SQL Server表关联
表关联:Hash、Nested Loops、Merge。这是实际算法,不是T-SQL中的inner/left/right/full/cross join。优化器会把这些T-SQL写法转换成上面的3种算法。
通过这3种算法,可以推出其他操作符的行为。
1.Hash Match Join
Hashing(散列法)和Hash Table。
Hashing:是编码技术,把数据转换成符号格式,以便有效的支持数据查询。如SQL Server会把一行数据转换成一个能标识这行数据内容的唯一值,并存放到一个表中,这个表就是Hash Table,也就是哈希表,这种技术类似加密,当需要原始数据时,也能解密出来。
Hash Table:实际上是一个数据结构,通过散列法的处理,把数据存放到表中,如SQL Server从一个实体表中查询数据,并把数据转成哈希值,存放到一个哈希表中,这个表则存放在tempdb中。
当SQL Server 把两个数据放入临时的哈希表中,然后用这个结构对比数据,并返回匹配的数据时,就会出现Hash Match操作符。
select e.JobTitle,a.City,p.LastName+','+ p.FirstName as EmployeeName
from HumanResources.Employee as e
join Person.BusinessEntityAddress as bea
on e.BusinessEntityID=bea.BusinessEntityID
join Person.Address a
on bea.AddressID=a.AddressID
join Person.Person as p
on e.BusinessEntityID =p.BusinessEntityID
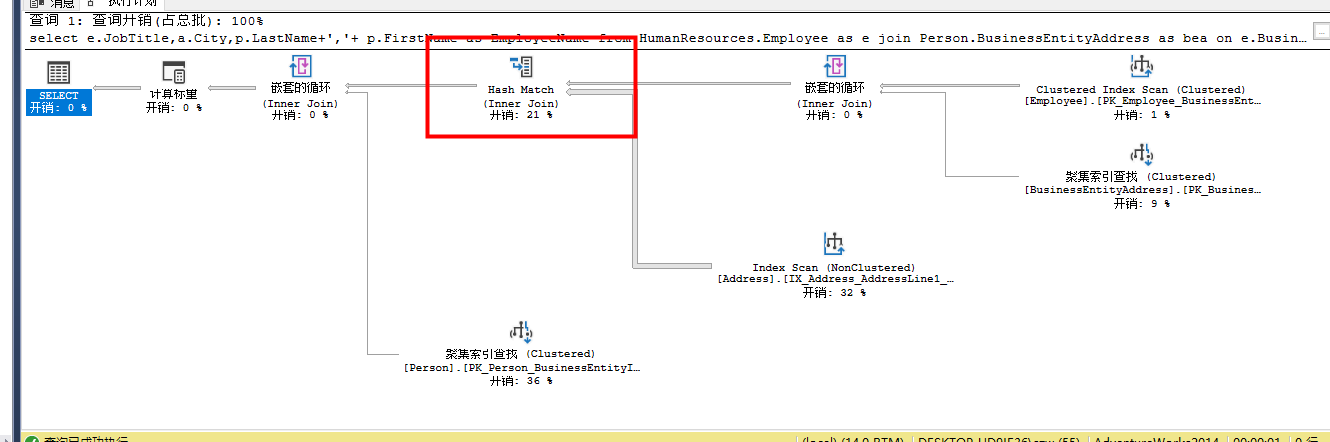
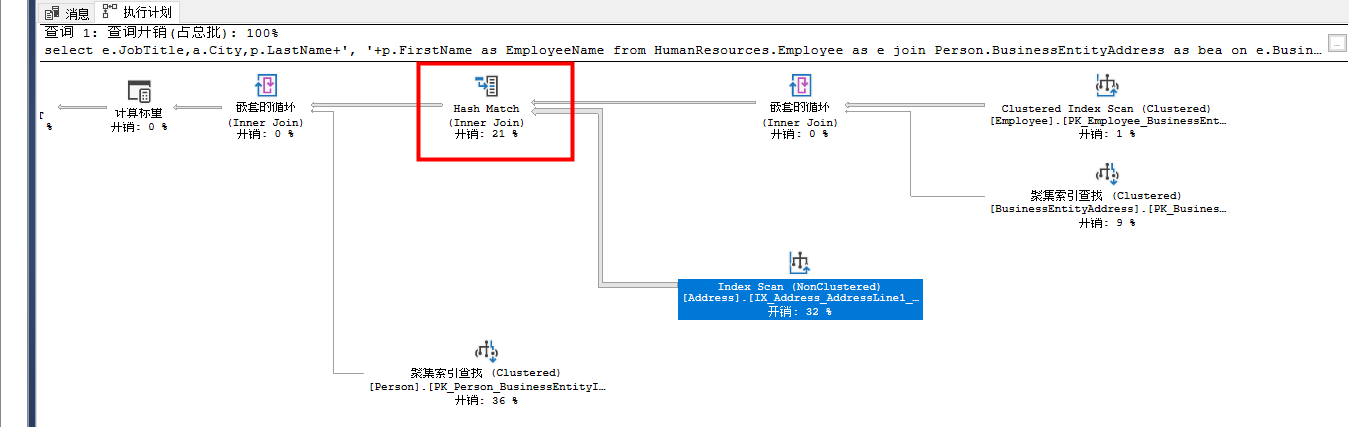
这个Hash Match Join操作把Index Scan和Nested Loops合并,然后输出结果集,这个操作符是开销比较大的操作符,在性能优化中也应该纳入检查范畴。看看tooltips
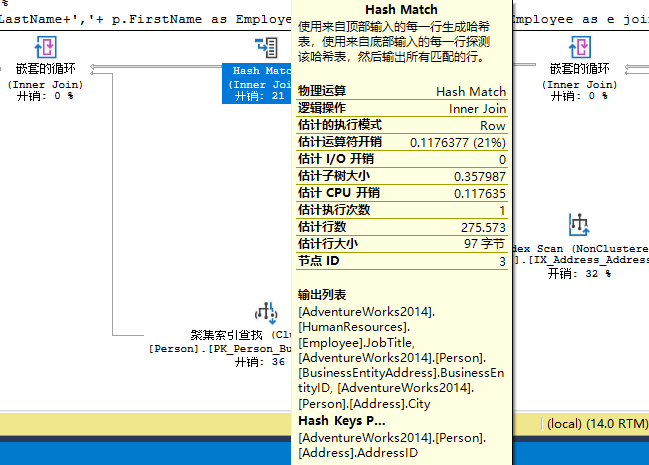
当SQL Server必须关联两个大数据集时,会把两个数据集中较小那个集合的数据进行散列处理,把哈希值存入tempdb的哈希表上,然后较大的那个数据集,会一行一行的与哈希表匹配,以便实现‘关联’逻辑,由于较小的表已经被转换成哈希表,所以它的体积会变得更小,在对比时使用哈希值相对较快。所以如果哈希表比较小,处理速度将会更快。如果两表都很大,对比于其他类型的关联算法,Hash Match Join会非常低效。同时,由于Hash表中存放在tempdb中,所以查询中的Hash Join将会给tempdb带来很大的负载压力。
