Spark学习之编程进阶总结(二)
五、基于分区进行操作
基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作。诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作。Spark 提供基于分区的 map 和 foreach ,让你的部分代码只对 RDD 的每个分区运行一次,这样可以帮助降低这些操作的代价。
当基于分区操作 RDD 时,Spark 会为函数提供该分区中的元素的迭代器。返回值方面,也返回一个迭代器。除 mapPartitions() 外,Spark 还有一些别的基于分区的操作符,列在了表中。

1、mapPartitions
与map类似,不同点是map是对RDD的里的每一个元素进行操作,而mapPartitions是对每一个分区的数据(迭代器)进行操作,具体可以看上面的表格。下面同时用map和mapPartitions实现WordCount,看一下mapPartitions的用法以及与map的区别。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
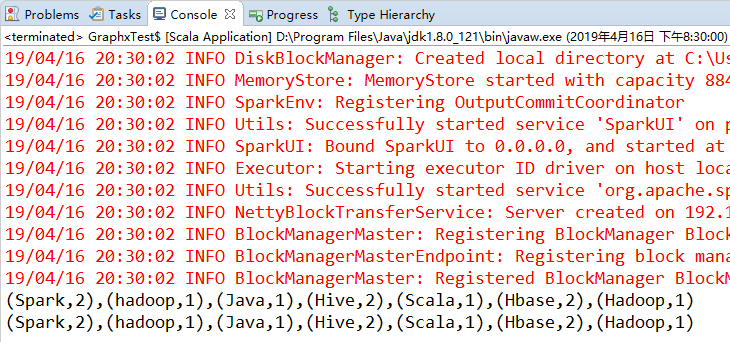
sc.setLogLevel("WARN") // 设置日志显示级别 val input = sc.parallelize(Seq("Spark Hive hadoop", "Hadoop Hbase Hive Hbase", "Java Scala Spark"))
val words = input.flatMap(line => line.split(" "))
val counts = words.map(word => (word, 1)).reduceByKey { (x, y) => x + y }
println(counts.collect().mkString(","))
val counts1 = words.mapPartitions(it => it.map(word => (word, 1))).reduceByKey { (x, y) => x + y }
println(counts1.collect().mkString(",")) }
}
2、mapPartitionsWithIndex
和mapPartitions一样,只是多了一个分区的序号,下面的代码实现了将Rdd的元素数字n变为(分区序号,n*n)。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别 val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
val res = rdd.mapPartitionsWithIndex((index, it) => {
it.map(n => (index, n * n))
})
println(res.collect().mkString(" ")) }
}

3、foreachPartitions
foreachPartitions和foreach类似,不同点也是foreachPartitions基于分区进行操作的。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
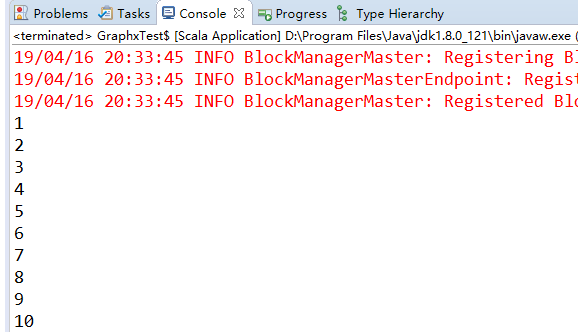
val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
rdd.foreachPartition(it => it.foreach(println)) }
}
六、与外部程序间的管道
Spark 提供了一种通用机制,可以将数据通过管道传给用其他语言编写的程序,比如 R 语言脚本。
Spark 在 RDD 上提供 pipe() 方法。Spark 的 pipe() 方法可以让我们使用任意一种语言实现 Spark 作业中的部分逻辑,只要它能读写 Unix 标准流就行。通过 pipe() ,你可以将 RDD 中的各元素从标准输入流中以字符串形式读出,并对这些元素执行任何你需要的操作,然后把结果以字符串的形式写入标准输出——这个过程就是 RDD 的转化操作过程。这种接口和编程模型有较大的局限性,但是有时候这恰恰是你想要的,比如在 map 或filter 操作中使用某些语言原生的函数。
有时候,由于你已经写好并测试好了一些很复杂的软件,所以会希望把 RDD 中的内容通过管道交给这些外部程序或者脚本来进行处理并重用。很多数据科学家都用 R写好的代码 ,可以通过pipe() 与 R 程序进行交互。
七、数值RDD的操作
Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回。表列出了 StatsCounter 上的可用方法。

