X86-64寄存器和栈帧--牛掰降解汇编函数寄存器相关操作
X86-64寄存器和栈帧
概要
说到x86-64,总不免要说说AMD的牛逼,x86-64是x86系列中集大成者,继承了向后兼容的优良传统,最早由AMD公司提出,代号AMD64;正是由于能向后兼容,AMD公司打了一场漂亮翻身战。导致Intel不得不转而生产兼容AMD64的CPU。这是IT行业以弱胜强的经典战役。不过,大家为了名称延续性,更习惯称这种系统结构为x86-64。
X86-64在向后兼容的同时,更主要的是注入了全新的特性,特别的:x86-64有两种工作模式,32位OS既可以跑在传统模式中,把CPU当成i386来用;又可以跑在64位的兼容模式中,更加神奇的是,可以在32位的OS上跑64位的应用程序。有这种好事,用户肯定买账啦。
值得一提的是,X86-64开创了编译器的新纪元,在之前的时代里,Intel CPU的晶体管数量一直以摩尔定律在指数发展,各种新奇功能层出不穷,比如:条件数据传送指令cmovg,SSE指令等。但是GCC只能保守地假设目标机器的CPU是1985年的i386,额。。。这样编译出来的代码效率可想而知,虽然GCC额外提供了大量优化选项,但是这对应用程序开发者提出了很高的要求,会者寥寥。X86-64的出现,给GCC提供了一个绝好的机会,在新的x86-64机器上,放弃保守的假设,进而充分利用x86-64的各种特性,比如:在过程调用中,通过寄存器来传递参数,而不是传统的堆栈。又如:尽量使用条件传送指令,而不是控制跳转指令。
寄存器简介
先明确一点,本文关注的是通用寄存器(后简称寄存器)。既然是通用的,使用并没有限制;后面介绍寄存器使用规则或者惯例,只是GCC(G++)遵守的规则。因为我们想对GCC编译的C(C++)程序进行分析,所以了解这些规则就很有帮助。
在体系结构教科书中,寄存器通常被说成寄存器文件,其实就是CPU上的一块存储区域,不过更喜欢使用标识符来表示,而不是地址而已。
X86-64中,所有寄存器都是64位,相对32位的x86来说,标识符发生了变化,比如:从原来的%ebp变成了%rbp。为了向后兼容性,%ebp依然可以使用,不过指向了%rbp的低32位。
X86-64寄存器的变化,不仅体现在位数上,更加体现在寄存器数量上。新增加寄存器%r8到%r15。加上x86的原有8个,一共16个寄存器。
刚刚说到,寄存器集成在CPU上,存取速度比存储器快好几个数量级,寄存器多了,GCC就可以更多的使用寄存器,替换之前的存储器堆栈使用,从而大大提升性能。
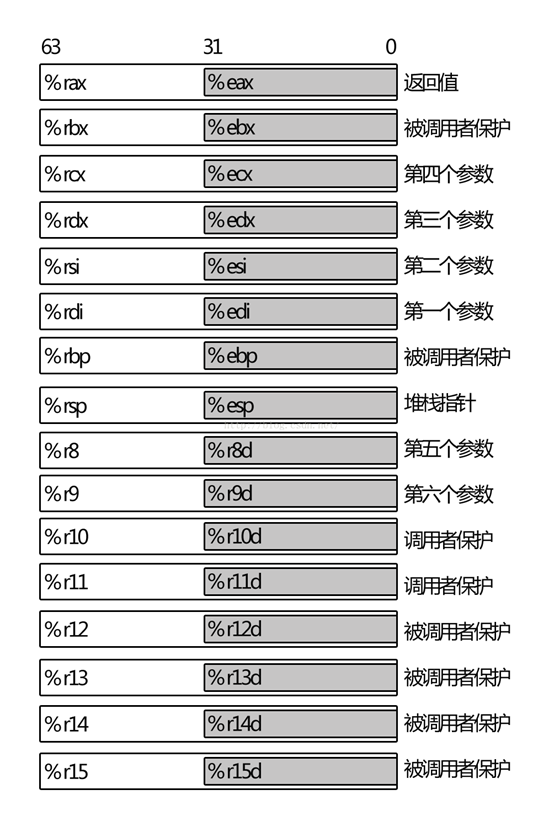
让寄存器为己所用,就得了解它们的用途,这些用途都涉及函数调用,X86-64有16个64位寄存器,分别是:
%rax,%rbx,%rcx,%rdx,%esi,%edi,%rbp,%rsp,%r8,%r9,%r10,%r11,%r12,%r13,%r14,%r15。
其中:
- %rax 作为函数返回值使用。
- %rsp 栈指针寄存器,指向栈顶
- %rdi,%rsi,%rdx,%rcx,%r8,%r9 用作函数参数,依次对应第1参数,第2参数。。。
- %rbx,%rbp,%r12,%r13,%14,%15 用作数据存储,遵循被调用者使用规则,简单说就是随便用,调用子函数之前要备份它,以防他被修改
- %r10,%r11 用作数据存储,遵循调用者使用规则,简单说就是使用之前要先保存原值
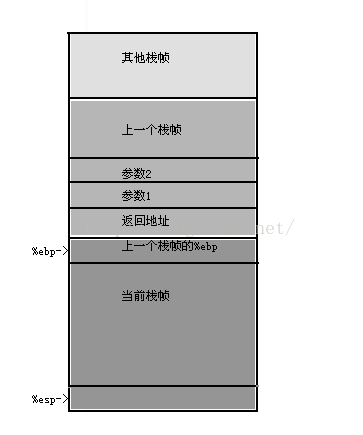
栈帧
栈帧结构