当看到Hash Match时,应该检查一下是否存在下面的问题:
丢失索引或者无效索引
缺少Where条件
where条件中存在非SARG操作,如对筛选列进行标量函数、隐式类型转换等,
以上会导致优化器不使用上面已由的索引。
Hash Match暗示着你可能需要检查查询是否有改写可能,是否可以加索引,使其关联时更加有效,如果没有可能,Hash Match Join也不失为一个高效的算法。
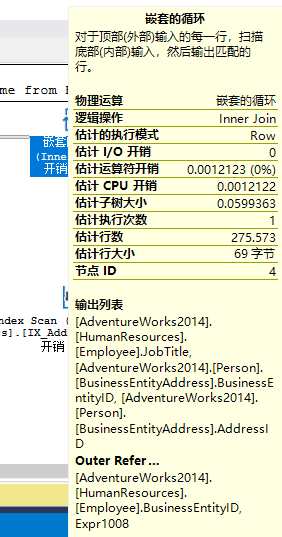
2.Nested Loops Join
上面的执行计划右边第一个是Nested Loops操作符。表Employee和表BusinessEntityAddress上分别存在聚集索引扫描和聚集索引查找,连个操作通过箭头汇总到Nested Loops操作符中
Nested Loops Join涉及两个数据集,一个叫做inner set,一个叫做outer set,位于上方的是outer set,下方的为inner set。这种算法把inner set的数据集与outer set一一匹配,知道inner set的数据集全部扫描完毕为止。如果两个数据集都很小,或者inner set数据很小,这种算法可算是最佳关联算法。
3.Merge Join
它的特点:关联的数据已经排序。这种算法把两个数据集合并到一起,由于已经预先排序,所以数据合并后已是有序的。然后会和匹配值匹配,排序的数据可以很快地标识数据,如1,2,3这样的数据,如果匹配到数据2已经找到,就不需要在往后查找了。
对于已经排序的数据集,这种算法是其中一种最高效的算法,但是很多时候数据集都是无序的,所以这种算法会引入一个排序操作符来协助工作,这个操作符会降低预期的
select c.CustomerID from Sales.SalesOrderDetail od
join Sales.SalesOrderHeader oh on od.SalesOrderID=oh.SalesOrderID
join Sales.Customer c on oh.CurrencyRateID=c.CustomerID
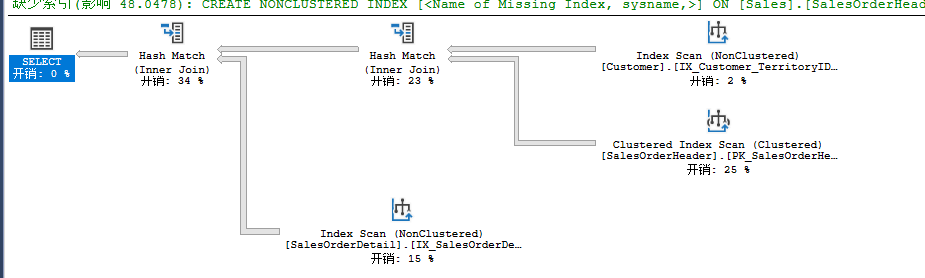
由于没有Where条件,SalesOrderHeader和Customer会进行相应的扫描操作。得到的数据集会通过Merge Join关联,当关联列已排序时,优化器会考虑用这种算法。关联使用了CustomerID作为两表关联关系,而这个列在两表中均有索引,也就是预排序。
