开发一个http代理服务器
参考链接:
http://www.cnblogs.com/jivi/archive/2013/03/10/2952860.html
https://www.2cto.com/kf/201405/297926.html
http://www.jb51.net/article/116591.htm
http://www.jb51.net/article/79893.htm
http://blog.csdn.net/u012734441/article/details/44801523
http://blog.csdn.net/turkeyzhou/article/details/5512348
http://blog.csdn.net/u013087513/article/details/53560827
一、产品原型
1、配置使用代理服务器
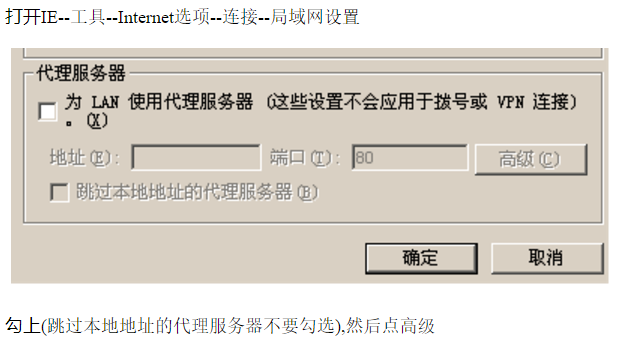
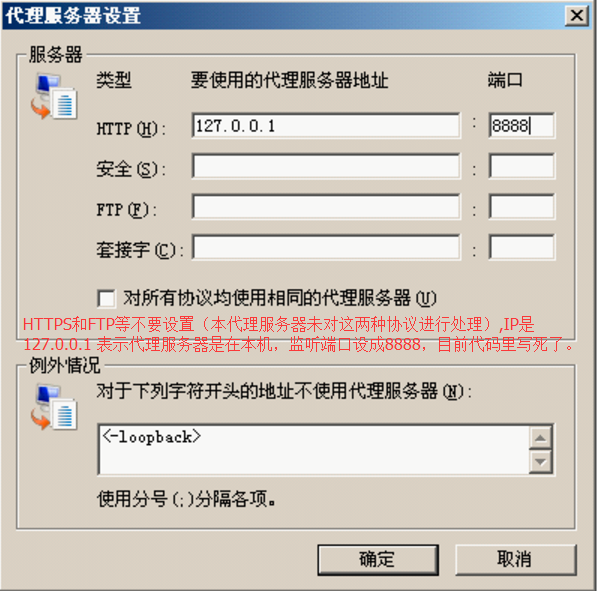
参照上图设置,HTTPS和FTP等不要设置(本代理服务器未对这两种协议进行处理), IP是 127.0.0.1 表示代理服务器是在本机,监听端口设成8888。
在IE里设置完后,我们会发现其它浏览器也自动开始使用代理服务器了,这是因为设置代理服务器是系统的功能,每个浏览器打开的都是同一个设置代理服务器的程序。
其实,我们可以实现一个自动设置代理服务器的功能,这样,当我们的代理服务器启动的时候,就自动将本机的代理服务器设置成自己,退出的时候,再恢复成原样,这样就不再需要向上面一样手动设置了。
2、使用代理服务器
配置完毕后,在浏览器里输入网址: http://www.baidu.com
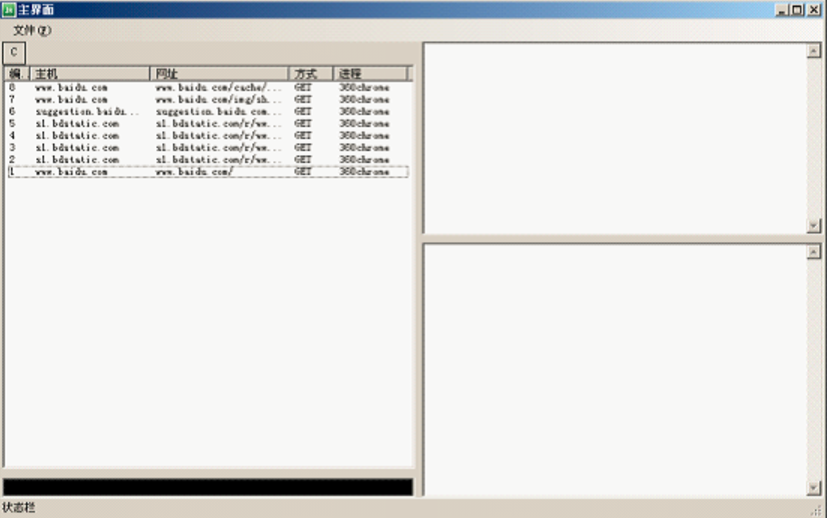
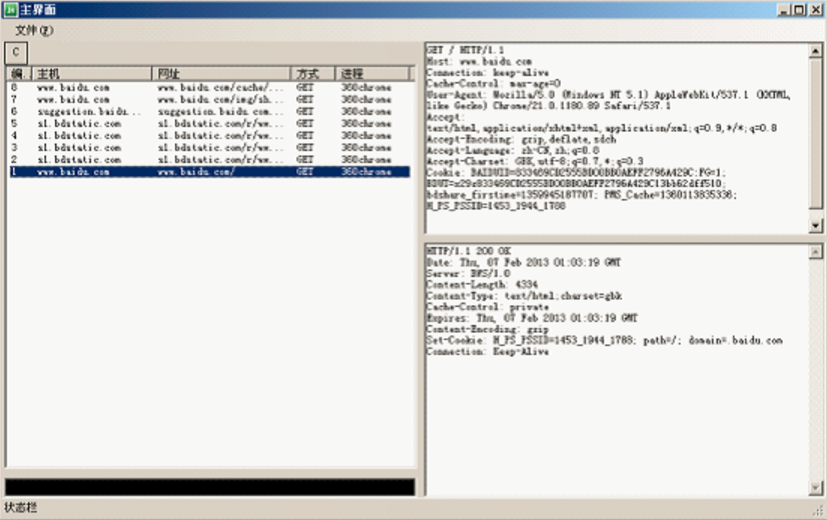
我们可以清楚看到,所有的请求和响应信息都已经被监听到了。
二、理论储备
1、http请求处理过程
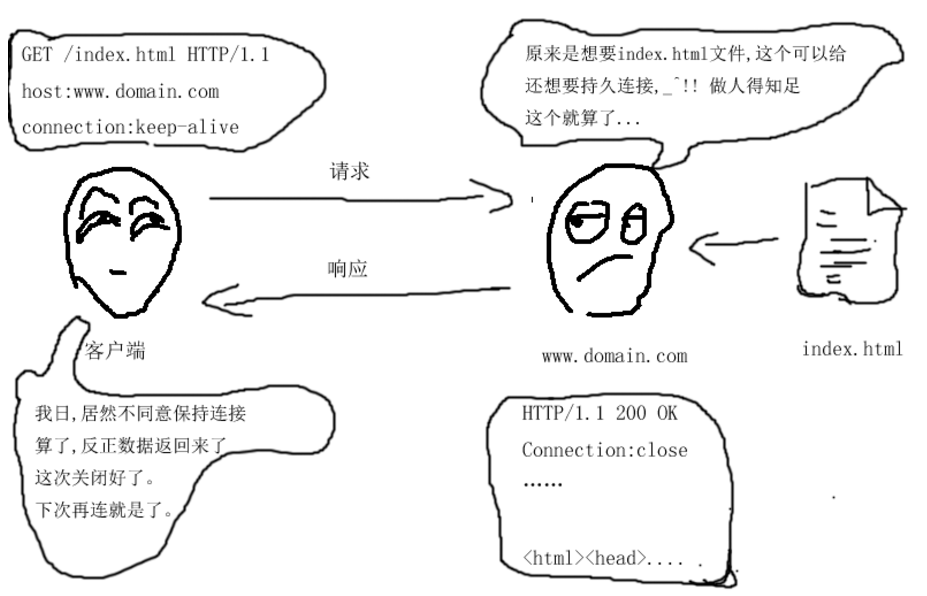
客户端先建立一个和服务端的TCP连接,然后利用这个TCP连接将一份象上面一样的HTTP请求报文发到服务端,
服务端监听到这个请求,然后利用Accept建立一条和这个客户端的专门连接,然后利用这个专门连接读取这一段请求报文,然后再分析这段报文,当他看到有connection:keep-alive的首部时,服务端就知道,客户端要求建立持久连接,服务端根据实际情况对这个请求进行处理。
