SQL Server 索引重建手册
Declare @dbid int
Select @dbid=DB_ID()
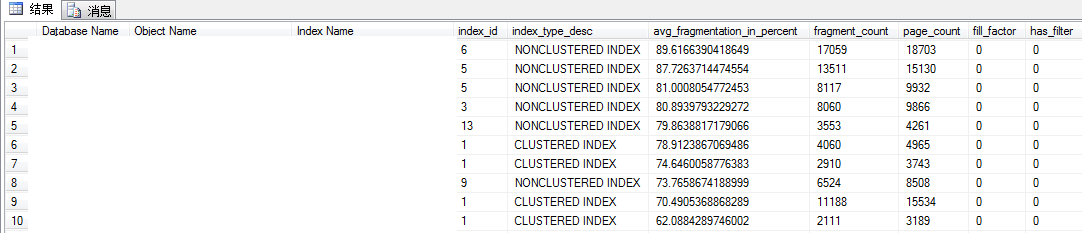
SELECT DB_NAME(ps.database_id) AS [Database Name], OBJECT_NAME(ps.OBJECT_ID) AS [Object Name],
i.name AS [Index Name], ps.index_id, ps.index_type_desc, ps.avg_fragmentation_in_percent,
ps.fragment_count, ps.page_count, i.fill_factor, i.has_filter, i.filter_definition
FROM sys.dm_db_index_physical_stats(@dbid,NULL, NULL, NULL,null) AS ps
INNER JOIN sys.indexes AS i WITH (NOLOCK)
ON ps.[object_id] = i.[object_id]
AND ps.index_id = i.index_id
WHERE ps.database_id = DB_ID()
AND ps.index_type_desc <> 'HEAP'
AND ps.page_count > 2500
ORDER BY ps.avg_fragmentation_in_percent DESC OPTION (RECOMPILE);
alter index index_name
on table_name
rebuild
with(online = on ,sort_in_tempDB = on , maxdop = 最大并行度);
go
- 为避免空间使用过多,应当对索引进行依次重建,不建议使用alter index all on table_name...的语句。
- 如果一个表有多个索引需要重建,则重建的顺序必须为:先重建聚集索引(即主键索引),再重建非聚集索引。
SQL Server 索引重建手册的更多相关文章
- SQL Server 索引重建的 4 种方法
解决方法 方法 1. 重建指定索引,这种方法没有性能可谈.重建时表还不可访问. 方法 2. 在线重建索引,只有SQL Server 企业版才支持. 方法 3. 使用填充因子重建,这样做不一定可以减小查 ...
- Sql Server索引重建
公司线上数据有几千万数据,有时候索引碎片会导致索引达不到我们的预期查询效率,这个时候将索引重建将会提升一定效率,不过重建的时候一定得晚上用户少的时候,索引重建需要一定时间. 直接贴自动重建索引脚本吧 ...
- SQL Server 索引重建脚本
在数据的使用过程中,由于索引page碎片过多,带来一些不利的性能问题,我们有时候需要对数据库中的索引进行重组或者重建工作.通常这个阈值为30%,大于30%我们建议进行索引重建,小于则进行重组操作.以下 ...
- SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘.既键值的逻辑顺序决定了表中相应行的物理顺序 多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度 页 ...
- [笔记整理]SQL Server 索引碎片 和 重建索引
铺垫知识点: 数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘.既键值的逻辑顺序决定了表中相应行的物理顺序 多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server 索引的图形界面操作 <第十二篇>
一.索引的图形界面操作 SQL Server非常强大的就是图形界面操作.关于索引方面也一样那么强大,很多操作比如说重建索引啊,查看各种统计信息啊,都能够通过图形界面快速查看和操作,下面来看看SQL S ...
- SQL Server索引设计 <第五篇>
SQL Server索引的设计主要考虑因素如下: 检查WHERE条件和连接条件列: 使用窄索引: 检查列的选择性: 检查列的数据类型: 考虑列顺序: 考虑索引类型(聚集索引OR非聚集索引): 一.检查 ...
随机推荐
- 【原创】NVIC中断
(1)NVIC 全称为Next Vector Interrupt Controoler,嵌套中断向量控制器,是ARM Cortex M3的内部设备之一,任何一款基于ARM Cortex M3的 ...
- Java 并发编程-NIO 简明教程
问题来源 在传统的架构中,对于客户端的每一次请求,服务器都会创建一个新的线程或者利用线程池复用去处理用户的一个请求,然后返回给用户结果,这样做在高并发的情况下会存在非常严重的性能问题:对于用户的每一次 ...
- docker使用ssh远程连接容器(没钱买服务器又不想安装虚拟机患者必备)
突然有需求,需要使用go语言写个ssh终端连接功能,这时候手上又没有服务器,虚拟机也没有,正好使用docker搞起来 docker容器开启sshd服务,模拟服务器 我们知道docker是可以用exec ...
- 让Python代码更快运行的 5 种方法
不论什么语言,我们都需要注意性能优化问题,提高执行效率.选择了脚本语言就要忍受其速度,这句话在某种程度上说明了Python作为脚本语言的不足之处,那就是执行效率和性能不够亮.尽管Python从未如C和 ...
- Java基础系列——序列化(一)
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6797659.html 工作中发现,自己对Java的了解还很片面,没有深入的研究,有很多的J ...
- CPU上下文切换
CPU上下文切换包括进程上下文切换.线程上下文切换及中断上下文切换,当任务进行io或发生时间片事件及发生中断(如硬件读取完成)时,就会进入内核态,发生CPU上下文切换. 进程上下文切换,进程的上下文信 ...
- MySQL中间件之ProxySQL(9):ProxySQL的查询缓存功能
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html ProxySQL支持查询缓存的功能,可以将后端返回的结果集缓存在自己的 ...
- 翻译:用户变量(User-Defined Variable)(已提交到MariaDB官方手册)
本文为mariadb官方手册:User-Defined Variables的译文. 原文:https://mariadb.com/kb/en/user-defined-variables/我提交到Ma ...
- 金三银四招聘季,这些BAT以及独角兽互联网公司官方招聘网站值得关注。(个人梳理备用:附BAT以及独角兽公司官方招聘网址)
金三银四是一年当中的招聘最旺盛的时期,即招聘高峰期,在这个期间内有非常多名企巨头公司的放出大量的岗位信息.以博主几年的工作经验来看,在这期间找到称心如意的工作的几率大大提升,对于很多程序员来说,薪水高 ...
- c# 静态构造函数与构造函数的调用先后
先上代码: 测试类: /// <summary> /// 构造函数 /// </summary> public RedisHelper() { Console.WriteLin ...