Perl引用入门
在perl中只有3种基本的数据结构:标量、数组、hash。变量可以是数值,可以是字符串。
这三种基本数据结构的数据存储方式如下:
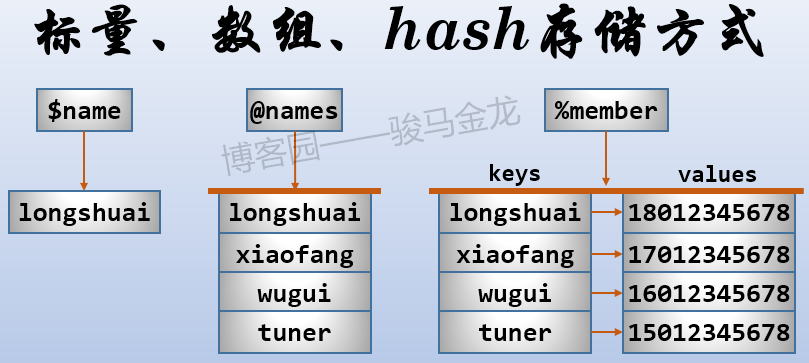
但是,仅仅由这3种基本结构,就可以构造出更复杂的数据结构,例如hash中用数组做value,数组中用hash做元素。
但是,perl对于底层的一些数据存储,很多时候对这些数据是直接拷贝存储的。而有些时候是没必要去拷贝数据的,通过引用,可以避免拷贝操作,哪里需要数据,用数据对象的引用即可,也就是插一个"指针"的事。
如何表示数组和hash的引用
引用就像是指针,对一个引用进行输出,在字符串上下文将返回它指向的目标数据的类型和内存地址,在数值上下文将返回地址空间。例如,数组的引用和hash的引用,如下图。
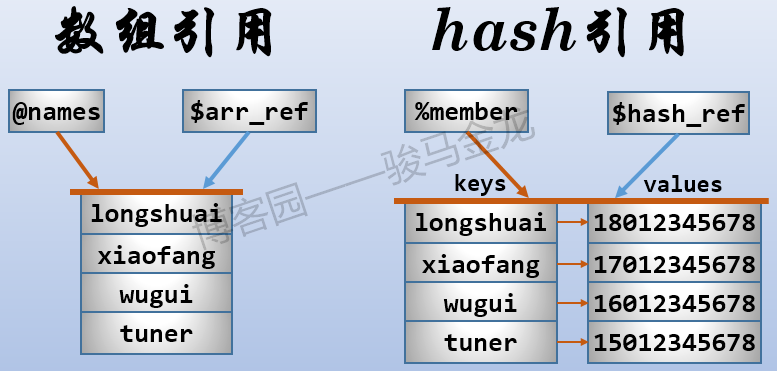
上图中,将数组@name的引用赋值给了一个名为$arr_ref的标量,将hash@member的引用赋值给了一个名为$hash_ref的标量。注意,引用都是标量。
引用的方式很简单,只需在 数组的@符号、hash的%符号之前加上反斜线\ 。例如\@name就表示这是名称为name的数组的引用,\%member就表示这是名称为member的hash的引用。
例如:
@name=qw(longshuai xiaofang wugui tuner);
%member=(
longshuai => "18012345678",
xiaofang => "17012345678",
wugui => "16012345678",
tuner => "15012345678"
);
$arr_ref=\@name; # 将数组的引用赋值给一个标量
$hash_ref=\%member; # 将hash的引用赋值给一个标量
print "$arr_ref","\n"; # 输出:ARRAY(0x18a5fa0)
print "$hash_ref","\n"; # 输出:HASH(0x18a6060)
由于引用被当作一个标量,所以能使用标量的地方,就能使用引用。例如,将一个数组的引用放进hash中:
@name=qw(longshuai xiaofang wugui tuner);
$arr_ref=\@name;
%member=(
longshuai => "18012345678",
xiaofang => "17012345678",
wugui => "16012345678",
tuner => $arr_ref
);
print "$member{'tuner'}","\n"; # 输出数组的引用:ARRAY(0x13d7fa0)
除数组、hash之外的引用
除数组、hash有引用,标量、函数也有引用,而且还不止这些,比如文件句柄引用、正则表达式引用等。
目前,暂时只需了解标量、数组、hash、函数的引用方式即可,分别为:
\$x # 引用 scalar
\@y # 引用 array
\%z # 引用 hash
\&f # 引用 function
标量引用的一个技巧
下面创建一个指向$foo1值的引用$ref_foo1,也就是说$ref_foo1和foo1是等价的,要引用这个变量的值,需要使用$$ref_foo1或$foo1。
my $ref_foo1 = \$foo1;
例如:
my $foo1="xyz";
my $ref_foo1 = \$foo1;
print "$$ref_foo1\n";
经常会看到下面一种代码格式:
my $ref_foo2 = \my $foo2;
等号右边\my $foo2表示先创建一个用my修饰的变量$foo2(因为未赋值,所以初始化为undef),再创建一个指向它的引用$ref_foo2。和上面的示例相比,它只是多了一个临时创建变量的功能,因为my的优先级高于\,它等价于\(my $foo2)。