a. 如果服务端不同意建立持久连接,那么会在响应报文里加上一个首部 connection:close 。然后再利用这个专门连接将这个响应报文发回给客户端,接着服务端就会关闭这条连接,
客户端会收到服务器刚才的应答信息,看到了connection:close,这时候客户端就知道服务端拒绝了他的持久连接,那么,客户端在完成这次响应报文的解析后会关闭这条连接,当下次再有请求发送到这个服务器的时候,会重新建一个连接。
b. 如果服务端同意建立持久连接,那么会在响应报文里加上一个首部connection:keep-alive。然后利用这个专门连接,将这个响应报文发回给客户端, 但不关闭这条连接,而是阻塞在那里,直到监视到有新的请求从这个连接传来,再接着处理。
客户端收到刚才的响应报名,看到了connection:keep-alive,于是客户端知道服务端同意了他的持久连接请求,那么客户端也不会关闭这个连接,当有新的向此服务器发送的请求时,客户端就会通过这个已经打开的连接进行传输,这样就可以节省很多时间(连接建立的时间是很耗时的)。
2、http请求报文
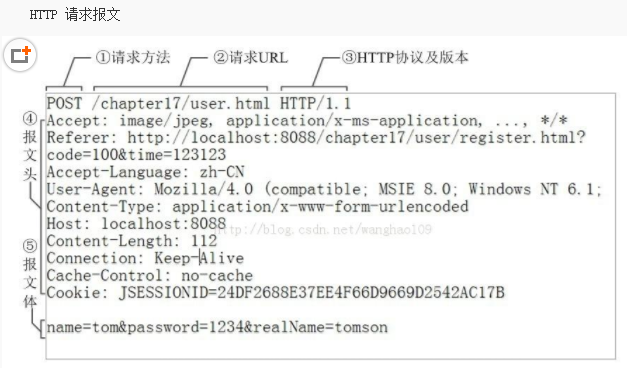

http请求报文包含如下三部分:
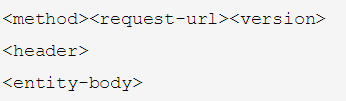
http请求报文例子分析:

关于请求头host补充一下:请求头host冒号后面的部分除了采用 域名:端口 的方法,还可以采用 IP:端口的方法。
例如 host:192.168.1.12:8080 。这种情况下,第二个冒号前面的就是IP了。
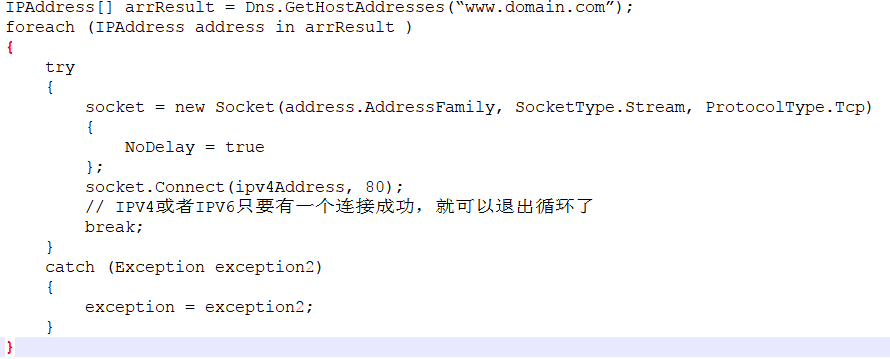
如果是域名,host:www.domain.com 的情况。这种情况,就需要从域名得到IP了。那么从域名--IP,需要什么技术呢,自然就是DNS(Domain Name System)了。
在本地的DNS缓存里找域名对应的IP,然后封装成IPAddress类型的数组进行返回。为什么返回的是数组?
因为有IPV4和IPV6两种类型的地址,但在一些不支持IPV6的机器上,IPV6项会被筛选掉,所以这种情况下,这个数组的大小就是1。
3、http响应报文

4、如果设置了代理
当没有设置代理的时候,正常的HTTP请求报文格式应该是这样的

