MySQL之B+树索引(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
每个索引都对应一棵
B+树,B+树分为好多层,最下边一层是叶子节点,其余的是内节点。所有用户记录都存储在B+树的叶子节点,所有目录项记录都存储在内节点。InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录。我们可以为自己感兴趣的列建立
二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再到聚簇索引中查找完整的用户记录。B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。通过索引查找记录是从
B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory(页目录),所以在这些页面中的查找非常
首先我们需要知道在innoDB中一条记录的格式:
将记录格式的其他信息去掉并把它竖起来的效果就是这样
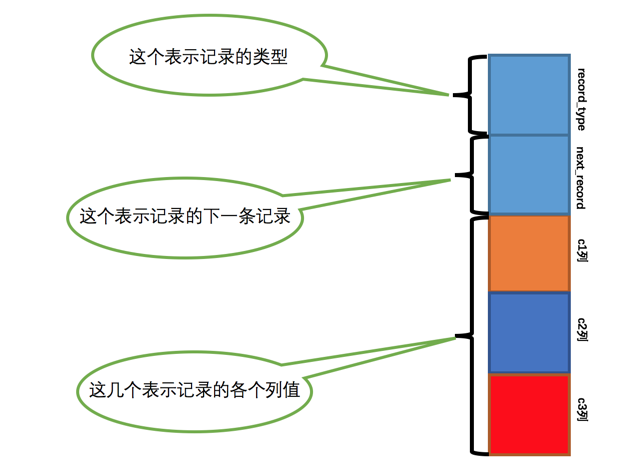
把一些记录放到页里边的示意图就是:
注意record_type的取值不同,代表着该条记录有不同的含义:
一个页面里面里的记录通过next_record指针串成一个链表,为了查找方便,为这个链表设置了两个虚拟头节点: 最小记录和最大记录:
record_type = 1表示是最小记录,record_type = 3表示是最大记录。
record_type = 0表示是普通用户记录。
record_type = 2表示是索引项目记录。这个后面再说。
页分裂
假设我们的每个数据页最多能存放3条记录(实际上一个数据页非常大,可以存放下好多记录),innoDB在插入数据项的时候,会按照主键值的大小顺序串联成一个单向链表:
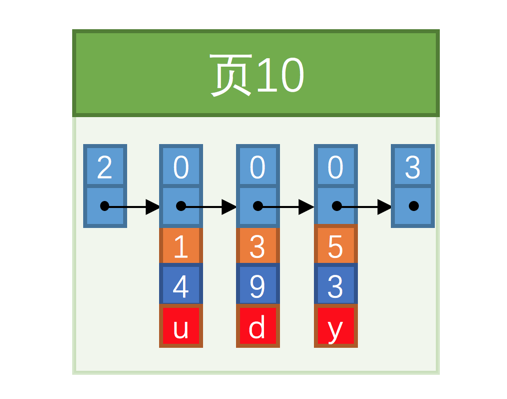
上图中的三条记录按照主键(橙色)由小到大的顺序串成一个链表
此时我们再插入一条记录,因为页10最多只能放3条记录,所以我们不得不再分配一个新页:
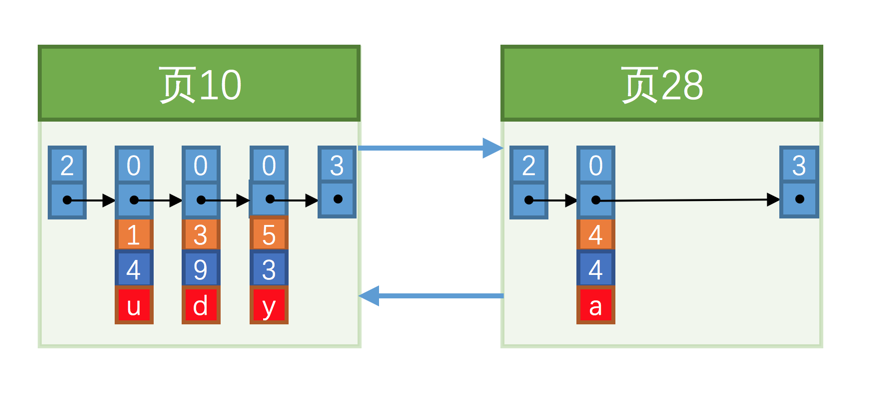
页10中用户记录最大的主键值是5,而页28中有一条记录的主键值是4,因为5 > 4,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以在插入主键值为4的记录的时候需要伴随着一次记录移动,也就是把主键值为5的记录移动到页28中,然后再把主键值为4的记录插入到页10中。我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程我们也可以称为页分裂。
B+树索引在空间和时间上都有代价,所以没事儿别瞎建索引。B+树索引适用于下边这些情况:- 全值匹配
- 匹配左边的列
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列
- 用于排序
- 用于分组
在使用索引时需要注意下边这些事项:
- 只为用于搜索、排序或分组的列创建索引
- 为列的基数大的列创建索引
- 索引列的类型尽量小
- 可以只对字符串值的前缀建立索引
- 只有索引列在比较表达式中单独出现才可以适用索引
- 为了尽可能少的让
聚簇索引发生页面分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。 - 定位并删除表中的重复和冗余索引
- 尽量使用
覆盖索引进行查询,避免回表带来的性能损耗。
其他的部分见掘金小册!