这种算法对预排序的关联列非常高效。反之,如果关联列没有预排序,优化器又选择了这种算法,就会出现以下两种情况:
1.优化器预先排序关联列,然后在进行Merge Join
2. 使用较为低效的Hash Match关联
四.筛选数据
select e.JobTitle,a.City,p.LastName+', '+p.FirstName as EmployeeName
from HumanResources.Employee as e
join Person.BusinessEntityAddress as bea on e.BusinessEntityID=bea.BusinessEntityID
join Person.Address a on bea.AddressID=a.AddressID
join Person.Person as p on e.BusinessEntityID=p.BusinessEntityID
where e.[JobTitle]='Production Technicaian - WC20'
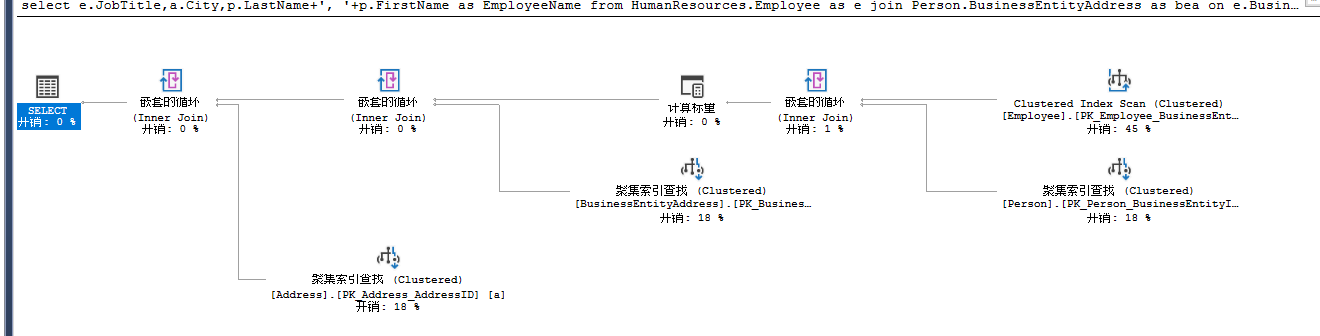
右上角的聚集索引扫描,WHERE条件使用PK_Employee_BusinesEntityID把数据集控制到了22行,由于数据量很小,优化器决定使用Nested Loops算法关联两表,产生数据集
聚集索引扫面的影响函数:

嵌套循环后的影响行数:

可以看到数据量还是很少,下一步优化器会用这个结果集和Address上通过聚集索引查找获得的数据再次进行Nested Loops。由于查询中添加了where子句,所以把数据控制到了很小的程度。把where条件去掉,再看之心计划,从中可以看到添加条件的重要性。
使用SET STATISTICS TIME ON 和SET STATISTICS IO ON查询。然后分别执行,查看数值,当然,前提是返回结果是一致的,不一致的数据没什么可比性。还有,就是把两个查询放到一个查询界面,然后打开实际执行计划,运行查询,再从执行计划中对比两者的开销,通常来说,百分比越低,开销越小,理论上性能也就越好。
SQL Server表关联的更多相关文章
- SQL Server表分区【转】
转自:http://www.cnblogs.com/knowledgesea/p/3696912.html SQL Server表分区 什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在 ...
