(Alpha)Let's-技术文档(技术规格说明书)
技术规格说明书
抽象
首先,对抽象原则的理解,“抽象”这一概念本身就很抽象。抽象体现的是一种概括能力。我们生活中遇到的很多客体,其在某些方面具备有一些相似甚至相同的性质,以这些特点而非事物本身来认识鉴别事物。在一篇文章中举到的例子颇为直观:“当你教一个小孩认识猫的时候,你会以具体的某一只猫作为例子告诉小孩这只是猫,如此反复几次以后,当出现其他不同的猫的时候小孩子也能辨识出那是猫。每一只猫都是不同的,但它们有着共同的特性,这些特性组合起来就是一个猫的定义也就是猫这个概念的抽象。由此可以看出抽象是对事物本质特性的归纳。”
针对我们的APP,在设计过程中,我们在定义各种实体的过程中就用到了抽象的思想,作为一个以“陌生人共同发起、参与活动”为核心功能的应用。我们需要集中关注的就是用户与活动这两个概念。其中用户这一概念相对简单,我们只需要获取到用户的身份信息,用来与其他用户加以区别,让用户之间能够进行交互识别。
而活动这一概念相对而言就复杂一些了,在现实世界中,有各种各样的活动:游山玩水,吟诗作赋,耕田织布,挑水浇园。那么问题来了:我们该如何从这纷繁复杂、无穷无尽的活动形式中概括抽象出活动这一概念,选取用来描述区分活动的属性呢。
针对这一问题,我们的思路是:从用户出发,从参与者的角度出发,设身处地地去筛选出参与一项活动需要了解到的以及想要了解到的信息。这样思考问题就很简单了:作为参与活动的用户,让我们产生想要参与一项活动的冲动的是什么呢?
在我看来,首先是这项活动的形式与内容,这是一项活动的灵魂所在,如果符合较多用户的爱好,自然会有很多用户想要加入。再来就是这一项活动的时间地点:如果时间产生冲突或者地点不太方便,即便是很想要参与,恐怕也只能望而却步。再来就是这项活动中其他的参与者了,作为一同游玩的小伙伴,尤其是在大家还互不认识的情况下,这一点就不能忽视了。即使只能了解到其他用户的一些基本信息,相信我们应该也能够以此为凭,对这次活动的参与体验有一个大致的预估(说白了就是一起去的妹子多不多)。
经过了上述分析:我们对活动这一概念抽象出了以下的属性:ID(主码)、名称、分类、时间、地点、发起者在发起活动时填写的活动的描述。而关于参与活动的其他用户,可以通过对数据库的查询进行获取并在活动界面上进行展示。
内聚/耦合/模块化
在工程实现中,我们首先做的是将代码实现模块化(Modularization)处理,然后根据定义的各个模块设计其中的细节。在实现过程中,可以用内聚(Cohesion)和耦合(Coupling)两个标准来评判该工程中各个实体之间的依赖程度。其中,内聚用来衡量单个模块内部各个成分之间相互依赖的程度,而耦合用来衡量不同模块之间的依赖程度。
其中,内聚根据程度从低到高可以划分为以下几种:
- 偶然内聚。如果一个模块的各成分之间毫无关系,则称为偶然内聚。
- 逻辑内聚。几个逻辑上相关的功能被放在同一模块中,则称为逻辑内聚。如一个模块读取各种不同类型外设的输入。尽管逻辑内聚比偶然内聚合理一些,但逻辑内聚的模块各成分在功能上并无关系,即使局部功能的修改有时也会影响全局,因此这类模块的修改也比较困难。
- 时间内聚。如果一个模块完成的功能必须在同一时间内执行(如系统初始化),但这些功能只是因为时间因素关联在一起,则称为时间内聚。
- 过程内聚。如果一个模块内部的处理成分是相关的,而且这些处理必须以特定的次序执行,则称为过程内聚。
