Mysql--执行计划 Explain
===============
0 介绍
0.1 是什么
使用 Explain 关键字可以模拟优化器执行 Sql 查询语句,从而知道 Mysql 是如何处理 Sql 的。
0.2 用法
Explain + Sql语句
0.3 执行计划包含的信息
如下图:
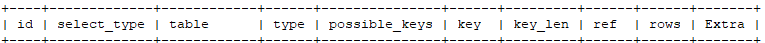
接下来,将对这 10 个表头中的字段一一进行说明。
1 id
1.1 概念
Select 查询的序列号,包含一组数字,表示查询中执行 Select 子句或操作表的顺序
1.2 三种情况
1.2.1 ID相同,执行顺序由上至下
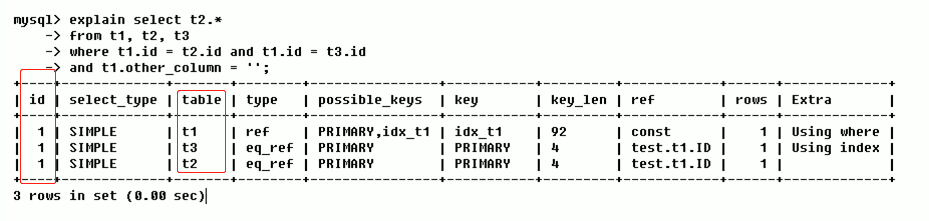
如上图,Mysql 认为三个ID相同均为1;于是,执行顺序由上至下;所以,Mysql 会按照 t1 --> t3 --> t2 的顺序加载这三张表。
1.2.2 ID不同,值越大优先级超高,越先被执行
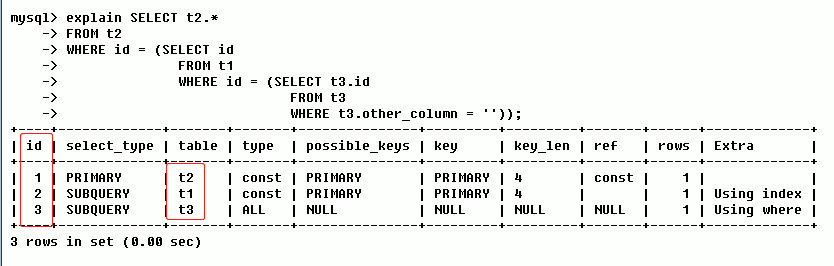
如上图,Mysql 认为三个ID不相同(分别为 1,2,3);于是,先执行值大的;所以,Mysql 会按照 t3 --> t1 --> t2 的顺序加载这三张表。
提示:如果是子查询,ID的序号会递增(如上图,id=2 & id=3 的这两项就是子查询 SUBQUERY)。
1.2.3 ID相同不同,同时存在
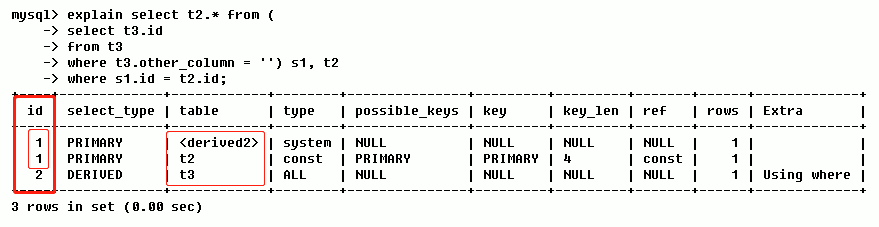
如上图,ID 存在两种值(分别是 id = 1 & id = 2);值大的先执行,于是,id=2 的先执行,对应就是 t3 表先加载;然后是两个 id=1 的,又按照由上至下的执行顺序,于是,先加载 derived2 表后加载 t2 表。所以这三张表最终的加载顺序就是 t3 --> derived2 --> t2。
提示:derived2 中的 2 表示衍生自 id=2 的那条记录(即衍生自 t3 表)
1.3 结论
ID值越大越先被执行,如果ID相同则由上至下执行
2 select_type
有以下 6 种取值:
- SIMPLE
- PRIMARY
- SUBQUERY
- DERIVED
- UNION
- UNION RESULT
3 table
显示这一行的数据是关于哪张表的
4 type--非常重要--非常重要--非常重要
4.1 介绍
type是指:访问类型
从最好到最差依次是:system > const > eq_ref > ref > range > index > all
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
4.2 详细说明
4.2.0 数据准备
DROP TABLE IF EXISTS employee;
CREATE TABLE IF NOT EXISTS employee(
id INT PRIMARY KEY auto_increment,
name VARCHAR(40),
dept_id INT
);
INSERT INTO employee(name, dept_id) VALUES('Alice', 1);
INSERT INTO employee(name, dept_id) VALUES('Alice2', 1);
INSERT INTO employee(name, dept_id) VALUES('BOb', 2);
INSERT INTO employee(name, dept_id) VALUES('BOb2', 2); DROP TABLE IF EXISTS department;
CREATE TABLE IF NOT EXISTS department(
id INT PRIMARY KEY auto_increment,
name VARCHAR(40)
);
INSERT INTO department(name) VALUES('RD');
INSERT INTO department(name) VALUES('HR');
数据说明:2个部门,4个员工,每个部门两个员工
4.2.1 const
表示通过索引一次就找到了,用于比较主键索引或者唯一性索引。如将主键置于 Where 条件中,Mysql 就能将该查询转换为一个常量
Sql语句:
EXPLAIN SELECT * FROM employee WHERE id = 1;
结果:

说明:id 是主键,将 id = 1(常量)置于 WHERE 条件中,于是,结果是 Const
4.2.2 system
表只有一行记录,是 Const 的特例,平时不会出现,可忽略
Sql语句:
EXPLAIN SELECT * FROM (SELECT * FROM employee WHERE id = 1) e;
结果:

说明:由于括号中的查询只会返回唯一结果,所以,外层再查询时就只有一条记录,于是,结果是 System
4.2.3 eq_ref
唯一性索引扫描。对于每个索引键表中只有一条记录与之匹配。常见于主键或唯一索引扫描
Sql语句:
EXPLAIN SELECT * FROM employee e, department d WHERE e.id = d.id;
结果:

说明:WHERE 条件中是 e.id = d.id,其左边是 e.id,即是 Employee 表的主键;主键肯定是唯一的,所以,Mysql 在查询索引时,肯定能得到唯一结果,于是 type = eq_ref。
提示:这里的 kye = PRIMARY(后面会用到)
这个例子本身不太好,因为员工ID和部门ID本来就不会有什么关系(对于真实应用来说)///////////////////////////////////////////////////////////TODO
4.2.4 ref
非唯一性索引扫描,返回匹配某个单独值的所有行
先来执行一下Sql语句:
SELECT * FROM employee e, department d WHERE e.dept_id = d.id;
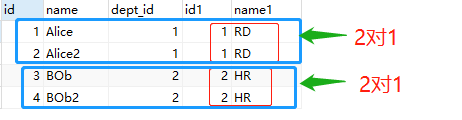
从员工的角度可以看到,员工与部门是多对一的关系(这也符合客观实际 ;此处数据是2对1关系)
执行一下Explain:
EXPLAIN SELECT * FROM employee e, department d WHERE e.dept_id = d.id;

可以看到,两张表都是 ALL,效果不理想;所以为了提升性能,需要为 Employee 表的 dept_id 字段建立索引(也是为了方便后续行文);
建立索引:
CREATE INDEX idx_deptId ON employee(dept_id);
再来Explain一下刚才的Sql语句:
EXPLAIN SELECT * FROM employee e, department d WHERE e.dept_id = d.id;
现在的结果:

可以看到,现在的 type = ref & key = idx_deptId(我们创建的索引)。
提示:注意和前面 eq_ref 进行对比;
- 在 eq_ref 中,type = eq_ref & key = PRIMARY;
- 我们重点通过 Key 的不同来进行比较;
- 对于 eq_ref 而言,其 Key = PRIMARY 且 PRIMARY 肯定是唯一的,所以,其 type = eq_ref;
- 对于 ref 而言,其 Key = idx_deptId 但 dept_id 字段的值不是唯一的(详见前文),所以,其 type = ref;
对于 eq_ref & ref 的总结就是:都会使用索引,但使用索引进行检索后的结果不同,前者的结果是唯一的、后者的结果不唯一。所以,前者通常用于主键或唯一性索引扫描,而后者通常用于非唯一性索引扫描。
4.2.5 range
只检索给定范围的行,使用一个索引来选择行;Key 列显示使用了哪个索引;一般就是在 Where 条件中出现了 between, <, >, in 等查询;它比全索引扫描要好,因为它开始于索引的某一点、且结束于另一点,而不用全索引扫描;
Sql语句:
EXPLAIN SELECT * FROM employee WHERE id > 1;
结果:

4.2.6 index
全索引扫描;只遍历索引树;index & all 都是全表扫描,但是 Index 是从索引中读取,而 All 是从磁盘中读取
Sql语句:
EXPLAIN SELECT id, dept_id FROM employee
结果:

说明:查询的是 id & dept_id,而它们两者都有索引(即都在索引列上),所以,可以通过扫描索引来完成,于是 type = index
4.2.7 all
全表扫描;磁盘扫描
Sql语句:
EXPLAIN SELECT * FROM employee;
结果:

说明:SELECT * 在此处等于 SELECT id, name, dept_id 三个字段,但是由于 name 字段没有索引,所以 Mysql 不得不全表扫描(全磁盘扫描)以获取 name 的值,于是,type = all
5 possible_keys
显示理论上有可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被实际使用。
6 key
实际使用的索引。如果为 Null,则没有使用索引。
查询中若使用了覆盖索引,则该索引只会出现在 Key 列表中(即不会出现在 possible_keys 列中)。
接下来,以真实例子进行演示。
6.1 key = Null
6.1.1 possible_keys = Null
Sql语句:
EXPLAIN SELECT * FROM employee;
结果:

说明:key = Null 且 type = ALL,没有使用上索引,全表扫描。
6.1.2 possible_keys != Null
Sql语句:
EXPLAIN SELECT * FROM employee e, department d WHERE e.dept_id = d.id;
结果:

分析:
对于 Department 表,Mysql 认为这是根据 d.id 主键来查询,故认为 possible_keys = PRIMARY,但实际上由于查询字段是 SELECT * 所以是全表扫描,于是,key = Null
6.2 key != Null
6.2.1 possible_keys = Null
Sql语句:
EXPLAIN SELECT id, dept_id FROM employee;
结果:

分析:
- 因为没有使用 Where 进行限制,所以 Mysql 认为这是全表扫描,所以,possible_keys = Null
- 但是由于查询的字段 id & dept_id 都在索引列上,所以,Mysql 实际上通过扫描索引来完成查询操作,于是,key = idx_deptId
6.2.1 possible_keys != Null
Sql语句:
EXPLAIN SELECT id, dept_id FROM employee WHERE id > 1;
结果:

分析:通过 id 进行条件限制,自然是能使用上索引的
7 key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。
显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的。
8 ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。表示哪些列或常量被用于查找索引列上的值。
下面以真实例子进行演示。
8.1 ref = const
Sql语句:
EXPLAIN SELECT * FROM employee WHERE id = 1;
结果:

分析:
因为 WHERE = 1,这是一个常量,所以,ref = const
8.2 ref = dbName.tableName.filedName
Sql语句:
EXPLAIN SELECT * FROM employee e, department d WHERE e.dept_id = d.id;
结果:

分析:
- ref = cyhtest.d.id
- cyhtest 是数据库名称,d 是表名,id 是 d 表(Department表)中的字段
- 表示 cyhtest.d.id 这一列的值被用来作为 e.dept_id 这一列中的索引进行查找的值(是指:假如 cyhtest.d.id = 2 则 e.dept_id 会使用索引来查找 e.dept_id = 2 的记录)
9 rows
根据表统计信息及索引选用情况,大致估算出找到所需记录所需要读取的行数。值越小越好。
10 extra
10.1 Using Filesort
说明 Mysql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行排序;Mysql 中无法利用索引完成的排序操作称为“文件排序”。
下面以真实例子进行演示。
10.1.1 会出现 Using Filesort
Sql语句:
EXPLAIN SELECT id FROM employee e ORDER BY e.name;
结果:

分析:name 不在索引上,根据它来排序,就会出现 Using Filesort,因为 Mysql 无法利用索引完成排序操作。
10.1.2 不会出现 Using Filesort
Sql语句:
EXPLAIN SELECT id FROM employee e ORDER BY e.dept_id;
结果:

分析:dept_id 在索引列上,Mysql 就可以直接根据它完成排序操作,所以不会出现 Using Filesort
10.1.3 总结
出现 Using Filesort 是九死一生的操作、比较危险,需要优化。
10.2 Using Temporary
使用了临时表保存中间结果,Mysql 在查询结果排序时使用临时表,常见于 ORDER BY 和 GROUP BY。
10.2.1 会出现 Using Temporary
Sql语句:
EXPLAIN SELECT id FROM employee e GROUP BY e.name;
结果:

说明:name 字段不在索引上,Mysql 无法利用索引完成排序和分组操作。
10.2.2 不会出现 Using Temporary
Sql语句:
EXPLAIN SELECT id FROM employee e GROUP BY e.dept_id;
结果:

分析:dept_id 字段在索引列上,所以 Mysql 就可以直接利用索引完成排序和分组操作。
10.2.3 总结
出现 Using Temporary 是十死无生的操作、火烧眉毛、亟待解决,必须优化。
10.3 Using Index
表示相应的 SELECT 操作中使用了覆盖索引,避免访问了表的数据行,效率不错;如果同时出现 Using Where,表明索引被用来执行索引键值的查找;如果没有出现 Using Where,表明索引用来读取数据而非执行查找动作。
一个同时出现 Using Where 的例子。
Sql语句:
EXPLAIN SELECT id FROM employee e WHERE e.dept_id > 1 GROUP BY e.dept_id;
结果:
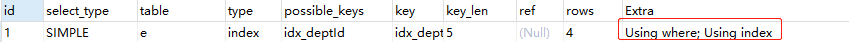
分析:加了一个 Where 条件,于是出现了 Using Where(注意和上一个例子进行对比)。
11 总结
11.1 重要的字段
type, key, ref, extra 是 Explain 分析结果中非常重要的字段。
11.2 type
从最好到最差依次是:system > const > eq_ref > ref > range > index > all
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
11.3 key
最好不要为 Null,否则就是没有使用上索引。
11.4 extra
最好是 Using Index,Using Where,一定不能出现 Using Filesort,Using Temporary。
Mysql--执行计划 Explain的更多相关文章
- MySQL 执行计划explain详解
MySQL 执行计划explain详解 2015-08-10 13:56:27 分类: MySQL explain命令是查看查询优化器如何决定执行查询的主要方法.这个功能有局限性,并不总会说出真相,但 ...
- MySQL执行计划 EXPLAIN参数
MySQL执行计划参数详解 转http://www.jianshu.com/p/7134286b3a09 MySQL数据库中,在SELECT查询语句前边加上“EXPLAIN”或者“DESC”关键字,即 ...
- MySQL执行计划explain的key_len解析
前言:当用Explain查看SQL的执行计划时,里面有列显示了 key_len 的值,根据这个值可以判断索引的长度,在组合索引里面可以更清楚的了解到了哪部分字段使用到了索引.下面演示中,表结构的合理性 ...
- 如何看MySql执行计划explain(或desc)
简介 MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化.EXPLAIN 命令用法十分简单, 在 S ...
- MySQL执行计划explain
一.简介 分析查询慢的原因,在查询语句前加explain即可.如: 二.输出格式 2.0 测试数据 # 表user_info CREATE TABLE `user_info` ( `id` bigin ...
- mysql执行计划
烂sql不仅直接影响sql的响应时间,更影响db的性能,导致其它正常的sql响应时间变长.如何写好sql,学会看执行计划至关重要.下面我简单讲讲mysql的执行计划,只列出了一些常见的情况, ...
- mysql执行计划介绍
简单讲讲mysql的执行计划,只列出了一些常见的情况,希望对大家有所帮助 烂sql不仅直接影响sql的响应时间,更影响db的性能,导致其它正常的sql响应时间变长.如何写好sql,学会看执行计划至 ...
- MySQL执行计划解读
Explain语法 EXPLAIN SELECT …… 变体: 1. EXPLAIN EXTENDED SELECT …… 将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可得 ...
- 如何查看MySQL执行计划
在介绍怎么查看MySQL执行计划前,我们先来看个后面会提到的名词解释: 覆盖索引: MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件 包含所有满足查询需要的数据的索引 ...
- mysql 执行计划的理解
1.执行计划就是在sql语句之前加上explain,使用desc 也可以.2.desc有两个选项extended和partitions,desc extended 将原sql语句进行优化,通过show ...
随机推荐
- 《javascript设计模式与开发实践》阅读笔记(10)—— 组合模式
组合模式:一些子对象组成一个父对象,子对象本身也可能是由一些孙对象组成. 有点类似树形结构的意思,这里举一个包含命令模式的例子 var list=function(){ //创建接口对象的函数 ret ...
- href的理解
您搜索的项目暂未上线,可直接<a style="color: #ff0000;" onclick="onlineTalk();" href="j ...
- C# 使用 ffmpeg 进行音频转码
先放一下 ffmpeg 的官方文档以及下载地址: 官方文档:http://ffmpeg.org/ffmpeg.html 下载地址:http://ffmpeg.org/download.html 用 f ...
- jQuery serialize()方法获取不到数据,alert结果为空
网上查找,问题可能是 id有重复 经排查,没有发现重复id 解决方案 form表单中每个input框都没有name属性,添加name属性即可 若name属性与jQuery的关键字有冲突,也可导致该问题 ...
- 谈谈自己的理解:python中闭包,闭包的实质
闭包这个概念好难理解,身边朋友们好多都稀里糊涂的,稀里糊涂的林老冷希望写下这篇文章能够对稀里糊涂的伙伴们有一些帮助~ 请大家跟我理解一下,如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内 ...
- Linux磁盘分区-rpm-yum
一.磁盘分区 1.开启Linux系统前添加一块大小为15G的SCSI硬盘 2.开启系统,右击桌面,打开终端 3.为新加的硬盘分区,一个主分区大小为5G,剩余空间给扩展分区,在扩展分区上划分1个逻辑分区 ...
- Nginx配置特定二级域名
首先把先在域名设置页面把二级域名解析到服务器的公网IP上,这里假设是 bbs.domainname.com 然后编辑 /etc/nginx/sites-available/domain.com.con ...
- 智能提示含查询多列(html+JS+handler+ HttpRemoting)一、html示列 加 JS加 请求 Handler
<html> <head> </head> <body> <form id="recordform" name="r ...
- CSS揭秘(四)视觉效果
Chapter 4 1. 单侧投影 为元素设置投影可以使用 box-shadow 属性,指定三个长度值(X轴偏移量.Y轴偏移.模糊半径)与一个颜色值 要想只在底部设置投影,需要用到第四个参数:投影的扩 ...
- Docker配置加速器
我们国内使用官方Docker Hub仓库实在是太慢了,很影响效率 使用命令编辑文件: vim /etc/docker/daemon.json 加入下面的数据: docker-cn镜像: { " ...