C语言属于面向过程语言,他最大特点就是把一个程序分解成若干过程(函数),比如:入口函数是main,然后调用各个子函数。在对应机器语言中,GCC把过程转化成栈帧(frame),简单的说,每个栈帧对应一个过程。X86-32典型栈帧结构中,由%ebp指向栈帧开始,%esp指向栈顶。
函数进入和返回
函数的进入和退出,通过指令call和ret来完成,给一个例子
#include
#include </code>
int foo (
int x )
{
int array[] = {1,3,5};
return array[x];
} /* ----- end of function foo ----- */
int main (
int argc, char *argv[] )
{
int i =
1;
int j = foo(i);
fprintf(stdout, "i=%d,j=%d\n", i, j);
return EXIT_SUCCESS;
} /* ---------- end of function main ---------- */
命令行中调用gcc,生成汇编语言:
Shell > gcc –S –o test.s test.c

Main函数第40行的指令Callfoo其实干了两件事情:
- Pushl %rip //保存下一条指令(第41行的代码地址)的地址,用于函数返回继续执行
- Jmp foo //跳转到函数foo
Foo函数第19行的指令ret 相当于:
- popl %rip //恢复指令指针寄存器
栈帧的建立和撤销
还是上一个例子,看看栈帧如何建立和撤销。
说题外话,以”点”做为前缀的指令都是用来指导汇编器的命令。无意于程序理解,统统忽视之,比如第31行。
栈帧中,最重要的是帧指针%ebp和栈指针%esp,有了这两个指针,我们就可以刻画一个完整的栈帧。
函数main的第30~32行,描述了如何保存上一个栈帧的帧指针,并设置当前的指针。
第49行的leave指令相当于:
Movq %rbp %rsp //撤销栈空间,回滚%rsp。
Popq %rbp //恢复上一个栈帧的%rbp。
同一件事情会有很多的做法,GCC会综合考虑,并作出选择。选择leave指令,极有可能因为该指令需要存储空间少,需要时钟周期也少。
你会发现,在所有的函数中,几乎都是同样的套路,我们通过gdb观察一下进入foo函数之前main的栈帧,进入foo函数的栈帧,退出foo的栈帧情况。
Shell> gcc -g -o testtest.c
Shell> gdb --args test
Gdb >
break main
Gdb > run
进入foo函数之前:
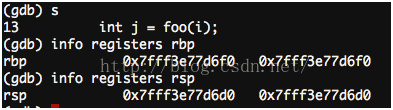
你会发现rbp-rsp=0×20,这个是由代码第11行造成的。
进入foo函数的栈帧:

回到main函数的栈帧,rbp和rsp恢复成进入foo之前的状态,就好像什么都没发生一样。

可有可无的帧指针
你刚刚搞清楚帧指针,是不是很期待要马上派上用场,这样你可能要大失所望,因为大部分的程序,都加了优化编译选项:-O2,这几乎是普遍的选择。在这种优化级别,甚至更低的优化级别-O1,都已经去除了帧指针,也就是%ebp中再也不是保存帧指针,而且另作他途。
在x86-32时代,当前栈帧总是从保存%ebp开始,空间由运行时决定,通过不断push和pop改变当前栈帧空间;x86-64开始,GCC有了新的选择,优化编译选项-O1,可以让GCC不再使用栈帧指针,下面引用 gcc manual 一段话 :
-O also turns on -fomit-frame-pointer on machines
where doing so does not interfere
with debugging.
