HanLP汉语言分析框架
HanLP(Han Language Processing)是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。
HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
环境搭建
1.创建java项目,导入HanLP必要的包

2.把对应的配置文件放置在src下
3.修改hanlp.properties配置文件,使其指向data(data中包含词典和模型)的上级路径,修改如下,
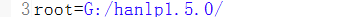
代码运行
1.第一个Demo
- System.out.println(HanLP.segment("你好,欢迎使用HanLP汉语处理包!"));
- //标准分词
- List<Term> standardList = StandardTokenizer.segment("商品和服务");
- System.out.println(standardList);
结果:

注意:HanLP.segment其实是对StandardTokenizer.segment的包装。
2.索引分词
- List<Term> indexList = IndexTokenizer.segment("主副食品");
- for (Term term : indexList)
- {
- System.out.println(term + " [" + term.offset + ":" + (term.offset + term.word.length()) + "]");
- }
结果:

注意:索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
3.自然语言分词
- List<Term> nlpList = NLPTokenizer.segment("中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程");
- System.out.println(nlpList);
结果:

注意:自然语言分词NLPTokenizer会执行全部命名实体识别和词性标注。
4.最短路径分词&N-最短路径分词
- String[] testCase = new String[]{
- "今天,刘志军案的关键人物,山西女商人丁书苗在市二中院出庭受审。",
- "刘喜杰石国祥会见吴亚琴先进事迹报告团成员",
- };
- //N-最短路径分词
- Segment nShortSegment = new NShortSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true);
- for (String sentence : testCase)
- {
- System.out.println("N-最短分词:" + nShortSegment.seg(sentence));
- }
- //最短路径分词
- Segment shortestSegment = new DijkstraSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true);
- for (String sentence : testCase)
- {
- System.out.println("最短路分词:" + shortestSegment.seg(sentence));
- }
结果:

注意:
N最短路分词器
NShortSegment比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强。一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。
5.CRF(条件随机场算法)分词
- Segment segment = new CRFSegment();
- segment.enablePartOfSpeechTagging(true);
- List<Term> crfList = segment.seg("你看过环太平洋吗");
- System.out.println(crfList);
- for (Term term : crfList)
- {
- if (term.nature == null)
- {
- System.out.println("识别到新词:" + term.word);
- }
- }
结果:

注意:CRF对新词有很好的识别能力,但是无法利用自定义词典。
6.用户自定义词典
- // 动态增加
- CustomDictionary.add("攻城狮");
- // 强行插入
- CustomDictionary.insert("白富美", "nz 1024");
- // 删除词语(注释掉试试)
- //CustomDictionary.remove("攻城狮");
- System.out.println(CustomDictionary.add("单身狗", "nz 1024 n 1"));
- System.out.println("单身狗 : " + CustomDictionary.get("单身狗"));
- String text2 = "攻城狮逆袭单身狗,迎娶白富美,走上人生巅峰";
- String text23 = "王重阳和步惊云一起讨论盖聂的百步飞剑的诀窍! ";
- // AhoCorasickDoubleArrayTrie自动机分词
- final char[] charArray = text23.toCharArray();
- CustomDictionary.parseText(charArray, new AhoCorasickDoubleArrayTrie.IHit<CoreDictionary.Attribute>()
- {
- @Override
- public void hit(int begin, int end, CoreDictionary.Attribute value)
- {
- System.out.printf("[%d:%d]=%s %s\n", begin, end, new String(charArray, begin, end - begin), value);
- }
- });
结果:

注意:
CustomDictionary是一份全局的用户自定义词典,可以随时增删,影响全部分词器。另外可以在任何分词器中关闭它。通过代码动态增删不会保存到词典文件。
7.中国人名识别
- String[] testCase2 = new String[]{
- "签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。",
- "张浩和胡健康复员回家了",
- "编剧邵钧林和稽道青说",
- "这里有关天培的有关事迹",
- "龚学平等领导,邓颖超生前",
- };
- Segment segment2 = HanLP.newSegment().enableNameRecognize(true);
- for (String sentence : testCase2)
- {
- List<Term> termList = segment2.seg(sentence);
- System.out.println(termList);
- }
结果:

