Spark MLlib 机器学习
本章导读
机器学习(machine learning, ML)是一门涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域的交叉学科。ML专注于研究计算机模拟或实现人类的学习行为,以获取新知识、新技能,并重组已学习的知识结构使之不断改善自身。
MLlib是Spark提供的可扩展的机器学习库。MLlib已经集成了大量机器学习的算法,由于MLlib涉及的算法众多,笔者只对部分算法进行了分析,其余算法只是简单列出公式,读者如果想要对公式进行推理,需要自己寻找有关概率论、数理统计、数理分析等方面的专门著作。本章更侧重于机器学习API的使用,基本能够满足大多数读者的需要。
1. 机器学习概率
机器学习也属于人工智能的范畴,该领域主要研究的对象是人工智能,尤其是如何在经验学习中改善具体算法。机器学习是人工智能研究较为年轻的分支,它的发展过程大致可分为如下4个阶段:
- 第一阶段:20世纪50年代中叶至60年代中叶,属于热烈时期。
- 第二阶段:20世纪60年代中叶至70年代中叶,称为冷静时期。
- 第三阶段:20世纪70年代中叶至80年代中叶,称为复兴时期。
- 第四阶段:从1986年开始至今。
(1) 机器学习的组成
机器学习的基本结构由环境、知识库和执行部分三部分组成。环境向学习部分(属于知识库的一部分)提供某些信息,学习部分利用这些信息修改知识库,以增进执行部分完成任务的效能,执行部分根据知识库完成任务,同时把获得的信息反馈给学习部分。
(2) 学习策略
学习策略是指机器学习过程中所采用的推理策略。学习系统一般由学习和环境两部分组成。环境(如书本或教师)提供信息,学习部分则实现信息转换、存储,并从中获取有用的信息。学习过程中,学生(学习部分)使用的推理越少,他对教师(环境)的依赖就越大,教师的负担也就越重。根据学生实现信息转换所需推理的多少和难易程度,以从简单到复杂,从少到多的次序可以将学习策略分为以下6种基本类型:
- 机械学习(rote learning):学习者不需要任何推理或转换,直接获取环境所提供的信息。属于此类的如塞缪尔的跳棋程序。
- 示教学习(learning from instruction):学习者从环境获取信息,把知识转换成内部可使用的表示形式,并将新知识和原有知识有机地合为一体。此种学习策略需要学生有一定程度的推理能力,但环境仍要做大量的工作。典型应用是FOO程序。
- 演绎学习(learning by deduction):学习者通过推理获取有用的知识。典型应用是宏操作(macro-operation)学习。
- 类比学习(learning by analogy):学习者根据两个不同领域(源域、目标域)中的知识相似性,通过类比,从源域的知识推导出目标域的相应知识。此类应用如卢瑟福类比。
- 基于解释的学习(explanation-based learning, EBL):学习者根据教师提供的目标概念和此概念的例子、领域理论及可操作准则,首先给出解释说明为什么该例子满足目标概念,然后将解释推广未目标概念的一个满足可操作准则的充分条件。著名的EBL系统由迪乔恩(G.DeJong)的GENESIS等。
- 归纳学习(learning from induction):由环境提供某概念的一些实例或反例,让学习者通过归纳推理得出该概念的一般描述。归纳学习是最基本的,发展也较为成熟的学习方法,在人工智能领域中已得到广泛的研究和应用。
学习策略还可以从所获取知识的表示形式、应用领域等维度分类。
(3) 应用领域
目前,机器学习广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。
2. Spark MLlib总体设计
MLlib(machine learning library)是Spark提供的可扩展的机器学习库。MLlib中已经包含了一些通用的学习算法和工具,如:分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。
MLlib提供的API主要分为以下两类:
- spark.mllib包中提供的主要API。
- spark.ml包中提供的构建机器学习工作流的高层次的API。
3. 数据类型
MLlib支持存储在一台机器上的局部向量和矩阵以及由一个或多个RDD支持的分布式矩阵。局部向量和局部矩阵是提供公共接口的简单数据模型。Breeze和jblas提供了底层的线性代数运算。Breeze提供了一组线性代数和数字计算的库,具体信息访问http://www.scalanlp.org/。jblas提供了使用Java开发的线性代数库,具体信息访问http://jblas.org/。
3.1 局部向量
MLlib支持两种局部向量类型:密集向量(dense)和稀疏向量(sparse)。密集向量由double类型的数组支持,而稀疏向量则由两个平行数组支持。例如,向量(1.0,0.0,3.0)由密集向量表示的格式为[1.0,0.0,3.0],由稀疏向量表示的格式为(3,[0,2],[1.0,3.0])。
注意:这里对稀疏向量做些解释。3是向量(1.0,0.0,3.0)的长度,除去0值外,其他两个值的索引和值分别构成了数组[0,2]和数组[1.0,3.0]。
有关向量的类如图所示。
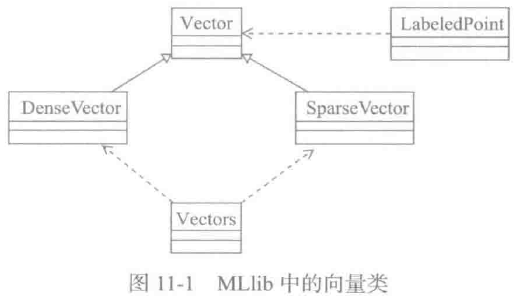
Vector是所有局部向量的基类,Dense-Vector和SparseVector都是Vector的具体实现。
Spark官方推荐使用Vectors中实现的工厂方法创建局部向量,就像下面这样:
import org.apache.spark.mllib.linalg.{Vector, Vectors}
//创建密集向量(1.0, 0.0, 3.0)
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
//给向量(1.0, 0.0, 3.0)创建疏向量
val svl: Vector= Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
//通过指定非0的项目,创建稀疏向量(1.0, 0.0, 3.0)
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
注意: Scala默认会导入scala.collection.immutable.Vector,所以必须显式导入org.apache.spark.mllib.linalg.Vector才能使用MLlib才能使用MLlib提供的Vector。
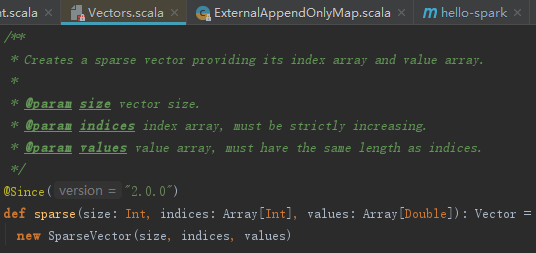
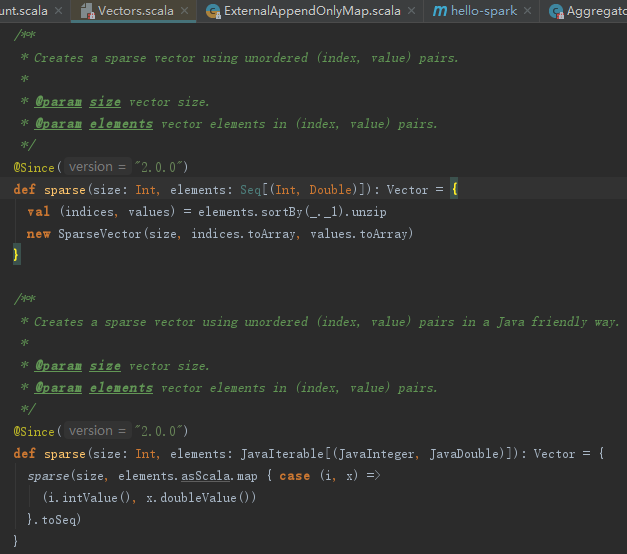
上面例子中以数组为参数,调用Vectors的sparse接口,见如下代码。使用Seq创建稀疏向量,其本质依然是使用数组,见如下代码。
3.2 标记点
标记点是将密集向量或者稀疏向量与应答标签相关联。在MLlib中,标记点用于监督学习算法。MLlib使用double类型存储标签,所以我们能在回归和分类中使用标记点。如果只有两种分类,可以使用二分法,一个标签要么是1.0,要么是0.0。如果有很多分类,标签应该从零开始:0、1、2....
标记点由样例类LabeledPoint来表示,其使用方式如下。
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.regression.LabeledPoint
//使用标签1.0和一个密集向量创建一个标记点
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
//使用标签0.0和一个疏向量创建一个标记点
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
用稀疏的训练数据做练习是很常见的,好在MLlib支持读取存储在LIBSVM格式中的训练例子。LIBSVM格式是一种每一行表示一个标签稀疏特征向量的文本格式,其格式如下:
label index1:value1 index2:value2 ...
LIBSVM是林智仁教授等开发设计的一个简单、易用和快速有效的SVM模式识别与回归的软件包。MLlib已经提供了MLUtils.loadLibSVMFile方法读取存储在LIBSVM格式文本文件中的训练数据,见如下代码:
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
3.3 局部矩阵
MLlib支持数据存储在单个double类型数组的密矩阵。先来看这样一个矩阵:

这个矩阵是如何存储的?它只是存储到一维数组[1.0, 3.0, 5.0, 2.0, 4.0, 6.0],这个矩阵的尺寸是3*2,即3行2列。
有关局部矩阵的类如下图所示。局部矩阵的基类是Matrix,目前有一个实现类DenseMatrix。Spark官方推荐使用Matrices中实现的工厂方法创建局部矩阵,例如:
import org.apache.spark.mllib.linalg.{Matrix, Matrices}
//创建密矩阵((1.0,2.0),(3.0, 4.0),(5.0, 6.0))
val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
3.4 分布式矩阵
分布式矩阵分布式地存储在一个或者多个RDD中。如何存储数据量很大的分布式矩阵?最重要的在于选择一个正确的格式。如果将分布式矩阵转换为不同格式,可能需要全局的shuffle,成本非常昂贵。
有关分布式矩阵的类如图所示:

