栈到CLR
提起栈想必会听到这样几个关键词:后进先出,先进后出,入栈,出栈。
栈这种数据结构,数组完全可以代替其功能。
但是存在即是真理,其目的就是避免暴漏不必要的操作。
如角色一样,不同的情景或者角色拥有不同的操作权限。
那我们来了解一下栈,栈是一种线性数据结构,并且只能从一端压入或者弹出 = 添加或者删除。
基于数组实现的栈是顺序栈,基于链表实现的链式栈。
接下来我们看一下.Net 是怎么实现栈的?
注释说的很明白:这是一个基于数组实现的顺序栈,其入栈复杂度O(n),出栈复杂度为O(1)
// A simple stack of objects. Internally it is implemented as an array,
// so Push can be O(n). Pop is O(1).
[DebuggerTypeProxy(typeof(System.Collections.Stack.StackDebugView))]
[DebuggerDisplay("Count = {Count}")]
[System.Runtime.InteropServices.ComVisible(true)]
[Serializable]
public class Stack : ICollection, ICloneable {
private Object[] _array; // Storage for stack elements
[ContractPublicPropertyName("Count")]
private int _size; // Number of items in the stack.
private int _version; // Used to keep enumerator in sync w/ collection.
[NonSerialized]
private Object _syncRoot; private const int _defaultCapacity = ; public Stack() {
_array = new Object[_defaultCapacity];
_size = ;
_version = ;
}
入栈:我们也看到这个是基于数组并且支持的那个太扩容的栈,默认大小围为10,当存满之后就会两倍扩容。
// Pushes an item to the top of the stack.
//
public virtual void Push(Object obj) {
//Contract.Ensures(Count == Contract.OldValue(Count) + 1);
if (_size == _array.Length) {
Object[] newArray = new Object[*_array.Length];
Array.Copy(_array, , newArray, , _size);
_array = newArray;
}
_array[_size++] = obj;
_version++;
}
正如注释中提到的,入栈复杂度可以达到O(n),出栈可以是O(1)
so Push can be O(n). Pop is O(1).
出栈Pop,复杂度为O(1)很好理解,
上面提到的动态栈是操作受限的数组,并且不会产生新的内存申请或者数据的搬移
我们只要是获取到最后一个,然后弹出(也就是删除)即可。
入栈Push,我们接下来分析一下出栈为什么复杂度为O(n):
前面有一篇《算法复杂度》 https://www.cnblogs.com/sunchong/p/9928293.html ,提到过:最好、最坏、平均
对于下面的入栈代码:
最好情况时间复杂度:不会有扩容和数据迁移,所以直接追加即可,复杂度为O(1)
最坏情况时间复杂度:需要扩容后并且搬移原来n个数据,然后再插入新的数据,复杂度为 O(n)
那么平均时间复杂度是多少呢?这里需要结合摊还分析法,进行复杂度分析。为什么这里要使用摊还分析法呢?
先耐心地看看其定义:
分析一个操作序列中所执行的所有操作的平均时间分析方法。
与一般的平均分析方法不同的是,它不涉及概率的分析,可以保证最坏情况下每个操作的平均性能。
总结一下摊还分析:执行的所有操作的平均时间,不扯概率。
一头雾水也不要紧,我们可以拿摊还分析来直接分析:
public virtual void Push(Object obj)
{
//Contract.Ensures(Count == Contract.OldValue(Count) + 1);
if (_size == _array.Length)
{
Object[] newArray = new Object[*_array.Length];
Array.Copy(_array, , newArray, , _size);
_array = newArray;
}
_array[_size++] = obj;
_version++;
}
入栈的最坏情况复杂度是O(n),但是这个最坏情况时间复杂度是在n+1次插入的时候发生的,
剩下的n次是不需要扩容搬移数据,只是简单的入栈 O(1),所以均摊下来的复杂度是O(1)。
那么为什么微软的工程师在备注里写下push复杂度是O(n)?--这里指的是空间复杂度O(n)
栈这种数据结构的应用有很多场景,其中一种就是我们的线程栈或者说函数栈。
当开启一个线程时,Windows系统为每个线程分配一个1M大小的线程栈。分配这个用来干什么呢?