这样一来,所有空间在函数开始处就预分配好,不需要栈帧指针;通过%rsp的偏移就可以访问所有的局部变量。说了这么多,还是看看例子吧。同一个例子, 加上-O1选项:
Shell>: gcc –O1 –S –o test.s test.c

分析main函数,GCC分析发现栈帧只需要8个字节,于是进入main之后第一条指令就分配了空间(第23行):
Subq $8, %rsp
然后在返回上一栈帧之前,回收了空间(第34行):
Addq $8, %rsp
等等,为啥main函数中并没有对分配空间的引用呢?这是因为GCC考虑到栈帧对齐需求,故意做出的安排。再来看foo函数,这里你可以看到%rsp是如何引用栈空间的。等等,不是需要先预分配空间吗?这里为啥没有预分配,直接引用栈顶之外的地址?这就要涉及x86-64引入的牛逼特性了。
访问栈顶之外
通过readelf查看可执行程序的header信息:

红色区域部分指出了x86-64遵循ABI规则的版本,它定义了一些规范,遵循ABI的具体实现应该满足这些规范,其中,他就规定了程序可以使用栈顶之外128字节的地址。
这说起来很简单,具体实现可有大学问,这超出了本文的范围,具体大家参考虚拟存储器。别的不提,接着上例,我们发现GCC利用了这个特性,干脆就不给foo函数分配栈帧空间了,而是直接使用栈帧之外的空间。@恨少说这就相当于内联函数呗,我要说:这就是编译优化的力量。
寄存器保存惯例
过程调用中,调用者栈帧需要寄存器暂存数据,被调用者栈帧也需要寄存器暂存数据。如果调用者使用了%rbx,那被调用者就需要在使用之前把%rbx保存起来,然后在返回调用者栈帧之前,恢复%rbx。遵循该使用规则的寄存器就是被调用者保存寄存器,对于调用者来说,%rbx就是非易失的。
反过来,调用者使用%r10存储局部变量,为了能在子函数调用后还能使用%r10,调用者把%r10先保存起来,然后在子函数返回之后,再恢复%r10。遵循该使用规则的寄存器就是调用者保存寄存器,对于调用者来说,%r10就是易失的,举个例子:
#include
<stdio.h>
#include
<stdlib.h>
void sfact_helper (
long int x,
long int * resultp)
{
if (x<=1)
*resultp = 1;
else {
long
int nresult;
sfact_helper(x-1,&nresult);
*resultp = x * nresult;
}
} /* ----- end of function foo ----- */
long
int
sfact ( long
int x )
{
long
int result;
sfact_helper(x, &result);
return result;
} /* ----- end of function sfact ----- */
int
main ( int argc,
char *argv[] )
{
int sum = sfact(10);
fprintf(stdout, "sum=%d\n", sum);
return EXIT_SUCCESS;
} /* ---------- end of function main ---------- */
命令行中调用gcc,生成汇编语言:
Shell>: gcc –O1 –S –o test2.s test2.c
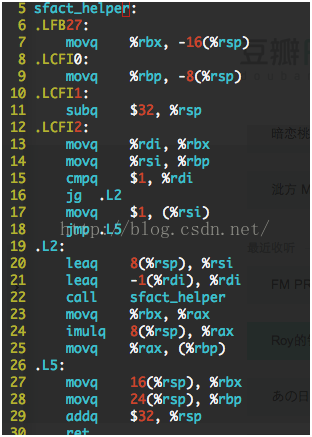
在函数sfact_helper中,用到了寄存器%rbx和%rbp,在覆盖之前,GCC选择了先保存他们的值,代码6~9说明该行为。在函数返回之前,GCC依次恢复了他们,就如代码27-28展示的那样。
看这段代码你可能会困惑?为什么%rbx在函数进入的时候,指向的是-16(%rsp),而在退出的时候,变成了32(%rsp)
。上文不是介绍过一个重要的特性吗?访问栈帧之外的空间,这是GCC不用先分配空间再使用;而是先使用栈空间,然后在适当的时机分配。第11行代码展示了空间分配,之后栈指针发生变化,所以同一个地址的引用偏移也相应做出调整。
X86时代,参数传递是通过入栈实现的,相对CPU来说,存储器访问太慢;这样函数调用的效率就不高,在x86-64时代,寄存器数量多了,GCC就可以利用多达6个寄存器来存储参数,多于6个的参数,依然还是通过入栈实现。了解这些对我们写代码很有帮助,起码有两点启示:
- 尽量使用6个以下的参数列表,不要让GCC为难啊。
- 传递大对象,尽量使用指针或者引用,鉴于寄存器只有64位,而且只能存储整形数值,寄存器存不下大对象
让我们具体看看参数是如何传递的:
#include
<stdio.h>
#include
<stdlib.h>
