python使用tesseract-ocr完成验证码识别(模型训练和使用部分)
一、Tesseract训练
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
1、用jTessBoxEditor把要训练样本图片文件合并成tif文件(样本图片一定要为有效的格式图片)
运行jTessBoxEditor程序,界面如下:

点击顶栏的Tools选项,选择Merge TIFF.. 进入你要训练的样本图片所在的目录,点击Ctrl+Alt+A,选择所有图片点击打开:

然后保存文件名到指定目录,我这里保存的文件名为: langyp.font.exp0.tif

2、生成Box文件
打开cmd,到你langyp.font.exp0.tif文件所在目录,执行:
tesseract langyp.font.exp0.tif langyp.font.exp0 batch.nochop makebox

结果生成了langyp.font.exp0.box文件
3、 对样本图片用jTessBoxEditor工具进行矫正
点击jTessBoxEditor工具的Box Editor选项,点击下方的open选项,打开刚刚生成的langyp.font.exp0.tif文件,结果如下:

右侧为对应的Box文件数据,如果char的字符和当前的样本图片一致时就进行矫正,修改char里的字符,然后进行save,这样就矫正了,进入下张样本图片时,同样,矫正后点击save,当所有样本图片都矫正了,这一步也就完成了
4、生成font_properties文件(该文件没有后缀名)
在命令行执行:echo font 0 0 0 0 0 >font_properties
结果生成了font_properties文件
内容为字体名font,后面带5个0,分别代表字体的粗体、斜体等属性,这里全部是0

5、生成.tr训练文件
在命令行执行: tesseract langyp.font.exp0.tif langyp.font.exp0 -l eng -psm 7 nobatch box.train

6、生成字符集文件
在命令行执行 : unicharset_extractor langyp.font.exp0.box

结果生成了unicharset文件
7、生成shape文件
在命令行执行 : shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.font.exp0.tr
结果生成了shapetable文件和langyp.unicharset文件

8、生成聚集字符特征文件
在命令行执行: mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.font.exp0.tr

结果生成了pffmtable,inttemp,unicharset文件
9、生成字符正常化特征文件
在命令行执行: cntraining langyp.font.exp0.tr

结果生成了normproto文件
10、把h,i步骤生成的文件用rename命令进行更名
在命令行执行:
**rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable**

11、合并训练文件
在命令行执行: combine_tessdata fontyp.

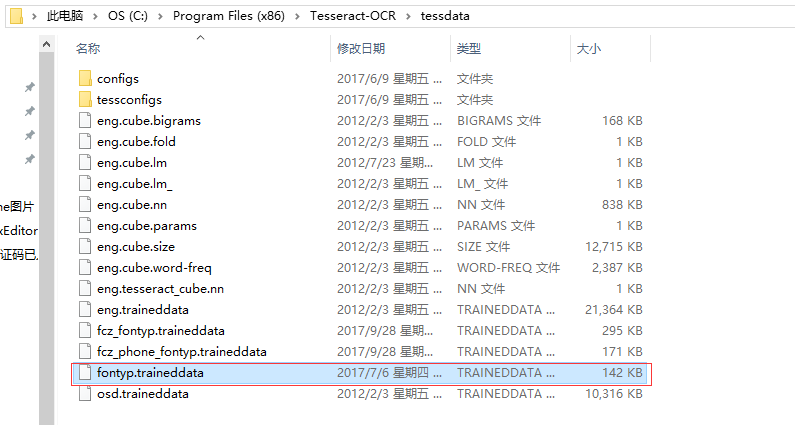
12、将fontyp.traineddata文件拷贝至Tesseract-OCR文件夹里的tessdata语言包文件夹里
windows下面:
linux下面:
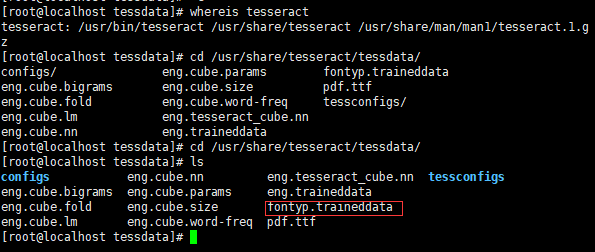
输入命令查找安装文件夹:whereis tesseract
然后拷贝到图上的地址:
二、Python验证码识别代码