存储方法中的参数和变量。趁这个机会,我们了解一下CLR的内存模型。
首先对于C#代码时如何编程机器代码的呢?
c#代码 -> 编译器 -> IL -> JIT -> CPU指令
当一个线程执行到以下方法时会有什么操作呢?
这段代码也很简单,就是在Main方法中调用了GetCode()方法,其他的都是一些临时变量。
static void Main(string[] args)
{
string parentCode = "PI001";
string newCode = string.Empty;
newCode = GetCode(parentCode);
} static string GetCode(string sourceCode)
{
string currentMaxCode = "";
string newCode = $"{sourceCode}{currentMaxCode}";
return newCode;
}
首先线程会分配1M内存用于存储临时变量和参数;
进入Main方法时,会将参数和返回地址依次压栈
static void Main(string[] args)
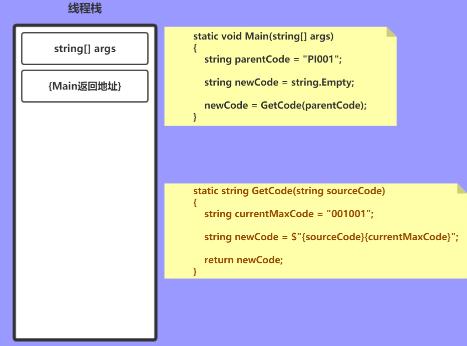
string parentCode = "PI001";
string newCode = string.Empty;

接下来开始进入到 GetCode() 方法,此时与之前一样压入参数和返回地址
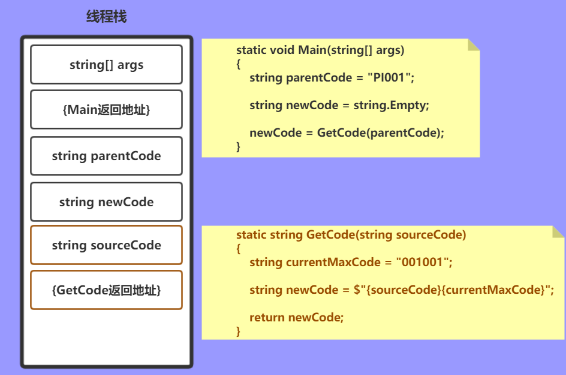
string currentMaxCode = "";
string newCode = $"{sourceCode}{currentMaxCode}";

既然说到了栈,那我们不得不再说一下托管堆,再来一段代码图解:
这是父类和子类的具体代码,可以略过此处。
public class BaseProduct
{
public string GetCode()
{
string maxCode = "";
return maxCode;
} public virtual string Trim(string source)
{
return source.Trim();
}
} public class Product : BaseProduct
{
private static string _type="PI"; public override string Trim(string source)
{
return source.Replace(" ", string.Empty);
} public static string GetNewCode(string parentCode)
{
string currentMaxCode = "";
string newCode = $"{parentCode}{currentMaxCode}";
return newCode; }
}
我们隐藏这些方法的具体实现,只预览他们的之间的关系:

接下来,线程即将进入到下面的这个方法:
void GetProduct()
{
BaseProduct p;
string sourceCode;
p = new Product();
sourceCode = p.GetCode();
sourceCode = Product.GetNewCode(sourceCode);
}
JIT在编译到此方法前会注意到这个方法所有的引用类型,
并向CLR发出通知,加载程序集,在托管对中创建相关的类型对象数据结构。
这也就是我们所能理解的静态字段为什么不是在实例化的时候创建,
而是在这个类型创建的时候就一直存在。
这其实就是两个概念,静态资源是属于类结构的,而实例资源时属于实例本身。
下面的图忽略String类型,因为String类型是常用类型可能在之前就已经创建好了,
类型对象包括:对象指针、同步块索引、静态资源、方法表,像下面这样:
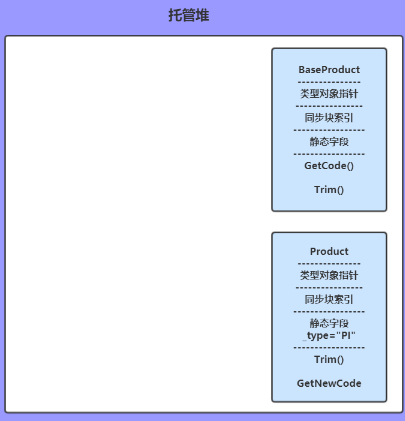
BaseProduct p;
string sourceCode;
方法变量入栈,并且引用类型初始化为null

p = new Product();
实例化Product ,托管堆创建Product对象,并将这个对象的指针指向Product类型。
将线程栈中的变量p指针,指向新创建的Product对象。

sourceCode = p.GetCode();
JIT找到这个变量p的Product对象,再找到对应的Product类型,表中找到此方法GetCode();
当然这个方法实际是父类的方法,所以JIT会一直向上找,直到找到为止。
图中是个虚拟路线,计算结果赋值给 string sourceCode
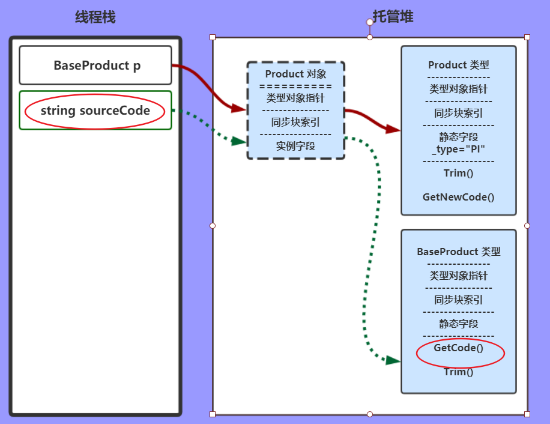
sourceCode = Product.GetNewCode(sourceCode);
和上一步类似,只不过这次是调用的静态方法。发出类型Product,静态方法是GetNewCode()
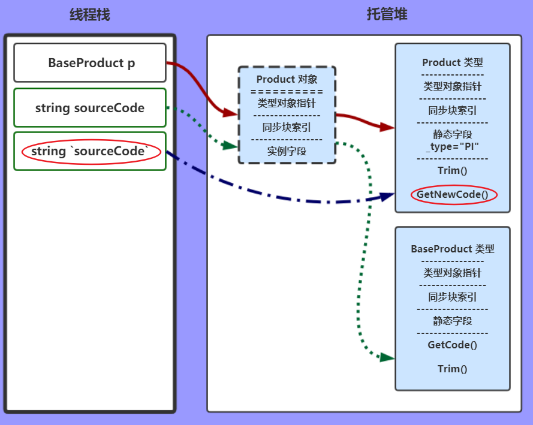
以上内容就是 JIT、CLR、线程栈、托管堆的一些运行时关系。
本文链接:https://www.cnblogs.com/sunchong/p/10011657.html,欢迎转载,如有不对的地方希望指正。
我们部门运营的公众号,里面有很多技术文章和最新热点,欢迎关注:


栈到CLR的更多相关文章
- .Net 类型、对象、线程栈、托管堆运行时的相互关系
JIT(just in time)编译器 接下来的会讲到方法的调用,这里先讲下JIT编译器.以CLR书中的代码为例(手打...).以Main方法为例: static void Main(){ Cons ...
- 【.Net基础一】 类型、对象、线程栈、托管堆运行时的相互关系
目前在看CLR via C#,把总结的记下来,索性就把他写成一个系列吧. 1.[.Net基础一] 类型.对象.线程栈.托管堆运行时的相互关系 2.[.Net基础二]浅谈引用类型.值类型和装箱.拆箱 J ...