但是如果设置了代理,那么浏览器的请求报文都会被发送到代理服务器,在这种情况下,浏览器会对请求报文做些简单的变化,主要在两个方面。
4.1、区别一:post / http/1.1 ----》post http://www.domain.com/ http/1.1
我们看到在直接发送到目标服务器的情况下,一般都是相对的地址(前面的例子默认都是这种情况下的):
post / http/1.1
而在发送到代理服务器的情况下,就会变成:
post http://www.domain.com/ http/1.1
<request-url> 部分被替换成了完整的URL地址。为什么要这样做呢,是因为早期的HTTP协议,是没有HOST首部的,这样当直接连接到服务器时,是没有问题的,因为服务器IP在发送报文前肯定是已知的,所以这种情况只要传个相对路径给服务器,服务器就可以通过这个相对路径找到资源并返回了。
但是如果是发送到代理的话,这个请求报文就出问题了,因为代理无法从这个请求报文里分析出来目标服务器的地址,地址都不知道代理又如何将这个请求转发呢。
所以,在HTTP协议里将发送到代理服务器情况下的请求报文里的<request-url>设计成了完整地址,这样代理服务器就可以通过分析这个完整的址址的主机部分获取目标服务器的地址,如此就可能顺利的建立到目标服务器的连接并实现转发了。
但是后来随着虚拟主机的出现,同一个服务器可以映射多个站点,没有HOST首部的HTTP协议,已经没办法处理这种情况了,所以后来HTTP协议里引入了HOST这个首部,
理论上在引入了HOST首部后,不仅虚拟主机的情况可以解决,就连代理服务器也可以一并解决了,就不用再在<request-url>里写完整地址了,但是为了保持协议的兼容性,当发送到代理服务器时<request-url>为完整地址的规则还是被继承了下来。
4.2、区别二: connection:keep-alive/close ----》proxy-conection:keep-alive/close
那就是当直接发送到目标服务器时,有个首部是
connection:keep-alive/close
当发送到代理服务器时,这个首部会被替换成
proxy-conection:keep-alive/close

这段代码在 ServerChatter 类里的 ResendRequest方法体里。这里又出现了this._bWasForwarded. 意思是 如果继续转发请求给代理服务器或网关,而且不是HTTPS的情况下,就把proxy-connection 替换成 connection .