迄今为止,MLlib已经实现了4种类型的分布式矩阵:
- RowMatrix:最基本的分布式矩阵类型,是面向行且行索引无意义的分布式矩阵。RowMatrix的行实际是多个局部向量的RDD,列受限于integer的范围大小。RowMatrix适用于列数不大以便单个局部向量可以合理地传递给Driver,也能在单个节点上存储和操作的情况。
下面展示了可以使用RDD[Vector]实例来构建RowMatrix的例子。
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val rows: RDD[Vector] = ...
val mat: RowMatrix = new RowMatrix(rows)
val m = mat.numRows()
val n = mat.numCols()
- IndexedRowMatrix:与RowMatrix类似,但却面向索引的分布式矩阵。IndexedRowMatrix常用于识别行或者用于执行连接操作。可以使用RDD[IndexedRow]实例创建IndexedRowMatrix。IndexedRow的实现如下:
@Experimental
case class IndexedRow(index: Long, vector: Vector)
通过删除IndexedRowMatrix的行索引,可以将IndexedRowMatrix转换为RowMatrix。下面的例子演示了如何使用IndexedRowMatrix。
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix, RowEntry}
val rows: RDD[IndexedRow] = ...
val mat: IndexedRowMatrix = new IndexedRowMatrix(rows)
val m = mat.numRows()
val n = mat.numCols()
val rowMat: RowMatrix = mat.toRowMatrix()
- CoordinateMatrix:使用坐标列表(COO)格式存储的分布式矩阵。支持CoordinateMatrix的RDD实际是(i: Long,j: Long, value: Double)这样的三元组,i是行索引,j是列索引,value是实际存储的值。CoordinateMatrix适用于行和列都很大且矩阵很稀疏的情况。
可以使用RDD[MatrixEntry]实例创建CoordinateMatrix。MatrixEntry的实现如下。
@Experimental
case class MatrixEntry(i: Long, j: Long, value: Double)
通过调用CoordinateMatrix的toIndexedRowMatrix方法,可以将CoordinateMatrix转换为IndexedRowMatrix。下面的例子演示了CoordinateMatrix的使用。
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
val entries: RDD[MatriEntry] = ...
val mat: CoordinateMatrix = new CoordinateMatrix(entries)
val m = mat.numRows()
val n = mat.numCols()
val indexedRowMatrix = mat.toIndexedRowMatrix()
- BlockMatrix:由RDD[MatrixBlock]支持的分布式矩阵。MatrixBlock实际是((Int, Int), Matrix)这样的二元组,(Int, Int)是Block的索引,Matrix是记录块大小的子矩阵。BlockMatrix支持与其他BlockMatrix的add和multiply,还提供validate方法用于校验当前BlockMatrix是否恰当构建。
通过调用IndexedRowRowMatrix或者CoordinateMatrix的toBlockMatrix方法,可以方便转换为BlockMatrix。toBlockMatrix方法创建的Block的默认大小是1024 x 1024。可以使用toBlockMatrix(rowsPerBlock,colsPerBlock)方法改变Block的大小。下面的例子演示了BlockMatrix的使用。
import org.apache.spark.mllib.linalg.distributed.{BlockMatrix, CoordinateMatrix, MatrixEntry}
val entries: RDD[MatrixEntry] = ...
val coordMat: CoordinateMatrix = new CoordinateMatrix(entries)
val matA: BlockMatrix = coordMat.toBlockMatrix().cache()
matA.validate()
val ata = matA.transpose.multiply(matA)
注意:由于MLlib会缓存矩阵的大小,所以支持分布式矩阵的RDD必须要有明确的类型,否则会导致出错。
4. 基础统计
MLlib提供了很多统计方法,包括摘要统计、相关统计、分层抽样、假设校验、随机数生成等。这些都涉及统计学、概率论的专业知识。
4.1 摘要统计
调用Statistics类的colStats方法,可以获得RDD[Vector]的列的摘要统计。colStats方法返回了MultivariateStatisticalSummary对象,MultivariateStatisticalSummary对象包含了列的最大值、最小值、平均值、方差、非零元素的数量以及总数。下面的例子演示了如何使用colStats。
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.stat.{MultivariateStatisticalSummary, Statistics}
val observations: RDD[Vector] = ...
val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)
println(summary.mean) //每个列值组成的密集向量
println(summary.variance) //列向量方差
println(summary.numNonzeros) //每个列的非零值个数
colStats实际使用了RowMatrix的computeColumnSummaryStatistics方法,见代码如下:

4.2 相关统计
计算两个序列之间的相关性是统计中通用的操作。MLlib提供了计算多个序列之间相关统计的灵活性。目前支持的关联方法运用了皮尔森相关系数(Pearson correlation coefficient)和斯皮尔森相关系统(Spearman's rank correlation coefficient)。
1. 皮尔森相关系数
皮尔森相关系数也称为皮尔森积矩相关系数(Pearson product-moment correlation coefficient),是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。
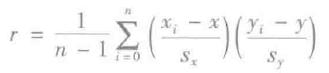
相关系数用r表示,其中n为样本量,xi,yi,sx,sy 分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。若r=0,表明两个变量间不是线性相关,但有可能是其他方式的相关(比如曲线方式)。
2. 斯皮尔森秩相关系数
斯皮尔森秩相关系数也称为Spearman的p,是由Charles Spearman命名的,一般用希腊字母ps(rho)或rs表示。Spearman秩相关系数是一种无参数(与分布无关)的校验方法,用于度量变量之间联系的强弱。在没有重复数据的情况下,如果一个变量是另外一个变量的严格单调函数,则Spearman秩相关系数就是+1或-1,称变量完全Spearman秩相关。注意和Pearson完全相关的区别,只有当两变量存在线性关系时,Pearson相关系数才为+1或-1。
Spearman秩相关系数为:
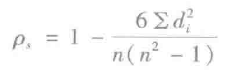
Statistics提供了计算序列之间相关性的方法,默认情况下使用皮尔森相关系数,使用方法如下:
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.stat.Statistics val sc: SparkContext = ...
val seriesX: RDD[Double] = ... //a series
val seriesY: RDD[Double] = ... //和seriesX必须有相同的分区和基数
val correlation:Double = Statistics.corr(seriesX, seriesY, "pearson")
val data: RDD[Vector] = ... //每个向量必须是行,不能是列
val correlMatrix: Matrix = Statistics.corr(data, "pearson")
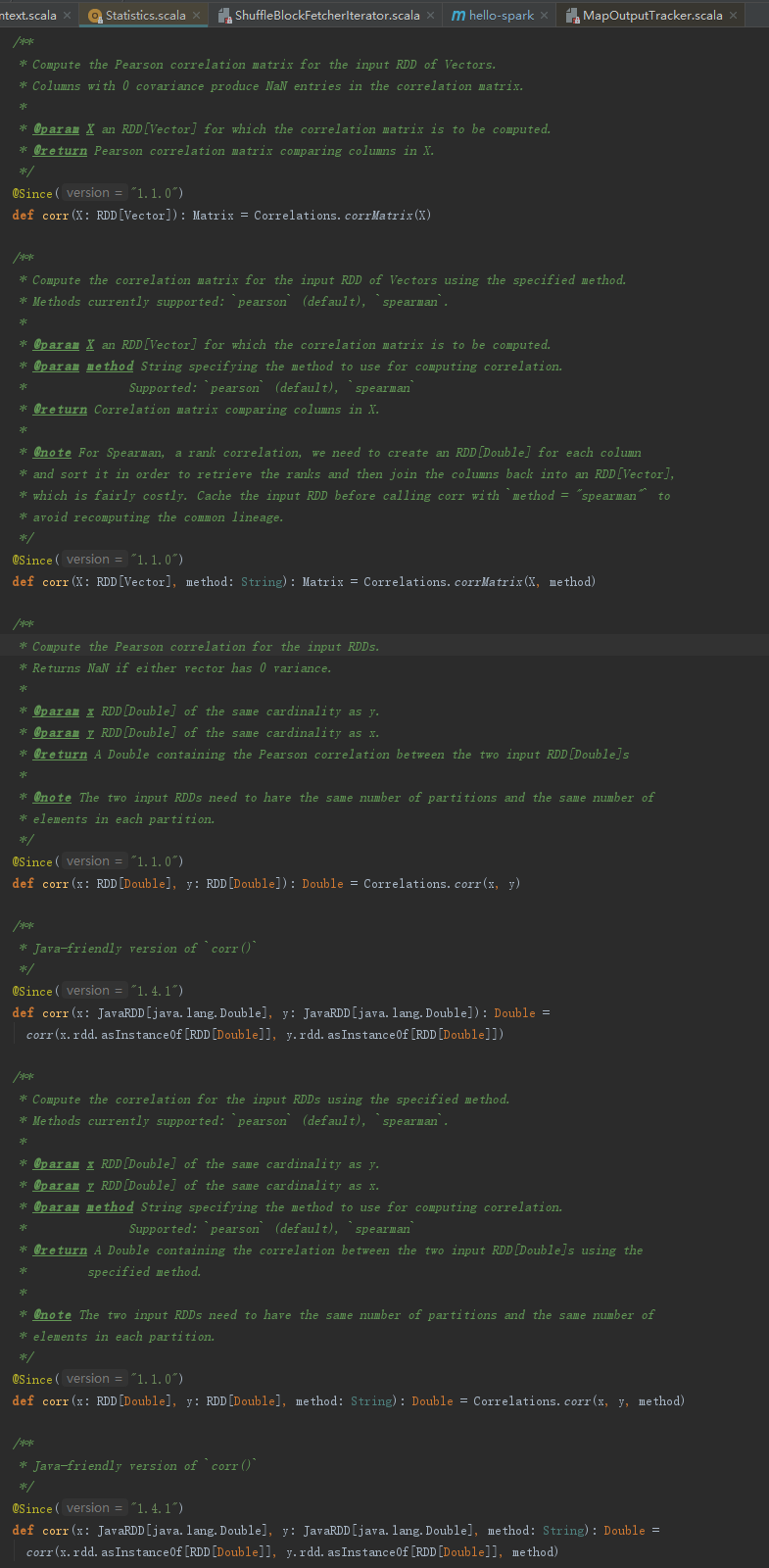
Statistics中相关性的实现,见代码如下:
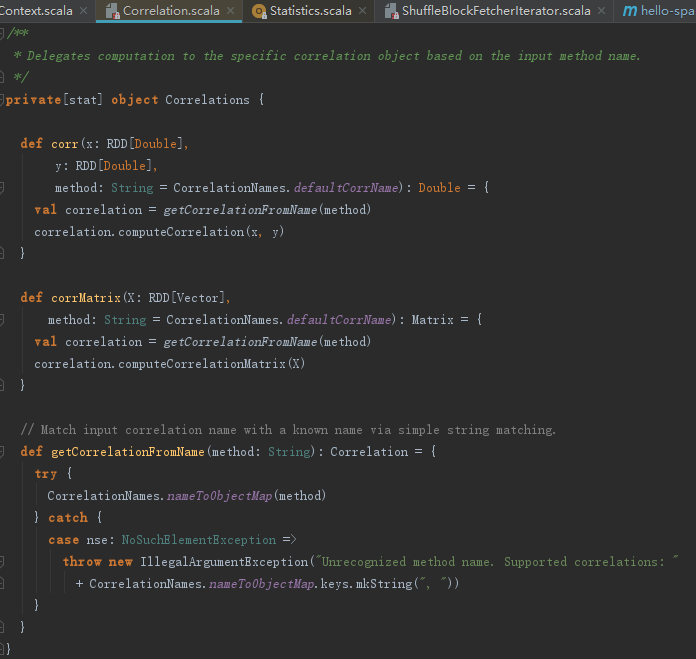
其实质是代理了Correlations,Correlations中相关性的实现见代码如下:
4.3 分层抽样
分层抽样(Stratified sampling)是先将总体按某种特征分为若干次级(层),然后再从每一层内进行独立取样,组成一个样本的统计学计算方法。为了对分层抽样有更直观的感受,请看下面的例子:
某市现有机动车共1万辆,其中大巴车500辆,小轿车6000辆,中拔车1000辆,越野车2000辆,工程车500辆。现在要了解这些车辆的使用年限,决定采用分层抽样方式抽取100个样本。按照车辆占比,各类车辆的抽样数量分别为5,60,10,20,5.
摘要统计和相关统计都集成Statistics中,而分层抽样只需要调用RDD[(K,V)]的sampleByKey和sampleByKeyExact即可。为了分层抽样,其中的键可以被认为是标签,值是具体的属性。sampleByKey方法采用掷硬币的方式来决定是否将一个观测值作为采样,因此需要一个预期大小的样本数据。sampleByKeyExact则需要更多更有效的资源,但是样本数据的大小是确定的。sampleByKeyExact方法允许用户采用符合[fk * nk] V k ∈ K,其中fk是键k的函数,nk是RDD[(K,V)]中键为k的(K,V)对,K是键的集合。下例演示了如何使用分层抽样。
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext
import org.apache.spark.rdd.PairRDDFunctions val sc: SparkContext = ...
val data = ... //an RDD[(K,V)] of any key value pairs
val fractions: Map[K. Double] = ... //specify the exact fraction desired from each key
val exactSample = data.sampleByKeyExact(withReplacement = false, fractions)
4.4 假设校验
假设校验(hypothesis testing) 是数理统计学中根据一定假设条件由样本推断总体的一种方法。
如果对总体的某种假设是真实的,那么不利于或不能支持这一假设的事件A(小概率事件)在一次试验中几乎不可能发生;要是在一次试验中A竟然发生了,就有理由怀疑该假设的真实性,拒绝这一假设。小概率原理可以用图表示。
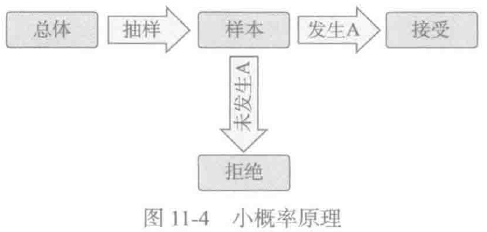
H0表示原假设,H1表示备选假设。常见的假设校验有如下几种:
- 双边校验:H0:u = u0,H1:u=/u0
- 右侧单边校验:H0:u<=u0,H1:u>u0
- 左侧单边校验:H0:u>=u0,H1:u<u0
假设校验是一个强大的工具,无论结果是否偶然的,都可以决定结果是否具有统计特征。MLlib目前支持皮尔森卡方测试。输入数据的类型决定了是做卡方适合度检测还是独立性检测。卡方适合度检测的输入数据类型应当是向量,而卡方独立性检测需要的数据类型是矩阵。RDD[LabeledPoint]可以作为卡方检测的输入类型。下列演示了如何使用假设校验。
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.stat.Statistics._ val sc: SparkContext = ...
val vec: Vector = ... //事件的频率组成的vector
val goodnessOfFitTestResult = Statistics.chiSqTest(vec)
println(goodnessOfFitTestResult)
val mat: Matrix = ... //偶然性matrix
val independenceTestResult = Statistics.chiSqTest(mat)
println(independenceTestResult)
val obs:RDD[LabeledPoint] = ... //(feature, label) pairs
val featureTestResults: Arra[ChiSqTestResult] = Statistics.chiSqTest(obs)
var i = 1
featureTestResults.foreach{ result =>
println(s"Column $i:\n result")
i += 1
} //summary of the test
4.5 随机数生成
随机数可以看做随机变量,什么是随机变量?将一枚质地均匀的硬币抛掷3次,记录它的结果,有:
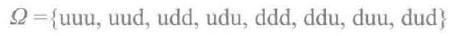
其中u代表正面朝上,d代表反面朝上,整个集合Ω是抛掷3次硬币的样本空间。正面朝上的次数可能是0,1,2,3。由于样本空间Ω中的结果都是随机发生的,所以出现正面的次数X是随机的,X即为随机变量。如果抛掷硬币,直到出现正面的抛掷次数为Y,那么Y的取值可能是0,1,2,3...。如果随机变量的取值是有限的(比如X)或者是可列的(比如Y),那么就称为离散随机变量。
刚才说的抛掷3次硬币的情况下,使用P(X = 取值)的方式表达每种取值的概率,我们不难得出:
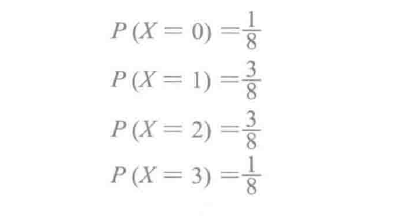
如果样本空间上随机变量的取值用x1,x2,x3,....表示,那么存在满足p(x1) = P(X = xi)和Σip(xi) = 1 的函数p。这个函数p称为随机变量X的概率质量函数或者频率函数。
如果X取值累积某个范围的值,那么其累积分布函数定义如下:

累积分布函数满足:
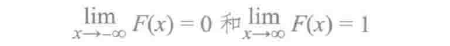
同一样本空间上两个离散随机变量X和Y的可能取值分别为x1,x2,x3,...和y1,y2,y3,...,如果对所有i和j,满足:
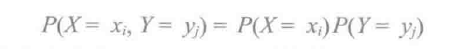
则X和Y是独立的。将此定义推广到两个以上离散随机变量的情形,如果对所有i, j 和 k,满足:
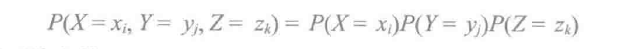
则X、Y和Z是相互独立的。
刚才所说的X、Y的取值都是离散的,还有一种情况下取值是连续的。以人的寿命为例,可以是任意的正实数值。与频率函数相对的是密度函数ƒ(x)。ƒ(x)有这些性质:ƒ(x) ≥ 0,ƒ分段连续且∫∞-∞ƒ(x)dx = 1。如果X是具有密度函数ƒ的随机变量,那么对于任意的a < b,X落在区间(a, b)上的概率是密度函数从a到b的下方面积:
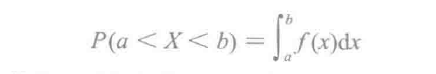
随机数生成对于随机算法、随机协议和随机性能测试都很有用。MLlib支持均匀分布、标准正态分布、泊松分布等生成随机RDD。
MLlib有关随机数的类如图所示:
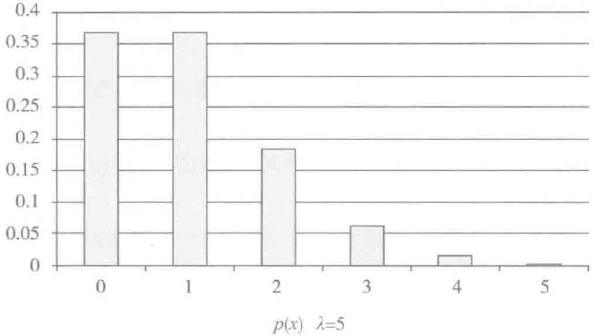
以泊松分布为例,先看看它的数学定义。参数为λ(λ>0)的泊松频率函数是

当λ = 0.1、1、5、10时的泊松分布如图所示:

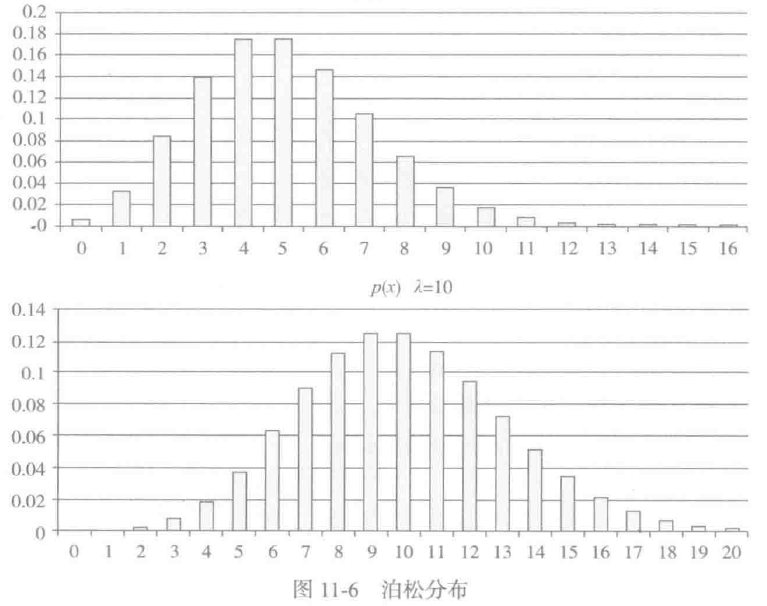
RandomRDDs提供了工厂方法创建RandomRDD和RandomVectorRDD。下面的例子中生成了一个包含100万个double类型随机数的RDD[double],其值符合标准正太分布N(0,1),分布于10个分区,然后将其映射到N(1, 4)。
import org.apache.spark.SparkContext
import org.apache.spark.mllib.random.RandomRDDs._ val sc: SparkContext = ...
val u = normalRDD(sc, 1000000L, 10)
val v = u.map(x => 1.0 + 2.0 * x)
5. 分类和回归
MLlib支持多种多样的分析方法,例如,二元分类、多元分类和回归。表11-1列出了各类问题的支持算法。

