qwe框架- CNN 实现
CNN实现
概述
我在qwe中有两种,第一种是按照Ng课程中的写法,多层循环嵌套得到每次的“小方格”,然后WX+b,这样的做法是最简单,直观。但是效率极其慢。基本跑个10张以内图片都会卡的要死。
第二种方法是使用img2col,将其转换为对应的矩阵,然后直接做一次矩阵乘法运算。
先看第一种
def forward(self, X):
m, n_H_prev, n_W_prev, n_C_prev = X.shape
(f, f, n_C_prev, n_C) = self.W.shape
n_H = int((n_H_prev - f + 2 * self.pad) / self.stride) + 1
n_W = int((n_W_prev - f + 2 * self.pad) / self.stride) + 1
n_H, n_W, n_C = self.output_size
Z = np.zeros((m, n_H, n_W, n_C))
X_pad = zero_pad(X, self.pad)
for i in range(m):
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start = h * self.stride
vert_end = vert_start + f
horiz_start = w * self.stride
horiz_end = horiz_start + f
A_slice_prev =X_pad[i,vert_start:vert_end, horiz_start:horiz_end, :]
Z[i,h,w,c] = conv_single_step(A_slice_prev, self.W[...,c], self.b[...,c])
def conv_single_step(X, W, b):
# 对一个裁剪图像进行卷积
# X.shape = f, f, prev_channel_size
return np.sum(np.multiply(X, W) + b)
对于m,n_H,n_W,n_C循环就是取得裁剪小方块,可以看到这里的计算复杂度m * n_H * n_W * n_C * (f*f的矩阵计算)
第二种方法,先转换成大矩阵,再进行一次矩阵运算,相当于节省了多次小矩阵运算时间,这还是很可观的,能查个几十倍的速度。
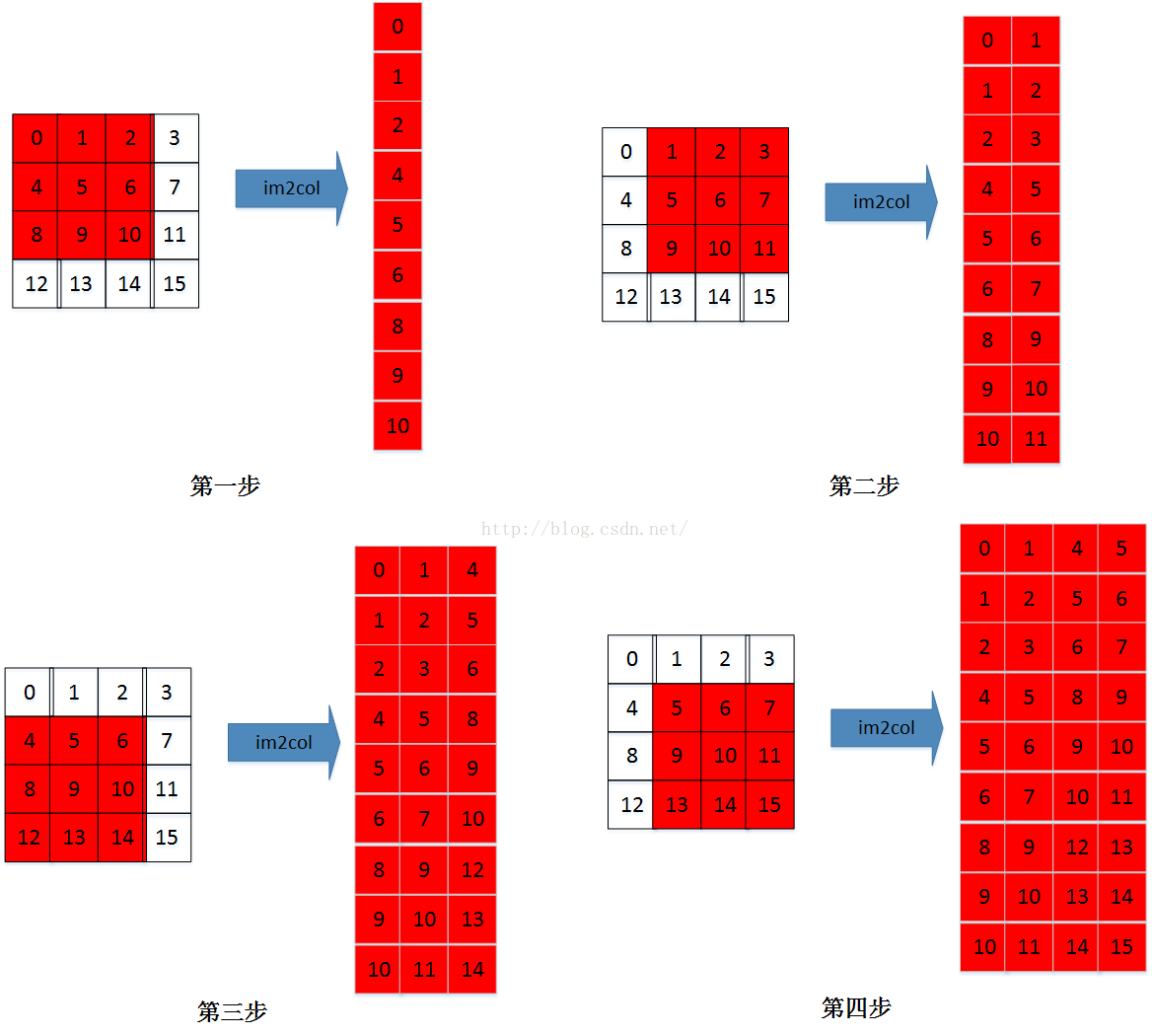
img2col原理很简单,详情可参考caffe im2col
就是循环将每一部分都拉长成一维矩阵拼凑起来。
对于CNN来说,H就是要计算方块的个数即m(样本数) n_H(最终生成图像行数)n_W(最终生成图像列数),W就是f(核kernel长)f(核宽)*(输入样本通道输)
然后还要把参数矩阵W也拉成这个样子,H就是f(核长)f(核宽)(输入样本通道输),W列数就是核数kernel_size
如下图

def img2col(X, pad, stride, f):
pass
ff = f * f
m, n_H_prev, n_W_prev, n_C_prev= X.shape
n_H = int((n_H_prev - f + 2 * pad) / stride) + 1
n_W = int((n_W_prev - f + 2 * pad) / stride) + 1
