使用webmagic爬虫对百度百科进行简单的爬取
分析要爬取的网页源码:
1、打开要分析的网页,查看源代码,找到要爬取的内容:
(选择网页里的一部分右击审查元素也行)

2、导入jar包,这个就直接去网上下吧;
3、写爬虫:
package com.gb.pachong;
import java.sql.SQLException;
import com.gb.util.AddNum;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class BaikePaChong implements PageProcessor
{
private static String key;
public static String res=null;
// 抓取网站的相关配置,包括编码、重试次数、抓取间隔
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void run(String key)
{
this.key = key;
//addUrl就是种子url,Page对象就是当前获取的页面,getUrl()可以获得当前url,addTargetRequests()就是把链接放入等待爬取,getHtml()获得页面的html元素
//启动爬虫
Spider.create(new BaikePaChong()).addUrl("https://baike.baidu.com/item/" + key).thread(5).run();
}
@Override
public Site getSite()
{
return site;
}
@Override
public void process(Page page)
{
//获取页面内容
res = page.getHtml().xpath("//meta[@name='description']/@content").toString();
//把包含数据添加到数据库的方法的类实例化成对象
AddNum addNum=new AddNum();
try
{
//数据添加进数据库
addNum.store(key, res);
}
catch (SQLException e)
{
e.printStackTrace();
}
}
public void search(String string)
{
BaikePaChong baikePaChong = new BaikePaChong();
baikePaChong.run(string);
}
public String getRes()
{
return res;
}
}
4、上面只是简单的爬取,可以仿照这样的方法进行一些别样的扩展使用。
5、Xpath可以在这里直接复制:
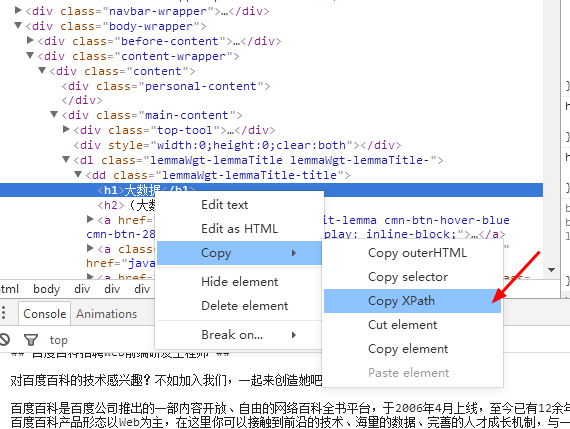
使用webmagic爬虫对百度百科进行简单的爬取的更多相关文章
- Python爬虫学习(5): 简单的爬取
学习了urllib,urlib2以及正则表达式之后就可以做一些简单的抓取以及处理工作.为了抓取方便,这里选择糗事百科的网页作为抓取对象. 1. 获取数据: In [293]: url = " ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫概念与编程学习之如何爬取视频网站页面(用HttpClient)(二)
先看,前一期博客,理清好思路. 爬虫概念与编程学习之如何爬取网页源代码(一) 不多说,直接上代码. 编写代码 运行 <!DOCTYPE html><html><head& ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
随机推荐
- 修改pudb颜色
2019-02-19,18点20vim调整颜色vim ~/.vimrc 这个pudb的配色用上的方法改不了.调试状态时候按o和回车能切换console和调试界面. 成功了.通过修改pudb源代码来实现 ...
- python3 第二十八章 - 内置函数之List相关
Python包含以下函数: 序号 函数 实例 1 list.append(obj)在列表末尾添加新的对象 2 list.count(obj)统计某个元素在列表中出现的次数 3 list.ext ...
- matplotlib 中文显示问题
matplotlib 默认显示不了中文,如果想显示中文,通过下面代码设置: import matplotlib #指定默认字体 matplotlib.rcParams['font.sans-serif ...
- sql_calc_found_rows原理
- java环境下载
https://repo.huaweicloud.com/java/jdk/8u201-b09/
- 关于Asp.net事件,如何在触发子控件的事件时,同步触发父页面的事件
对页面引用自定义控件后,通过绑定自定义事件,页面绑定子控件的事件,在子控件做了某些修改动作后,如何同步操作父页面的方法:下面我煮了个栗子,同学们可以来尝一尝试一试 a.aspx 引用 UserCont ...
- JUnit学习笔记-0-JUnit启动类
[说明]:本文基于JUnit4.13版本代码,JDK1.8.0_151环境,使用工具为Eclipse,版本为Oxygen.1a Release (4.7.1a) [图示]: [正文]:JUnit4.1 ...
- HTML5结构标签
<!DOCTYPE html> <!-- ↑ 文档声明.HTML5已经简化为上述样式! 注意:文档声明必须有!而且必须在文档页面的第一行! HTML4.01之前的文档声明: &l ...
- Vue route部分简单高级用法
一改变页面title的值 在开发时常常需要在切换到不同页面时改变浏览器的title值,那么我们就可以在定义路由的时候通过配置 meta 属性 来改变title值. import Vue from ...
- NGUI_创建图集Altas
在project面板下创建一个名为Textures的folder,把事先准备好的贴图素材直接拖到Textures下 2.导航栏NGUI处打开atlas 3.project下新建一个atlas的文件夹, ...