- 通信内聚。如果一个模块的所有成分都操作同一数据集或生成同一数据集,则称为通信内聚。
- 顺序内聚。如果一个模块的各个成分和同一个功能密切相关,而且一个成分的输出作为另一个成分的输入,则称为顺序内聚。
- 功能内聚。模块的所有成分对于完成单一的功能都是必须的,则称为功能内聚。
在设计过程中,我们参考了Steve McCoonell的Code Complete,根据书中Section 5.2对耦合的定义,可以将耦合根据程度从低到高分为如下几种:
- 简单数据耦合
- 简单对象耦合
- 对象参数耦合
- 语义上的耦合
根据模块化的思想,一个内聚程度高,耦合程度低的系统是比较理想的。
在本项目中,宏观上两个大模块是:服务端模块,客户端模块
服务端模块分为:数据库模块,文件服务模块,短信服务模块,消息推送模块
客户端模块分为:用户实体,活动实体,登录注册模块,主页模块,发起活动模块,地图服务模块,个人中心模块。
其关系图如下:
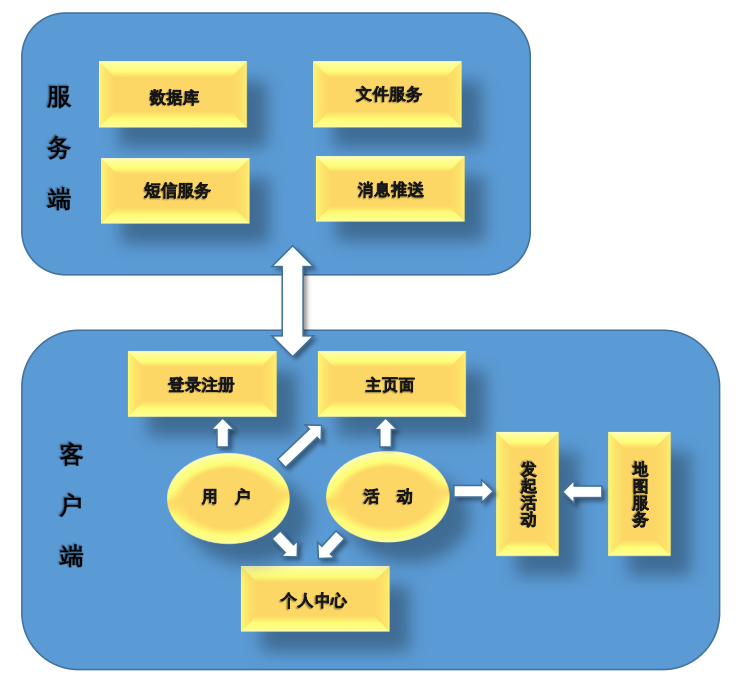
图中的箭头表示各个模块之间的依赖关系,被箭头指向的模块依赖于发出箭头的模块。
根据上述模块划分,接下来对各个模块的内聚和耦合进行分析:
- 内聚
- 各大模块的设计以多数以功能内聚为标准,如服务端的数据库模块负责用户、活动信息数据的存储和增删改查;文件服务模块负责用户图片等信息的存取;短信服务模块负责验证码短信的发送和验证;消息推送模块即负责消息的推送。
- 对于客户端,各个模块可以看做是各个不同功能的页面,每个页面的功能不同,因此各个模块的内聚均以功能内聚为标准。其中两个特殊的实体,用户和活动,也是通过将用户和活动的不同属性集合到一起完成用户类和活动类的管理功能。
- 根据上述分析,由于各大功能的定位划分都比较清晰明显,因此各个模块的内聚性较强。
- 耦合
- 在现阶段的设计中(不考虑安卓本身机制的设计),各个模块之间只有简单数据耦合,因此在设计上实现了松耦合(Loose Coupling)。如,服务端和客户端之间,通过协议和数据通信相互依赖;而地图服务和发起活动两个模块间,地图服务负责传递地图上的具体地址给发起活动模块。
- 其中大部分的数据传递都通过安卓中的Activity切换机制实现,利用putExtra函数实现不同模块(页面)间的信息传递,而非直接调用方法在类间传递。利用安卓本身机制进行不同模块间的松耦合进一步增强了系统的稳定性和安全性。
信息隐藏和封装
该内容在Code Complete一书中涉及。
此处摘录书中Section 5.3的原文:“Information hiding is part of the foundation of both structured design and object-oriented design.In structured design, the notion of 'black boxes' comes from information hiding.In object-oriented design, it gives rise to the concepts of encapsulation and modularity,and it is associated with the concept of abstraction.”
