偏差-方差均衡(Bias-Variance Tradeoff)
众所周知,对于线性回归,我们把目标方程式写成: 。
。
(其中,f(x)是自变量x和因变量y之间的关系方程式, 表示由噪音造成的误差项,这个误差是无法消除的)
表示由噪音造成的误差项,这个误差是无法消除的)
对y的估计写成: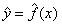 。
。
 就是对自变量和因变量之间的关系进行的估计。一般来说,我们无从得之自变量和因变量之间的真实关系f(x)。假设为了模拟的缘故,我们设置了它们之间的关系(这样我们就知道了它们之间的真实关系),但即便如此,由于有这个irreducible error,我们还是无法得之真正的y是多少。当然,这并没有关系。因为我们想要知道的就是自变量和因变量之间的一般性关系,不需要把噪音计算进去。
就是对自变量和因变量之间的关系进行的估计。一般来说,我们无从得之自变量和因变量之间的真实关系f(x)。假设为了模拟的缘故,我们设置了它们之间的关系(这样我们就知道了它们之间的真实关系),但即便如此,由于有这个irreducible error,我们还是无法得之真正的y是多少。当然,这并没有关系。因为我们想要知道的就是自变量和因变量之间的一般性关系,不需要把噪音计算进去。
通常我们使用一组训练数据让某个算法来进行学习,然后得到一个模型,这个模型能使损失函数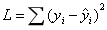 最小。但是我们想要知道的是模型的泛化能力,也就是说我们需要模型在所有数据上都表现良好,而不仅仅是训练数据。假设我们知道所有的数据,然后把这些数据分成n组,我们把这n组数据在模型上进行测试,得到n个不同的损失函数。如果这些损失函数的平均值最小,也就是说真实数值和估计数值之间的差异平方的期望值最小,那就说明这个模型最理想。
最小。但是我们想要知道的是模型的泛化能力,也就是说我们需要模型在所有数据上都表现良好,而不仅仅是训练数据。假设我们知道所有的数据,然后把这些数据分成n组,我们把这n组数据在模型上进行测试,得到n个不同的损失函数。如果这些损失函数的平均值最小,也就是说真实数值和估计数值之间的差异平方的期望值最小,那就说明这个模型最理想。
此期望值的公式如下:
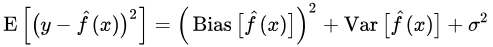
其中:
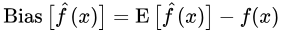
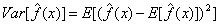
σ2是的方差
公式的推导过程如下(为简便起见,f(x)缩写成f,f(x)-hat缩写成f-hat):
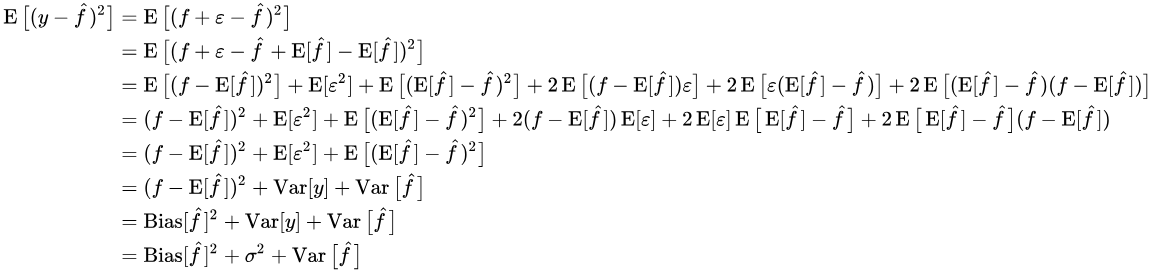
翻译成人话就是:
总泛化误差(Total Generalization Error) = 偏差(Bias) + 方差(Variance) + 无法消除的误差项(Irreducible Error)
我们要使总误差最小,就要想办法减少偏差和方差,因为最后一项是无法减少的。
现在让我们来看一下偏差和方差到底是什么。