注意:目前分词器基本上都默认开启了中国人名识别,比如HanLP.segment()接口中使用的分词器等等,用户不必手动开启;
8.关键字提取
- String content = "程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。";
- List<String> keywordList = HanLP.extractKeyword(content, 5);
- System.out.println(keywordList);
结果:
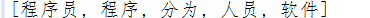
注意:其内部采用TextRankKeyword(类谷歌的PageRank)实现,用户可以直接调用TextRankKeyword.getKeywordList(document, size)。
9.简繁转换
- System.out.println(HanLP.convertToTraditionalChinese("用笔记本电脑写程序"));
- System.out.println(HanLP.convertToSimplifiedChinese("「以後等妳當上皇后,就能買士多啤梨慶祝了」"));
结果:

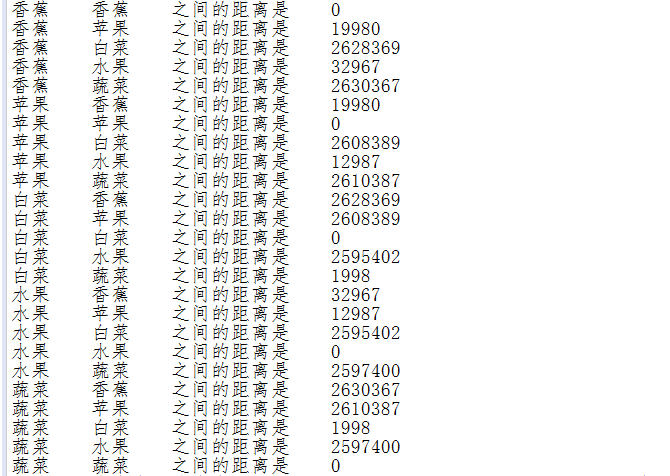
10.语义距离
String[] wordArray2 = new String[]
{
"香蕉","苹果","白菜","水果","蔬菜"
};
for (String a : wordArray2){
for (String b : wordArray2)
{
System.out.println(a + "\t" + b + "\t之间的距离是\t" + CoreSynonymDictionary.distance(a, b));
}
}
结果:
注意:
说明
设想的应用场景是搜索引擎对词义的理解,词与词并不只存在“同义词”与“非同义词”的关系,就算是同义词,它们之间的意义也是有微妙的差别的。
算法
为每个词分配一个语义ID,词与词的距离通过语义ID的差得到。语义ID通过《同义词词林扩展版》计算而来。
HanLP汉语言分析框架的更多相关文章
- 符号执行-基于python的二进制分析框架angr
转载:All Right 符号执行概述 在学习这个框架之前首先要知道符号执行.符号执行技术使用符号值代替数字值执行程序,得到的变量的值是由输入变 量的符号值和常量组成的表达式.符号执行技术首先由Kin ...
- OSNIT信息收集分析框架OSRFramework
OSNIT信息收集分析框架OSRFramework OSNIT是一种从公开的信息资源搜集信息的有效方式.Kali Linux集成了一款专用分析工具集OSRFramework.该工具集包含多个常用工具 ...
- 开源网络抓包与分析框架学习-Packetbeat篇
开源简介packbeat是一个开源的实时网络抓包与分析框架,内置了很多常见的协议捕获及解析,如HTTP.MySQL.Redis等.在实际使用中,通常和Elasticsearch以及kibana联合使用 ...
- cube.js 开源模块化分析框架
cube.js 是一款很不错的模块化web 应用分析框架.cube.js 的设计主要是面向serverless 服务, 但是同时也支持所有rdbms, cube.js不是一个单体应用,包含了以下部分: ...
- Dubbo学习系列之十六(ELK海量日志分析框架)
外卖公司如何匹配骑手和订单?淘宝如何进行商品推荐?或者读者兴趣匹配?还有海量数据存储搜索.实时日志分析.应用程序监控等场景,Elasticsearch或许可以提供一些思路,作为业界最具影响力的海量搜索 ...
- Dshell----开源攻击分析框架
前言 随着互联网的高速发展,网络安全问题变得至关重要,随着网络的不断规模化和复杂化,网络中拒绝服务(Denial of Service,DoS)攻击和分布式拒绝服务(Distributed Denia ...
- 音频分析框架pyAudioAnalysis文档
