object detection[content]
近些年,随着DL的不断兴起,计算机视觉中的对象检测领域也随着CNN的广泛使用而大放异彩,其中Girshick等人的《R-CNN》是第一篇基于CNN进行对象检测的文献。本文欲通过自己的理解来记录这几大模型的发展。(自己挖坑,自己待填)
0. overfeat
0.1. MultiBox
1. R-CNN
R-CNN是第一篇将CNN用在目标检测领域中的,是开山之作,不过其中的原理结构也较为简单,如下图:

图1.1 R-CNN结构
步骤
- 通过selective search方法在一张图片上获取很多的候选区域框(在真实目标上框出了大致粗糙的结果框,可是有三个问题:1 - 多;2-一些框置信度不够;3 - 框的边界不够精细);
- 用CNN对每个框提取特征;
- 用SVM做对象分类;
- 用回归器修正候选框位置。
特点:作者基于之前dl在图像分类上的准确度,想通过cnn提取图片的特征来实现特征提取这步操作
2. SPPnet
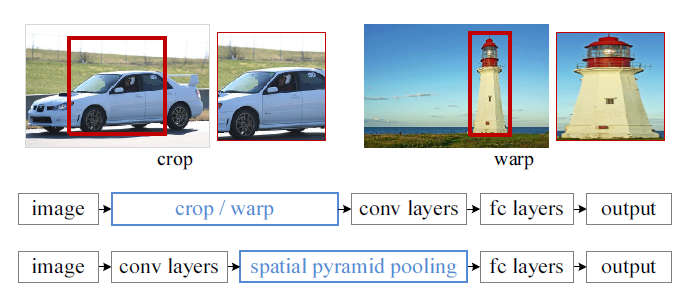
图2.1 传统CNN和SPP
如上图所示,因为常用的CNN网络都需要事先crop和warp,这样造成的问题就是要么图像内目标没包含完整、要么就是图像必须一定的拉伸导致几何失真。
所以作者在最后一层卷积层和全连接层之间加了一个SPP池化。因为传统的CNN是需要全连接层的,对于前面的卷积层来说,图片输入多大,对应的输出也会有对应变化,可是仍然能够很好的处理。而全连接层却需要固定维度的输入;所以传统的CNN可以将前面的卷积层看成是特征提取器,然后将提取到的特征通过传统的神经网络(也就是全连接层)做分类预测。
具体的SPP操作如下图:
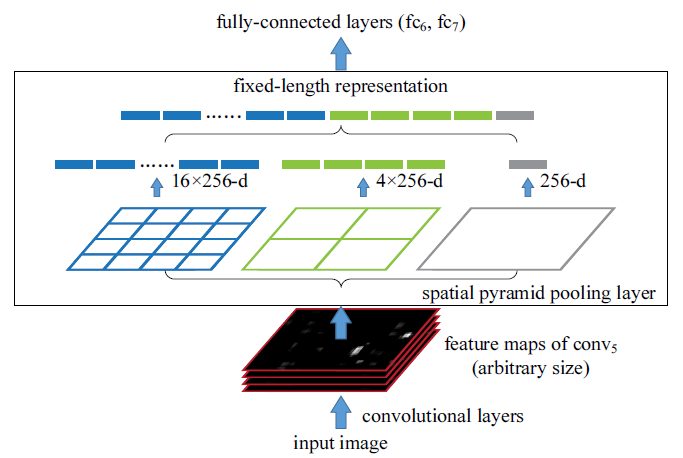
图2.2 SPP操作
如上图所示,在最后一层卷积层和第一层全连接层之间加一层空间金字塔池化层。上图中256表示之前特征图的通道数(也就是之前的特征图是一个M*N*D的张量,而每个特征图size为M*N,一共D个通道)。这里采取了3种不同的池化方式,第一个是固定每个特征图输出一个16维的向量;第二个固定输出一个4维的向量;第三个是个全局池化,即每个特征图固定输出一个值。
步骤如下
- 照常输入图片;
- 在最后一层卷积层的输出部分获取当前特征图的size;
- 通过对全连接层的输入的维度固定,反推当前的SPP层每个特征图上需要的池化窗口大小和滑动步长大小;
- 对当前特征图进行SPP池化
3. fast R-CNN
特点: 引入了ROI池化:所谓ROI就是基于当前图片中感兴趣区域,是CV中的常见术语,而池化是DL常见术语。ROI池化就是基于当前特征图的感兴趣区域(选定的部分区域)进行池化操作。
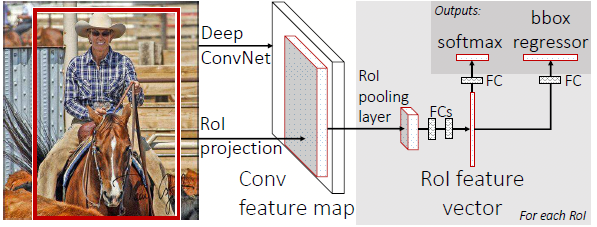
图3.1 fast-rcnn网络结构图
- 因为RCNN是分阶段处理的,所以训练还是测试都是比较繁琐的;
所以,在fast RCNN中,除了最开始的对象候选框还是采用了SS的方法,后续的都是基于cnn的方式,从而能够实现end-to-end。- rcnn相对来说,慢是因为每个候选框上都需要过一次cnn;
所以,fast rcnn就想,能不能在一个图片上过一次,然后在后面的feature map上直接提取每个候选框对应的区域(即一个ROI区域对应一个由SS方法提到的候选框);- 可是得到的每个ROI都是不固定的size,如何能统一成一致的大小,从而完成后续的层训练;
所以,提出了ROI-pooling的方法,从SPP-net得到的灵感,直接将每个得到的ROI区域划分成固定size的网格,每个格子中进行max-pooling,从而输出统一的数据向量- 那么这时候怎么反向BP这些不同size的ROI呢;