然而程序本身是没有办法判断出要转发到的目标服务器究竟是不是代理服务器或者网关的,所以这个变量,不在人工干预的情况下,百分之百是FALSE的 。在我们的代码里,目前并没有实现人工干预的功能,所以这个变量永远都是FALSE。保留他下来只是为了以后的扩展。
事实上代理服务器确实不一定会把请求直接转发到最终的目标服务器,而是有可能先转发到另外一个代理服务器或者网关上,然后再由他们转发到最终的目标服务器或者他也是再转发至下一个代理服务器或者网关。
因为我们很有可能会遇到下面的这种情况, 在自己的内网建了一个过滤代理,这个过滤代理的功能就是把除了公司想让我们访问的网址以外的所有网址全部屏蔽,但是现在出问题了,公司想让我们访问的网站,全部都是被天朝封锁的国外网站,这可怎么办呢?
其实不难办,这时候只要过滤代理再把这个请求转发给另外一个代理服务器(这个服务器要求在国内能访问,另外它也能访问国外的网站就可以了),然后由它来获取网页后响应给我们的过滤代理,再由我们的过滤代理发回给客户端 。
三、关键点设计
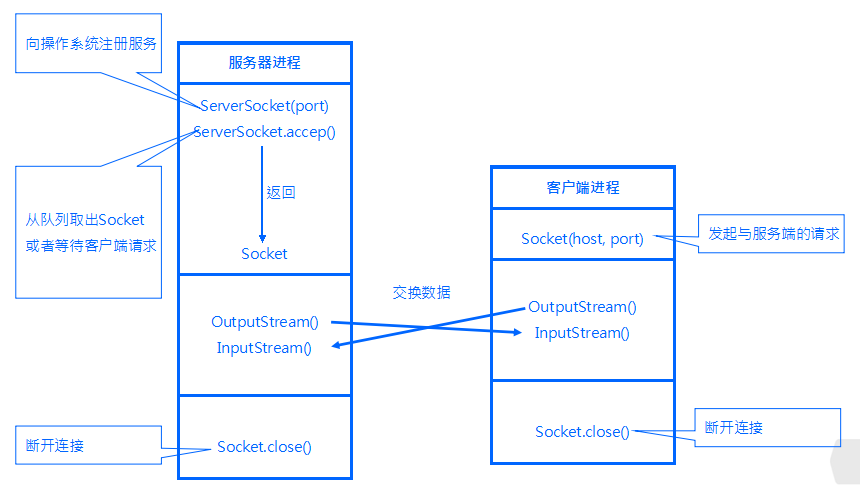
代理服务器程序启动时,new 一个代理(Proxy)类的实例,然后调用这个实例的Start方法,在Start方法里不停的异步监听代理服务器8888端口,
如果监听到了,就从线程池里取出来一个线程,并在这个线程里构造一个Session对象。一个Session对象代表客户端与服务器的一次会话,在有代理服务器情况下的一次会话(Session) 过程如下:
- 1.从客户端读请求
- 2.重新包装客户端的请求,转发至目标服务器.