5.1 数学公式
许多标准的机器学习方法都可以配制成凸优化问题,即找到一个极小的凸函数ƒ依赖于一个d项的可变向量w。形式上,我们可以写为优化问题minwεR dƒ(w),其中所述目标函数的形式为:
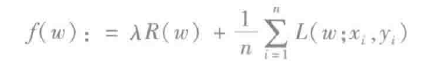
这里的向量xi ε Rd 是训练数据,1 ≤ i ≤ n 并且yi ε Rd 是想要预测数据的相应的标签。如果L(w; xi, yi)能表示为 wτX和y的函数,我们就说这个方法是线性的。几个MLlib的分类和回归算法都属于这一类,并在这里讨论。
目标函数ƒ有两个部分:控制该模型的复杂的正则化部分和用于在训练数据上测量模型的误差的损失部分。损失函数L(w)是典型的基于w的凸函数。固定的正则化参数λ ≥ 0定义了最小损失(即训练误差)和最小化模型的复杂性(即避免过度拟合)这两个目标之间的权衡。
(1) 损失函数
在统计学,统计决策理论和经济学中,损失函数是指一种将一个事件(在一个样本空间中的一个元素)映射到一个表达与其事件相关的经济成本和机会成本的实数上的一种函数。通常而言,损失函数由损失项和正则项组成。表11-2列出了常用的损失函数。

这里对表11-2中的一些内容做些说明:
- Hinge loss:常用于软间隔支持向量机的损失函数;
- Logistic loss:常用于逻辑回归的损失函数;
- Squared loss:常用于最小二乘的损失函数;
- Gradient or sub gradient:梯度与次梯度
(2) 正规化
正规化的目的是鼓励简单的模型,并避免过度拟合。MLlib支持以下正规化,如表11-3所示:

这里的sign(w)是由向量w中所有项的符号(±1)组成的向量。平滑度L2正规化问题一般比L1正规化容易解决。然而L1正规化能帮助促进稀疏权重,导致更小、更可解释的模型,其中后者于特征选择是有用的。没有任何正规化,特别是当训练实例的数目是小的,不建议训练模型。
(3) 优化
线性方法使用凸优化来优化目标函数。MLlib使用两种方法:新元和L-BFGS来描述优化部分。目前,大多数算法的API支持随机梯度下降(SGD),并有一些支持L-BFGS。
5.2 线性回归
线性回归是一类简单的指导学习方法。线性回归是预测定量响应变量的有用工具。很多统计学习方法都是从线性回归推广和扩展得到的,所以我们有必要重点理解它。
1.简单线性回归
简单线性回归非常简单,只根据单一的预测变量X预测定量响应变量Y。它假定X与Y之间存在线性关系。其数学关系如下:
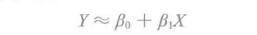
≈表示近似。这种线性关系可以描述为Y对X的回归。β0和β1是两个未知的常量,被称为线性模型的系数,它们分别表示线性模型中的截距和斜率。
β0和β1怎么得到呢?通过大量样本数据估算出估计值。假如样本数据如下:
(x1, y1),(x2, y2),....,(x3, y3)
此时问题转换为在坐标中寻找一条与所有点的距离最大程度接近的直线问题,如图11-7所示
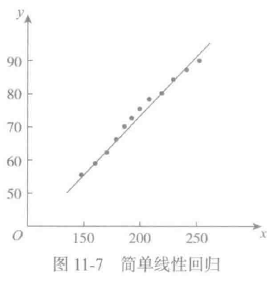
使用最小二乘方法最终求得的估计值(β’0,β’1)。
实际情况,所有的样本或者真实数据不可能真的都在一条直线上,每个坐标都会有误差,所以可以表示为如下关系:
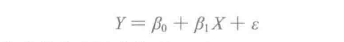
上式也称为总体回归直线,是对X和Y之间真实关系的最佳线性近似。
2.多元线性回归
相比简单线性回归,实践中常常不止一个预测变量,这就要求对简单线性回归进行扩展。虽然可以给每个预测变量单独建立一个简单线性回归模型,但无法做出单一的预测。更好的方法是扩展简单线性回归模型,使它可以直接包含多个预测变量。一般情况下,假设有p个不同的预测变量,多元线性回归模型为:
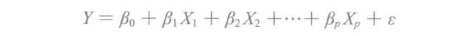
其中Xj代表第j个预测变量,βj代表第j个预测变量和响应变量之间的关联。
5.3 分类
5.2节的线性回归模型中假设响应变量Y是定量的,但很多时候,Y却是定性的。比如杯子的材质是定性变量,可以是玻璃、塑料或不锈钢等。定性变量也叫分类变量。预测定性响应值是指对观测分类。
分类的目标是划分项目分类。最常见的分类类型是二元分类,二元分类有两种分类,通常命名为正和负。如果有两个以上的分类,它被称为多元分类。MLlib支持两种线性方法分类:线性支持向量机和逻辑回归。线性支持向量机仅支持二元分类,而逻辑回归对二元分类和多元分类都支持。对于这两种方法,MLlib支持L1和L2正规化变体。MLlib中使用RDD[LabeledPoint]代表训练数据集,其中标签引从0开始,如0,1,2,...。对于二元标签γ在MLlib中使用0表示负,使用+1表示正。
1.线性支持向量机
线性支持向量机(SVM)是用于大规模分类任务的标准方法。正是在介绍损失函数时提到的:
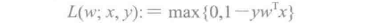
默认情况下,线性支持向量机使用L2正规化训练。MLlib也支持选择L1正规化,在这种情况下,问题就变成了线性问题。线性支持向量机算法输出SVM模型。给定一个新的数据点,记为X,该模型基于wτx的值做预测。默认情况下,如果wτx ≥ 0则结果是正的,否则为负。
下例展示了如何加载样本数据集,执行训练算法。
import org.apache.spark.mllib.classification.{SVMModel,SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.util.MLUtils
//加载LIBSVM格式的训练数据
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsbvm_data.txt")
//将数据切分为训练数据(60%)和测试数据(40%)
val splits = data.randomSplit(Array(0.6,0.4),seed = 11L)
val training = splits(0).cache()
val test = splits(1)
//运行训练算法构建模型
val numIterations = 100
val model = SVMWithSGD.train(training, numIterations)
//在测试数据上计算原始分数
val scoreAndLabels = test.map{ point =>
val score = model.predict(point.features)
(score, point.label)
}
//获取评估指标
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
//保存和加载模型
model.save(sc, "myModelPath")
val sameModel = SVMModel.load(sc, "myModelPath")
SVMWithSGD.train默认执行L2正规化,可以设置正则化参数为1.0为执行L1正规化。配置及优化SVMWithSGD的代码如下:
import org.apache.spark.mllib.optimization.L1Updater
val svmAlg = new SVMWithSGD()
svmAlg.optimizer.
setNumIterations(200).
setRegParam(0.1).
setUpdater(new L1Updater)
val modelL1 = svmAlg.run(training)
2.逻辑回归
逻辑回归被广泛用于预测二元响应。它正是在介绍损失函数时提到的:

对于二元分类问题,该算法输出二元逻辑回归模型。给定一个新的数据点,记为X,该模型基于应用逻辑函数
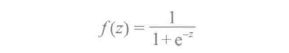
做预测,其中z = wτx。默认情况下,如果ƒ(wτx) > 0.5,输出为正,否则为负。虽然不像线性支持向量机,逻辑回归模型中,ƒ(z)的原始输出具有一概率解释(即X是正概率)。
二元逻辑回归可以推广到多元逻辑回归来训练和预测多元分类问题。对于多元分类问题,该算法将输出一个多元逻辑回归模型,其中包含K-1个二元逻辑回归模型。MLlib实现了两种算法来解决逻辑回归分析:小批量梯度下降和L-BFGS。Spark官方推荐L-BFGS,因为它比小批梯度下降的收敛更快。
下例演示了如何使用逻辑回归。
//运行训练算法构建模型
val model = new LogisticRegressionWithLBFGS().setNumClasses(10).run(training)
//在测试数据上计算原始分数
val predictionAndLabels = test.map{ case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
//获取评估指标
val metrics = new MulticlassMetrics(predictionAndLabels)
val precision =metrics.precision
println("Precision = " + precision)
//保存和加载模型
model.save(sc, "myModelPath")
val samleModel = LogisticRegressionModel.load(sc, "myModelPath")
5.4 回归
1.线性最小二乘、套索和岭回归
线性最小二乘公式是回归问题最常见的公式。在介绍损失函数时也提到过它的公式:

多种多样的回归方法通过使用不同的正规化类型,都派生自线性最小二乘。例如,普通最小二乘或线性最小二乘使用非正规化:岭回归使用L2正规化;套索使用L1正规化。对于所有这些模型的损失和训练误差:
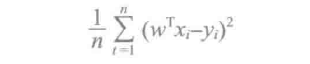
就是均方误差。
下面的例子演示了如何使用线性回归。
//加载解析数据
val data = sc.textFile("data/mllib/ridge-data/lpsa.data")
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble))).cache()
//构建模型
val numIterations = 100
val model = LinearRegressionWithSGD.train(parsedData, numIterations)
//使用训练样本计算模型并且计算训练误差
val valueAndPreds = parsedData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val MSE = valueAndPreds.map{case(v, p) => math.pow((v- p), 2)}.mean()
println("training Mean Squared Error = " + MSE)
//保存与加载模型
model.save(sc, "myModelPath")
val sameModel = LinearRegressionModel.load(sc, "myModelPath")
}
2.流线性回归
流式数据可以适用于线上的回归模型,每当有新数据到达时,更新模型的参数。MLlib目前使用普通最小二乘法支持流线性回归。除了每批数据到达时,模型更新最新的数据外,实际与线下的执行是类似的。
下面的例子,假设已经初始化好了StreamingContext ssc来演示流线性回归。
val numFeatures = 3
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.zeros(numFeatures))
model.trainOn(trainingData)
model.predictOnValues(testData.map(lp => (lp.label, lp.features))).print()
ssc.start()
ssc.awaitTermination()
6. 决策树
决策树是分类和回归的机器学习任务中常用的方法。决策树广泛使用,因为它们很容易解释,处理分类的功能,延伸到多元分类设置,不需要缩放功能,并能捕捉到非线性和功能的交互。
MLlib使用连续和分类功能支持决策树的二元和多元的分类和回归。通过行实现分区数据,允许分布式训练数以百万计的实例。
6.1 基本算法
决策树是一个贪心算法,即在特性空间上执行递归的二元分割。决策树为每个最底部(叶)分区预测相同的标签。为了在每个树节点上获得最大的信息,每个分区是从一组可能的划分中选择的最佳分裂。
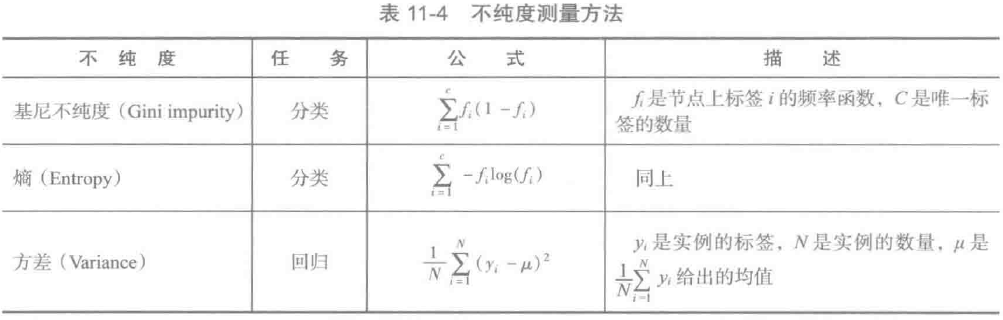
1.节点不纯度和信息增益
节点不纯度是节点上标签的均匀性的量度。当前实现提供了两种分类不纯度测量的方法(基尼不纯度和嫡)和一种回归不纯度测量的方法(方差),如表11-4所示:
信息增益是父节点不纯度与两个子节点不纯度的加权总和之间的差。假设将有s个分区,大小为N的数据集D划分为两个数据集Dleft和Dright,那么信息增益为:
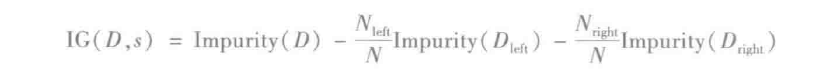
2.划分候选人
(1) 连续特征
对于单机上实现的小数据集,给每个连续特征划分的候选人在此特征上有唯一值。有些实现了对特征值排序,为了加速计算,使用这些有序的唯一值划分候选人。对于大的分布式数据集,排序是很昂贵的。通过在样本数据分数上执行位计算,实现了计算近似的划分候选人集合。有序划分创建了“箱”,可使用maxBins参数指定这样的容器的最大数量。
(2) 分类特征
对于有M种可能值的分类特征,将会有2M-1-1个划分候选人。对于二元(0/1)分类和回归,我们可以通过平均标签排序的分类特征值,减少划分候选人至M-1多得数据量。例如,对于一个有A、B和C三个分类的分类特征的二元分类问题,其相应的标签1的比例是0.2,0.6和0.4时,分类特征是有序的A、C、B。两个划分候选人分别是A|C,B和A,C|B,其中|标记划分。
在多元分类中共有2M-1-1种可能的划分,无论何时都可能被使用。当2M-1-1比参数maxBins大时,我们使用与二元分类和回归相类似的方法。M种分类特征用不纯度排序,最终得到需要考虑的M-1个划分候选人。
3.停止规则
递归树的构建当满足下面三个条件之一时会停在一个节点。
- 节点的深度与maxBins相等;
- 没有划分候选人导致信息增益大于minInfoGain;
- 没有划分候选人产生的子节点都至少有minInstancesPerNode个训练实例。
6.2 使用例子
下面的例子演示了使用基尼不纯度作为不纯度算法且树深为5的决策树执行分类。
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val splits = data.randomSplit(Array(0.7, 0.3))
//训练决策树模型
//空categoricalFeaturesInfo说明所有的特征是连续的
val numClasses = 2
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "gini"
val maxDepth = 5
val maxBins = 32
// trainingData是训练数据
val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
//在测试实例上计算
val labelAndPreds = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
println("Test Error = " + testErr)
println("Learned classification tree model: \n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = DecisionTreeModel.load(sc, "myModelPath")
下面的例子演示了使用方差作为不纯度算法且树深为5的决策树执行分类
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "variance"
val maxDepth =5
val maxBins = 32
val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
val labelsAndPredictions = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelsAndPredictions.map{ case(v, p) => math.pow((v - p), 2)}.mean()
println("Test Mean Squared Error =" + testMSE)
println("Learned regression tree model:\n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = DecisionTreeModel.load(sc, "myModelPath")
7. 随机森林
合奏是一个创建由其他模型的集合组合而成的模型的学习算法。MLlib支持两个主要的合奏算法:梯度提升决策树和随机森林,它们都使用决策树作为其基础模型。梯度提升决策树和随机森林虽然都是决策树合奏的学习算法,但是训练过程是不同的。关于合奏有以下几个权衡点:
- GBT每次都要训练一颗树,所以它们比随机森林需要更长的时间来训练。随机森林可以平行地训练多棵树。另一方面,GBT往往比随机森林更合理地使用更小(浅)的树并且训练小树会花费更少的时间。
- 随机森林更不易发生过度拟合。随机森林训练更多的树会减少多半的过度拟合,而GBT训练更多的树会增加过度拟合。(在统计语言中,随机森林通过使用更多的树木减少方差,而GBT通过使用更多的树木减少偏差。)
- 随机森林可以更容易调整,因为性能与树木的数量是单调增加的。但如果GBT树木的数量增长过大,性能可能开始下降。
总之,两种算法都是有效的,具体选择应取决于特定的数据集。
随机森林是分类与回归中最成功的机器学习模型之一。为了减少过度拟合的风险,随机森林将很多决策树结合起来。和决策树相似,随机森林处理分类的功能,延伸到多元分类设置,不需要缩放功能,并能捕捉到非线性和功能的交互。
MLlib使用连续和分类功能支持随机森林的二元和多元的分类和回归。
7.1 基本算法
随机森林训练一个决策树的集合,所以训练可以并行。该算法随机性注入训练过程,使每个决策树会有一点不同。结合每棵树的预测降低了预测的方差,改进了测试数据的性能。
1.随机注入
算法随机性注入训练的过程包括:
1) 每次迭代对原始数据集进行二次采样获得不同的训练集,即引导。
2) 考虑在树的每个节点上将特征的不同随机子集分割。
除了这些随机性,每个决策树个体都以同样的方法训练。
2.预测
对随机森林做预测,就必须聚合它的决策树集合的预测。分类和回归的聚合是不同的:
- 分类采用多数表决。每棵树的预测作为对分类的一次投票,收到最多投票的分类就是预测结果。
- 回归采用平均值。每棵树都有一个预测值,这些树的预测值的平均值就是预测结果。
7.2 使用例子
下面例子演示了使用随机森林执行分类。
//训练随机森林模型
//空categoricalFeaturesInfo说明所有特征是连续的
val numClasses = 2
val categoricalFeaturesInfo = Map[Int, Int]()
val numTrees = 3 //use more practice
val featureSubsetStrategy = "auto" //Let the algorithm choose.
val impurity = "gini"
val maxDepth = 4
val maxBins = 32
val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
val labelAndPreds = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
} val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
println("Test Error = " + testErr)
println("Learned classification forest model:\n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = RandomForestModel.load(sc, "myModelPath")
下面例子演示了使用随机森林执行回归。
val numClasses = 2
val categoricalFeaturesInfo = Map[Int, Int]()
val numTrees = 3 //Use more in practice.
val featureSubsetStrategy = "auto" //Let the algorithm choose
val impurity = "variance"
val maxDepth = 4
val maxBins = 32
val model = RandomForest.trainRegressor(trainingData, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
val labelAndPredictions = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelAndPredictions.map{ case(v, p) => math.pow((v -p), 2)}.mean()
println("Test Mean Squared Error = " + testMSE)
println("Learned regression forest model:\n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = RandomForestModel.load(sc, "myModelPath")
8. 梯度提升决策树
GBT迭代训练决策树,以便最小化损失函数。和决策树相似,随机森林处理分类的功能,延伸到多元分类设置,不需要缩放功能,并能捕捉到非线性和功能的交互。
MLlib使用连续和分类功能支持梯度提升决策树的二元和多元的分类和回归。
8.1 基本算法
GBT迭代训练一个决策树的序列。在每次迭代中,算法使用当前合奏来预测每个训练实例的标签,然后将预测与真实的标签进行比较。数据集被重新贴上标签,将重点放在预测不佳的训练实例上。因此,在下一迭代中,决策树将帮助纠正先前的错误。重贴标签的具体机制是由损失函数定义的。随着每次迭代,GBT进一步减少训练数据上的损失函数。表11-5列出了MLlib中GBT支持的损失函数。请注意,每个损失只适用于分类或回归之一。其中N表示实例数量,y1表示实例i的标签,xi表示实例i的特征,F(Xi)表示实例i的模型预测标签。

