[Inside HotSpot] C1编译器HIR的构造
1. 简介
这篇文章可以说是Christian Wimmer硕士论文Linear Scan Register Allocation for the Java HotSpot™ Client Compiler的不完整翻译,这篇论文详细论述了HotSpot JIT编译器的架构,然后描述了C1编译器(研究用,细节和Sun的Client编译器生产级实现有些许出入)中线性扫描寄存器分配算法的设计和实现。
C1编译器内部使用HIR,LIR做为中间表示并进行系列优化和寄存器分配。字节码到HIR的构造是最先完成的步骤,其中HIR是一个平台无关的图结构IR,它的构造位于hotspot\share\c1\c1_IR.cpp,整个源码的层次如下:
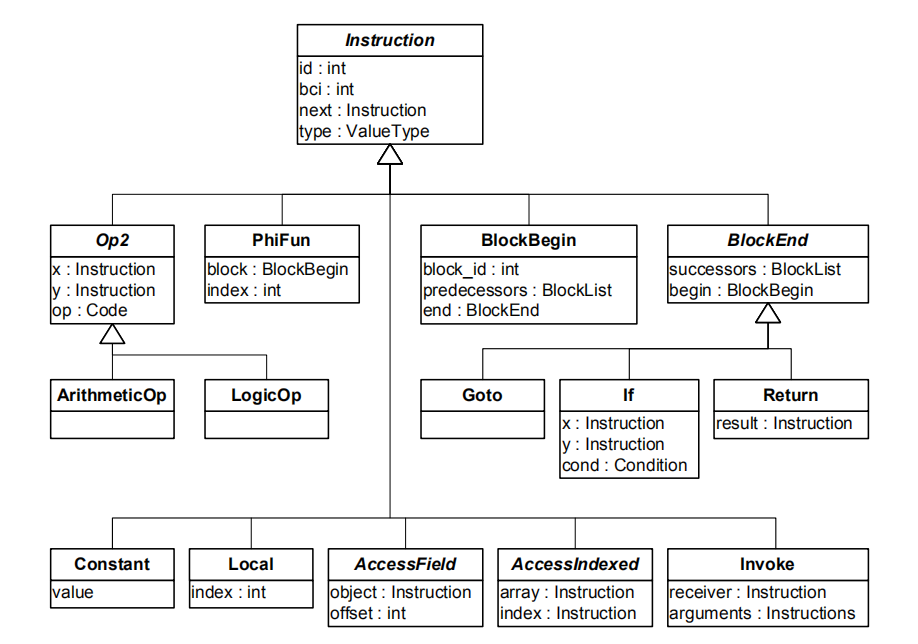
上面是不完整的类层次图,列举了最重要的类。所有的指令都是继承自Instruction:
class Instruction: public CompilationResourceObj {
private:
int _id; // 指令id
int _use_count; // 值的使用计数
int _pin_state; // pin的原因
ValueType* _type; // 指令类型
Instruction* _next; // 下一个指令(如果下一个是BlockEnd则为null)
Instruction* _subst; // 替换指令,如果有的话。。
LIR_Opr _operand; // LIR operand信息
unsigned int _flags; // flag信息
ValueStack* _state_before; // Copy of state with input operands still on stack (or NULL)
ValueStack* _exception_state; // Copy of state for exception handling
XHandlers* _exception_handlers; // Flat list of exception handlers covering this instruction
protected:
BlockBegin* _block; // 包含该指令的Block的指针
..
};
2. HIR的设计
BlockBegin表示一个基本块的开始,BlockEnd表示结束,两者有一个指针相连,这样可以快速的遍历控制流图,而不需要经过基本块中间的指令。BlockBegin的字段predecessors表示前驱基本块,由于前驱可能是多个,所以是BlockList结构,BlockList是GrowableArray<BlockBegin*>,即多个BlockBegin组成的可扩容数组。同理,BlockEnd的successors表示多个后继基本块。
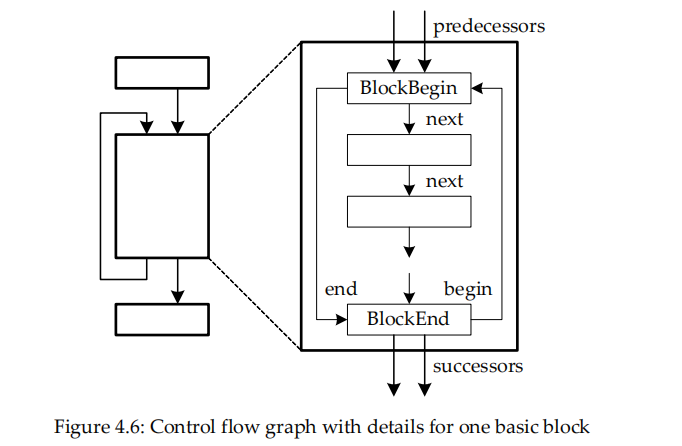
基本块除了BlockBegin,BlockEnd之外就是主体部分,这一部分由具体的Instruction子类组成,每个Instruction有一个next指针(见上面源码),以此可以构成Instruction链表。
3. 高观点层次的字节码到HIR构造
在[Inside HotSpot] C1编译器工作流程及中间表示我们提到build_hir()这个函数会执行HIR的构造,HIR的优化。从字节码到HIR的构造最终调用的是GraphBuilder。
GraphBuilder首先使用BlockListBuilder遍历字节码构造所有基本块,然后储存为一个链表结构,即之前提到的GrowableArray<BlockBegin*>,但是这个时候的基本块只有BlockBegin,不包括具体的字节码。第二步GraphBuilder用一个ValueStack作为操作数栈和局部变量表,模拟执行字节码,构造出对应的HIR,填充之前空的基本块:
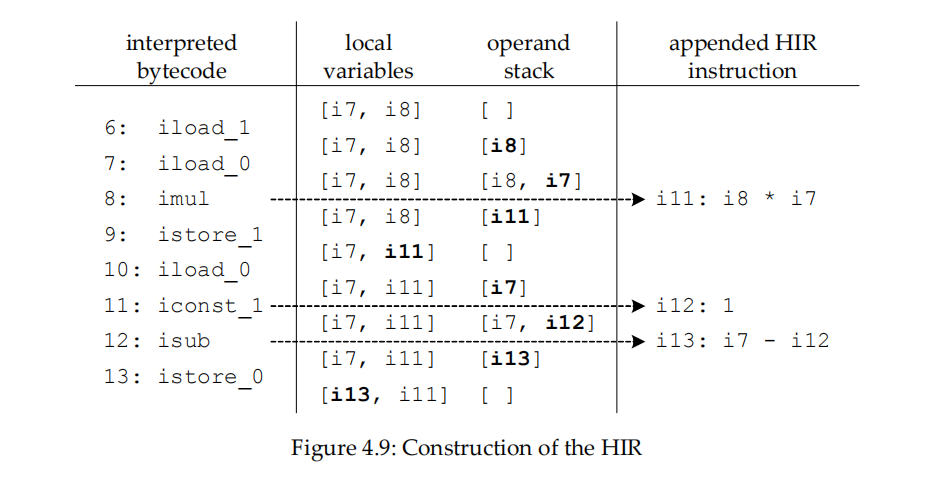
上图是非常直观的构造过程,上面的local variable和operand stack位于ValueStack里面,当执行iload_1时候,局部变量表的索引1位置的变量i8压入操作数栈;执行iload_0压入i7到操作数栈(下文用栈代替),imul弹出栈顶两个值,然后构造出HIR指令i11 = i8 * i7,然后根据imul的语义生成的i11入栈;istore_1弹出栈的数据保存到局部变量表;iconst_1构造出HIR指令i12 = 1然后压入i12,;isub弹出栈顶做减法,构造出i13 = i7 - i12,将i13压入栈;最后istore_0弹出栈顶i13写入局部变量表。