- 3.从目标服务器读取响应信息
- 4.包装接收到的响应信息并返回给客户端。
故而在Session类里,封装一个ClientChatter类型的名为Request的对象,用来实现和客户端的通讯, 另外又封装了一个ServiceChatter类型的名为Response的对象,用来实现和目标服务器的通讯。

1、ObtainRequest()
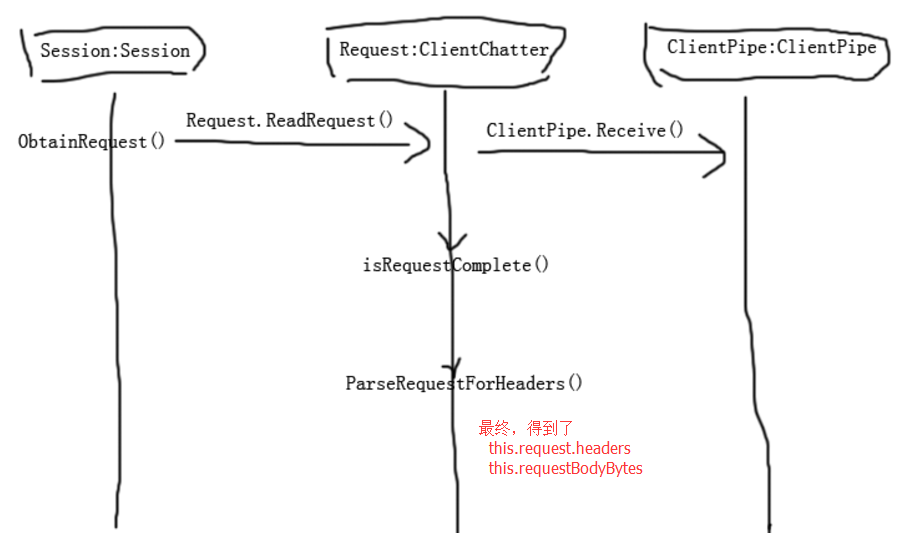
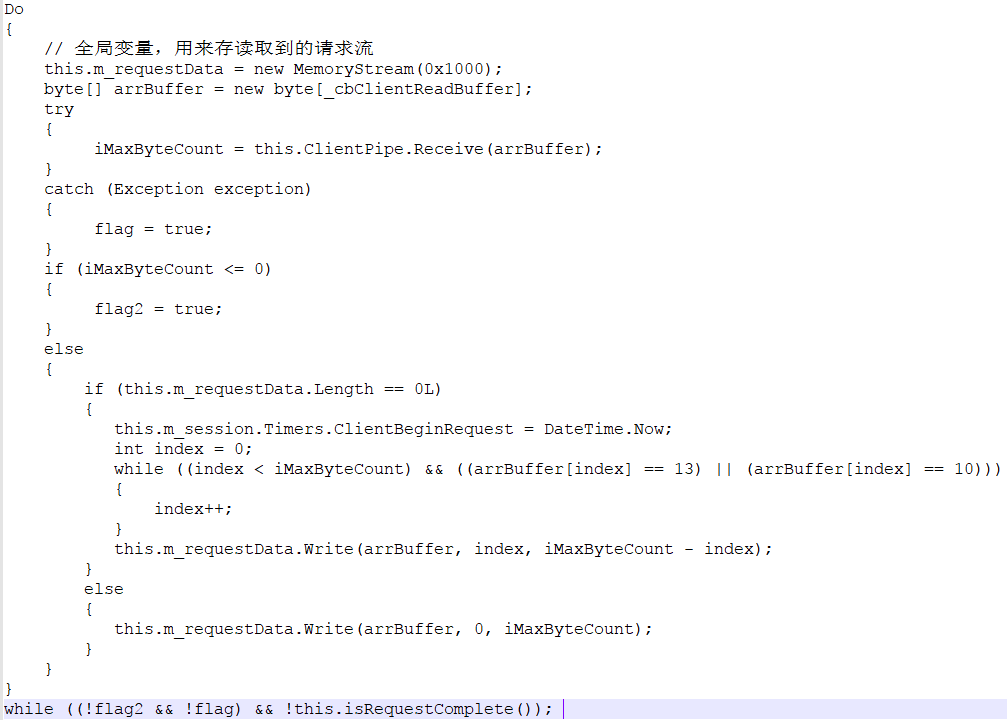
这里就是不停的读取请求信息,直到读取完成为止。读取的同时将这些请求信息存在this.m_requestData(MemoryStream类型)这个全局变量里。有一点要注意一下,那就是判断接收结束的方法。也就是while里面的那三个条件:
- 一个是 flag2 = true , 从上面的代码可以看出,就是iMaxByteCount = 0 ,客户端关闭了链接
- 另外一个条件是 flag = true,也就是出意外了,出意外了自然结束
- 还有一个就是 isRequestComplete(), 封装了两种结束方式:content-length结束和transfer-encoding:chunked方式结束
iMaxByteCount = 0 了,不就代表已经读取完客户端发过来的请求数据了吗,当然不是,iMaxByteCount其实是客户端关闭了链接。
这个iMaxByteCount 其实是Socket.Receive的返回值, Socket.Receive(byte[] buffer) 从绑定的 Socket 套接字接收数据,将数据存入接收缓冲区。
当读不到数据的时候,Receive方法会阻塞在那里,直到有数据到达,或者超时为止,而不是象我们想象的那样返回0,返回0只有一种情况,就是Socket.Shutdown(),也就是连接的那个Socket关闭了他的连接,在这里也就是客户端关闭了连接。
所以说一般情况下,我们是不可能通过iMaxByteCount=0(iMaxByteCount= Socket.receive())来判断是否已经读取完了客户端的请求报文(用户在请求过程上,关闭了浏览器可能会发生这种情况)。
请求接收结束时机 isRequestComplete()->content-length方式结束
当客户端将请求报文发送到服务器后,连接是不会关闭的,客户端是否关闭连接,要等到服务器响应后才决定。