8.2 使用例子
下例演示了用LogLoss作为损失函数,使用GBT执行分类的例子。
//训练GradientBoostedTree模型
//默认使用LogLoss
val boostingStrategy = BoostingStrategy.defaultParams("Classification")
boostingStrategy.numIterations = 3 //Note:Use more iterations in practice.
boostingStrategy.treeStrategy.numClasses = 2
boostingStrategy.treeStrategy.maxDepth = 5
//空categoricalFeaturesInfo说明所有特征是连续的
boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]()
val model = GradientBoostedTrees.train(trainingData, boostingStrategy)
val labelAndPreds = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
println("Test Error = " + testErr)
println("Learned classification GBT model:\n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = GradientBoostedTreesModel.load(sc, "myModelPath")
下例演示了用Squared Error 作为损失函数,使用GBT执行回归的例子。
//训练GradientBoostedTrees模型
// defaultParams指定了Regression, 默认使用SquaredError
val boostingStrategy = BoostingStrategy.defaultParams("Regression")
boostingStrategy.numIterations = 3 //Note: Use more iterations in practice.
boostingStrategy.treeStrategy.maxDepth = 5
//空categoricalFeaturesInfo说明所有特征是连续的
boostingStrategy。treeStrategy.categoricalFeaturesInfo = Map [Int, Int]()
val model = GradientBoostedTrees.train(trainingData, boostingStrategy)
val labelsAndPredictions = testData.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelsAndPredictions.map{case(v, p) => math.pow((v - p), 2)}.mean()
println("Test Mean Squared Error = " + testMSE)
println("Learned regression GBT model:\n" + model.toDebugString)
model.save(sc, "myModelPath")
val sameModel = GradientBoostedTreesModel.load(sc, "myModelPath")
9. 朴素贝叶斯
9.1 算法原理
j我们首先来介绍一些数学中的理论,然后来看朴素贝叶斯。
条件概率:A和B表示两个事件,且P(B) ≠ 0(B事件发生的概率不等于0),则给定事件B发生的条件下事件A发生的条件概率定义为:

使用条件概率推导出乘法定律:A和B表示两个事件,且P(B) ≠ 0(B事件发生的概率不等于0)。那么:
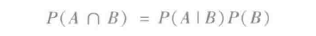
将乘法定律扩展为全概率定律:事件B1,B2,...,Bn满足Uni=1 Bi=Ω,Bi∩Bj=Ø,i ≠ j,且对所有的i,P(Bi) > 0。那么,对于任意的A,满足:

贝叶斯公式:事件事件A, B1,B2,...,Bn, 其中Bi不相交,Uni=1 Bi=Ω,且对所有的i,P(Bi) > 0。那么:
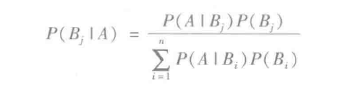
朴素贝叶斯分类算法是一种基于每对特征之间独立性的假设的简单的多元分类算法。朴素贝叶斯的思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。朴素贝叶斯分类的定义如下:
1) 设x = {a1,a2,...,am}为待分类项,每个ai为x的一个特征属性;
2)类别集合C = {y1,y2,...,yn};
3) 计算P(y1|x),P(y2|x),...,P(yn|x) ;
4) 如果P(yk|x) = max{(y1|x),P(y2|x),...,P(yn|x) },则x ε yk 。
关键在第三步:
1) 找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2) 统计得到在各类别下各个特征属性的条件概率估计。即P(a1|y1),P(a2|y1),...,P(am|y1); P(a1|y2),P(a2|y2),... ,P(am|y2);...;P(a1|yn),P(a2|yn),...,P(am|yn) 。
3) 如果各个特征属性都是独立的,则根据贝叶斯公式可以得到以下推导:
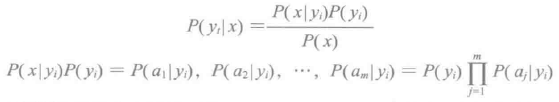
朴素贝叶斯能够被非常有效的训练。它被单独传给训练数据,计算给定标签特征的条件概率分布并给出观察结果用于预测。
MLlib支持多项朴素贝叶斯和伯努利朴素贝叶斯。这些模型典型的应用是文档分类。在这方面,每个观察是一个文档,每个特征代表一个条件,其值是条件的频率(在多项朴素贝叶斯中)或一个由零个或一个指示该条件是否在文档中找到(在伯努利朴素贝叶斯中)。特征值必须是非负的。模型类型选择使用可选的参数"多项"或“伯努利”。“多项”作为默认模型。通过设置参数λ(默认为1.0)添加剂平滑。为文档分类,输入特征向量通常是稀疏的,因为稀疏向量能利用稀疏性的优势。因为训练数据只使用一次,所以没有必要缓存它。
9.2 使用例子
下面的例子演示了如何使用多项朴素贝叶斯。
import org.apache.spark.mllib.classification.{NaiveBayes, NaiveBayesModel}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
val data = sc.textFile("data/mllib/sample_naive_bayes_data.txt")
val parsedData = data.map{ line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}
val splits = parsedData.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0)
val test = splits(1)
val model = NaiveBayes.train(training, lambda = 1.0, modelType = "multinomial")
val predictionAndLabel = test.map(p => (model.predict(p.features), p.label))
val accuracy = 1.0 * predictionAndLabel.filter(x => x._1 == x._2).count() / test.count()
model.save(sc, "myModelPath")
val sameModel = GradientBoostedTreesModel.load(sc, "myModelPath")
10. 保序回归
10.1 算法原理
保序回归属于回归算法,其定义为:给定一个有限的实数集合Y = {y1,y2,...,yn} 表示观测响应, X = {x1,x2,...,xn} 表示未知的响应值,进行拟合找到一个最小化函数:
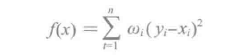
并使用x1≤x2≤...≤xn 对目标排序,其中ωi 是大于0的权重。最终的函数被称为保序回归,并且它是唯一的。它可以看做是排序限制下的最小二乘问题。基本上保序回归是拟合原始数据点最佳的单调函数。
MLlib支持PAVA,此算法使用一种办法来平行化保序回归。保序回归有一个可选参数isotonic,默认值是true。此参数指定保序回归是保序的(单调增加)还是不保序的(单调减少)。
保序回归的结果被视为分段线性函数。因此,预测的规则是:
1) 如果预测输入能准备匹配训练特征,那么返回相关预测。如果有多个预测匹配训练特征,那么会返回其中之一。
2) 如果预测输入比所有的训练特征低或者高,那么最低和最高的训练特征各自返回。如果有多个预测比所有的训练特征低或者高,那么都会返回。
3) 如果预测输入介于两个训练特征,那么预测会被视为分段线性函数和从最接近的训练特征中计算得到的插值。
10.2 使用例子
下面的例子演示了如何使用保序回归。
import org.apache.spark.mllib.regression.{IsotonicRegression, IsotonicRegressionModel}
//省略数据加载及样本划分的代码
val model = new IsotonicRegression().setIsotonic(true).run(training)
val predictionAndLabel = test.map { point =>
val predictedLabel = model.predict(point._2)
(predictedLabel, point._1)
}
val meanSquareError = predictionAndLabel.map{case(p, 1) => math.pow((p-1), 2)}.mean()
println("Mean Squared Error = " + meanSquaredError)
model.save(sc, "myModelPath")
val sameModel = IsotonicRegressionModel.load(sc, "myModelPath")
11. 协同过滤
协同过滤通常用于推荐系统。这些技术旨在填补用户关联矩阵的缺失项。MLlib支持基于模型的协同过滤,用户和产品可以预测缺失项的潜在因素的小集合来描述。MLlib采用交替最小二乘算法来学习这些潜在的因素。
矩阵分解的标准方法基于协同过滤处理用户项矩阵的条目是明确的。现实世界的用例只能访问隐式反馈是更常见的(例如浏览、点击、购买、喜欢、股份等)。
下面的例子演示了如何使用协同过滤。
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.mllib.recommendation.Rating val data = sc.textFile("data/mllib/als/test.data")
val ratings = data.map(_.split(',') match { case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
//使用ALS构建推荐模型
val rank = 10
val numIterations = 20
val model = ALS.train(ratings, rank, numIterations, 0.01)
//模型计算
val usersProducts = ratings.map{ case Rating(user, product, rate) =>
(user, product)
}
val predictions = model.predict(usersProducts).map { case Rating(user, product, rate) =>
((user, product), rate)
}
val ratesAndPreds = ratings.map { case Rating(user, product, rate) =>
((user, product), rate)
}.join(predictions)
val MSE = ratesAndPres.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("Mean Squared Error = " + MSE)
model.save(sc, "myModelPath")
val sameModel = MatrixFactorizationModel.load(sc, "myModelPath")
12. 聚类
聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。MLlib支持的聚类算法如下:
- K-means;
- 高斯混合(Gaussian mixture);
- power iteration clustering(PIC);
- latent Dirichlet allocation(LDA);
- 流式K-means.
12.1 K-means
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说,样本中已经给出了样本的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中点集(x, y, z)。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。
在聚类问题中,训练样本X = {x1,x2,...,xm},每个xi ε Rn,K-means算法是将样本聚类成k个簇,具体算法描述如下:
1) 随机选取k个聚类质心点为µ1,µ2,...,µk ε Rn;
2) 重复下面过程直到收敛。
对每一个样本i计算它应该属于的类

