Python之Scrapy爬虫框架 入门实例(一)
一、开发环境
1.安装 scrapy
2.安装 python2.7
3.安装编辑器 PyCharm
二、创建scrapy项目pachong
1.在命令行输入命令:scrapy startproject pachong
(pachong 为项目的名称,可以改变)

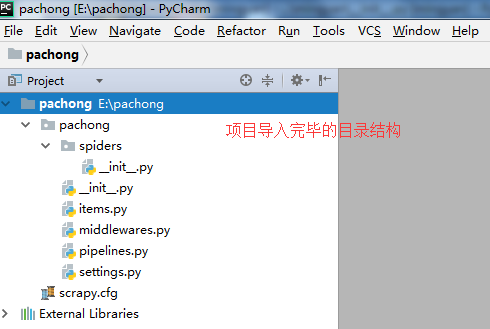
2.打开编辑器PyCharm,将刚刚创建的项目pachong导入。
(点击file—>选择open—>输入或选择E:\pachong—>点击ok)
三、创建scrapy爬虫文件pachong_spider.py
在pachong_spider.py这个文件夹中编写爬取网站数据的内容。
(右击文件spiders—>选择New,在选择PhthonFile—>输入文件名pachong_spider)

四、编写爬虫pachong
将 网址 http://lab.scrapyd.cn/ 博客中的所有博客标题和博客标签,以作者名-语录为名分别保存在各自作者对应的txt文件中。
1.查看http://lab.scrapyd.cn/源代码,获取自己所需的博客标题、作者、标签三个内容的对应HTML标签信息。

2.获取网址的内容,保存到变量pachong里。
(分析HTML结构,每一段需要提取的内容都被一个 <div class="quote post">……</div> 包裹。)

3.获取循环获取标题、作者的第一个内容,和对应标签的内容,并对标签的内容进行逗号分隔后,进行分类保存。

4.查看下一页的HTML标签,对下一页获取的内容进行循环。
(查看存在不存在下一页的链接,如果存在下一页,把下一页的内容提交给parse然后继续爬取。如果不存在下一页链接结束爬取。)


5.爬虫源代码。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#Python 默认脚本文件都是 UTF-8 编码的,当脚本出现中文汉字时需要对其进行解码。
import scrapy
class itemSpider(scrapy.Spider):
# scrapy.Spider 是一个简单的爬虫类型。
# 它只是提供了一个默认start_requests()实现。
# 它从start_urlsspider属性发送请求,并parse 为每个结果响应调用spider的方法。
name ="pachong"
# 定义此爬虫名称的字符串。
# 它必须是唯一的。
start_urls = ['http://lab.scrapyd.cn']
#爬虫抓取自己需要的网址列表。
#该网站列表可以是多个。
def parse(self, response):
# 定义一个parse规则,用来爬取自己需要的网站信息。
pachong = response.css('div.quote')
# 用变量pachong来保存获取网站的部分内容。
for v in pachong:
text = v.css('.text::text').extract_first()
autor = v.css('.author::text').extract_first()
tags = v.css('.tags .tag::text').extract()
tags = ','.join(tags)
# 循环提取所有的标题、作者和标签内容。
fileName = u'%s-语录.txt' % autor
# 文件的名称为作者名字—语录.txt。
with open(fileName, "a+")as f:
f.write(u'标题:'+text)
f.write('\n')
f.write(u'标签:' + tags)
f.write('\n------------------------------------------------\n')
# 打开文件并写入标题和标签内容。
f.close()
# 关闭文件
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
# 查看存在不存在下一页的链接,如果存在下一页,把下一页的内容提交给parse然后继续爬取。
# 如果不存在下一页链接结束爬取。
五、运行爬虫pachong
1.在命令行输入命令:scrapy crawl pachong
(在pachong的目录下输入命令)


2.打开e盘 pachong文件夹,已经按要求爬取网址 http://lab.scrapyd.cn/ 的内容。

Python之Scrapy爬虫框架 入门实例(一)的更多相关文章
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- scrapy爬虫框架入门实例(一)
流程分析 抓取内容(百度贴吧:网络爬虫吧) 页面: http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=ut ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息
scrapy作为流行的python爬虫框架,简单易用,这里简单介绍如何使用该爬虫框架爬取个人博客信息.关于python的安装和scrapy的安装配置请读者自行查阅相关资料,或者也可以关注我后续的内容. ...
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://sc ...
- scrapy爬虫框架入门实战
博客 https://www.jianshu.com/p/61911e00abd0 项目源码 https://github.com/ppy2790/jianshu/blob/master/jiansh ...
随机推荐
- Android开发——Fragment的简单使用总结
前言: 之前搞项目的时候,就使用了这个Fragment,中间遇到了许多坑,把坑都解决了,现在写一篇较为简单的Fragment使用总结 Fragment的简单介绍: 简单来说,Fragment其实可以理 ...
- linux的学习之路--(五)bash及其特性
操作系统组成作用shell是离用户最近的程序 shell:外壳 两类 GUI:Gnome,KDE,Xfce CLI:sh, csh,ksh,bash(都是程序,就是功能支持的不同而已) 进程:在每个进 ...
- 在 Scale Up 中使用 Health Check - 每天5分钟玩转 Docker 容器技术(145)
对于多副本应用,当执行 Scale Up 操作时,新副本会作为 backend 被添加到 Service 的负责均衡中,与已有副本一起处理客户的请求.考虑到应用启动通常都需要一个准备阶段,比如加载缓存 ...
- 分享基于Qt5开发的一款故障波形模拟软件
背景介绍 这是一款采用Qt5编写的用于生成故障模拟波形的软件.生成的波形数据用于下发到终端机器生成对应的故障类型,用于培训相关设备维护人员的故障排查技能.因此,在这款软件中实现了故障方案管理.故障波形 ...
- grep -vFf 比较2个文件差异
grep -vFf 1.txt 2.txt 打印出2.txt中与1.txt有差异的数据. #cat .txt 192.168.0.1 192.168.0.2 192.168.0.3 #cat .t ...
- canvas填充样式
填充样式主要针对fillStyle.fillStyle除了可以赋值为color,还可以赋值渐变色,包括线性渐变色和径向渐变色,还是和css3里的内容类似. 一.线性渐变 1.设置线性渐变的填充样式 设 ...
- Oracle修改字段类型方法小技巧
有一个表名为tb,字段段名为name,数据类型nchar(20). 1.假设字段数据为空,则不管改为什么字段类型,可以直接执行:alter table tb modify (name nvarchar ...
- linq分组求和_实体类和datatable
1.数据分组求合,分别用的实体类以及datatable来分组求合,还有分组求和之后的如何取值 //实体类版本 List<ProgramTimeModel> TotalAllList = G ...
- js中非死循环引起的栈调用溢出问题
一般情况下,仅从代码上看只要不出现死循环,是不会出现堆栈调用溢出的.但是某些情况下列外,比如下面这段代码: var a = 99; function b (){ a --; if (a > 0) ...
- Alpha冲刺Day4
Alpha冲刺Day4 一:站立式会议 今日安排: 我们把项目大体分为四个模块:数据管理员.企业人员.第三方机构.政府人员.完成了数据库管理员模块.因企业人员与第三方人员模块存在大量的一致性,故我们团 ...