Z = np.zeros((m * n_H * n_W, f * f * n_C_prev))
X_pad = np.pad(X, ((0, 0), (pad, pad), (pad, pad), (0, 0)), 'constant', constant_values=0)
row = -1
for i in range(m):
for h in range(n_H):
for w in range(n_W):
row += 1
vert_start = h * stride
horiz_start = w * stride
for col in range(f * f * n_C_prev):
t = col // n_C_prev
hh = t // f
ww = t % f
cc = col % n_C_prev
Z[row, col] = X_pad[i, vert_start + hh, horiz_start + ww, cc]
def speed_forward(model, X):
W = model.W
b = model.b
stride = model.stride
pad = model.pad
(n_C_prev, f, f, n_C) = W.shape
m, n_H_prev, n_W_prev, n_C_prev = X.shape
n_H = int((n_H_prev - f + 2 * pad) / stride) + 1
n_W = int((n_W_prev - f + 2 * pad) / stride) + 1
# WW = W.swapaxes(2,1)
# WW = WW.swapaxes(1,0)
XX = img2col(X, pad, stride, f)
# WW = WW.reshape(f*f*n_C_prev, n_C)
WW = W.reshape(f*f*n_C_prev, n_C)
model.XX = XX
model.WW = WW
Z = np.dot(XX, WW) + b
return Z.reshape(m, n_H, n_W, n_C)
这种耗时操作,最好使用Cython扩展来写,不然速度还是不够理想。Cython扩展代码code
反向传播同理,具体代码参考
github
qwe框架- CNN 实现的更多相关文章
- 深度学习原理与框架-CNN在文本分类的应用 1.tf.nn.embedding_lookup(根据索引数据从数据中取出数据) 2.saver.restore(加载sess参数)
1. tf.nn.embedding_lookup(W, X) W的维度为[len(vocabulary_list), 128], X的维度为[?, 8],组合后的维度为[?, 8, 128] 代码说 ...
- 深蓝色 --ppt
Deep Learning of Binary Hash Codes for Fast Image Retrieval [Paper] [Code-Caffe] 1. 摘要 针对图像检索问题,提出简单 ...
- [基础]Deep Learning的基础概念
目录 DNN CNN DNN VS CNN Example 卷积的好处why convolution? DCNN 卷积核移动的步长 stride 激活函数 active function 通道 cha ...