所以,我们以ROI-pooling层作为分界线,后面是正常的基于整个图片提取特征的过程;到了ROI-pooling层,向前分隔成2个并列的全连接层;a)用来做当前ROI的分类,是一个softmax层结果;b)用来对当前ROI进行坐标精确微调,是一个基于全连接层的作者自定义的目标函数;
而从后往前当残差传到ROI层的时候,将当前残差对应回完整的那个feature map,其中如果某个神经元参与了不同的ROI区域,那么该神经元的残差是接收其涉及的ROI残差的和,如下图所示:
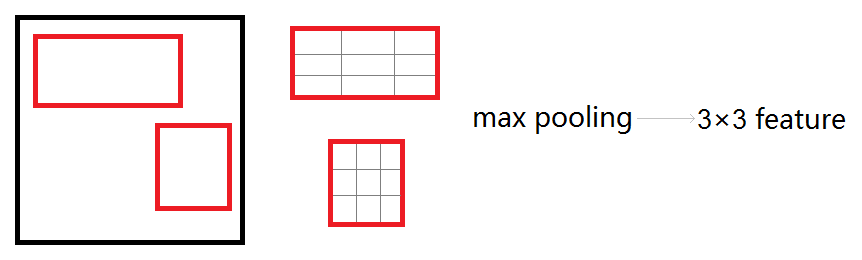
图3.2 ROI池化层前向传播,该图来自这里

图3.3 ROI池化层后向传播,该图来自这里
在图3.3中,先将不同的ROI映射回原来完整的feature map,然后重叠区域的残差是2个ROI传到这里的残差之和,其中绿点是因为采用的max-pooling,然后恰好这两个ROI池化时候网格的块中结果都是这个神经元。
几个有干货,而不是简单的翻译的博客:博客1;博客2
4. faster R-CNN
从上面几个网络的发展来看,有种顺风顺水的感觉,就是当前暴露了哪个问题,那么就解决那个问题,接下来暴露下一个问题,那么就接着解决暴露的问题。通过fast-rcnn之后,发现下一个要解决的问题就是SS方法提取的太耗时了,所以faster RCNN就着重解决区域提取方法,即让cnn网络自己提出所谓的图片ROI区域。这里叫做区域候选网络(region proposal network,RPN)。
而且faster rcnn,个人人为是目标检测的一个高潮,因为后续的ssd,yolo,rfcn都是基于这个网络进行对比的,而faster rcnn的准确度是最高的,所以后续的几个网络都是在其他方面有所优势,比如照顾小目标,比如实时性等等。
看这里,faster rcnn
5. YOLO
这里我们来说YOLO架构:
yolo相较于之前几个模型就比较暴力,直接将最后的feature map硬编码成7*7的网格,每个神经元就是一个如faster rcnn中RPN的划框,先验的将faster rcnn的RPN的工作硬编码到网络中。假设每个神经元就是原图中对象的中心,通过直接对目标函数进行改进,很好的将原来RPN的工作和fast rcnn的工作融合到目标函数中去了,这样做的好处是快,在预测的时候也不需要经过RPN去先得到所谓的对象候选框,直接一次过整个网络就行了;当然,也存在最后目标预测准确度下降的问题,因为从模型的设计上就可以看出,如果每个神经元只预测一个对象,那么就存在丢失目标的可能,而且作者通过实验也发现,对小目标的识别不如faster rcnn。
6. SSD
7. RFCN
8. FPN
9. PVANET
参考文献:
- [overfeat] Sermanet P, Eigen D, Zhang X, et al. Overfeat: Integrated recognition, localization and detection using convolutional networks[J]. arXiv preprint arXiv:1312.6229, 2013.
- [r-cnn] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587,2014
- [spp] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//European Conference on Computer Vision. Springer, Cham, 2014: 346-361.
