kafka快速入门
一、kafka简介
kafka,ActiveMQ,RabbitMQ是当今最流行的分布式消息中间件,其中kafka在性能及吞吐量方面是三者中的佼佼者,不过最近查阅官网时,官方与它的定义为一个分布式流媒体平台。kafka最主要有以下几个方面作用:
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错持久的方式存储记录流。
- 处理记录发生的流
kafka有四个比较核心的API 分别为:
producer:允许应用程序发布一个消息至一个或多个kafka的topic中
consumer:允许应用程序订阅一个或多个主题,并处理所产生的对他们记录的数据流
stream-api: 允许应用程序从一个或多个主题上消费数据然后将消费的数据输出到一个或多个其他的主题当中,有效地变换所述输入流,以输出流。类似于数据中转站的作用
connector-api:允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。官网给我们的示意图:
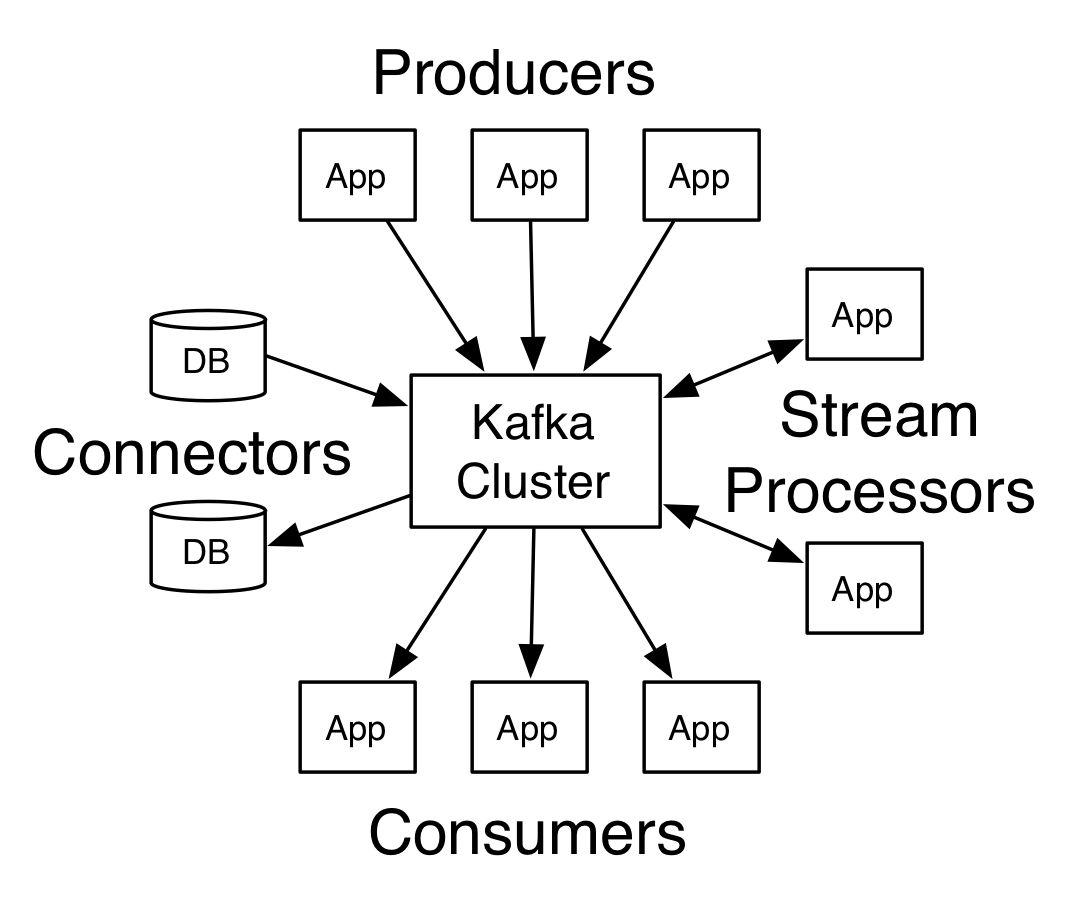
kafka关键名词解释:
- producer:生产者。
- consumer:消费者。
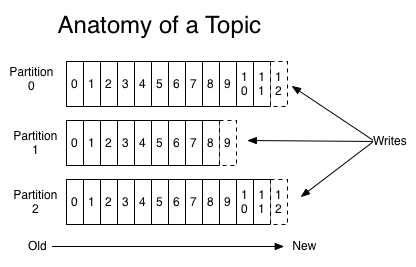