上面的语句还可以赋值:
my $ref_foo2 = \(my $foo2="abcd");
print "$$ref_foo2\n";
引用计数器和引用作用域
可以为同一段数据对象创建多个引用,由于每个引用都指向同一段数据对象,所以相同数据对象的引用是完全一致的。
由于引用在数值上下文返回引用对象的地址空间,所以可以用比较操作符==来比较引用,当然,使用eq来比较也完全可以:
@name=qw(longshuai xiaofang wugui tuner);
$arr_ref=\@name;
$arr_ref1=\@name;
$arr_ref2=$arr_ref;
print "ref equals\n" if $arr_ref == \@name; # true
print "ref equal ref1\n" if $arr_ref == $arr_ref1; # true
print "ref1 equal ref2\n" if $arr_ref1 == $arr_ref2; # true
在perl中,对每段数据的引用都会维护一个引用计数器:
- 最初创建数据对象时,赋值给初始化数组、hash,引用数为1
- 以后每次引用、赋值引用、拷贝引用等操作都会对引用数加1
- 将其赋值为undef,则显式取消引用关系,引用数减1
- 引用有作用域,当离开作用域时,该作用域内的引用都将取消(可看作是赋值型的标量,当定义my时,超出边界就失效)
- 只要引用计数器还未减少为0,用于存储数据对象所占用的内存就不会释放。当引用计数为0时,perl将回收这段内存空间,但不会交还给操作系统,perl再需要的时候会重用这段内存空间存储新数据,而无需重新向操作系统申请开辟新内存
这和硬链接类似,每创建一个硬链接,硬链接数量就加1,每删除一个硬链接,硬链接数量就减1。
#!/usr/bin/perl
use 5.010;
@names=qw(longshuai xiaofang wugui tuner); # ref counter = 1
$arr_ref1=\@names; # ref counter = 2
$arr_ref2=$arr_ref1; # ref counter = 3
$arr_ref3=\@names; # ref counter = 4
$arr_ref2=undef; # ref counter = 3
@names=undef; # ref counter = 2
say "arr: @names"; # 输出:arr:
say "ref1: $arr_ref1"; # 输出:ARRAY(0x55befad8f0a0)
say "ref2: $arr_ref2"; # 输出:ref2:
say "ref3: $arr_ref3"; # 输出:ARRAY(0x55befad8f0a0)
如果使用my或local这样作用域关键词去定义引用,当引用超出对应边界后,就会失效,引用计数器就会对应减1。当然,如果不定义为my或local,则超出边界也不会失效。
#!/usr/bin/perl
use 5.010;
@names=qw(longshuai xiaofang wugui tuner); # ref counter = 1
$arr_ref1=\@names; # ref counter = 2
{
my $arr_ref2=$arr_ref1; # ref counter = 3
my $arr_ref3=\@names; # ref counter = 4
} # ref counter = 2
say "ref1: $arr_ref1";
say "ref2: $arr_ref2"; # arr_ref2已经失效
say "arr: @names";
say "ref3: $arr_ref3"; # arr_ref3已经失效
有一点需要注意,就是将引用作为子程序(函数)的参数时,它首先将引用赋值给@_特殊变量,这时引用计数会加1,当退出子程序时,@_将失效,引用计数器将减1。
