scrapy架构简介
一.scrapy架构介绍
1.结构简图:
主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine
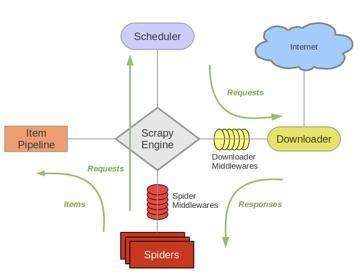
2.结构详细图:
主要步骤(往复循环):
1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——>
2.engine拿到requests返回给scheduler(什么也没做)——>
3.然后scheduler会生成一个requests交给engine(url调度器)——>
4.engine通过downloader的middleware一层一层过滤然后将requests交给downloader——>
5.downloader下载完成后又通过middleware过滤将response返回给engine——>
6.engine拿到response之后将response通过spiders的middleware过滤后返回给spider,然后spider做一些处理(如返回items或requests)——>
7.spiders将处理后得到的一些items和requests通过中间件过滤返回给engine——>
8.engine判断返回的是items或requests,如果是items就直接返回给item pipelines,如果是requests就将requests返回给scheduler(和第二步一样)

源码简介:
源码核心的东西
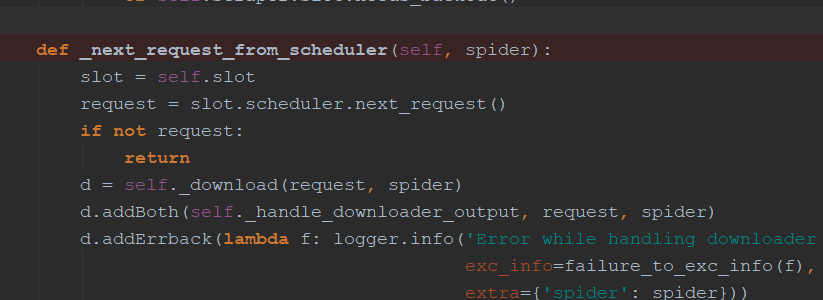
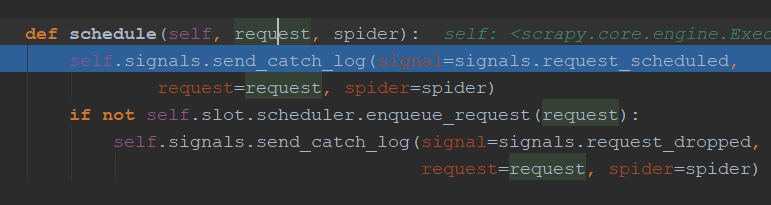
engine.py中介绍:通过_next_request_from_scheduler判断是否有requests(request返回给engine直接返回给scheduler【第一步】),request会首先调用schedule()函数发送给schedule(第二步),然后返回给engine
downloader简介:

可以处理很多类型的下载
Request和Response简介:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
......
官网介绍(具体官网网址:https://doc.scrapy.org/en/latest/topics/request-response.html):
| 参 数: |
|
|---|
class Response(object_ref):
def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None):
self.headers = Headers(headers or {})
self.status = int(status)
self._set_body(body)
self._set_url(url)
self.request = request
self.flags = [] if flags is None else list(flags)
......
| 参数: |
|
|---|
scrapy架构简介的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- LoadRunner系统架构简介
1.LoadRunner系统架构简介 LoadRunner是通过创建虚拟用户来代替真实实际用户来操作客户端软件比如Internet Explorer,来向IIS.Apache等Web服务器发送HTTP ...
- crtmpserver的架构简介
crtmpserver的架构简介 一.层 Layers . 机器层 Machine layer . 操作系统层 Operating System Layer This layer is compo ...
- Extjs6官方文档译文——应用架构简介(MVC,MVVM)
应用架构简介 Extjs 同时提供对于MVC和MVVM应用架构的支持.这两个架构方式共享某些概念,而且都旨在沿着逻辑层面划分应用程序代码.每种方法在选择如何划分应用组件上都有其各自的优势. 本指南的目 ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Scrapy架构概述
Scrapy架构概述 1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象. 2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器) ...
- Kafka:架构简介【转】
转:http://www.cnblogs.com/f1194361820/p/6026313.html Kafka 架构简介 Kafka是一个开源的.分布式的.可分区的.可复制的基于日志提交的发布订阅 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
随机推荐
- Spring Boot+Spring Security+JWT 实现 RESTful Api 权限控制
摘要:用spring-boot开发RESTful API非常的方便,在生产环境中,对发布的API增加授权保护是非常必要的.现在我们来看如何利用JWT技术为API增加授权保护,保证只有获得授权的用户才能 ...
- 屏蔽右键+f12
function disableInfo() { document.onkeydown = function() { var e = window.event || arguments[0]; //屏 ...
- Docker安装MySQL并配置远程访问
1.docker search mysql 查看mysql版本 2.docker pull mysql 要选择starts最高的那个name 进行下载 3.docker images 查看下载好的镜像 ...
- return关键字的作用和接受实验
package com.Summer_0419.cn; /** * @author Summer * 查看return关键字的作用,实验目的: * 1.传入两个实参查看输出结果 * 2.传入两个无参数 ...
- 启动项目显示:非法字符:'\ufeff' 和需要 class ,interface 或者 enum 错误
原来是因为 Windows 记事本在修改 UTF-8 文件时自作聪明地在文件开头添加 BOM 导致的,所以才会导致 IDEA 不能正确读取 .java 文件从而程序出错. 解决: 找到 xxx. ja ...
- MySql 建表出现的问题:[ERR] 1064 - You have an error in your SQL syntax; check the manual.......
使用 MySql 建表出现的问题 在使用 Navicat Premium 运行 sql 语句进行建表时,MySQL 报错如下: 建表语句: DROP DATABASE IF EXISTS javawe ...
- input表单提交完毕,返回重新填入有黄色背景,和 历史记录 清除
<input autocomplete="value"> // 添加这个属性,可以解决然后添加一个css input:-webkit-autofill {box-sha ...
- Spring Cloud 入门教程(八): 断路器指标数据监控Hystrix Dashboard 和 Turbine
1. Hystrix Dashboard (断路器:hystrix 仪表盘) Hystrix一个很重要的功能是,可以通过HystrixCommand收集相关数据指标. Hystrix Dashboa ...
- Java 多线程(六)之Java内存模型
目录 1. 并发编程的两个问题 2 CPU 缓存模型 2.1 CPU 和 主存 2.2 CPU Cache 2.3 CPU如何通过 Cache 与 主内存交互 2.4 CPU 缓存一致性问题 3 Ja ...
- CentOS 7+nginx+PHP+php-fpm
根据网上资料配置: location ~ \.php$ { #include fastcgi_params; fastcgi_pass 127.0.0.1:9000; fastcgi_index in ...