信息隐藏和封装是结构化编程和面向对象思想的基础。它产生了结构化编程中黑盒测试的想法,促进了面向对象过程中的封装与模块化的概念,并和抽象的编程思维相关。
为了论证这一点,作者采用了“冰山理论”作为说明。我们的代码与冰山一致,需要将大部分外界不关心的东西隐藏起来,而将可见的部分留给真正需要的人。
在遵守这一原则时,要注意隐藏两种因素:
- 隐藏复杂度:复杂性高的功能需要单独封装隐藏起来,一方面为了防止使用时要重复书写,一方面防止外部调用增加程序不确定性。
- 隐藏变化源:一些在程序中经常出现的全局变化源需要隐藏起来,比如计数器,可以用函数封装进行累加,避免直接对计数值操作。这样可以增强代码安全性和可拓展性。
关于封装,对一个类所封装的接口一方面要对类职责、角色进行高度抽象,将类本身内部、类与类之间的交互、行为、职能都做出一个抽象,并且保证这些抽象之间依赖性最小。
在工程中,设计参考了上述Code Complete书中的要求,我们的设计比较好的保证了隐藏和封装的原则要求。
从宏观上来看,主要有:
- 对数据对象即数据库中每张表的数据结构,进行信息隐藏和封装设计。
- 对每个相对独立和完整的功能,设计成一个单独的Activity。
对于第一种类型,我们的项目中User.java,完成了对User表中的所有数据项的隐藏,其访问控制关键字均为private,同时封装了相关修改其数据项的接口,所有与User数据有关的操作都通过这个类来完成。增强了代码的安全性和可扩展性。
对于第二种类型,项目中总共设计了11个Activity,每一个Activity负责一个单独的功能。比如InitiateEventActivity负责发起活动功能,其内部封装了完善活动信息的方法、与服务器数据库交互的函数、以及切换到其它Activity的操作,即能在当前Activity完成所有的功能处理,并且这些不公共的处理函数不会暴露给外界(类外部)。当Activity之间需要切换的时候,数据传递都通过安卓中的Activity切换机制实现,利用putExtra函数实现不同模块(页面)间的信息传递,而非直接调用方法在类间传递。利用安卓本身机制进行不同模块间的松耦合进一步增强了系统的稳定性和安全性。
界面和实现的分离
在工程设计过程中,界面和实现的分离主要体现在三个部分:人员分配,开发进度和前后耦合。
在人员分配方面,开发人员主要分为前端UI和后台实现两个部分,分工较为明确。前端的开发人员负责UI的美工设计,界面xml文件的编写,以及少数控件事件代码的书写;后台的开发人员即根据前端实现的各个控件模块进行事件实现。
在开发进度上,始终要求UI的进度需要至少提前后台一步,即后台开始进行功能一的实现时后台至少正在进行功能二的开发。这样保证后台的工作不会受到前端的制约,并且后台对前端有需求更改的时候前端能够有剩余时间进行修改。
在前后端耦合上,先由全体开发人员共同决定各个页面的功能,确定基础的控件需求,再由前端人员对各个页面的布局进行设计完成UI文件。此后,后台人员为各个控件添加事件和联系,同时针对不足的地方向前端人员提出修改意见,进一步优化界面显示和用户体验。
错误处理
项目中我们采取的错误处理主要有三种方式:
- 直接返回,上层处理
- 采取异常机制,抛出异常
- 重写监听器中的onFailure()方法或者onError()
我们在实际编码的过程中更加倾向于后两种处理方式,原因在于第一种方式要么需要定义一张冗长而复杂的错误码列表,而且对方法的返回类型有着苛刻的要求;要么就是要求上层代码的编写者清楚所调用函数的全部过程和返回值的语义。这样不利于我们进行快速的团队开发工作。
第二种方法,我们定义了MyException,具体包含的部分异常类型定义如下:
class ReplicatePhoneException extends Exception { }
class PasswordNotEqualException extends Exception { }