python使用tesseract-ocr完成验证码识别(模型训练和使用部分)的更多相关文章
- 人脸检测及识别python实现系列(3)——为模型训练准备人脸数据
人脸检测及识别python实现系列(3)——为模型训练准备人脸数据 机器学习最本质的地方就是基于海量数据统计的学习,说白了,机器学习其实就是在模拟人类儿童的学习行为.举一个简单的例子,成年人并没有主动 ...
- tensorflow训练验证码识别模型
tensorflow训练验证码识别模型的样本可以使用captcha生成,captcha在linux中的安装也很简单: pip install captcha 生成验证码: # -*- coding: ...
- 【转】CNN+BLSTM+CTC的验证码识别从训练到部署
[转]CNN+BLSTM+CTC的验证码识别从训练到部署 转载地址:https://www.jianshu.com/p/80ef04b16efc 项目地址:https://github.com/ker ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- CNN+BLSTM+CTC的验证码识别从训练到部署
项目地址:https://github.com/kerlomz/captcha_trainer 1. 前言 本项目适用于Python3.6,GPU>=NVIDIA GTX1050Ti,原mast ...
- python截图+百度ocr(图片识别)+ 百度翻译
一直想用python做一个截图并自动翻译的工具,恰好最近有时间就在网上找了资料,根据资料以及自己的理解做了一个简单的截图翻译工具.整理一下并把代码放在github给大家参考.界面用python自带的G ...
- 利用keras进行手写数字识别模型训练,并输出训练准确度
from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.lo ...
- Mac python Tesseract 验证码识别
Tesseract 简介 Tesseract(/'tesərækt/) 这个词的意思是"超立方体",指的是几何学里的四维标准方体,又称"正八胞体".不过这里要讲 ...
- Pyhthon爬虫其之验证码识别
背景 现在的登录系统几乎都是带验证手段的,至于验证的手段也是五花八门,当然用的最多的还是验证码.不过纯粹验证码识已经是很落后的东西了,现在比较多见的是滑动验证,滑动拼图验证(这个还能往里面加广告).点 ...
- python3.7验证码识别MuggleOCR,为什么总是报错
先来看看MuggleOCR简介(白嫖)这是一个为麻瓜设计的本地OCR模块只需要简单几步操作即可拥有两大通用识别模块,让你在工作中畅通无阻. 这套模型是基于 https://github.com/ker ...
随机推荐
- Zabbix JMX之tomcat监控
工作原理: 1.JAVA-GATEWAY Zabbix本身不支持直接监控Java,在zabbix 1.8以前,只能使用Zapcat来做代理监控,而且要修改源代码,非常麻烦.所有后来为了解决这个监控问 ...
- IDEA2017版本打可运行jar包并运行
一.打JAR包 JAR:From modules with dependencies 将依赖一起打包 一般依赖放在与xx.jar同级的libs文件夹中 敲黑板,下图第一个框是输出jar包的位置,第二 ...
- play @Before 的使用
用play 框架也又一段时间了,也算是有了些经验,今天就总结下@Before 的使用. 这个注解能主要在控制器中使用,用于在Action 前进行拦截 unless 表示不用拦截 的Action @Be ...
- mysql__存储过程
1.存储过程相当于我们学的各种高级语言的函数,既然是函数就可能有参数,先介绍参数类型: 存储过程主要包含三种参数类型,注意我说的不是数据类型(INT.VARCHAR) 第一种:IN输入参数:表示这种参 ...
- Lintcode360 Sliding Window Median solution 题解
[题目描述] Given an array of n integer, and a moving window(size k), move the window at each iteration f ...
- 进入TP-Link路由器之后利用快捷键F12查看星号路由密码的方法
今天又破解了几个路由器,这两张图片是大多数路由器如TP-LINK路由器查看拨号圆点密码的方法.
- php 图片合成时文字颜色丢失
最近在做图片合成的时候无意间发现文字颜色丢失了,仔细找了以后才发现原来是因为图片格式的原因 当图片是png图片时文字的颜色就变成了白色的,So.........去你妹的png,用jpg吧! $dest ...
- python爬微信公众号前10篇历史文章(3)-lxml&xpath初探
理解lxml以及xpath 什么是lxml? python中用来处理XML和HTML的library.与其他相比,它能提供很好的性能, 并且它支持XPath. 具体可以查看官方文档->http: ...
- c++代码的编译
1.gcc和g++ 1.1搞清楚几个名字 GCC :GNU Compiler Collection (GUN编译套件),可以编译c,c++,java,objective-c,F ...
- python中干掉tornado的连接失败日志
用了tornado真的是比较舒服,很多事都为你做好了. 但也有不令人满意的地方--对于我这个洁癖来说,自动给我的控制台打印不受我控制的信息是不能忍受的. 连接到一个新的地方,如果失败,tornado会 ...