Python全栈开发记录_第十篇(反射及选课系统练习)
反射机制:反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块中寻找指定函数,对其进行操作。也就是利用字符串的形式去对象(模块)中操作(查找or获取or删除or添加)成员,一种基于字符串的事件驱动。
上面对反射的解释估计没听懂吧,这样我们一步一步来,看为啥我们会使用到反射机制以及如何使用。
我们在访问网站的时候,比如商城的时候,我们访问不同页面是不是url后缀会不同,如果点击首页,则会跳转至xxx/index,下图所示:
# func.py文件内容
def index():
print("首页") def login():
print("登录页面")
# test.py文件内容
import func def run():
input_str = input(">>>")
# 根据不同的url,执行不同的函数,获得不同的页面
if input_str == "index":
func.index()
elif input_str == "login":
func.login()
else:
print("") if __name__ == "__main__":
run()
上面的写法是比较笨拙的一种写法, 如果func.py内有上千个函数呢?因此这就引用到了反射的概念,将代码修改,如下:
import func def run():
input_str = input(">>>")
# 说明:判断对象object是否包含名为name的特性(hasattr是通过调用getattr(ojbect, name)是否抛出异常来实现的),有则返回true,否则返回false
if hasattr(func, input_str):
# 从object(func模块)中取成员(input_str函数)
f = getattr(func, input_str)
f()
else:
print("") if __name__ == "__main__":
run()
python的四个重要内置函数:getattr、hasattr、delattr和setattr较为全面的实现了基于字符串的反射机制。他们都是对内存内的模块进行操作,并不会对源文件进行修改。
r = hasattr(commons,xxx)判断某个函数或者变量是否存在
print(r) setattr(commons,'age',18) 给commons模块增加一个全局变量age = 18,创建成功返回none setattr(config,'age',lambda a:a+1) //给模块添加一个函数 delattr(commons,'age')//删除模块中某个变量或者函数
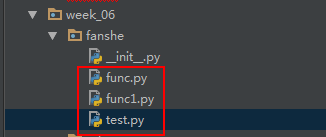
但是我们问题又来了,上面的例子是在某个特定的目录结构下才能正常实现的,也就是func和test模块在同一目录下,并且所有的页面处理函数都在test模块内。但在现实使用环境中,页面处理函数往往被分类放置在不同目录的不同模块中,难道我们要在test模块里写上一大堆的import 语句逐个导入func还有其它模块吗?要是有上千个这种模块呢?如下图:
刚才我们分析完了基于字符串的反射,实现了动态的函数调用功能,我们不禁会想那么能不能动态导入模块呢?这完全是可以的!python提供了一个特殊的方法:__import__(字符串参数)。通过它,我们就可以实现类似的反射功能。__import__()方法会根据参数,动态的导入同名的模块。
def run():
input_str = input(">>>") # 输入func1/index1
m, f = input_str.split('/')
# 导入了m这个变量保存的字符串同名的模块,并将它赋值给obj变量
obj = __import__(m)
if hasattr(obj, f):
fun = getattr(obj, f)
fun()
else:
print("") if __name__ == "__main__":
run()
不过如果目录结构变成了这样呢?我们要导入other下面的呢?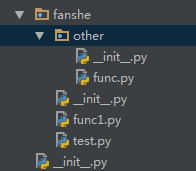
def run():
input_str = input(">>>") # func/index
m, f = input_str.split('/')
# 导入了m这个变量保存的字符串同名的模块,并将它赋值给obj变量
obj = __import__("other."+m, fromlist=True) # 如果不加上fromlist=True,只会导入other目录
if hasattr(obj, f):
fun = getattr(obj, f)
fun()
else:
print("") if __name__ == "__main__":
run()
至此,动态导入模块的问题基本都解决了,只剩下最后一个,那就是万一用户输入错误的模块名呢?比如用户输入了somemodules/find,由于实际上不存在somemodules这个模块,必然会报错!那有没有类似上面hasattr内置函数这么个功能呢?答案是没有!碰到这种,你只能通过异常处理来解决。
练习:选课系统
一、选课系统(面向对象作业) 角色:学校、学员、课程、讲师
要求:
. 创建北京、上海 所学校
. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开
. 课程包含,周期,价格,通过学校创建课程
. 通过学校创建班级, 班级关联课程、讲师
. 创建学员时,选择学校,关联班级
. 创建讲师角色时要关联学校,
. 提供两个角色接口
6.1 学员视图, 可以注册, 交学费, 选择班级,
6.2 讲师视图, 讲师可管理自己的班级, 上课时选择班级, 查看班级学员列表 , 修改所管理的学员的成绩
6.3 管理视图,创建讲师, 创建班级,创建课程
. 上面的操作产生的数据都通过pickle序列化保存到文件
该练习思路参考:http://www.cnblogs.com/lianzhilei/p/5985333.html
Python全栈开发记录_第十篇(反射及选课系统练习)的更多相关文章
- Python全栈开发记录_第三篇(linux(ubuntu)的操作)
该篇幅主要记录linux的操作,常见就不记录了,主要记录一些不太常用.难用或者自己忘记了的点. 看到https://www.cnblogs.com/resn/p/5800922.html这篇幅讲解的不 ...