class VerifyCodeFailException extends Exception { }
class NullItemException extends Exception {
public NullItemException(String str) {
super(str);
}
}
异常机制主要用于不存在监听器机制的处理函数或者是监听器内部所调用的函数所出现的错误情况。异常的好处是,如上所示的异常类型名字,能够很快的“望文生义”,即只要是同一团队的成员只要看到这个函数所抛出的异常就能很快的了解这是什么错误情况,自己能进行相应的处理。比如在项目中,button的onClick()事件的监听器不存在onFailure()方法,于是我们的设计是在其中再调用一个函数,如下所示:
public void onClick(View v) {
try {
registerClick();
} catch (NullItemException e) {
// TODO
} catch (PasswordNotEqualException e) {
// TODO
} catch (VerifyCodeFailException e) {
// TODO
}
}
通过这样的异常处理机制,就可以在适当的情景下,把相应的错误情况进行有效的处理。
第三种方法就更为便捷方便,比如这样的代码:
query.findObjects(this, new FindListener<UserActivity>(){…})
这是向服务器数据库请求一个查询的情景,可以看到代码中新建了一个FindListener<T>()监听器,同时要求重写下面这两个函数。
@Override
public void onSuccess() {
// TODO Auto-generated method stub
}
@Override
public void onError() {
// TODO Auto-generated method stub
}
然后就可以很方便的在onError()函数中进行可能出现的错误情况的处理。
假设
我们的项目运行环境设定的是搭载android 4.4.2及以上版本的android系统的平台。
假如运行在比android 4.4.2低的安卓系统上,会提示“当前安卓版系统本太低,无法安装该应用”这样的错误信息。
主要的大模块就本地模块和服务器端模块。本地模块只对系统的版本有要求,所以不会产生其他影响;然而服务器端模块代码基于一个开源框架,安全性具有相当的保障,出现的所有错误都是由于本地上传的请求或者数据不符合相应的格式,这种问题我们在编码及调试阶段全部解决了。经过上述分析,这两个模块之间还可能出现的问题只有一种可能性,就是网络通讯失败,所以我们在相应的监听器中都有通讯失败情况的处理函数。由此,程序就可以在任何情况下,都能按照开发时假设的运行环境和模块逻辑下运行。
对于输入输出的假设,有两种情况。一种是在调用模块之前进行参数有效性判断,另一种是进入模块之后首先对参数进行有效性判断。本项目中,我们团队约定,所有模块都要对于传进的参数进行有效性判断,若无效则抛出异常或者显示错误信息。这样约定的理由是,本模块的开发者更清楚本模块所需参数的要求,所以由本模块开发者进行判断分析更有效快捷。
应对变化的灵活性
1) 实体的灵活性
我们的工程中涉及到的两个主要实体,用户和活动。在设计实现中,我们将两个实体在数据库表中对应的各个属性和类中的成员变量一一对应,这样在后期需要修改实体属性时,只要往数据库表中添加相应的列,并在代码中添加对应成员以及相应的get/set方法即可。
2) 界面显示的灵活性