MySQL之B+树索引(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)的更多相关文章
- MySQL之 InnoDB记录结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
以下内容来自掘金小册 MySQL 是怎样运行的:从根儿上理解 MySQL 版权归原作者所有! 页是MySQL中磁盘和内存交互的基本单位,也是MySQL是管理存储空间的基本单位. 指定和修改行格式的语法 ...
- MySQL之InnoDB数据页结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页. 一个数据页可以被大致划分为7个部分,分别是 File Header,表示页的一些通用信息,占固定的38字节. Pag ...
- SQL优化 MySQL版 - B树索引详讲
SQL优化 MySQL版 - -B树索引详讲 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] 为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太 ...
- MySQL的B+树索引和hash索引的区别
简述一下索引: 索引是数据库表中一列或多列的值进行排序的一种数据结构:索引分为聚集索引和非聚集索引,聚集索引查询类似书的目录,快速定位查找的数据,非聚集索引查询一般需要再次回表查询一次,如果不使用索引 ...
- MySQL的B树索引与索引优化
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引 ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- Mysql之B+树索引实战
索引代价 空间上的代价 一个索引都对应一棵B+树,树中每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,所以一个索引也是会占用磁盘空间的. 时间上的代价 索引是对数据的排序,那么当对表中的 ...
- MySQL中B+树索引的使用
1) 不同应用中B+树索引的使用 对于OLTP应用,由于数据量获取可能是其中一小部分,建立B+树索引是有异议时的 对OLAP应用,情况比较复杂,因为索引的添加应该是宏观的而不是微观的. ...
- 为什么MySQL字符串不加引号索引失效?《死磕MySQL系列 十一》
群里一个小伙伴在问为什么MySQL字符串不加单引号会导致索引失效,这个问题估计很多人都知道答案.没错,是因为MySQL内部进行了隐式转换. 本期文章就聊聊什么是隐式转换,为什么会发生隐式转换. 系列文 ...
随机推荐
- java~gradle构建公用包并上传到仓库~使用私有仓库的包
在新的项目里使用仓库的包 上一讲中我们说了java~gradle构建公用包并上传到仓库,如何发布公用的非自启动类的包到私有仓库,而这一讲我们将学习如何使用这些包,就像我们使用spring框架里的功能包 ...
- 基于IdentityServer的系统对接微信公众号
业务需求 公司有两个业务系统,A和B,AB用户之间属于多对一的关系,数据库里面也就是两张表,A表有个外键指向B.现在需要实现以下几个功能. A用户扫描B的二维码,填写相关的注册信息,注册完成之后自动属 ...
- DS控件库 DS标签的另类用法之折叠展开
某些场合下,可以通过动态设置DS标签的文本内容来输出不同的显示效果,以下是示例. 示例中的素材 示例资源文本 String1="<linkimg=E1><b>&l ...
- 用v-bind:style时的问题
今天纠结了挺久一个问题,个人习惯是在HBuilder里先写好前端样式,在放.net去测试数据,但是发现一个问题 就是一个提示框跟随鼠标移动 提示框用v-bind:style绑定一个对象 DIV就是这句 ...
- 简述Servlet的基本概念
Servlet的基本概念 Servlet的概念 http协议作用于客户端-服务端.由客户端发送请求(Request),服务器端接收到数据之后,向客户端发送响应(Response),这就是请求-响应模式 ...
- 回顾曾经的自己,献给java初学者的建议
要不惜代价投资自己,任何对自己的投资都是值得的 要多学习数据结构, 习惯看源码! 一份知识经过n个人的传递早已经不成样子了 遇到问题不要直接百度,百度上那些花里胡哨的东西有用的很少,对症下药才是王道, ...
- JVM的总结
1.JVM的内存模型 JVM主要由程序计数器,虚拟机栈,堆,方法区,本地方法区 1.程序计数器的功能是记录当前线程执行到了字节码文件的哪一行, JVM执行的是.java编译后的.class文件 2.虚 ...
- Numpy库的学习(二)
今天来继续学习一下Numpy库的使用 接着昨天的内容继续 在Numpy中,我们如果想要进行一个判断使用“==” 我们来看下面的代码 vector = np.array([5,10,15,20,25]) ...
- Jmeter 接口测试实战-有趣的cookie
Jmeter 接口测试实战-有趣的cookie 场景: 接口测试时常都需要登录,请求方式(post), 登录常用的方法有通过获取token, 获取session, 获取cookie, 等等. 这几种都 ...
- MyDAL - like && not like 条件 使用
索引: 目录索引 一.API 列表 C# 代码中 String.Contains("conditionStr") 生成 SQL 对应的 like '%conditionStr%' ...