- SQL Server表分区详解
原文:SQL Server表分区详解 什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆 ...
- SQL Server表分区-水平分区
SQL Server表分区,sql server水平分区 转自:http://www.cnblogs.com/knowledgesea/p/3696912.html 根据时间的,直接上T-SQL代码 ...
- 在一个SQL Server表中的多个列找出最大值
在一个SQL Server表中一行的多个列找出最大值 有时候我们需要从多个相同的列里(这些列的数据类型相同)找出最大的那个值,并显示 这里给出一个例子 IF (OBJECT_ID('tempdb..# ...
- SQL Server表分区的NULL值问题
SQL Server表分区的NULL值问题 SQL Server表分区只支持range分区这一种类型,但是本人觉得已经够用了 虽然MySQL支持四种分区类型:RANGE分区.LIST分区.HASH分区 ...
- SQL Server 表变量和临时表的区别
SQL Server 表变量和临时表的区别 一.表变量 表变量在SQL Server 2000中首次被引入.表变量的具体定义包括列定义,列名,数据类型和约束.而在表变量中可以使用的约束包括主键约束,唯 ...
- [转载]在SQL Server 中,如何实现DBF文件和SQL Server表之间的导入或者导出?
原来使用SQL Server 2000数据库,通过DTS工具很方便地在SQL Server和DBF文件之间进行数据的导入和导出,现在安装了SQL Server2005之后,发现其提供的“SQL Ser ...
- SQL server 表中如何创建索引?
SQL server 表中如何创建索引?看个示例,你就会了 use master goif db_id(N'zhangxu')is not nulldrop database zhangxugocre ...
- 图解SQL多表关联查询
图解SQL多表关联查询 网上看了篇文章关于多表连接的,感觉很好,记录下来,以便日后自己学习 内连接 左连接 右连接 全外连接 1. 查两表关联列相等的数据 ...
随机推荐
- 析构函数 声明为protected
1.如果一个类被继承,同时定义了基类以外的成员对象,且基类析构函数不是virtual修饰的, 那么当基类指针或引用指向派生类对象并析构(例如自动对象在函数作用域结束时:或者通过delete)时,会调用 ...
- 内核中dump_stack()的实现,并在用户态模拟dump_stack()【转】
转自:https://blog.csdn.net/jasonchen_gbd/article/details/44066815?utm_source=blogxgwz8 版权声明:本文为博主原创文章, ...
- Keepalived两节点出现双VIP情况及解决方法【原创】
1.故障现象 俩台服务器keepalived的vip在俩台服务器同时出现 A:10.70.12.72 B:10.70.12.73 2.问题分析 1).先分析那台服务器在提供服务 A:10.70.12. ...
- 范围for语句
C++11 新标准引入了一种更简单的for语句,这种语句可以遍历容器或其他序列的所有元素.范围for语句(range for statement)的语法形式是: for (declaration : ...
- struts2项目搭建
把strutslib中的所有jar包添加到类路径 在src下创建struts.xml文件 <?xml version="1.0" encoding="UTF-8&q ...
- ansible和python的zabbix_api批量添加rsync服务的监控
一.正常的处理流程: 1.添加zabbix用户对rsync程序的sudo权限,且不需要输入密码 # visudo即在/etc/sudoers配置文件最后添加如下内容 Defaults:zabbix ! ...
- Centos7环境下etcd集群的搭建
Centos7环境下etcd集群的搭建 一.简介 "A highly-available key value store for shared configuration and servi ...
- linux下export命令添加、删除环境变量(转载)
转自:http://blog.csdn.net/shenshendeai/article/details/49794699 export命令 功能说明:设置或显示环境变量. 语 法:export [- ...
- Linux学习之CentOS(三)--初识linux的文件系统以及用户组等概念
Linux学习之CentOS(三)--初识linux的文件系统以及用户组等概念 进入到了Linux学习之CentOS第三篇了,这篇文章主要记录下对linux文件系统的初步认识,以及用户组.用户权限.文 ...
- Codeforces 671D Roads in Yusland [树形DP,线段树合并]
洛谷 Codeforces 这是一个非正解,被正解暴踩,但它还是过了. 思路 首先很容易想到DP. 设\(dp_{x,i}\)表示\(x\)子树全部被覆盖,而且向上恰好延伸到\(dep=i\)的位置, ...