对于每一个类重新计算该类的质心
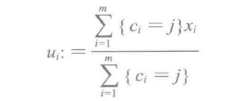
k是我们事先给定的聚类数,ci代表样本i与k个类中距离最近的那个类,ci的值是1到k中的一个。质心uj代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,接着选取距离最近的那个星团作为ci,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心uj(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。图11-8演示了以上过程。
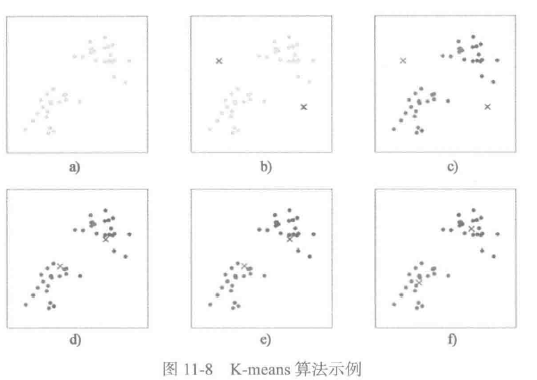
下面的例子演示了K-means算法的使用。
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
val data = sc.textFile("data/mllib/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
val numClusters =2
val numIterations = 20
val clusters = KMeans.train(parsedData, numClusters, numIterations)
val WSSSE = clusters.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + WSSSE)
clusters.save(sc, "myModelPath")
val sameModel = KMeansModel.load(sc, "myModelPath")
12.2 高斯混合
K-means的结果是每个数据点被分配到其中某一个cluster了,而高斯混合则给出这些数据点被分配到每个cluster的概率。高斯混合的算法与K-means算法类似。MLlib中高斯混合的使用例子
import org.apache.spark.mllib.clustering.GaussianMixture
import org.apache.spark.mllib.clustering.GaussianMixtureModel
import org.apache.spark.mllib.linalg.Vectors val data = sc.textFile("data/mllib/gmm_data.txt")
val parsedData = data.map(s => Vectors.dense(s.trim.split(' ').map(_.toDouble))).cache()
val gmm = new GaussianMixture().setK(2).run(parsedData)
gmm.save(sc, "myGMMModel")
val sameModel = GaussianMixtureModel.load(sc, "myGMMModel")
for(i <- 0 until gmm.k){
println("weight=%f\nmu=%s\nsigma=\n%s\n" format
(gmm.weights(i), gmm.gaussians(i).mu, gmm.gaussians(i).sigma))
}
12.3 快速迭代聚类
快速迭代聚类是一种简单可扩展的图聚类方法。其使用例子如下:
import org.apache.spark.mllib.clustering.{PowerIterationClustering, PowerIterationClusteringModel}
import org.apache.spark.mllib.linalg.Vectors
val similarities: RDD[(Long, Long, Double)] = ...
val pic = new PowerIterationClustering().setK(3).setMaxIterations(20)
val model = pic.run(similarities)
model.assignments.foreach{ a =>
println(s"${a.id} -> ${a.cluster}")
}
model.save(sc, "myModelPath")
val sameModel = PowerIterationClusteringModel.load(sc, "myModelPath")
12.4 latent Dirichlet allocation
latent Dirichlet allocation(LDA)是一个三层贝叶斯概率模型,包含词、主题和文档三层结构。文档到主题服从Dirichlet分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。它采用了词袋的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
对于语料库中的每篇文档,LDA定义了如下生成过程:
1) 对每一篇文档,从主题分布中抽取一个主题;
2) 从上述被抽到的主题所对应的单词分布中抽取一个单词;
3) 重复上述过程直至遍历文档中的每一个单词。
下例演示了LDA的使用。
12.5 流式K-means
当数据流到达,我们可能想要动态地估算cluster,并更新它们。该算法采用了小批量的K-means更新规则。对每一批数据,将所有的点分配到最近的cluster,并计算最新的cluster中心,然后更新每个cluster的公式为:
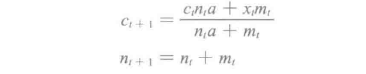
ci是前一次计算得到的cluster中心,ni是已经分配到cluster的点数,xi是从当前批次得到的cluster的新中心,mi是当前批次加入cluster的点数。衰减因子a可被用于忽略过去的数据;a=1时所有数据都从一开始就被使用;a=0时只有最近的数据将被使用。这类似于一个指数加权移动平均值。
下面的例子演示了流失K-means的使用。
13. 维数减缩
维数减缩是减少所考虑变量的数量的过程。维数减缩有两种方式:
- 奇异值分解;
- 主成分分析。
13.1 奇异值分解
奇异值分解将一个矩阵因子分解为三个矩阵U、Σ 和 V:
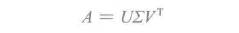
其中U是正交矩阵,其列被称为左奇异向量;Σ是对角矩阵,其对角线是非负的且以降序排列,因此被称为奇异值;V也是正交矩阵,其列被称为右奇异向量。
对于大的矩阵,除了顶部奇异值和它的关联奇异值,我们不需要完全分解。这样可以节省存储、去噪声和恢复矩阵的低秩结构。如果我们保持前7个顶部奇异值,那么最终的低秩矩阵为:

假设n小于m。奇异值和右奇异值向量来源于特征值和Gramian矩阵AτA的特征向量。矩阵存储左奇异向量U,通过矩阵乘法U = A(VS-1)计算。使用的实际方法基于计算成本自动被定义:
1) 如果(n < 100) 或者(k > n/2),我们首先计算Gramian矩阵,然后再计算其顶部特征向量并将特征向量本地化到Driver。这需要单次传递,在每个Executor和Driver上使用O(n2)的存储,并花费Driver上O(n2k)的时间。
2) 否则,将使用分布式的方式计算AτA的值,并且发送给ARPACK计算顶部特征向量。这需要O(k)次传递,每个Executor上使用O(n)的存储,在Driver上使用O(nk)的存储。
下面的例子演示了SVD的使用。
13.2 主成分分析
主成分分析是一种统计方法,此方法找到一个旋转,使得第一坐标具有可能的最大方差,并且每个随后的坐标都具有可能的最大方差。旋转矩阵的列被称为主成分。下面的例子演示了使用RowMatrix计算主成分。
14. 特征提取与转型
14.1 术语频率反转
术语频率反转是一个反映文集的文档中的术语的重要性,广泛应用于文本挖掘的特征矢量化方法。术语表示为t,文档表示为d,文集表示为D。术语频率TF(t,d)表示术语t在文档d中出现的频率,文档频率DF(t, D)表示包含术语t的文档数量。如果我们仅使用术语频率来测量重要性,则很容易过度强调术语出现的很频繁,而携带的关于文档的信息很少,例如a、the 和of等。如果术语非常频繁地跨文集出现,这意味着它并没有携带文档的特定信息。反转文档频率是一个术语提供了多少信息的数值度量:

|D| 表示文集中的文档总数。因为使用了对数,如果一个术语出现于所有的文档中,它的IDF值变0。需要注意的是,应用一个平滑项,以避免被零除。TF-IDF方法基于TF与IDF,它的公式如下:
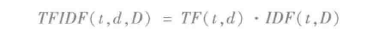
这里有一些术语频率和文档频率定义的变种。在MLlib中,为了使TF和IDF更灵活,将它们分开了,MLlib实现术语频率时使用了哈希。应用欧冠哈希函数将原始特征映射到了索引(术语),术语频率因此依赖于map的索引计算。这种方法避免了需要计算一个全局术语到索引图,这对于大型语料库开销会很大。但由于不同的原始特征在哈希后可能变为同样的术语,所以存在潜在的哈希冲突。为了降低碰撞的机会,我们可以增加目标特征的维度(即哈希表中的桶数)。默认的特征维度是220 = 1048576.
下面的例子演示了HashingTF的使用。
14.2 单词向量转换
Word2Vec计算由单词表示的分布式向量。分布式表征的主要优点是,类似的单词在矢量空间是接近的,这使得泛化小说模式更容易和模型估计更稳健。分布式向量表示被证实在许多自然语言处理应用中有用,例如,命名实体识别、消歧、解析、标记和机器翻译。
MLlib的Word2Vec实现采用了skip-gram模型。skip-gram的训练目标是学习单词的向量表示,其善于在同一个句子预测其上下文。给定了单词序列w1,w2,...,wτ,skip-gram模型的目标是最大化平均对数似然,公式如下:
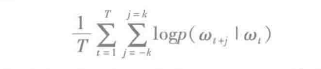
其中k是训练窗口的大小。每个单词w与两个向量uw和vw关联,并且由单独的向量来表示。通过给定的单词wj正确预测wi的概率是由softmax模型决定的。softmax模型如下:
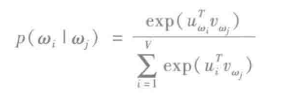
w表示词汇量。
由于计算logp(wi|wj)的成本与V成正比(V很容易就达到百万以上),所以softmax这种skip-gram模型是很昂贵的。为了加速Word2Vec计算,MLlib使用分级softmax,它可以减少计算logp(wi|wj) 复杂度到O(log(V))。
下面的例子演示了Word2Vec的使用,
14.3 标准尺度
通过缩放到单位方差和/或通过在训练集的样本上使用列摘要统计溢出均值使特征标准化,这是常见的预处理步骤。例如,当所有的特征都有单位方差和/或零均值时,支持向量机的RBF核或者L1和L2正规化线性模型通常能更好地工作。标准化可以提高在优化过程中的收敛速度,并且还可以防止在模型训练期间,非常大的差异会对特征发挥过大的影响。
StandardScaler的构造器有两个参数:
- withMean:默认false。用于缩放前求均值,这将建立一个密集的输出,所以不能在稀疏输入上正常工作,并将引发异常。
- withStd:默认true。缩放数据到标准单位误差。
以下例子演示了StandardScaler的使用。
14.4 正规化尺度
正规化尺度把样本划分为单位Lp范式,即维度。这是一种常见的对文本分类或集群化的操作。例如,两个L2正规化TF-IDF向量的点积是这些向量的余弦近似值。
设二维空间内有两个向量a和b,它们的夹角为θ(0≤θ≤π),则点积定义为以下实数:
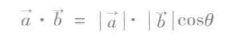
MLlib提供Normalizer支持正规化,Normalizer有以下构造参数:
p: 正规化到Lp空间,默认为2。
下面的例子演示了Normalizer的使用。
14.5 卡方特征选择器
ChiSqSelector用于卡方特征选择。它运转在具有分类特征的标签数据上。ChiSqSelector对基于分类进行独立卡方测试的特征排序,并且过滤(选择)最接近标签的顶部特征。
ChiSqSelector有以下构造器参数:
numTopFeatures:选择器将要过滤(选择)的顶部特征数量。
下边的例子演示了ChiSqSelector的使用。
14.6 Hadamard积
ElementwiseProduct采用逐个相乘的方式,使用给定的权重与每个输入向量相乘。换言之,它采用一个标量乘法器扩展数据集的每一列。这表示Hadamard积对输入向量v,使用转换向量w,最终生成一个结果向量。Hadamard积可由以下公式表示:
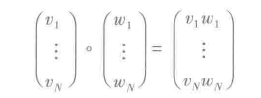
ElementwiseProduct的构造器参数为:
w:转换向量。
下面代码演示了ElementwiseProduct的使用。
15. 频繁模式挖掘
分析大规模数据集的第一个步骤通常是挖掘频繁项目、项目集、亚序列或其他子结构,这在数据挖掘中作为一个活跃的研究主题已多年了。其数学原理读者可以取维基百科了解。MLlib提供了频繁模式挖掘的并行实现——FP-growth算法。
FP-growth
给定一个交易数据集,FP-growth的第一步骤是计算项目的频率,并确定频繁项目。FP-growth虽然与Apriori类算法有相同的设计目的,但是FP-growth的第二步使用后缀树(FP树)结构对交易数据编码且不会显式生成候选集(生成候选集通常开销很大)。第二步之后,就可以从FP树中抽取频繁项目集。MLlib中实现了FP-growth的平行版本,叫做PFP。PFP可以将FP-growth的工作分发到其他机器,比单机运行有更好的扩展性。
FPGrowth有以下参数:
- minSupport:项目集被确定为频繁的最小数量。
- numPartitions:分发任务的数量。
下面的例子演示了FPGrowth的使用。
16. 预言模型标记语言
预言模型标记是一种基于XML的语言,它能够定义和共享应用程序之间的预测模型。
MLlib支持将模型导出为预言模型标记语言。表11-6列出了MLlib模型导出为PMML的相应模型。