也就是说一般情况下,我们是不可能通过iMaxByteCount=0(iMaxByteCount= Socket.receive())来判断是否已经读取完了客户端的请求报文(用户在请求过程上,关闭了浏览器可能会发生这种情况)。 那么我们又怎么来判断请求报文已经全部接收完成了呢?

请求头:content-length:8, 表示实体 <entity-body>(在上面的例子里就是a=b&b=cd)的长度,那么<head>头部解析完后再读取content-length个字符,不就表示此次的请求已经全部读取完成了吗?
实际的处理如下:

请求接收结束时机 isRequestComplete()->transfer-encoding:chunked方式结束
当然content-length并不能判断所有的情况,只有确切的知道entity-body长度的情况下,content-length才是有意义的。
但是事实上entity-body的长度并不总是可以预知的,尤其在传一些大文件的时候,为了节省资源和时间,一般会采用分块传输的方式,采用分块传输的时候,会在报文里增加一个首部transfer-encoding:chunked,另外在entity-body里也要遵循一定的格式,
这种情况在请求报文里很少见,因为请求报文在不选择文件进行提交的时候,一般报文都很小,这种情况主要出现在响应报文里。这种情况一般会有如下处理方式:

同时,isRequestComplete()解析了请求报文头,ParseRequestForHeaders()
if (!this.ParseRequestForHeaders())
这个就是分析报头的代码了,前面提到过,会将原始报头映射到一个HTTPRequestHeaders类型的对象里,那么这个方法就是做那个的了,
此方法执行完成后,会把原始的请求报文流中的报头部分(除entity-body以外的部分)分析到一个HTTPRequestHeaders类型的私有属性(m_headers)里。
然后在ClientChatter里又暴露了一个Public的属性Headers来访问这个属性。当然这个方法里还会记录entity-body的起始位置,这样,在后面的TakeEntity方法就可以通过这个位置读取entity-body的内容了。
而TakeEntity会在 Session类的ObtainRequest里被调用this.RequestBodyBytes = this.Request.TakeEntity();
Session类的ObtainRequest方法终于分析完成!