由于设计的APP中有许多不同类型信息动态展示的页面,如:搜索一个信息我们需要同时返回搜索到的用户集和活动集;点击一个活动界面中已经参与的用户,需要展现所有已参与用户的列表;可以查看用户发起/参与的活动列表;主页可以显示推荐的活动列表等等。为了使页面的显示更灵活,提高其泛型以备后期的功能拓展,我们在实现过程中为展示列表的ListView实现了一个泛型Adapter,它可以针对需要展现的不同类型信息对ListView的布局进行相应调整,而后期如果需要增加显示的类型,只需要设计好该类型信息的布局模式,将该模式提供给Adapter即可。所有修改只需要一行代码即可完成,大大增强了显示的灵活性。
对大量数据的处理能力
我们这个App的后台数据库操作,用到了一个网站提供的完全免费的云数据库,可视化的云端NoSQL数据表设计,支持多达10种数据类型。简单,自由地根据业务需求完成数据库配置,轻松实现云与端的数据交互。
谈及对数据的操作,很自然地联想到了数据的增删改查。
在数据量增大的过程中,上述操作的复杂度都会逐渐提升,这是无可避免的。我们所能做到的就是结合平台本身的一些特性,使得程序的效率保持在一个相对稳定的基础上。
首先,针对数据的增加,我们采取了手机验证的方式,这本身就杜绝了恶意注册缓存策略,而且在注册过程中需要发送验证码,针对同一个手机号,每天只能发送五条验证码,这也就使得恶意验证变得不再可能。
另外受数据量影响较为严重的就是查询功能了,如果数据量很大,查询的过程必定会耗费较多的时间,这会使得用户体验变差,针对这一点,我们采取的办法是加入缓存功能,当用户的设备处于离线状态时,就可以从缓存中获取数据来显示。或者在应用界面刚刚启动,从网络获取数据还未得到结果时,先使用缓存数据来显示。这样可以让用户不必在按下某个按钮后进行枯燥的等待。
并且我们设计了几种不同的缓存策略,以适应不同应用场景的需求。缓存查询通常是将查询结果缓存在磁盘上。
IGNORE_CACHE :只从网络获取数据,且不会将数据缓存在本地,这是默认的缓存策略。
CACHE_ONLY :只从缓存读取数据,如果缓存没有数据会导致一个BmobException,可以忽略不处理这个BmobException。
NETWORK_ONLY :只从网络获取数据,同时会在本地缓存数据。
NETWORK_ELSE_CACHE :先从网络读取数据,如果没有,再从缓存中获取。CACHE_ELSE_NETWORK:先从缓存读取数据,如果没有,再从网络获取。
ACHE_THEN_NETWORK:先从缓存取数据,无论结果如何都会再次从网络获取数据。也就是说会产生2次调用。
值得注意的一点是:只有当缓存查询的条件一模一样时才会获取到缓存到本地的缓存数据。
这就使得用户获取到的数据的准确性得到了保障。
在分析这部分的问题的过程中,我们主要采取的策略就是充分结合平台的功能特性,以此为手段,从用户的需求与体验感受出发,进行程序的逐步优化,以使程序能够在数据量较大的情况下仍然不失效率。
(Alpha)Let's-技术文档(技术规格说明书)的更多相关文章
- [转]unity3d 脚本参考-技术文档
unity3d 脚本参考-技术文档 核心提示:一.脚本概览这是一个关于Unity内部脚本如何工作的简单概览.Unity内部的脚本,是通过附加自定义脚本对象到游戏物体组成的.在脚本对象内部不同志的函数被 ...
- Atitit usrQBK1600 技术文档的规范标准化解决方案
Atitit usrQBK1600 技术文档的规范标准化解决方案 1.1. Keyword关键词..展关键词,横向拓展比较,纵向抽象细化拓展知识点1 1.2. 标题必须有高大上词汇,参考文章排行榜,1 ...
- Kafka 技术文档
Kafka 技术文档 目录 1 Kafka创建背景 2 Kafka简介 3 Kafka好处 3.1 解耦 3.2 冗余 3.3 扩展性 3.4 灵活性 & 峰值处理能力 3.5 可恢复性 ...
- RabbitMq 技术文档
RabbitMq 技术文档 目录 1 AMQP简介 2 AMQP的实现 3 RabbitMQ简介 3.1 概念说明 3.2 消息队列的使用过程 3.3 RabbitMQ的特性 4 RabbitMQ使用 ...