- topic: 消息以topic为类别记录,每一类的消息称之为一个主题(Topic)。为了提高吞吐量,每个消息主题又会有多个分区
- broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
主题与日志:
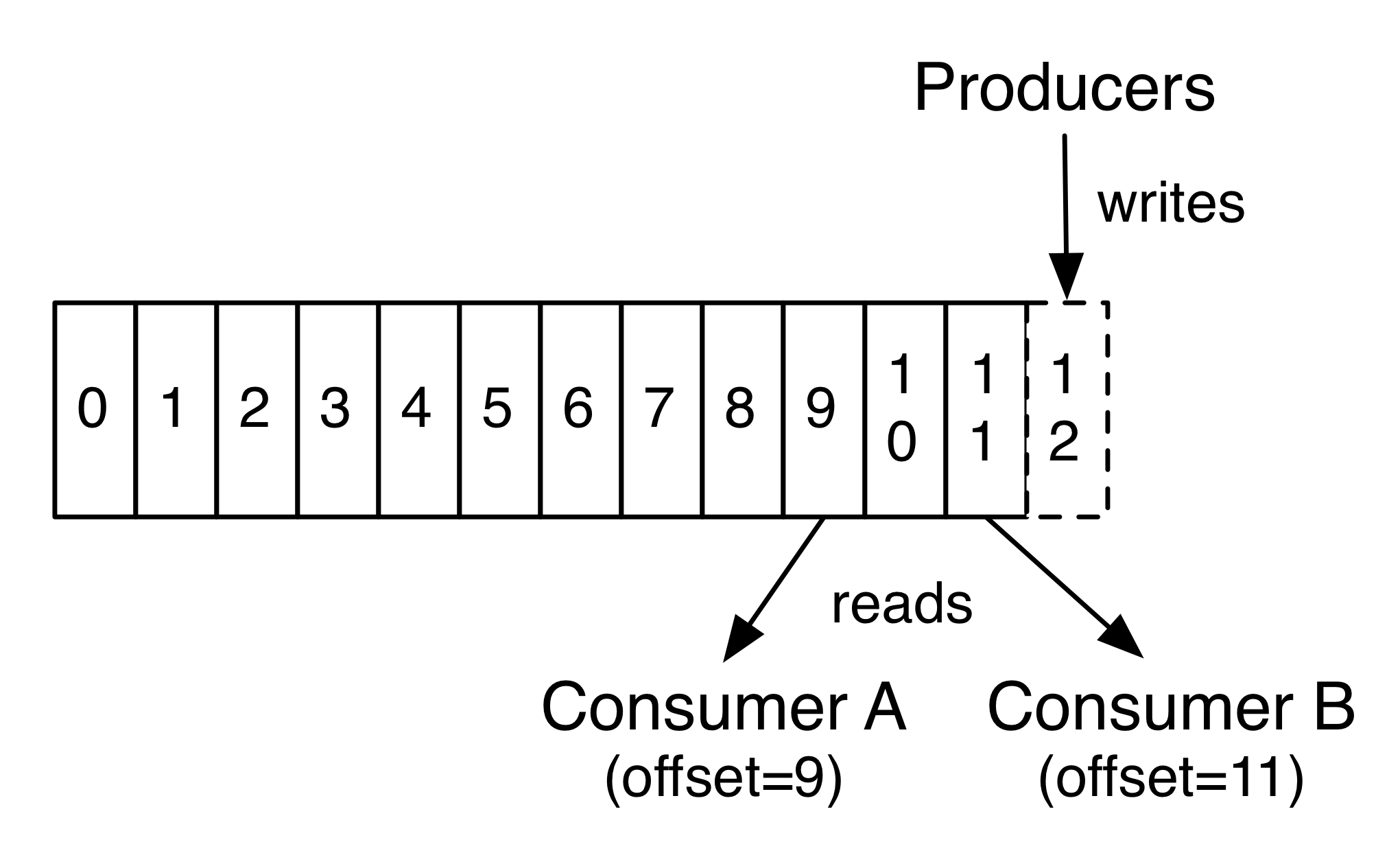
每一个分区(partition)都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。
二、kafka速成
1、下载kafka并解压
kafka下载地址,注意kafka需要zookeeper的服务,因此请确保kafka服务启动之前先运行zookeeper,请参考这篇文章。在kafka的bin目录下有 windows的文件夹 用于在windows环境下启动kafka
2、启动kafka服务
> bin/kafka-server-start.sh config/server.properties
[-- ::,] INFO Verifying properties (kafka.utils.VerifiableProperties)
[-- ::,] INFO Property socket.send.buffer.bytes is overridden to (kafka.utils.VerifiableProperties)
...
