req);
}catch(lower_biggerthan_upper &e){e.what();}
5.参数组合错误
命令行输入: sudoku.exe -c -s puzzle.txt
try{
paraHandle(argc,argv,req);
}catch(combination_err &e){e.what();}
九.界面模块的详细设计过程
界面模块的重点在于数独棋盘的设计。我们设计的棋盘由81个pushButton组成。每个按钮使用styleSheet做不同的变形。在相应函数中,使用正则匹配和修改styleSheet从而实现按钮式样的动态变化。这里贴几个按钮的stylesheet:
border-style:solid;
border-color:black;
border-width:1px;
border-top-width:2px;
border-top-left-radius:10px;
border-left-width:2px;
下面是一个动态修改stylesheet的代码示例:
const std::regex bg("(background-color:).+?;\\n");
QPushButton *pb = board_[i];
std::string styleSheet = pb->styleSheet().toStdString();
styleSheet = std::regex_replace(styleSheet, bg, "$1" + none_rstrColor+ ";\n");
pb->setStyleSheet(styleSheet.c_str());
十.界面模块与计算模块的对接
将计算模块封装到DLL中,然后在界面模块动态调用DLL。以下是调用DLL中函数的过程:
typedef void(*GENERATE_M) (int, int, int**);
typedef void(*GENERATE_R) (int, int, int, bool, int**);
typedef bool(*SOLVE_S) (int *, int *); HMODULE coreDLL;
GENERATE_M generate_m = NULL;
GENERATE_R generate_r = NULL;
SOLVE_S solve_s = NULL; coreDLL = LoadLibrary(TEXT("Core/SoduCore.dll"));
generate_m = (GENERATE_M)GetProcAddress(coreDLL, "generate_m");
generate_r = (GENERATE_R)GetProcAddress(coreDLL, "generate_r");
solve_s = (SOLVE_S)GetProcAddress(coreDLL, "solve_s"); FreeLibrary(CoreDLL);
在响应函数中使用三个接口函数实现功能。
void MainWindow::initBoard(int mode, bool unique){
...
if(unique){
int difficultyDivide[] = {, , , };
generate_r(, difficultyDivide[mode - ], difficultyDivide[mode] - , true, &originBoard);
}
else{
generate_m(, mode, &originBoard);
}
...
}
void MainWindow::newGame(){
...
if(currentindex<){
int difficultyDivide[] = {, , , };
generate_r(, difficultyDivide[currentindex ], difficultyDivide[currentindex+] - , true, &originBoard);
}
else{
generate_m(, (currentindex%)+, &originBoard);
}
...
}
十一.描述结对的过程
话不多说,直接发我们讨论的照片。

十二.结对编程的优缺点和结对伙伴的评价
优点:
- 大大提高效率。结对编程看似是两人写一段程序,但其实写程序的速度大大提高,因为思路断了后可以有人帮助提醒
- 提高代码的准确率,因为结对编程两个人都在思考,所以可以很快的发现错误并改正
- 两个人相互督促,大大改善了拖延症
缺点:
- 可能需要一段磨合时间吧,一开始的效率肯定没有那么高的
结对伙伴刘的优点:
- 审美好,设计的GUI大家都说好看;积极主动,学习能力强,善于解决问题
缺点:
- 写的代码注释太少。。
我的优点:
- 比较细致认真,
缺点:
- 总是想得多,做的少。。
十三.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 120 |
| · Design Spec | · 生成设计文档 | 100 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 600 | 630 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 200 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 100 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 100 | 60 |
| 合计 | 1980 | 2000 |
十四.界面模块,测试模块和核心模块的松耦合
github地址:https://github.com/Liu-SD/SudoUi
合作小组两位同学学号:15061119 15061104
代码合并的过程有些曲折...我们本想在qt creator上修改相应的代码引入他们的lib,但是因为至今仍然不明的原因,qt一直不能争取的引入这个lib,所以不得已我们把我们的代码转移到VS上,使用VS的qt插件,修改相应代码就可以正确的使用他们的lib了。
经过测试,他们的模块没有大的问题,但是有两点不足:
1.根据数独的生成情况可以看出他们的数独游戏的终局生成没有加入随机的因素,即生成数独的顺序是按照固定的顺序回溯得到的,这样导致可玩性有些下降。
2.他们的生成唯一解的数独算法最后生成的数独空的分布不均匀,它们的挖空总是集中在上半部分。
十五.通过增量修改的方式,改进程序,发布一个真正的软件
github地址:https://github.com/Liu-SD/SudoUi
我们把我们的数独程序介绍给周围人玩,收到了如下反馈:
- “没有支持键盘输入很不爽”。关于这一点,因为截止时间快到了,所以在上交的版本还没有时间键盘输入,不过之后一定会实现键盘的输入的。
- “提示错误时把一整行都变红了,感觉很不舒服”。这里我们把这部分改了,原来是把错误的行/列/九宫格变红,现在是仅仅把错误重复的两个数字变红,这样能舒服很多
- “没有新手引导”。新手引导目前只能加上一个help按钮,给你说如何操作,更详细的引导之后再加。
- “太难了,不玩了不玩了”。这位同学连easy模式都觉得难,我觉得这是他自己的问题:)
- “remind me次数是不是需要加个限制”,这个限制之后会加。
- “有个bug,gui刚打开就可以点击数独格子了”。这确实是个bug,在用户设定好模式之前,不能让填数独的格子Enable。
[2017BUAA软工]结对项目-数独程序扩展的更多相关文章
- [2017BUAA软工]结对项目
软工结对项目 一. Github项目地址 https://github.com/crvz6182/sudoku_partner 二. PSP表格 Psp personal software progr ...