调用完Session的ObtainRequest方法后,程序会变成什么样呢,经过刚才的分析其实已经很清楚了。
这时在Session类里,只要使用this.Request.Headers就可以获得所有的报头信息了。报体部分entity-body 则是通过this.RequestBodyBytes 进行调用 。
2、response.ResendRequest
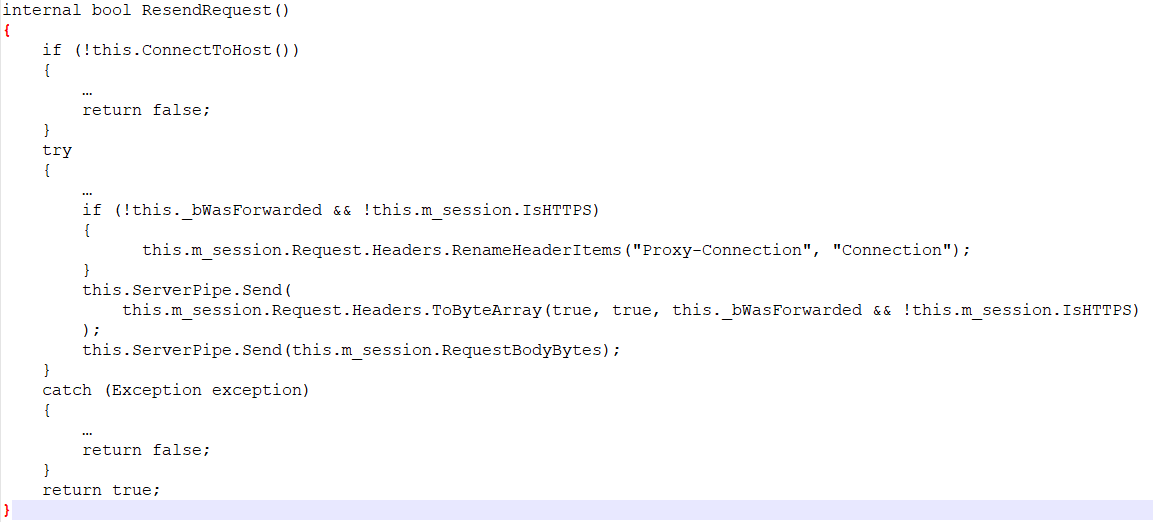
核心逻辑分析如下:
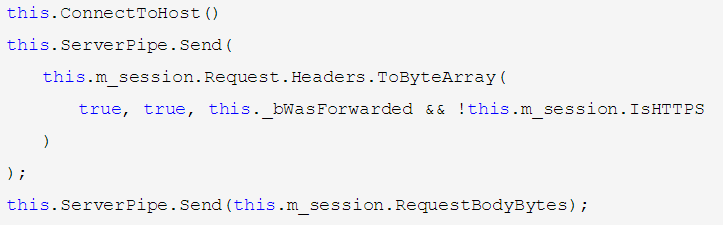
其中,
a、this.ConnectToHost();
// 构造一个ServerPipe,并在里面封装一个和服务端通讯的Socket
// 获取ip(可以通过dns解析域名,从在本地的DNS缓存里找域名对应的IP得到)
// 获取端口
// 创建链接
this.ConnectToHost() 展开如下:
b、this.ServerPipe.Send( this.m_session.Request.Headers.ToByteArray( true, true, this._bWasForwarded && !this.m_session.IsHTTPS ) );
// 通过这个ServerPipe的Send方法将使用this.m_session.Request.Headers.ToByteArray方法重新包装的请求报头发送给服务器 。
c、this.ServerPipe.Send(this.m_session.RequestBodyBytes);
// 发送原始请求报文的报体到服务器
3、response.ReadRequest
响应报文:
ReadResponse(ServerChatter.cs里)方法和读取请求报文时(ClientChatter的ReadRequest方法)基本上是一样的,都是不停的使用Receive方法接收数据,直到已经接收完成为止(也要判断三种情况)。
然后再将接收到的响应信息映射到一个HTTPResponseHeaders 类型的对象里,这个对象名叫_inHeaders。同样的也有一个public的Headers属性来访问它。
和读取请求报文时一样,这个方法里,也会记录<entity-body>的偏移位置,以备 TakeEntity方法调用时,用来读取entito-body 部分。
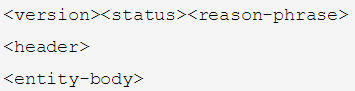
- version : HTTP的版本号,例如 HTTP/1.1 or HTTP/1.0
- status : 状态码 常见的 200 成功 404 没有找到文件 500 服务器错误等
- reason-phrase : 对于状态码的简短解释,这个解析不同的服务器内容可能不尽相同。例如 当 status为200时,这里可以是 OK
- head : 首部,可以有0个或者多个,每个首部都是key:value的形式,然后以CRLF(回车换行)结束 例如: content-type:text/html
- entity-body 主体内容,返回的HTML,或者二进制的图片,视频等数据都在这一部分
4、returnResponse
开发一个http代理服务器的更多相关文章
- 【如何快速的开发一个完整的iOS直播app】(原理篇)
原文转自:袁峥Seemygo 感谢分享.自我学习 目录 [如何快速的开发一个完整的iOS直播app](原理篇) [如何快速的开发一个完整的iOS直播app](播放篇) [如何快速的开发一个完整的 ...
- 如何快速的开发一个完整的iOS直播app(原理篇)
目录 [如何快速的开发一个完整的iOS直播app](原理篇) [如何快速的开发一个完整的iOS直播app](播放篇) [如何快速的开发一个完整的iOS直播app](采集篇) 前言 大半年没写博客了,但 ...