- [fast r-cnn] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
- [faster r-cnn] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
- [yolo] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. arXiv preprint arXiv:1506.02640, 2015
- [yolo 9000] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. arXiv preprint arXiv:1612.08242, 2016
- [ssd] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
- [fpn] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[J]. arXiv preprint arXiv:1612.03144, 2016.
- [rfcn] Dai J, Li Y, He K, et al. R-fcn: Object detection via region-based fully convolutional networks[C]//Advances in neural information processing systems. 2016: 379-387.
- [模型比较] Huang J, Rathod V, Sun C, et al. Speed/accuracy trade-offs for modern convolutional object detectors[J]. arXiv preprint arXiv:1611.10012, 2016.
- [pvanet] Kim K H, Hong S, Roh B, et al. PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection[J]. arXiv preprint arXiv:1608.08021, 2016.
- [multibox] Erhan D, Szegedy C, Toshev A, et al. Scalable object detection using deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 2147-2154.
- [SqueezeDet] Wu B, Iandola F, Jin P H, et al. SqueezeDet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving[J]. arXiv preprint arXiv:1612.01051, 2016.
object detection[content]的更多相关文章
- 关于目标检测 Object detection
NO1.目标检测 (分类+定位) 目标检测(Object Detection)是图像分类的延伸,除了分类任务,还要给定多个检测目标的坐标位置. NO2.目标检测的发展 R-CNN是最早基于C ...
- 关于目标检测(Object Detection)的文献整理
本文对CV中目标检测子方向的研究,整理了如下的相关笔记(持续更新中): 1. Cascade R-CNN: Delving into High Quality Object Detection 年份: ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- 论文阅读(Chenyi Chen——【ACCV2016】R-CNN for Small Object Detection)
Chenyi Chen--[ACCV2016]R-CNN for Small Object Detection 目录 作者和相关链接 方法概括 创新点和贡献 方法细节 实验结果 总结与收获点 参考文献 ...
- deep learning on object detection
回归工作一周,忙的头晕,看了两三篇文章,主要在写各种文档和走各种办事流程了-- 这次来写写object detection最近看的三篇文章吧.都不是最近的文章,但是是今年的文章,我也想借此让自己赶快熟 ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- object detection技术演进:RCNN、Fast RCNN、Faster RCNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- TensorFlow Object Detection API(Windows下测试)
"Speed/accuracy trade-offs for modern convolutional object detectors." Huang J, Rathod V, ...
随机推荐
- 「Android」系统架构概述
目录: 1.Android系统架构 2.Android类库 3.四大组件 --------------------------------------------------------------- ...
- Android 7.0 fiddler代理抓不到https请求的解决办法
解决方法: 1.在源码res目录下新建xml目录,增加network_security_config.xml文件 (工程名/app/src/main/res/xml/network_security ...
- powersploit的用法
一.PowerSploit简介 PowerSploit是GitHub上面的一个安全项目,上面有很多powershell攻击脚本,它们主要被用来渗透中的信息侦察.权限提升.权限维持. Powershel ...
- Microsoft .NET Framework 3.5 离线安装方法 (仅适用于Win8以上的系统)
所需工具:本系统对应原版镜像或Win8以上操作系统原版ISO镜像 操作: 1.利用Windows资源管理器挂载 ISO 镜像,或其他虚拟光驱工具挂载镜像,记住挂载的盘符 2.打开Windows命令提示 ...
- JavaScript -- 时光流逝(六):js中的正则表达式 -- RegExp 对象
JavaScript -- 知识点回顾篇(六):js中的正则表达式 -- RegExp 对象 1. js正则表达式匹配字符之含义 查找以八进制数 规定的字符. 查找以十六进制数 规定 ...
- LeetCode算法题-Lowest Common Ancestor of a Binary Search Tree
这是悦乐书的第197次更新,第203篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第59题(顺位题号是235).给定二叉搜索树(BST),找到BST中两个给定节点的最低共 ...
- ArcMap2Sld:一个将MXD中图层配图样式转换为OGC的SLD文件的开源工具
在一个项目中,用户采用GeoServer做为GIS服务器(原因嘛当然是免费能省钱,经过验证可能还会在性能和稳定性等表现力也有优越性),但是手上收集的数据都是ESRI格式的,这倒不打紧,因为GeoSer ...
- JavaScript数组对象详情
Array 数组概述 Array 类型是 ECMAScript 最常用的类型.javaScript 中的 Array 类型和其他语言中的数组有着很大的区别. 虽然数组都是有序排列,但 javaScri ...
- dp P1103 书本整理 洛谷
题目描述 Frank是一个非常喜爱整洁的人.他有一大堆书和一个书架,想要把书放在书架上.书架可以放下所有的书,所以Frank首先将书按高度顺序排列在书架上.但是Frank发现,由于很多书的宽度不同,所 ...
- 安装mysql5.6报错问题统计点
报错1(su进入mysql属组时报错): [root@dbserver ~]# su - mysql Last login: Thu Aug 31 17:20:03 CST 2017 on pts/1 ...