- hdu 1506 单调栈问题
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1506 题目的意思其实就是要找到一个尽可能大的矩形来完全覆盖这个矩形下的所有柱子,只能覆盖柱子,不能留空 ...
- C#.Net GC(garbage Collector) 垃圾回收器
以前一直以为gc的原理很简单,也就是分代处理堆数据,直到我的膝盖中了一箭(好吧 直到有天汪涛和我说他面试携程的面试题 关于服务器和 工作站gc 的区别)其实我当时尚不知道 工作站和服务器有什么区别更不 ...
- .NET垃圾回收机制 转
在.NET Framework中,内存中的资源(即所有二进制信息的集合)分为"托管资源"和"非托管资源".托管资源必须接受.NET Framework的CLR( ...
- .net垃圾收集机制【转】
在.NET Framework中,内存中的资源(即所有二进制信息的集合)分为"托管资源"和"非托管资源".托管资源必须接受.NET Framework的CLR( ...
- [CLR via C#]4. 类型基础及类型、对象、栈和堆运行时的相互联系
原文:[CLR via C#]4. 类型基础及类型.对象.栈和堆运行时的相互联系 CLR要求所有类型最终都要从System.Object派生.也就是所,下面的两个定义是完全相同的, //隐式派生自Sy ...
- 类型,对象,线程栈,托管堆在运行时的关系,以及clr如何调用静态方法,实例方法,和虚方法(第二次修改)
1.线程栈 window的一个进程加载clr.该进程可能含有多个线程,线程创建的时候会分配1MB的栈空间. 如图: void Method() { string name="zhangsan ...
- .NET全栈开发工程师学习路径
PS:最近一直反复地看博客园以前发布的一条.NET全栈开发工程师的招聘启事,觉得这是我看过最有创意也最朴实的一个招聘启事,更为重要的是它更像是一个技术提纲,能够指引我们的学习和提升,现在转载过来与各位 ...
随机推荐
- linux下实时查看tomcat运行日志 2017.12.4
1.先切换到:cd usr/local/tomcat5/logs 2.tail -f catalina.out 3.这样运行时就可以实时查看运行日志了
- java 基础之 反射技术
1. java代码 在 java 语言中最核心的就是代码的运行, 按照面向对象的思想,在调用java代码时往往需要先创建对象,再调用方法, 而写在方法中的即所谓的java 代码 一段java代码在程序 ...
- celery学习笔记1
生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类.函数.线程.进程等).产生数据的模块,就形象地称为生产 ...
- Python replace()方法
描述 Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次. 语法 replace()方法语法: st ...
- Dubbo中订阅和通知解析
Dubbo中关于服务的订阅和通知主要发生在服务提供方暴露服务的过程和服务消费方初始化时候引用服务的过程中. 2345678910111213141516171819 public <T> ...
- Volley手写属于自己的万能网络访问框架
用户在调用层(Activity或Service中),发起一个网络请求,该请求肯定包含url,请求参数(requestParameter),以及我们需要给调用层提供一个请求成功或失败以后回调监听的接口d ...
- exgcd学习笔记
扩展欧几里得算法是当已知a和b时,求得一组x和y使得 首先,根据数论中的相关定理,解一定存在 //留坑待填 之后我们可以推一推式子 将a替换掉 展开括号 提出b,合并 且 设 现在已经将 ...
- 基于SDRAM的视频图像采集系统
本文是在前面设计好的简易SDRAM控制器的基础上完善,逐步实现使用SDRAM存储视频流数据,实现视频图像采集系统,CMOS使用的是OV7725. SDRAM控制器的完善 1. 修改SDRAM的时钟到1 ...
- SQL Server 容易忽略的错误
一.概述 因为每天需要审核程序员发布的SQL语句,所以收集了一些程序员的一些常见问题,还有一些平时收集的其它一些问题,这也是很多人容易忽视的问题,在以后收集到的问题会补充在文章末尾,欢迎关注,由于收集 ...
- 【STM32H7教程】第10章 STM32H7的FLASH,RAM和栈使用情况(map和htm文件)
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第10章 STM32H7的FLASH,RAM ...