- Python全栈开发记录_第八篇(模块收尾工作 json & pickle & shelve & xml)
由于上一篇篇幅较大,留下的这一点内容就想在这里说一下,顺便有个小练习给大家一起玩玩,首先来学习json 和 pickle. 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过, ...
- Python全栈开发记录_第四篇(集合、函数等知识点)
知识点1:深拷贝和浅拷贝 非拷贝(=赋值:数据完全共享,内存地址一样,修改一个另一个也变化) 浅拷贝:数据半共享(复制其数据独立内存存放,但是只拷贝成功第一层)像[[1,2],3,4]如果修改列表中列 ...
- Python全栈开发记录_第七篇(模块_time_datetime_random_os_sys_hashlib_logging_configparser_re)
这一篇主要是学习python里面的模块,篇幅可能会比较长 模块的概念:在Python中,一个.py文件就称之为一个模块(Module). 模块一共三种: python标准库 第三方模块 应用程序自定义 ...
- Python全栈开发记录_第六篇(生成器和迭代器)
说生成器之前先说一个列表生成式:[x for x in range(10)] ->[0,1,2....,9]这里x可以为函数(因为对python而言就是一个对象而已),range(10)也可 ...
- Python全栈开发记录_第五篇(装饰器)
单独记录装饰器这个知识点是因为这个知识点是非常重要的,必须掌握的(代码大约150行). 了解装饰器之前要知道三个知识点 作用域,上一篇讲到过顺序是L->E->G->B 高阶函数: 满 ...
- Python全栈开发记录_第一篇(循环练习及杂碎的知识点)
Python全栈开发记录只为记录全栈开发学习过程中一些难和重要的知识点,还有问题及课后题目,以供自己和他人共同查看.(该篇代码行数大约:300行) 知识点1:优先级:not>and 短路原则:a ...
- Python全栈开发记录_第九篇(面向对象(类)的学习)
有点时间没更新博客了,今天就开始学习类了,今天主要是面向对象(类),我们知道面向对象的三大特性,那就是封装,继承和多态.内容参考该博客https://www.cnblogs.com/wupeiqi/p ...
- Python全栈开发记录_第二篇(文件操作及三级菜单栏增删改查)
python3文件读写操作(本篇代码大约100行) f = open(xxx.txt, "r", encoding="utf-8") 不写“r”(只读)默认是只 ...
随机推荐
- spring AOP知识点总结以及日志的输出
AOP的作用就是在基于OCP在不改变原有系统核心业务代码的基础上动态添加一些扩展功能.通常应用于日志的处理,事务处理,权限处理,缓存处理等等 首先,使用AOP需要添加的依赖有:spring-conte ...
- Spring ConditionalOnProperty
Spring Annotation @ConditionalOnProperty spring doc解释 @Conditional: Indicates that a component is on ...
- laravel 修改时邮箱字段唯一性验证时忽略指定 ID
- 各种BUG
1.下载VS2005,版本太低和win10不好兼容 2.由于提前下载好了,visual studio2010,在下载VS2012过程中提示说检测到要更新VS2010才可以,百度后,返回安装上一步,取消 ...
- ImportError: dynamic module does not define module export function (PyInit__sqlite3)
使用python3.6 中的django-admin创建项目的时候报错 ImportError: dynamic module does not define module export functi ...
- sql注入-输入’or 1=1#
比如:在用户名输入框中输入:’or 1=1#,密码随便输入,这时候的合成后的SQL查询语句为: select * from users where username='' or 1=1#' a ...
- Java技术之如何保证同一资源被多个线程并发访问时的完整性?
常用的同步方法是采用信号或加锁机制,保证资源在任意时刻至多被一个线程访问.Java语言在多线程编程上实现了完全对象化,提供了对同步机制的良好支持. 在Java中一共有四种方法支持同步,其中前三个是同步 ...
- php session的一些操作
<?php /** * Session控制类 */ class Session{ /** * 设置session * @param String $name session name * @pa ...
- Django学习笔记之视图高级-错误处理
错误处理 在一些网站开发中.经常会需要捕获一些错误,然后将这些错误返回比较优美的界面,或者是将这个错误的请求做一些日志保存.那么我们本节就来讲讲如何实现. 常见的错误码 404:服务器没有指定的url ...
- html 出现粒子线条,鼠标移动会以鼠标为中心吸附的特效之canvas-nest.js插件
我在网上看到一个很炫酷,很有趣的特效,网页上会有很多移动的粒子和线条,鼠标经过时会以鼠标为中心吸附过来,如果时间够久,会形成一个类似震动的.带辐条的车轮子的东西. 网上搜了一下,源码是github里面 ...