&mysub(\@names); # 直接将引用赋值给@_
&mysub($arr_ref); # 拷贝引用,@_也将引用数据对象
引用计数管理内存的优点和缺点
perl采用引用计数的方式回收内存空间。引用计数管理内存的方式已经存在了很久,和GC(Garbage collection)垃圾回收机制是同一年(1960年)被研究出来的。无论是哪种内存管理机制,都有优点,也都有缺点。
对于引用计数管理方式而言,它最大的优点在于:
- 即刻回收:只要数据对象的引用计数器为0了,就会立刻被回收
- 暂停时长很短:因为回收速度时无需遍历内存,所以负责回收的工作效率很高
使用引用计数管理内存最大的缺点在于:
- 因为要频繁增、减计数,负责增、减的工作压力非常大
- 无法回收循环引用(引用环路问题,见下文)
相比于引用计数管理内存的方式,GC回收机制都是在内存不够后,遍历整个内存来回收的,所以有延迟性和低效性(有好几种改进的GC,都各有优缺点,但原始的GC算法就是如此)。
其实无论是引用计数还是GC,都对它们各自的缺点有各种改进,但修补缺陷的同时,也会损伤它们的优点,所以不同语言针对不同适用场景,总是采用不同的折衷手段。
回到引用计数的一个缺点问题上:无法回收循环引用问题。所谓循环引用,是指A引用B的对象,B又引用A的对象。例如:
@name1=qw(longshuai wugui);
@name2=qw(xiaofang tuner);
push @name1,\@name2;
push @name2,\@name1;
验证下:
#!/usr/bin/perl
use 5.010;
@name1=qw(longshuai wugui);
@name2=qw(xiaofang tuner);
say "name1_1: ",\@name1; # ARRAY(0xNAME1)
say "name2_1: ",\@name2; # ARRAY(0xNAME2)
push @name1,\@name2;
push @name2,\@name1;
say "name1_2: @name1"; # ARRAY(0xNAME2)
say "name2_2: @name2"; # ARRAY(0xNAME1)
如下图所示:
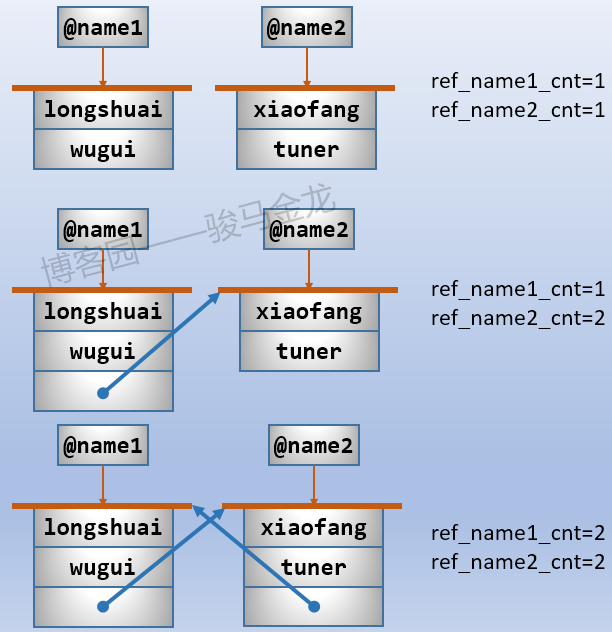
这样的引用环路,使得@name1和@name2对应的数据对象的引用,无论如何也无法减少到0。
这样会导致一个重大问题:内存泄漏(memory leak)。随着泄漏越来越多,内存终有被耗尽的时刻。也许真正写成内存泄漏的代码比较少,但很多时候构建复杂的数据结构时,无意中可能就会出现引用环路问题。
要避免引用环路,可以使用perl的另一种引用行为:弱引用(weak)。或者,在退出引用作用域之前,打破引用环路。例如:
{
@name1=qw(longshuai wugui);
@name2=qw(xiaofang tuner);
push @name1,\@name2;
push @name2,\@name1;
......
# 退出作用域之前,在引用的内部清空引用数据
@name1=();
@name2=();
}
这样,在退出作用域后,@name1=qw(longshuai wugui (这段空)),同理@name2。如此一来,@name1和@name2又变回了最初状态,都只有一个引用,且没有了循环引用。
当然,上面是直接清空初始引用的,如果push进去的是引用变量,则清空引用变量即可。
{
@name1=qw(longshuai wugui);
@name2=qw(xiaofang tuner);
$name1_ref=\@name1;
$name2_ref=\@name2;
push @name1,$name1; # 使用引用变量,而非初始的数组名引用
push @name2,$name2;
......