偏差(bias)是指由于错误的假设导致的误差,比如说我们假设只有一个自变量能影响因变量,但其实有三个;又比如我们假设自变量和因变量之间是线性关系,但其实是非线性关系。其描述的是期望估计值和真实规律之间的差异。
方差(variance)是指通过n组训练数据学习拟合出来的结果之间的差异。其描述的是估计值和平均估计值之间差异平方的期望。
如果看了以上内容还是有点懵,那么看下面这张经典的图便可以理解:
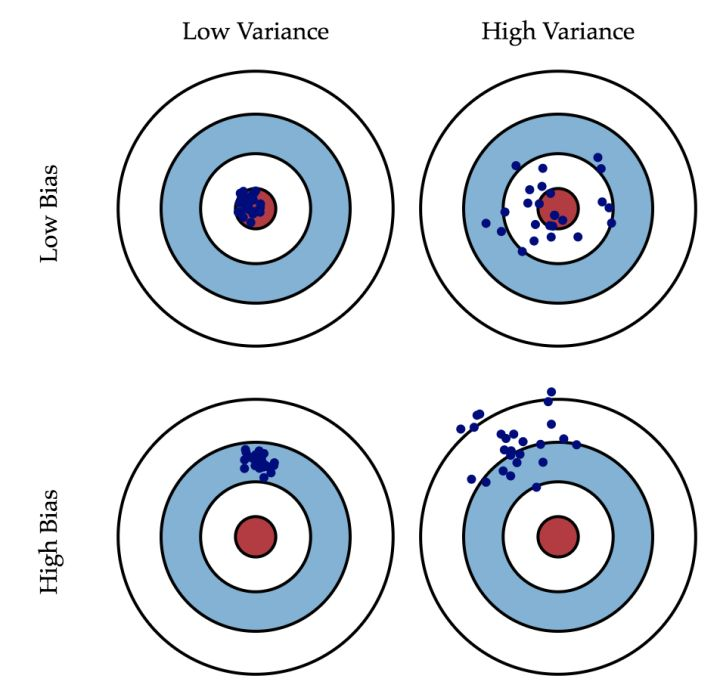
学习n次就相当于投靶n次。如果偏差小,同时方差又小,那就相当于每次都几乎正中靶心。这样的结果当然是最好的。如果偏差大,即使方差再小,那么投靶结果也还是离靶心有一段距离。反之,如果偏差小,但是方差很大,那么投靶结果将散布在靶心四周。
有人也许会说,只要偏差小,就算方差大一点也无所谓啊,只要把多次学习的结果平均一下,还是可以预测准确的;而如果偏差大的话,那就是连基本面都错了。但是这种认为减少偏差比减少方差更重要的想法是错误的,因为通常我们只有一组数据,而不是n组,我们的模型是依据我们已有的那组数据得出来的。因此,偏差和方差同样重要。
那么有没有可能让偏差小的同时又让方差小呢?这样我们不就能得到最好的结果了吗?但通过多次实验表明,事实不如人愿。

图1
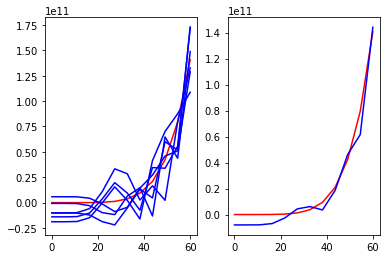
图2
红线是真实规律,左图蓝线是多次学习的结果,右图蓝线是平均结果。
图1是使用简单模型多次拟合的结果,可以看到其多次拟合的结果之间相差不大,但是平均结果和真实规律相差较大(也就是方差小,偏差大);图2是使用较复杂的模型多次拟合的结果,可以看到其多次拟合的结果之间相差较大,但是平均结果和真实规律相差不大(也就是方差大,偏差小)。
总结来说就如下图所示,简单的模型偏差大,方差小;复杂的模型则相反,偏差小,方差大。随着模型越来越复杂,偏差逐渐减小,方差逐渐增大。我们发现无法在减少偏差的同时也减少方差。因此,我们需要找到一个折中的方案,即找到总误差最小的地方,这就叫做偏差-方差均衡(Bias-Variance Tradeoff)。

偏差-方差均衡这一概念贯穿整个机器学习,你随处都能见到它的身影。因此理解这一概念非常重要。
那么怎样才知道自己的模型是偏差大还是方差大呢?
高偏差:训练集误差大,验证集误差和训练集误差差不多大
高方差:训练集误差小,验证集误差非常大
又是如何解决高偏差或高方差问题呢?
高偏差问题:1,使用更复杂的模型
2,加入更多的特征
高方差问题:1,获取更多的数据
2,减少特征
3,正则化
以下是流程图:

偏差-方差的分解公式只在基于均方误差的回归问题上可以进行推导,但通过实验表明,偏差-方差均衡无论是对回归问题还是分类问题都是适用的。
偏差-方差均衡(Bias-Variance Tradeoff)的更多相关文章
- 【笔记】偏差方差权衡 Bias Variance Trade off
偏差方差权衡 Bias Variance Trade off 什么叫偏差,什么叫方差 根据下图来说 偏差可以看作为左下角的图片,意思就是目标为红点,但是没有一个命中,所有的点都偏离了 方差可以看作为右 ...