“ pyAudioAnalysis是一个非常好用且强大的音频分析开源工具,能实现音频的特征提取.分类和回归模型的训练和执行,以及其他一些实用的功能.此外,本文档并非直译,也有部分比较简略,可以结合源码 ...
- druid.io 海量实时OLAP数据仓库 (翻译+总结) (1)——分析框架如hive或者redshift(MPPDB)、ES等
介绍 我是NDPmedia公司的大数据OLAP的资深高级工程师, 专注于OLAP领域, 现将一个成熟的可靠的高性能的海量实时OLAP数据仓库介绍给大家: druid.io NDPmedia在2014年 ...
- nginx源代码分析--框架设计 & master-worker进程模型
Nginx的框架设计-进程模型 在这之前,我们首先澄清几点事实: nginx作为一个高性能server的特点.事实上这也是全部的高性能server的特点,依赖epoll系统调用的高效(高效是相对sel ...
随机推荐
- 图片base64上传时可能遇到的问题
base64上传图片时服务器接到的值可能会丢失字符串 解决方法如下:(分为单个上传和多个上传) <?php $BASE_DIR = "../"; //文件上传 $img = ...
- Java的运行原理(转载)
在Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器.这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口.编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由 ...
- Java 容器 & 泛型:四、Colletions.sort 和 Arrays.sort 的算法
Writer:BYSocket(泥沙砖瓦浆木匠) 微博:BYSocket 豆瓣:BYSocket 本来准备讲 Map集合 ,还是喜欢学到哪里总结吧.最近面试期准备准备,我是一员,成功被阿里在线笔试秒杀 ...
- eclipse制作exe文件
1.右击你的项目,选择Export: 2.选择Java目录下的JAR file: 3.设置导出jar文件的路径,我这里选择的是桌面,点击Next: 4.这一步默认,不用改动,直接Next: 5.设置项 ...
- shiro + jwt 实现 请求头中的 rememberMe 时间限制功能
前言: 上一篇提出, 通过修改 rememberMe 的编码来实现 rememberMe的功能的设想, 事后我去尝试实现了一番, 发现太麻烦, 还是不要那么做吧. 程序还是要越简单越好. 那功能总是要 ...
- [转]Memcache的使用和协议分析详解
Memcache是什么 Memcache是danga.com的一个项目,最早是为 LiveJournal 服务的,目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力. 它可以应 ...
- 使用字面量,比new更加有效
参考原文:http://www.cnblogs.com/yxf2011/archive/2012/04/01/2428225.html http://www.cnblogs.com/mushishi/ ...
- 各个模式的accesstoken续期详解
一些预备知识 jwt的时间格式 转换为时间可以用js, new Date(1531841745*1000) ==>Tue Jul 17 2018 23:35:45 GMT+0800 (中国标准时 ...
- JavaScript 图片弹框显示
function fnCreate(src) { /* 要创建的div的classname */ var ClassName = "thumb ...
- 从零开始学安全(十九)●PHP数组函数
$temp= array(1,2,3,,,,) 创建一个数组赋值给temp $id=range(1,6,2); 成长值 1到6 跨度为2 就是3个长度数组 也可以是字符“a” &quo ...