- qwe 简易深度框架
qwe github地址 简介 简单的深度框架,参考Ng的深度学习课程作业,使用了keras的API设计. 方便了解网络具体实现,避免深陷于成熟框架的细节和一些晦涩的优化代码. 网络层实现了Dense ...
- 【深度学习系列3】 Mariana CNN并行框架与图像识别
[深度学习系列3] Mariana CNN并行框架与图像识别 本文是腾讯深度学习系列文章的第三篇,聚焦于腾讯深度学习平台Mariana中深度卷积神经网络Deep CNNs的多GPU模型并行和数据并行框 ...
- 卷积神经网络CNN与深度学习常用框架的介绍与使用
一.神经网络为什么比传统的分类器好 1.传统的分类器有 LR(逻辑斯特回归) 或者 linear SVM ,多用来做线性分割,假如所有的样本可以看做一个个点,如下图,有蓝色的点和绿色的点,传统的分类器 ...
- 我所写的CNN框架 VS caffe
我所写的CNN框架 VS caffe 一个月前.自己模仿caffe实现了一个卷积神经网络的框架. 同样点 1无缝支持CPU和GPU模式,GPU模式使用cuda实现. 不同点 1我的CNN不依赖与不论什 ...
- ubuntu之路——day19.2 开源框架与迁移、CNN中的数据扩充
开源框架与迁移 上面介绍了一些已经取得很好成绩的CNN框架,我们可以直接从GitHub上下载这些神经网络的结构和已经在ImageNet等数据集上训练好的权重超参数. 在应用于我们自己的数据时. 1.如 ...
- CNN基础框架简介
卷积神经网络简介 卷积神经网络是多层感知机的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来.视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,我们称之为感受野 ...
随机推荐
- ABP官方文档翻译 3.4 领域服务
领域服务 介绍 IDomainService接口和DomainService类 示例 创建接口 服务实现 使用应用服务 一些探讨 为什么只有应用服务? 如何强制使用领域服务? 介绍 领域服务(或者在D ...
- UOJ Round #15 [构造 | 计数 | 异或哈希 kmp]
UOJ Round #15 大部分题目没有AC,我只是水一下部分分的题解... 225[UR #15]奥林匹克五子棋 题意:在n*m的棋盘上构造k子棋的平局 题解: 玩一下发现k=1, k=2无解,然 ...
- BZOJ 4195: [Noi2015]程序自动分析 [并查集 离散化 | 种类并查集WA]
题意: 给出若干相等和不等关系,判断是否可行 woc NOI考这么傻逼的题飞快打了一个种类并查集交上了然后爆零... 发现相等和不等看错了异或一下再叫woc90分 然后发现md$a \neq b, a ...
- POJ1509 Glass Beads [后缀自动机]
题意: 给一个字符串S,每次可以将它的第一个字符移到最后面,求这样能得到的字典序最小的字符串.输出开始下标 练习SAM第一题! SS构造SAM,然后从开始尽量走最小走n步就可以啦 什么?开始位置?!R ...
- C 洛谷 P3599 Koishi Loves Construction [构造 打表观察]
题目描述 Koishi决定走出幻想乡成为数学大师! Flandre听说她数学学的很好,就给Koishi出了这样一道构造题: Task1:试判断能否构造并构造一个长度为的的排列,满足其个前缀和在模的意义 ...
- php环境搭建和第一个php程序
一.开发环境搭建 因为是初学,使用的还是非常经典的组合appserv+dreamweaver cs6; 1.1 appserv安装 appserv的安装还是非常简单的,直接双击可执行程序appse ...
- sass 变量
1.使用变量 $符号标识变量 变量名中 中划线和下划线互通(不包括sass中纯 css 部分) 变量值 css 属性标准值 包括以空格 和 逗号 , 分开的多个属性值 变量可以定义在规则块之外
- TripleDES加密解密
参考:http://www.cnblogs.com/chnking/archive/2007/08/14/855600.html 参考:http://blog.csdn.net/change_from ...
- vim操作备忘录
vim操作备忘录 vim 备忘录 vim的书籍虽然看不不少,可是老是容易忘记,主要是自己操作总结过少,这个博客就主要用来记录一些比较常见的术语和操作,以防止自己再次忘记. <leader> ...
- CentOS 6安装Oracle报错解决方案
1. Preparing to launch Oracle Universal Installer from /tmp/OraInstall2017-05-23_04-18-48AM. Please ...