- [2017BUAA软工]结对项目:数独扩展
结对项目:数独扩展 1. Github项目地址 https://github.com/Slontia/Sudoku2 2. PSP估计表格 3. 关于Information Hiding, Inter ...
- [buaa-SE-2017]结对项目-数独程序扩展
结对项目-数独程序扩展 step1~step3:github:SE-Sudoku-Pair-master step4:github:SE-Sudoku-Pair-dev-combine step5:g ...
- [BUAA_SE_2017]结对项目-数独程序扩展
结对项目-数独程序扩展 Runnable on x64 Only sudoku17.txt 须放置在可执行文件同目录中,可移步以下链接进行下载 Core-Github项目地址 GUI-Github项目 ...
- [2017BUAA软工]个人项目
软工个人项目 一.Github项目地址 https://github.com/Lydia-yang/2017BUAA-SoftwareEngineering 二.解题思路 在刚开始拿到题目的时候,关于 ...
- [2017BUAA软工]个人项目心得体会:数独
心得体会 回顾此次个人项目,感受比较复杂,最明显的一点是--累!代码编写.单元测试.代码覆盖.性能优化,环环相扣,有种从作业发布开始就一直在赶DDL的感觉,但是很充实,也学习到和体验了很多东西.最令人 ...
- 软工结对项目之词频统计update
队友 胡展瑞 031602215 作业页面 GitHub 具体分工 111500206 赵畅:负责WordCount的升级,添加新的命令行参数支持(自定义输入输出文件,权重词频统计,词组统计等所有新功 ...
- BUAA 软工 结对项目作业
1.相关信息 Q A 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结对项目作业 我在这个课程的目标是 系统地学习软件工程开发知识,掌握相关流程和技术,提升 ...
- BUAA软工-结对项目作业
结对项目作业 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结对项目作业 我在这个课程的目标是 通过这门课锻炼软件开发能力和经验,强化与他人合作 ...
随机推荐
- Docker技术入门与实战 第二版-学习笔记-6-仓库
仓库(Repository)是集中存放镜像的地方 一个容易混淆的概念是注册服务器(Registry). 实际上注册服务器是管理仓库的具体服务器,每个服务器上可以有多个仓库,而每个仓库下面有多个镜像. ...
- OpenCV——边缘检测入门、Canny边缘检测
边缘检测的一般步骤: 最优边缘检测的三个评价标准: 低错误率:表示出尽可能多的实际边缘,同时尽可能地减少噪声产生的误报: 高定位性:标识出的边缘要与图像实际边缘尽可能接近: 最小响应:图像中的边缘只能 ...
- JS输入框邮箱自动提示(带有demo和源码)
今天在javascriptQQ群里面 有童鞋问到 有没有 "JS输入框邮箱自动提示"插件,即说都找遍了github上源码 都没有看到这样类似的插件,然后我想了下 "JS输 ...
- windows安装wget
windows安装wget1. 下载wget-1.11.4-1-setup.exehttps://jaist.dl.sourceforge.net/project/gnuwin32/wget/1.11 ...
- Oracle 函数function之返回结果集
工作中常需要经过一段复杂逻辑处理后,得出的一个结果集.并能够将这个结果集作为一个表看待,去进行关联查询 我一般采用建立函数function的方式来处理. --创建包,声明function和typeCR ...
- Huploadify V2.1+ SpringMVC上传文件的实现
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- 20155227辜彦霖《基于Cortex-M4的UCOSIII的应用》课程设计个人报告
20155227辜彦霖<基于Cortex-M4的UCOSIII的应用>课程设计个人报告 一.个人贡献 参与课设题目讨论及完成全过程: 资料收集: 负责主要代码调试: 撰写小组结题报告. 二 ...
- # 2017-2018-2 20155231《网络对抗技术》实验九: Web安全基础实践
2017-2018-2 20155231<网络对抗技术>实验九: Web安全基础实践 实验要求: 本实践的目标理解常用网络攻击技术的基本原理.Webgoat实践下相关实验. 实验内容: ( ...
- 20155301PC平台逆向破解
20155301PC平台逆向破解 1.掌握NOP, JNE, JE, JMP, CMP汇编指令的机器码 NOP:NOP指令即"空指令".执行到NOP指令时,CPU什么也不做,仅仅当 ...
- controlfile作为RMAN的repository时,对 keep time 的测试
4月2日,首先查看系统状况: SQL> show parameter control NAME TYPE VALUE ...