# 退出作用域之前,在引用的内部清空引用数据
$name1=undef;
$name2=undef;
}
要检查是否出现内存泄漏问题,可以使用Test::Memory::Cycle模块。
最后,perl目前还没有其它垃圾回收机制(garbage collection),也许在未来的版本中可能会引入新的gc管理方式来替代引用计数的管理方式。
Perl引用入门的更多相关文章
- perl 引用(数组和hash引用) --- perlreftut - Mark 的一个简单的'引用'教程 ---Understand References Today. --Mark Jason Dominus, Plover Systems (mjd-perl-ref+@plover.com)
https://blog.csdn.net/fangwei1235/article/details/8570886 首页 博客 学院 下载 论坛 APP 问答 商城 活动 VIP会员 招聘 ITeye ...
- Perl 引用:引用就是指针,Perl 引用是一个标量类型可以指向变量、数组、哈希表(也叫关联数组)甚至子程序。
Perl 引用引用就是指针,Perl 引用是一个标量类型可以指向变量.数组.哈希表(也叫关联数组)甚至子程序,可以应用在程序的任何地方. 1.创建引用1.使用斜线\定义变量的时候,在变量名前面加个\, ...
- Perl语言入门: 斜线不是元字符,所以在不作为分隔符时不需要加上反斜线。
Perl语言入门: 斜线不是元字符,所以在不作为分隔符时不需要加上反斜线.
- Perl引用
引用就是C语言中的指针,perl引用是一个标量类型可以指向变量.数组.哈希表(也叫关联数组)甚至子程序,可以应用在程序的任何地方. 在变量前面加一个\就得到了这个变量的一个引用 #!usr/bin/p ...
- perl 引用(一)
1. 普通变量引用 variable reference 引用就好比C语言的指针,引用变量存储被引用变量的地址.赋值时注意要在变量前加上 \;使用时要多加一个 $ . 当然,引用也可以成为简单变量,可 ...
- Perl 引用与匿名数组
写这篇是因为工作遇到一个需要使用列表作为hash的值的问题,这在Python中是非常简单而轻松的事,如下面这段python程序. def add_to_index(index, keyword, ur ...
- Perl 语言入门6-9
---- 第6章 哈希----------- 简介 键值对.键和值都是任意标量,但键总是会被转换成字符串. 键唯一,值可重复. 应用场景:一组数据对应到另一组数据时. 如找出重复/唯一/交叉引用/查表 ...
- Perl语言入门
Perl 是 Practical Extraction and Report Language 的缩写,可翻译为 "实用报表提取语言". Perl语法基础: (1)Perl程序由声 ...
- Perl语言入门--3--文件读取与写入
现有文件test.txt,内容为:"123\n456" 1,打开文本test.txt #!/usr/bin/perl open d,"test.txt"; d ...
随机推荐
- ubuntu安装spyder和jupyter notebook
ubuntu安装spyder和jupyter notebook 安装spyder 安装spyder sudo apt install spyder sudo apt install spyder3 安 ...
- shell中的常用条件判断
-e :该“文件名”是否存在.exit-d :该文件名是否为目录.dir-f :该文件名是否为普通文件.file -b:该文件是否为块文件.block -r :该文件是否具有可读属性 read-w ...
- 简单了解Django
Django 是开源代码web应用的框架,由python完成,django的主要目的是简便,快速开发数据库驱动网站 主要用于测试,运维,自测. 1.下载Django. 个人建议使用命令pip inst ...
- react native (1) 新建页面并跳转
新建页面 1.新建文件 import React from 'react'; import { Text } from 'react-native'; export default class tod ...
- 算法第四版jar包下载地址
算法第四版jar包下载地址:https://algs4.cs.princeton.edu/code/
- some knowledge of the IT world
IT世界一切皆是可信息化(数据的转换)即信息记录一切,对信息的控制{存储,运算,传输{信息的位置转移},转换}就是对一切的控制{硬件(实质维)以信息的控制{软件形式(存在维)}进行操作} 信息本身的实 ...
- Mysql函数大全以及存储过程、函数、触发器、游标等等
https://www.cnblogs.com/slowlyslowly/p/8649430.html MySQL大全 存储过程: 基本语法 : create procedure sp_name([[ ...
- jQuery获取父级、兄弟节点的方法
一.jQuery的父节点查找方法 $(selector).parent(selector):获取父节点 $(selector).parentNode:以node[]的形式存放父节点,如果没有父节点,则 ...
- 利用Socket 实现多客户端的请求与响应
import java.io.IOException; import java.net.ServerSocket; import java.net.Socket; public class Serve ...
- 修复运行 tasklist 命令时提示 ERROR: Not found
最近碰到了一个脚本运行 tasklist 总是提示 ERROR: Not found,在这里找到了修复的方法 https://superuser.com/questions/1282867/windo ...