4. 源码层次的字节码到HIR构造
明白高观点下字节码是如何构造出HIR的,源码层次也变得很容易理解了。ValueStack表示用于模拟字节码执行的操作数栈和局部变量表:
// hotspot\share\c1\c1_ValueStack.hpp
class ValueStack: public CompilationResourceObj {
public:
enum Kind {
Parsing, // During abstract interpretation in GraphBuilder
CallerState, // Caller state when inlining
StateBefore, // Before before execution of instruction
StateAfter, // After execution of instruction
ExceptionState, // Exception handling of instruction
EmptyExceptionState, // Exception handling of instructions not covered by an xhandler
BlockBeginState // State of BlockBegin instruction with phi functions of this block
};
private:
IRScope* _scope; // the enclosing scope
ValueStack* _caller_state;
int _bci;
Kind _kind;
Values _locals; // the locals
Values _stack; // the expression stack
Values _locks; // the monitor stack (holding the locked values)
...
};
然后GraphBuilder的模拟过程如下:
// hotspot\share\c1\c1_GraphBuilder.cpp
// 加载局部变量表的值到栈
void GraphBuilder::load_local(ValueType* type, int index) {
Value x = state()->local_at(index);
assert(x != NULL && !x->type()->is_illegal(), "access of illegal local variable");
push(type, x);
}
// 储存栈的值到局部变量表
void GraphBuilder::store_local(ValueType* type, int index) {
Value x = pop(type);
store_local(state(), x, index);
}
// 逻辑运算
void GraphBuilder::logic_op(ValueType* type, Bytecodes::Code code) {
Value y = pop(type);
Value x = pop(type);
push(type, append(new LogicOp(code, x, y)));
}
// 比较运算
void GraphBuilder::compare_op(ValueType* type, Bytecodes::Code code) {
ValueStack* state_before = copy_state_before();
Value y = pop(type);
Value x = pop(type);
ipush(append(new CompareOp(code, x, y, state_before)));
}
按照JVM虚拟机规范上字节码的语义来。比如上面的logic_op即从操作数栈弹出两个值,然后做逻辑运算,具体逻辑运算类型用code表示。除了这些常规的指令模拟外,还有些特殊指令可能会在模拟之外增加一些内容,比如在分层编译模式下goto和if指令可能增加回边计数等profiling信息。
[Inside HotSpot] C1编译器HIR的构造的更多相关文章
- [Inside HotSpot] C1编译器优化:全局值编号(GVN)
1. 值编号 我们知道C1内部使用的是一种图结构的HIR,它由基本块构成一个图,然后每个基本块里面是SSA形式的指令,关于这点如可以参考[Inside HotSpot] C1编译器工作流程及中间表示. ...