3、创建一个主题
我们用一个分区和一个副本创建一个名为“test”的主题:
> bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test
然后我们可以运行如下命令查看是否已经创建成功:
> bin/kafka-topics.sh --list --zookeeper localhost:
test
当发送的主题不存在且想自动创建主题时,我们可以编辑config/server.properties
auto.create.topics.enable=true
default.replication.factor=
4、发送消息
Kafka附带一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每行将作为单独的消息发送。
> bin/kafka-console-producer.sh --broker-list localhost: --topic test
This is a message
This is another message
5、消费消息
> bin/kafka-console-consumer.sh --bootstrap-server localhost: --topic test --from-beginning
This is a message
This is another message
6、集群搭建
首先我们为每个代理创建一个配置文件(在Windows上使用该copy命令):
> cp config/server.properties config/server-.properties
> cp config/server.properties config/server-.properties
分别编辑上述文件:
config/server-.properties:
broker.id=
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs- config/server-.properties:
broker.id=
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-
分别启动:
> bin/kafka-server-start.sh config/server-.properties &
...
> bin/kafka-server-start.sh config/server-.properties &
...
现在创建一个复制因子为三的新主题:
> bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic my-replicated-topic
我们可以通过以下命令查看状态:
> bin/kafka-topics.sh --describe --zookeeper localhost: --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount: ReplicationFactor: Configs:
Topic: my-replicated-topic Partition: Leader: Replicas: ,, Isr: ,,
7、外网配置kafka注意事项
请编辑server.properties添加如下配置:
broker.id主要做集群时区别的编号
port 默认kafka端口号
host.name 设置为云内网地址
advertised.host.name 设置为云外网映射地址
三、spring中使用kafka
1、编辑gradle配置文件:
dependencies {
// https://mvnrepository.com/artifact/org.springframework/spring-context
compile group: 'org.springframework', name: 'spring-context', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-web
compile group: 'org.springframework', name: 'spring-web', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-context-support
compile group: 'org.springframework', name: 'spring-context-support', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-webmvc
compile group: 'org.springframework', name: 'spring-webmvc', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka
compile group: 'org.springframework.kafka', name: 'spring-kafka', version: '2.1.4.RELEASE'
// https://mvnrepository.com/artifact/org.slf4j/slf4j-api
compile group: 'org.slf4j', name: 'slf4j-api', version: '1.7.25'
// https://mvnrepository.com/artifact/ch.qos.logback/logback-core
compile group: 'ch.qos.logback', name: 'logback-core', version: '1.2.3'
// https://mvnrepository.com/artifact/ch.qos.logback/logback-classic
testCompile group: 'ch.qos.logback', name: 'logback-classic', version: '1.2.3'
testCompile group: 'junit', name: 'junit', version: '4.12'
}
2、编写AppConfig配置文件类:
package com.hzgj.lyrk.spring.study.config; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.*;
import org.springframework.stereotype.Component; import java.util.HashMap;
import java.util.Map; @Configuration
@EnableKafka
@ComponentScan
public class AppConfig { @Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> props = new HashMap<>(8);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
} @Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory(), true);
} @Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>(8);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props); } @Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConcurrency(3);
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(3000);
return factory;
} @Component
static class Listener { @KafkaListener(id="client_one",topics = "test")
public void receive(String message) {
System.out.println("收到的消息为:" + message);
}
@KafkaListener(id="client_two",topics = "test1")
public void receive(Integer message) {
System.out.println("收到的的Integer消息为:" + message);
} }
}
3. 编写Main方法
package com.hzgj.lyrk.spring.study; import com.hzgj.lyrk.spring.study.config.AppConfig;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFutureCallback; public class Main { public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
KafkaTemplate<String, String> kafkaTemplate = applicationContext.getBean(KafkaTemplate.class);
kafkaTemplate.send("test", 0,"msg","{\"id\":2}").addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable ex) {
ex.printStackTrace();
} @Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("发送消息成功....");
}
});
}
}
执行成功后得到如下结果:
kafka快速入门的更多相关文章
- docker安装kafka快速入门
docker安装kafka快速入门 1.安装zookeeper docker search zookeeperdocker pull zookeeperdocker run -d -v /home/s ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- kafka快速入门到精通
目录 1. 消息队列两种模式 1.1 消息队列作用 1.2 点对点模式(一对一,消费者主动拉取数据,消息收到后消息删除) 1.3 发布/订阅模式(一对多,消费数据之后不会删除消息) 1.4 kafka ...