- 训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合
1. 训练.验证.测试集 对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分: 训练集(train set):用训练集对算法或模型进行训练过程: 验证集(d ...
- 偏差和方差以及偏差方差权衡(Bias Variance Trade off)
当我们在机器学习领域进行模型训练时,出现的误差是如何分类的? 我们首先来看一下,什么叫偏差(Bias),什么叫方差(Variance): 这是一张常见的靶心图 可以看左下角的这一张图,如果我们的目标是 ...
- 机器学习总结-bias–variance tradeoff
bias–variance tradeoff 通过机器学习,我们可以从历史数据学到一个\(f\),使得对新的数据\(x\),可以利用学到的\(f\)得到输出值\(f(x)\).设我们不知道的真实的\( ...
- Bias/variance tradeoff
线性回归中有欠拟合与过拟合,例如下图: 则会形成欠拟合, 则会形成过拟合. 尽管五次多项式会精确的预测训练集中的样本点,但在预测训练集中没有的数据,则不能很好的预测,也就是说有较大的泛化误差,上面的右 ...
- 2.9 Model Selection and the Bias–Variance Tradeoff
结论 模型复杂度↑Bias↓Variance↓ 例子 $y_i=f(x_i)+\epsilon_i,E(\epsilon_i)=0,Var(\epsilon_i)=\sigma^2$ 使用knn做预测 ...
- 机器学习理论知识部分--偏差方差平衡(bias-variance tradeoff)
摘要: 1.常见问题 1.1 什么是偏差与方差? 1.2 为什么会产生过拟合,有哪些方法可以预防或克服过拟合? 2.模型选择例子 3.特征选择例子 4.特征工程与数据预处理例子 内容: 1.常见问题 ...
- [转]理解 Bias 与 Variance 之间的权衡----------bias variance tradeoff
有监督学习中,预测误差的来源主要有两部分,分别为 bias 与 variance,模型的性能取决于 bias 与 variance 的 tradeoff ,理解 bias 与 variance 有助于 ...
- On the Bias/Variance tradeoff in Machine Learning
参考:https://codesachin.wordpress.com/2015/08/05/on-the-biasvariance-tradeoff-in-machine-learning/ 之前一 ...
随机推荐
- 使用LR编写windows sockets协议xml报文格式脚本实战
以下是测试脚本Demo: #include "lrs.h" Action() { char * resultCode;//结果代码 char * time; //系统时间 char ...
- relief中visio图出现问题处理
需安装visio2010版本, 安装DsoFramer_KB311765_x86.exe 管理员权限打开cmd,运行regsvr32 dsoframer.ocx
- 无需***,轻松提速 Github
无需***,轻松提速 Github 众所周知,Github 是全球程序员最喜欢访问的网站之一,但是在国内,会很容易出现一个水土不服的局面 -- 下载不了(稍微大一点中途就报错了),下载速度慢 .... ...
- 基于Springboot集成security、oauth2实现认证鉴权、资源管理
1.Oauth2简介 OAuth(开放授权)是一个开放标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OAu ...
- wordpress的excerpt()函数
问题:在wordpres中的single页面,本身引用的<?php the_excerpt(); ?>,但是在页面上显示的却是文章的内容 原因:the_excerpt(); 在excerp ...
- 在VS 2017 下创建 Xamarin NuGet Package
最近在做一个Xamarin for android的项目,有个需求是一次可以从相册中选择多张图片,但是 android API<19 的版本还不支持一次选择多张图片,在网上找了一下,发现原生的组 ...
- jQuery事件绑定,解绑,触发
事件绑定 1.bind(type,[data],fn) --type: 含有一个或多个事件类型的字符串,由空格分隔多个事件.比如"click"或"submit" ...
- Easyui datagrid combobox输入框下拉(取消)选值和编辑已选值处理
datagrid combobox输入框下拉(取消)选值和编辑已选值处理 by:授客 QQ:1033553122 测试环境 jquery-easyui-1.5.3 需求场景 如下,在datagri ...
- Android MVP
大家先看看目录结构 先看V层 View里面我写了一个接口LoginView 然后,在登录这个Activity 去实现这个接口,并实现其抽象方法.即看LoginActivity onCreate中引用了 ...
- Jmeter输出完美报告
做技术的就爱折腾, 看到哪里不够完美,就想把它改改, 使其顺眼. 同样Jmeter输出的报告实在差强人意, 截图发给领导看不够美观, 缺少统计汇总, 有什么方法给对方一个地址就可以浏览报告? 答案是肯 ...