int foo (
int arg1, int arg2,
int arg3, int arg4,
int arg5, int arg6,
int arg7 )
{
int array[] = {100,200,300,400,500,600,700};
int sum = array[arg1]+ array[arg7];
return sum;
} /* ----- end of function foo ----- */
int
main ( int argc,
char *argv[] )
{
int i =
1;
int j = foo(0,1,2,
3, 4,
5,6);
fprintf(stdout, "i=%d,j=%d\n", i, j);
return EXIT_SUCCESS;
} /* ---------- end of function main ---------- */
命令行中调用gcc,生成汇编语言:
Shell>: gcc –O1 –S –o test1.s test1.c
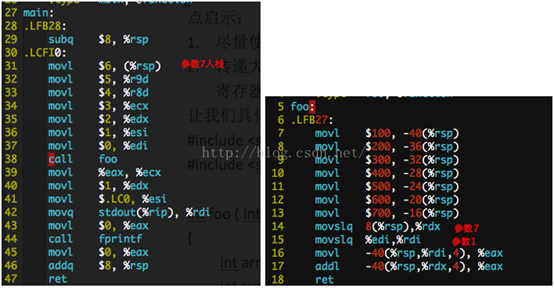
Main函数中,代码31~37准备函数foo的参数,从参数7开始,存储在栈上,%rsp指向的位置;参数6存储在寄存器%r9d;参数5存储在寄存器%r8d;参数4对应于%ecx;参数3对应于%edx;参数2对应于%esi;参数1对应于%edi。
Foo函数中,代码14-15,分别取出参数7和参数1,参与运算。这里数组引用,用到了最经典的寻址方式,-40(%rsp,%rdi,4)=%rsp
+ %rdi *4 + (-40);其中%rsp用作数组基地址;%rdi用作了数组的下标;数字4表示sizeof(int)=4。
结构体传参
应@桂南要求,再加一节,相信大家也很想知道结构体是如何存储,如何引用的,如果作为参数,会如何传递,如果作为返回值,又会如何返回。
看下面的例子:
#include
<stdio.h>
#include
<stdlib.h>
struct demo_s {
char var8;
int var32;
long var64;
};
struct demo_s foo (struct demo_s d)
{
d.var8=8;
d.var32=32;
d.var64=64;
return d;
} /* ----- end of function foo ----- */
int
main ( int argc,
char *argv[] )
{
struct demo_s d, result;
result = foo (d);
fprintf(stdout, "demo: %d, %d, %ld\n", result.var8,result.var32, result.var64);
return EXIT_SUCCESS;
} /* ---------- end of function main ---------- */
我们缺省编译选项,加了优化编译的选项可以留给大家思考。
Shell>gcc -S -o test.s test.c

上面的代码加了一些注释,方便大家理解,
问题1:结构体如何传递?它被分成了两个部分,var8和var32合并成8个字节的大小,放在寄存器%rdi中,var64放在寄存器的%rsi中。也就是结构体分解了。
问题2:结构体如何存储? 注意看foo函数的第15~17行注意到,结构体的引用变成了一个偏移量访问。这和数组很像,只不过他的元素大小可变。
问题3:结构体如何返回,原本%rax充当了返回值的角色,现在添加了返回值2:%rdx。同样,GCC用两个寄存器来表示结构体。
恩, 即使在缺省情况下,GCC依然是想尽办法使用寄存器。随着结构变的越来越大,寄存器不够用了,那就只能使用栈了。
总结
了解寄存器和栈帧的关系,对于gdb调试很有帮助;过些日子,一定找个合适的例子和大家分享一下。
参考
1. 深入理解计算机体系结构
2. x86系列汇编语言程序设计
X86-64寄存器和栈帧--牛掰降解汇编函数寄存器相关操作的更多相关文章
- X86-64寄存器和栈帧
简介 通用寄存器可用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果.除此之外,它们还各自具有一些特殊功能.通用寄存器的长度取决于机器字长,汇编语言程序员必须熟悉每个寄存器的一般用途和特殊用途, ...
- IDA Pro 权威指南学习笔记(十) - 栈帧
栈帧(stack frame)是在程序的运行时栈中分配的内存块,用于特定的函数调用 如果一个函数没有执行则不需要内存,当函数被调用时就需要用到内存 1.传给函数的参数的值需要存储到函数能够找到它们的位 ...