- Apache Kafka 快速入门
概述 Apache Kafka是一个分布式发布-订阅消息系统和强大的队列,可以处理大量的数据,将消息从一个端点传递到另一个端点.Kafka适合离线和在线消息消费,Kafka消息保存在磁盘上,并在集群内 ...
- Kafka 快速入门
Kafka Kafka 核心概念 什么是 Kafka Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.该项目的目标是为处理实时数据提供一个统一.高吞吐.低延迟 ...
- Kafka快速上手(2017.9官方翻译)
为了帮助国人更好了解.上手kafka,特意翻译.修改了个文档.官方Wiki : http://kafka.apache.org/quickstart 快速开始 本教程假定您正在开始新鲜,并且没有现有的 ...
- RocketMQ快速入门
前面几篇文章介绍了为什么选择RocketMQ,以及与kafka的一些对比: 阿里 RocketMQ 优势对比,方便大家对于RocketMQ有一个简单的整体了解,之后介绍了:MQ 应用场景,让我们知道M ...
- logstash快速入门实战指南-Logstash简介
作者其他ELK快速入门系列文章 Elasticsearch从入门到精通 Kibana从入门到精通 Logstash是一个具有实时流水线功能的开源数据收集引擎.Logstash可以动态统一来自不同来源的 ...
- Scala快速入门 - 基础语法篇
本篇文章首发于头条号Scala快速入门 - 基础语法篇,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干货,也欢迎关注我的 ...
随机推荐
- 技术文档分享_linux中生成考核用的GPT分区表结构修复
注:历史版本,后期改用python实现了 实验一: 目的:用于生成大量模拟破坏GPT分区结构案例,并生成唯一方式修复后的评判方法.故障:在一个完整的GPT分区磁盘上,丢失了GPT主分区表,或备份分区表 ...
- REST or RPC?
1 概念 1.1 RPC RPC(Remote Procedure Call)-远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议的存 ...
- UTF-8 UTF-16 UTF-32 最根本的区别?
昨天看书的时候突然发现UTF-16 我好像还没见过这个东西 也可能忘记了 反正现在对自己科普一下吧 最根本的区别 UTF-32 把所有的字符都用32bit -- 4个字节 来表示 UTF-16 和 ...
- LeetCode & Q169-Majority Element-Easy
Array Divide and Conquer Bit Manipulation Description: Given an array of size n, find the majority e ...
- (转载) Mysql 时间操作(当天,昨天,7天,30天,半年,全年,季度)
1 . 查看当天日期 select current_date(); 2. 查看当天时间 select current_time(); 3.查看当天时间日期 select current_timesta ...
- Jenkins+maven+git配置
1) 安装maven 如下图我已装好maven(这是我很早以前装的,安装教程大家可以百度一下,很容易安装的) 2) 安装git客户端 如下图所示,我也安装好了git客户 ...
- Angular组件——组件生命周期(二)
一.view钩子 view钩子有2个,ngAfterViewInit和ngAfterViewChecked钩子. 1.实现ngAfterViewInit和ngAfterViewChecked钩子时注意 ...
- Docker学习笔记 - Docker的简介
传统硬件虚拟化:虚拟硬件,事先分配资源,在虚拟的硬件上安装操作系统,虚拟机启动起来以后资源就会被完全占用. 操作系统虚拟化:docker是操作系统虚拟化,借助操作系统内核特性(命名空间.cgroups ...
- gradle入门(1-2)gradle的依赖管理
Gradle支持以下仓库格式: Ivy仓库 Maven仓库 Flat directory仓库 一.添加仓库 1.添加Ivy仓库 1.1.通过URL地址添加一个Ivy仓库 我们可以将以下代码片段加入到b ...
- codeforces round 425 div2
A. Sasha and Sticks 水题,判断一下次数的奇和偶就可以的. B. Petya and Exam 赛上的时候没有写出来,orz,记录一下吧. 题意:给出一个模式串,可能会有?和*两种符 ...