- 如何开发一个直播APP
一.个人见解(直播难与易) 直播难:个人认为要想把直播从零开始做出来,绝对是牛逼中的牛逼,大牛中的大牛,因为直播中运用到的技术难点非常之多,视频/音频处理,图形处理,视频/音频压缩,CDN分发,即时通 ...
- 抖音短视频爆火的背后到底是什么——如何快速的开发一个完整的直播app
前言 今年移动直播行业的兴起,诞生了一大批网红,甚至明星也开始直播了,因此不得不跟上时代的步伐,由于第一次接触的原因,因此花了很多时间了解直播,今天我来教你从零开始搭建一个完整的直播app,希望能帮助 ...
- 拥抱.NET Core,如何开发一个跨平台类库 (1)
在此前的文章中详细介绍了使用.NET Core的基本知识,如果还没有看,可以先去了解“拥抱.NET Core,学习.NET Core的基础知识补遗”,以便接下来的阅读. 在本文将介绍如何配置类库项目支 ...
- 如何开发一个简单的HTML5 Canvas 小游戏
原文:How to make a simple HTML5 Canvas game 想要快速上手HTML5 Canvas小游戏开发?下面通过一个例子来进行手把手教学.(如果你怀疑我的资历, A Wiz ...
- [MEF插件式开发] 一个简单的例子
偶然在博客园中了解到这种技术,顺便学习了几天. 以下是搜索到一些比较好的博文供参考: MEF核心笔记 <MEF程序设计指南>博文汇总 先上效果图 一.新建解决方案 开始新建一个解决方案Me ...
- bootstrap开发一个简单网页。
CSS代码: body{ padding-top: 50px; padding-bottom: 50px; overflow: auto!important; ...
- 后移动互联网时代:到底还要不要开发一个App?
后移动互联网时代,到底是什么样的一个时代? 首先,后移动互联网时代中,产生头部应用的几率变小了,像微信这样巨头式的App很难在产生第二个.其次,后移动互联网时代,物联网发展迅速,所有的智能硬件都需要一 ...
随机推荐
- 洛谷 P2904 [USACO08MAR]跨河River Crossing
题目 动规方程 f[i]=min(f[i],f[i−j]+sum) 我们默认为新加一头牛,自占一条船.想象一下,它不断招呼前面的牛,邀请它们坐自己这条船,当且仅当所需总时间更短时,前一头奶牛会接受邀请 ...
- 【Unity与23种设计模式】解释器模式(Interpreter)
GoF中定义: "定义一个程序设计语言所需要的语句,并提供解释来解析(执行)该语言." 传统上,执行程序代码通常通过两种方式 第一种:编译程序 第二种:解释器 常见的使用解释器的程 ...
- Maven-11: 从命令行调用插件
mvn -h显示mvn命令帮助: usage: mvn [options] [<goal(s)>] [<phase(s)>] Options: -am,--also-make ...
- html-简单的简历表制作
代码如下: <!DOCTYOE html> <html> <head> <meta charset='UTF-8'/> <title>课后作 ...
- Spring Boot with Spring-Data-JPA学习案例
0x01 什么是Spring Boot? Spring Boot是用来简化Spring应用初始搭建以及开发过程的全新框架,被认为是Spring MVC的"接班人",和微服务紧密联系 ...
- wipefs进程
wipefs进程是啥,占用了百分之90多的cpu wipefs进程是啥,占用了百分之90多的cpu,把这个进程干掉了,过了一天又自动启动了,很多朋友应该遇到过类似的问题. wipefs是linux自带 ...
- Eclipse项目中web app libraries和 Referenced Libraries区别
Referenced Libraries是编译环境下使用的JAR包,所谓编译环境下使用的JAR包, 就是说你在Eclipse中进行源文件的编写的时候,所需要引用到的类都从Referenced Li ...
- Eclipse配置类似sublime的黑色主题
另一篇中,详细介绍了如何使用Eclipse+Pydev搭建Python环境,传送门:http://www.cnblogs.com/BH8ANK/p/8688110.html 下面介绍下如何在Eclip ...
- Leetcode 19——Remove Nth Node From End of List
Given a linked list, remove the nth node from the end of list and return its head. For example, Give ...
- 第二次作业-Steam软件分析
1 .介绍产品相关信息 随着电子音频游戏产业的发展以及正版意识的崛起,Steam已经成为大部分游戏爱好者必备的一款游戏下载平台.这款软件也使得Valve公司从一个游戏制作公司成功扩展业务到一个承揽众多 ...