下面的例子演示了将KMeamsModel导出为PMML格式。
17. 管道
Spark1.2增加了一个新包spark.ml,目的是提供一套高层次的API,帮助用户创建、调试机器学习的管道。spark.ml的标准化API用于将多种机器学习算法组合到一个管道或工作流中。下面列出了Spark ML API的主要概念:
- ML DataSet:由Hive table或者数据源的数据构成的可容纳各种数据类型的DataFrame作为数据集。例如,数据集可以由不同的列分别存储文本、特征向量、标签和预测值。
- Transformer:是一种将DataFrame转换为另一个DataFrame的算法。例如,ML模型是一个将特征RDD转换为预测值RDD的Transformer。
- Estimator:适用于DataFrame,并生成一个Transformer。例如,学习算法是一个在数据集上训练并生成一个模型的Estimator。
- Pipeline:链接多个Transformer和Estimator,一起构成ML的工作流。
- Param:所有Transformer和Estimator用于指定参数的通用API。
17.1 管道工作原理
机器学习中,运行一系列的算法取处理数据或者从数据学习的场景是很常见的。例如,一个简单的文本文档处理工作流可能包含以下阶段:
1) 将文档文本切分成单词;
2) 将文档的单词转换为数字化的特征向量;
3) 使用特征向量和标签学习一个预测模型。
Spark ML以一系列按序运行的PipelineStage组成的管道来表示这样的工作流。这一系列的Stage要么是Transformer,要么是Estimator。数据集通过管道中的每个Stage都会被修改。比如Transformer的transform()方法将在数据集上被调用,Estimator的fit()方法被调用生成一个Transformer,然后此Transformer的transform()方法也将在数据集上被调用。图11-9展示了简单文本文档工作流例子使用管道的处理流程。
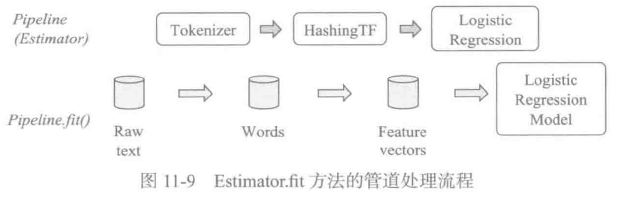
图11-9说明整个管道由3个Stage组成。Tokenizer和HashingTF都是Transformer,LogisticRegression是Estimator。每个圆柱体都说明它本身是一个DataFrame。整个处理流程如下:
1) 在由原生文本文档构成的原始数据集上应用Pipeline.fit()方法。
2) Tokenizer.transform()将原生文本文档切分为单词,并向数据集增加单词列。
3) HashingTF.transform()将单词列转换为特征向量,并向数据集增加向量列。
4) 因为LogisticRegression是Estimator,所以管道第一次调用LogisticRegression.fit()生成了LogisticRegressionModel。如果管道中还有更多的Stage,将会传递数据集到下一个Stage之前在数据集上调用LogisticRegressionModel的transform()。
管道本身是一个Estimator。因此调用Pipeline的fit()方法最后生成了PipelineModel,PipelineModel也是一个Transformer。这个PipelineModel会在测试时间使用,测试过程如图11-10所示。

图11-10说明PipelineModel的测试过程与图11-9的管道有相同的Stage数量。但是图11-9的管道中的所有Estimator在此时都已经变为Transformer。当在测试数据集上调用PipelineModel的transform()方法时,数据在管道中按序通过。每个Stage的transform()方法都会更新数据集,并将数据集传递给下一个Stage。
刚才介绍的例子中,管道是线性的,即每个stage都使用由上一个stage生产的数据。只要数据流图构成了DAG,它就有可能不是线性的。如果管道构成了DAG,那么这些Stage就必须指定拓扑顺序。
17.2 管道API介绍
Spark ML的Transformer和Estimator指定参数具有统一的API。有两种方式指定参数:
- 给实例设置参数。例如,Ir是LogisticRegression的实例,可以调用lr.setMaxIter(10)使得调用lr.fit()时最多迭代10次。
- 传递ParamMap给fit()或者transform()方法。通过这种方式指定的参数值将会覆盖所有由set方式指定的参数值。
下面的例子演示了Estimator、Transformer和Param的使用。
17.3 交叉验证
模型选择是Spark ML中很重要的课题。通过对整个管道的调整,而不是对管道中的每个元素的调整,促成对管道模型的选择。当前spark.ml使用CrossValidator支持模型选择。CrossValidator本身携带一个Estimator、一组ParamMap以及一个Evaluator。CrossValidator开始先将数据集划分为多组,每组都由训练数据集和测试数据集组成。例如,需要划分3组,那么CrossValidator将生成三个数据集对(训练,测试)。每一对都使用2/3的数据用于训练,1/3的数据用于测试。CrossValidator会迭代ParamMap的集合。对于每个ParamMap,它都会训练给定的Estimator并使用给定的Evaluator计算。ParamMap将会产出最佳的计算模型(对多个数据集对求平均),CrossValidator最终使用这个最佳的ParamMap和整个数据集拟合Estimator。下边的例子演示了CrossValidator的使用。使用ParamGridBuilder构造网格参数:hashingTF.numFeatures有3个值,r.regParam有2个值。这个网格将会有3*2=6个参数设置供CrossValidator选择。使用了2组数据集对,那么一共有(3*2)*2=12种不同的模型被训练。
下面的代码演示了交叉验证的使用。
Spark MLlib 机器学习的更多相关文章
- Spark MLlib机器学习
前言 Spark MLlib是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器.
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Spark MLlib机器学习(一)——决策树
决策树模型,适用于分类.回归. 简单地理解决策树呢,就是通过不断地设置新的条件标准对当前的数据进行划分,最后以实现把原始的杂乱的所有数据分类. 就像下面这个图,如果输入是一大堆追求一个妹子的汉子,妹子 ...
- 《Spark MLlib 机器学习实战》1——读后总结
1 概念 2 安装 3 RDD RDD包含两种基本的类型:Transformation和Action.RDD的执行是延迟执行,只有Action算子才会触发任务的执行. 宽依赖和窄依赖用于切分任务,如果 ...
- Spark Mllib里如何生成KMeans的训练样本数据、生成线性回归的训练样本数据、生成逻辑回归的训练样本数据和其他数据生成
不多说,直接上干货! 具体,见 Spark Mllib机器学习(算法.源码及实战详解)的第2章 Spark数据操作
- Spark Mllib里如何采用保序回归做回归分析(图文详解)
不多说,直接上干货! 相比于决策树,保序回归的应用范围没有决策树算法那么广泛. 特别在数据处理较为庞大的时候,采用保序回归做回归分析,可以极大地节省资源,从而提高计算效率. 保序回归的思想,是对数据进 ...
- Spark Mllib里的卡方检验
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
- Spark Mllib里的分层抽样(使用map作为分层抽样的数据标记)
不多说,直接上干货! 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mllib数理统计
- Spark Mllib里的如何对单个数据集用斯皮尔曼计算相关系数
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
随机推荐
- os x && linux 文件传输基础命令
一.从服务器下载文件到本机 1.修改文件所属 由于只能下载文件所属为自己的文件,所以要做修改文件所属的操作. chown hudelei /opt/logs/tomcat/app/tomcat_stk ...
- Atcoder 乱做
最近感觉自己思维僵化,啥都不会做了-- ARC103 F Distance Sums 题意 给定第 \(i\) 个点到所有点的距离和 \(D_i\) ,要求构造一棵合法的树.满足第 \(i\) 个点到 ...
- 【CF446C】DZY Loves Fibonacci Numbers (线段树 + 斐波那契数列)
Description 看题戳我 给你一个序列,要求支持区间加斐波那契数列和区间求和.\(~n \leq 3 \times 10 ^ 5, ~fib_1 = fib_2 = 1~\). Solut ...
- 【BZOJ5300】[CQOI2018]九连环 (高精度,FFT)
[BZOJ5300][CQOI2018]九连环 (高精度,FFT) 题面 BZOJ 洛谷 题解 去这里看吧,多么好 #include<iostream> #include<cstdi ...
- hexo+next主题目录解析
默认目录结构: . ├── .deploy ├── public ├── scaffolds ├── scripts ├── source | ├── _drafts | └── _posts ├── ...
- [2017-8-02]Android Learning Day9
Layout动画效果 为布局添加简单的动画效果 public class MainActivity extends AppCompatActivity { @Override protected vo ...
- 洛谷P4219 大融合
LCT新姿势:维护子树信息. 不能带修,子树修改就要toptree了... 题意:动态加边,求子树大小. 解: 维护子树信息只要额外维护虚边连的儿子的信息即可.这里把siz的定义变成子树大小. 哪里会 ...
- @Async的简单用法总结
前言: 在Java应用中,绝大多数情况下都是通过同步的方式来实现交互处理的:但是在处理与第三方系统交互的时 候,容易造成响应迟缓的情况,之前大部分都是使用多线程来完成此类任务,其实,在Spring 3 ...
- anaconda的安装教程和使用方法
一.anaconda安装方法: 1.下载: anaconda官方下载地址:https://www.anaconda.com/download/ 2.安装: 可以自己指定路劲,也可以选择默认安装,最后记 ...
- bcftools将vcf生成bgzip和index格式
利用bcftools软件将vcf格式生成gz格式和index格式,需要用到“-Oz”和“index”命令,具体如下: /bcftools-1.8/bin/bcftools view ExAC.vcf ...