- C函数调用过程原理及函数栈帧分析(转)
在x86的计算机系统中,内存空间中的栈主要用于保存函数的参数,返回值,返回地址,本地变量等.一切的函数调用都要将不同的数据.地址压入或者弹出栈.因此,为了更好地理解函数的调用,我们需要先来看看栈是怎么 ...
- Linux内核调试方法总结之栈帧
栈帧 栈帧和指针可以说是C语言的精髓.栈帧是一种特殊的数据结构,在C语言函数调用时,栈帧用来保存当前函数的父一级函数的栈底指针,当前函数的局部变量以及被调用函数返回后下一条汇编指令的地址.如下图所示: ...
- Linux - 函数的栈帧
栈帧(stack frame),机器用栈来传递过程参数,存储返回信息,保存寄存器用于以后恢复,以及本地存储.为单个过程(函数调用)分配的那部分栈称为栈帧.栈帧其实是两个指针寄存器, 寄存器%ebp为帧 ...
- C语言的函数调用过程(栈帧的创建与销毁)
从汇编的角度解析函数调用过程 看看下面这个简单函数的调用过程: int Add(int x,int y) { ; sum = x + y; return sum; } int main () { ; ...
- c函数调用过程原理及函数栈帧分析
转载自地址:http://blog.csdn.net/zsy2020314/article/details/9429707 今天突然想分析一下函数在相互调用过程中栈帧的变化,还是想尽量以比 ...
- HotSpot的执行引擎-CallStub栈帧
之前多次提到接触到调用JavaCalls::call()方法来执行Java方法,如: (1)Java主类装载时,调用JavaCalls::call()方法执行的Java方法checkAndLoadMa ...
- 第5篇-调用Java方法后弹出栈帧及处理返回结果
在前一篇 第4篇-JVM终于开始调用Java主类的main()方法啦 介绍了通过callq调用entry point,不过我们并没有看完generate_call_stub()函数的实现.接下来在ge ...
随机推荐
- SuperMap-iServer过滤请求返回值
目的: iServer发布的arcgis地图服务中,由于tileinfo参数为null,导致用arcgis-ios客户端开发的APP闪退.通过过滤器将get请求的返回值修改 代码: package c ...
- Python-Django Win7上使用Apache24和mod_wsgi部署Django1.11应用程序
Win7上使用Apache24和mod_wsgi部署Django1.11应用程序 by:授客 QQ:1033553122 测试环境 win7 64 Django-1.11.4.tar.gz 下载地址: ...
- java POI导出Excel文件数据库的数据
在web开发中,有一个经典的功能,就是数据的导入导出.特别是数据的导出,在生产管理或者财务系统中用的非常普遍,因为这些系统经常要做一些报表打印的工作.这里我简单实现导出Excel文件. POI jar ...
- C# 枚举转列表
using System; using System.Collections.Generic; using System.ComponentModel; namespace Common.Utils ...
- Linux的notifier机制的应用
在linux内核系统中,各个模块.子系统之间是相互独立的.Linux内核可以通过通知链机制来获取由其它模块或子系统产生的它感兴趣的某些事件. notifier_block结构体在include/lin ...
- Windows Server 2016-Active Directory复制概念(一)
停更十余天后,从今天开始继续为大家带来Windows Server 2016 Active Directory系列更新,本章为大家介绍有关Active Directory复制相关概念内容,有关Acti ...
- IOC注解开发与XML整合
区别: xml:可以适用于任何场景,结构清晰,方便维护 注解:开发方便,快速.有些地方适用不了,这个类不是自己提供的(比如源码提供的类) xml和注解整合开发,各取所长 xml使用于对bean进行管理 ...
- Nginx 的 TCP 负载均衡介绍
Nginx除了以前常用的HTTP负载均衡外,Nginx增加基于TCP协议实现的负载均衡方法. HTTP负载均衡,也就是我们通常所有“七层负载均衡”,工作在第七层“应用层”.而TCP负载均衡,就是我们通 ...
- Eclipse的各种查找,类的查找,方法查找快捷键
eclipse开发中,查找会是一个经常用到的功能所以总结一下1,查找一个类 Shift + Ctrl + h 这种方式能快速的定位接口,类还有注解在那个包里面2.综合查找 Ctrl + H 这是一种综 ...
- IE和其他浏览器内核
1.qq急速 2.qq的IE兼容模式 3.Edge 4.IE11 5.chrome js获取浏览器内核 <script language="JavaScript" type= ...