- [Inside HotSpot] C1编译器优化:条件表达式消除
1. 条件传送指令 日常编程中有很多根据某个条件对变量赋不同值这样的模式,比如: int cmov(int num) { int result = 10; if(num<10){ result ...
- [Inside HotSpot] C1编译器工作流程及中间表示
1. C1编译器线程 C1编译器(aka Client Compiler)的代码位于hotspot\share\c1.C1编译线程(C1 CompilerThread)会阻塞在任务队列,当发现队列有编 ...
- C1编译器的实现
总览 词法.语法分析 分析方案 词法 语法 符号表 类型系统 AST 语义检查 EIR代码生成器 MIPS代码生成器 寄存器分配 体系结构相关特性优化 使用说明 编译 运行 总览 C1语言编译器及流程 ...
- [inside hotspot] 汇编模板解释器(Template Interpreter)和字节码执行
[inside hotspot] 汇编模板解释器(Template Interpreter)和字节码执行 1.模板解释器 hotspot解释器模块(hotspot\src\share\vm\inter ...
- [Inside HotSpot] Java分代堆
[Inside HotSpot] Java分代堆 1. 宇宙初始化 JVM在启动的时候会初始化各种结构,比如模板解释器,类加载器,当然也包括这篇文章的主题,Java堆.在hotspot源码结构中gc/ ...
- [Inside HotSpot] Java的方法调用
1. 方法调用模块入口 Java所有的方法调用都会经过JavaCalls模块.该模块又细分为call_virtual调用虚函数,call_static调用静态函数等.虚函数调用会根据对象类型进行方法决 ...
- [Inside HotSpot] 模板解释器
0. 简介 众所周知,hotspot默认使用解释+编译混合(-Xmixed)的方式执行代码.它首先使用模板解释器对字节码进行解释,当发现一段代码是热点的时候,就使用C1/C2 JIT进行优化编译再执行 ...
- [Inside HotSpot] hotspot的启动流程与main方法调用
hotspot的启动流程与main方法调用 虚拟机的使命就是执行public static void main(String[])方法,从虚拟机创建到main方法执行会经过一系列流程.这篇文章详细讨论 ...
随机推荐
- java之Hibernate框架实现数据库操作
之前我们用一个java类连接MySQL数据库实现了数据库的增删改查操作---------MySQL篇: 但是数据库种类之多,除了MySQL,还有Access.Oracle.DB2等等,而且每种数据库语 ...
- yii2实战之初见端倪
PHP框架大PK php框架有很多种,在国内应用较多的有:Thinkphp, Yii, Laravel, Codeigniter等.关于这些框架,孰优孰劣,是一个极具争议性的话题.各方支持者总能拿出自 ...
- Qt5.7 实现Https 认证全过程解析(亲自动手版)
#### NetworkRequestManager.h #include <QSsl>#include <QSslKey>#include <QSslSocket> ...
- MySQL分组、链接的使用
一.深入学习 group by group by ,分组,顾名思义,把数据按什么来分组,每一组都有什么特点. 1.我们先从最简单的开始: select count(*) from tb1 group ...
- Python零散函数
1. python json.dumps() json.dump()的区别 注意cat ,是直接输出文件的内容 load和loads都是实现"反序列化",区别在于(以Python为 ...
- Caused by: android.view.InflateException: Binary XML file line #2: Error inflating class android.sup
解决:找不到资源文件: 系统会根据分辨率来选择加载不同drawable下文件夹的资源,如果只在一个文件下放了资源文件,不同的分辨率设备的会报错.
- python之Flask实现登录功能
网站少不了要和数据库打交道,归根到底都是一些增删改查操作,这里做一个简单的用户登录功能来学习一下Flask如何操作MySQL. 用到的一些知识点:Flask-SQLAlchemy.Flask-Logi ...
- Tiny4412之按键驱动
一:按键驱动 按键驱动跟之前的LED,蜂鸣器的方法类似:通过底板,核心板我们可以看到按键的电路图: 通过电路图我们可以看出,当按键按下去为低电平,松开为高电平:所以我们要检测XEINT26的状态,通过 ...
- 【转】java中equal与==的区别 其中有个缓冲区,需要注意
转自http://www.cnblogs.com/dolphin0520/p/3592500.html 在学Java时,可能会经常碰到下面的代码: 1 String str1 = new String ...
- Git Push:error: Couldn't set refs/remotes/origin/master;error: update_ref failed for ref 'refs/remot
作者:荒原之梦 原文链接:http://zhaokaifeng.com/?p=543 今天使用Git Push代码时产生错误: Rename from 'XXXX/.git/refs/remotes/ ...