如果你只想计算这些统计数据中的一个,也可以直接对 RDD 调用对应的方法,比如 rdd.mean() 或者 rdd.sum() 。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val rdd = sc.parallelize(List(1,2,3,4))
val res = rdd.stats
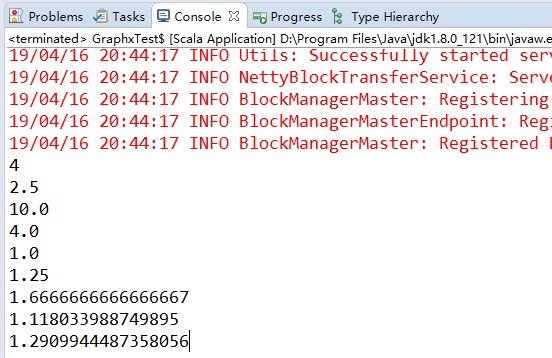
println(res.count) // 4 统计元素个数
println(res.mean) // 2.5 平均值
println(res.sum) // 10 总和
println(res.max) // 4 最大值
println(res.min) // 1 最小值
println(res.variance) // 1.25 方差
println(res.sampleVariance) //1.667 采样方差
println(res.stdev) // 1.11803 标准差
println(res.sampleStdev) //1.29099 采样标准差
}
}
这篇博文主要来自《Spark快速大数据分析》这本书里面的第六章,内容有删减,还有关于本书的一些代码的实验结果。
Spark学习之编程进阶总结(二)的更多相关文章
- Spark学习之编程进阶——累加器与广播(5)
Spark学习之编程进阶--累加器与广播(5) 1. Spark中两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器对信息进行聚合,而广播变 ...
- Spark学习之编程进阶总结(一)
一.简介 这次介绍前面没有提及的 Spark 编程的各种进阶特性,会介绍两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器用来对信息进行聚合 ...
- Java多线程编程——进阶篇二
一.线程的交互 a.线程交互的基础知识 线程交互知识点需要从java.lang.Object的类的三个方法来学习: void notify() 唤醒在此对象监视器上等待的单个 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark函数式编程进阶
函数式编程进阶 1.函数和变量一样作为Scala语言的一等公民,函数可以直接复制给变量: 2.函数更长用的方式是匿名函数,定义的时候只需要说明输入参数的类型和函数体即可,不需要名称,但是匿名函数赋值给 ...
- python学习_数据处理编程实例(二)
在上一节python学习_数据处理编程实例(二)的基础上数据发生了变化,文件中除了学生的成绩外,新增了学生姓名和出生年月的信息,因此将要成变成:分别根据姓名输出每个学生的无重复的前三个最好成绩和出生年 ...
随机推荐
- 基于RecyclerView的瀑布流实现
fragment的布局: <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xm ...
- require './ex25' can't load such file
require './ex25' can't load such file 在练习learn ruby the hard way时候,第25题,发生了一下错误 LoadError: cannot lo ...
- 常用的几个在线生成网址二维码的API接口
原创,转载请注明出处! 用接口的好处就是简单,方便,时时更新,二维码生成以后不用保存在本项目服务器上面,可以减少不必要的开支,无需下载安装什么软件,可简单方便地引用,这才是最便捷的免费网址二维码生成 ...
- AE的空间分析(转载)
1.1 ITopologicalOperator接口 1.1.1 ITopologicalOperator接口简介ITopologicalOperator接口用来通过对已存在的几何对象做空间拓扑运算以 ...
- jquery touch 移动端上下滑动加载
var touchStart, touchEnd, touchDiff = 80; $(window).on({ 'touchstart': function (e) { touchStart = e ...
- HTML学习笔记8:表单
什么是表单? 一个网页表单可以将用户输入的数据发送到服务器进行处理.因为互联网用户使用复选框,单选按钮或文本字段填写表格,所以WebForms的形式类似文件或数据库.例如,WebForms ...
- Android自动化框架介绍
随着Android应用得越来越广,越来越多的公司推出了自己移动应用测试平台.例如,百度的MTC.东软易测云.Testin云测试平台…….由于自己所在项目组就是做终端测试工具的,故抽空了解了下几种常见的 ...
- Python_字符串检测与压缩
''' center().ljust().rjust(),返回指定宽度的新字符串,原字符串居中.左对齐或右对齐出现在新字符串中, 如果指定宽度大于字符串长度,则使用指定的字符(默认为空格进行填充). ...
- String的substring()用于截取字符串
substring() 用于返回一个字符串的子字符串,即截取字符串功能. substring()常用的重载方法如下: substring(int beginIndex,int endIndex) 意思 ...
- java线程interrupt、interrupted 、isInterrupted区别
前言 在分析interrupt之前,应该先了解java里线程有5种状态,其中有一个阻塞状态,interrupt和阻塞有关. interrupt() 方法 作用于要中断的那个线程. interrupt( ...