- Umbraco官方技术文档 中文翻译
Umbraco 官方技术文档中文翻译 http://blog.csdn.net/u014183619/article/details/51919973 http://www.cnblogs.com/m ...
- [转]chrome技术文档列表
chrome窗口焦点管理系统 http://www.douban.com/note/32607279/ chrome之TabContents http://www.douban.com/note/32 ...
- Niagara技术文档汇总
Niagara技术文档汇总http://wenku.baidu.com/view/ccdd4e2c3169a4517723a38f.html Niagara讲解要点http://wenku.baidu ...
- DL动态载入框架技术文档
DL动态载入框架技术文档 DL技术交流群:215680213 1. Android apk动态载入机制的研究 2. Android apk动态载入机制的研究(二):资源载入和activity生命周期管 ...
- 使用Jupyter Notebook编写技术文档
1.jupyter Notebook的组成 这里它的组件及其工程构成,帮助大家更好的用好jupyter Notebook 组件 Jupyter Notebook结合了三个组件: 笔记本Web应用程序: ...
- 技术文档生成工具:appledoc
做项目一般都会要求写技术文档,特别是提供SDK或者基础组件的.如果手写这类技术文档的话,工作量比编写代码也少不了多少.比如 Java 语言本身就自带 javadoc 命令,可以从源码中抽取文档.本篇我 ...
随机推荐
- linux结束程序内存不会马上释放的解决方法
Linux下频繁读写文件时,内存资源被耗尽,当程序结束后,内存不会释放需要清除缓存.Linux缓存有dentry,buffer cache,page cache. 注:Dentry用来加速文件路径 ...
- 10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.创建MySQL数据 create database solr; use solr; DROP TABLE ...
- mtime参数的理解
mtime参数的理解应该如下:-mtime n 按照文件的更改时间来找文件,n为整数.n表示文件更改时间距离为n天, -n表示文件更改时间距离在n天以内,+n表示文件更改时间距离在n天以前.例如:-m ...
- 6、JVM--类文件结构(上)
6.1.概述 写的程序需要经编译器翻译成由0和1构成的二进制格式才能由计算机执行 6.2.无关性基石 Java在刚刚诞生之时曾经提出过一个非常著名的宣传口号:“一次编写,到处运行(Write Once ...
- Jmeter性能测试-分布式压力测试
作为一个测试行业的菜鸟,由于投身于一个小公司,包揽所有的测试.刚开始的功能测试到接口测试,稳定性测试,兼容性测试等,一般由于是小项目所以对于性能有所忽略,也没怎么涉及,公司接了个大项目,后期对于性能上 ...
- C# 自定义类型转换
1.显式转换和隐式转换: ; long b=a; // 从int到long的隐式转换 int c=(int) b; // 从long到int是显式转换 ------------------------ ...
- sql的一个查询,情景:a表中存在的数据,且在b表中不存在 (not in,not exists
这里需要强调的是b表中关联字段的值是唯一的这种情况,并且b表尽量是列举类型的,意味着表比较小. ==================== 准备数据: 1. 建两个类似表,test1,test2,只有i ...
- 20155317王新玮《网络对抗》Exp2 后门原理与实践
20155317王新玮<网络对抗>Exp2 后门原理与实践 一.实验内容 (1)使用netcat获取主机操作Shell,cron启动 (2)使用socat获取主机操作Shell, 任务计划 ...
- Exp1 PC平台逆向破解(5)M
Exp1 PC平台逆向破解(5)M [ 直接修改程序机器指令,改变程序执行流程] 用命令cp pwn1 20155320备份pwn1 输入objdump -d 20155320反汇编,找到call指令 ...
- Data Consistency Primer
云应用通常来说,使用的数据很多都是分散的,来自不同的数据仓库.在这种环境下,管理和保持数据一致性是很复杂的,无论是在并发跟可用性上都可能出问题.开发者有的时候就需要为了强一致性而牺牲可用性了.这也就意 ...