k邻近算法(KNN)实例
一 k近邻算法原理
k近邻算法是一种基本分类和回归方法.
原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的
多数属于某个类,就把该输入实例分类到这个类中。
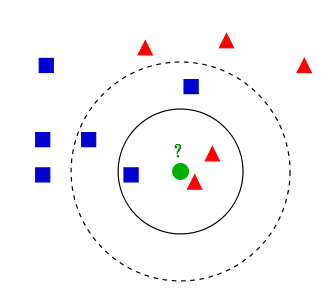
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。
- 如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
参考一文搞懂k近邻(k-NN)算法(一) https://zhuanlan.zhihu.com/p/25994179
二 特点
优点:精度高(计算距离)、对异常值不敏感(单纯根据距离进行分类,会忽略特殊情况)、无数据输入假定
(不会对数据预先进行判定)。
缺点:时间复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
三 欧氏距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
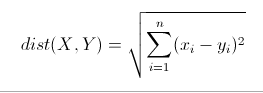
四 sklearn库中使用k邻近算法
- 分类问题:from sklearn.neighbors import KNeighborsClassifier
- 回归问题:from sklearn.neighbors import KNeighborsRegressor
五 使用sklearn的K邻近简单实例
1 数据蓝蝴蝶
#导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
from sklearn.neighbors import KNeighborsClassifier #k邻近算法模型 #使用datasets创建数据
import sklearn.datasets as datasets
iris = datasets.load_iris() feature = iris['data']
target = iris['target'] #将样本打乱,符合真实情况 np.random.seed(1)
np.random.shuffle(feature)
np.random.seed(1)
np.random.shuffle(target) #训练数据
x_train = feature[:140]
y_train = target[:140]
#测试数据
x_test = feature[-10:]
y_test =target[-10:] #实例化模型对象&训练模型
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(x_train,y_train)
knn.score(x_train,y_train) print('预测分类:',knn.predict(x_test))
print('真实分类:',y_test)
2 根据身高、体重、鞋子尺码,预测性别
#导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series #手动创建训练数据集
feature = np.array([[170,65,41],[166,55,38],[177,80,39],[179,80,43],[170,60,40],[170,60,38]])
target = np.array(['男','女','女','男','女','女']) from sklearn.neighbors import KNeighborsClassifier #k邻近算法模型 #实例k邻近模型,指定k值=3
knn = KNeighborsClassifier(n_neighbors=3) #训练数据
knn.fit(feature,target) #模型评分
knn.score(feature,target) #预测
knn.predict(np.array([[176,71,38]]))
3 手写数字识别
- 导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier
- 查看单一图片特征
img=plt.imread('data/0/0_2.bmp')
plt.imshow(img)

- 提炼样本数据
feature=[]
target=[]
for i in range(10):
for j in range(500):
img_arr=plt.imread(f'data/{i}/{i}_{j+1}.bmp')
feature.append(img_arr)
target.append(i) #构建特征数据格式
feature=np.array(feature)
target=np.array(target) feature.shape #(5000, 28, 28) #输入数据必须是二维数组,必须对feature降维
#(1)降维方式一:mean() (2)降维方式二:reshape()
feature=feature.reshape(5000,28*28) #将样本打乱 (必须使用多个seed)
np.random.seed(5)
np.random.shuffle(feature)
np.random.seed(5)
np.random.shuffle(target) #数据分割为训练数据和测试数据
x_train=feature[:4950]
y_train=target[:4950]
x_test=feature[-50:]
y_test=target[-50:]
- KNN模型建立和评分
#训练模型
knn.fit(x_train,y_train) #评分
knn.score(x_train,y_train) #预测
# knn.predict(x_test)
- 真实预测手写数字图片的一般流程
# 读取图片数据
num_img_arr=plt.imread('../../数字.jpg')
plt.imshow(num_img_arr)
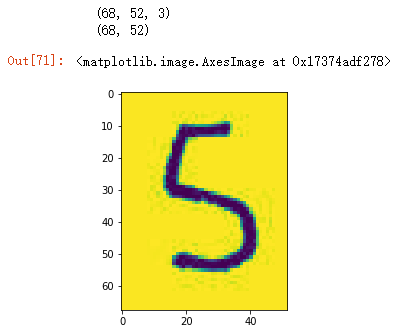
#图片截取数字5
five_arr=num_img_arr[90:158,80:132]
plt.imshow(five_arr)

#降维操作(five数组是三维的,需要进行降维,舍弃第三个表示颜色的维度)
print(five_arr.shape) #(65, 56, 3)
five=five_arr.mean(axis=2)
print(five.shape) #(65, 56)
plt.imshow(five)
# 图片压缩为像素28*28
import scipy.ndimage as ndimage
five = ndimage.zoom(five,zoom = (28/68,28/52))
five.shape #(28, 28) # 压缩后的5的显示
plt.imshow(five)
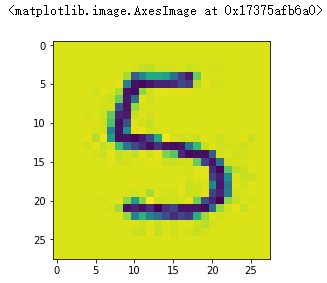
# 把数据降维为feature 数据格式
five.reshape(1,28*28)
#预测
knn.predict(five.reshape(1,28*28))

下载源数据和代码:https://github.com/angleboygo/data_ansys
k邻近算法(KNN)实例的更多相关文章
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
- 机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法 1.K邻近算法 将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近 ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一.前言 kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别.mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
随机推荐
- Sql语言简介——检索数据
检索数据可以通过SELECT语句来实现. select子句:用于选择数据表.视图中的列. into子句:用于将原表中的结构和数据插入新表中. from子句:用于指定数据来源,包括表.视图和其他sele ...
- iOS 8 中如何集成 Touch ID 功能
2013年9月,苹果为当时发布的最新iPhone产品配备了一系列硬件升级方案.在iPhone 5s当中,最具创新特性的机制无疑要数围绕Home按钮设计的超薄金属圈,也就是被称为Touch ID的指纹传 ...
- DB2数据库操作XMl字段
1.xml查询语句 ① 查询xml中的单个节点内容 select TM_PRM_OBJECT.ORG , TM_PRM_OBJECT.PARAM_CLASS , TM_PRM_OBJECT.PARAM ...
- Docker 镜像之进阶篇
笔者在<Docker 基础 : 镜像>一文中介绍了 docker 镜像的基本用法,本文我们来介绍 docker 镜像背后的技术原理. 什么是 docker 镜像 docker 镜像是一个只 ...
- vue中引入babel步骤
vue中引入babel步骤 vue项目中普遍使用es6语法,但有时我们的项目需要兼容低版本浏览器,这时就需要引入babel插件,将es6转成es5. 1.安装babel-polyfill插件 npm ...
- 用Python学分析 - 正态分布
正态分布(Normal Distribution) 1.正态分布是一种连续分布,其函数可以在实线上的任何地方取值. 2.正态分布由两个参数描述:分布的平均值μ和方差σ2 . 3.正态分布的取值可以从负 ...
- 一线互联网企业常见的14个Java面试题,Java面试题集大全等你拿,颤抖吧程序员!
本文由尚学堂学员们根据自己参加过的面试回忆.总结而成,一线互联网企业常见的14个Java面试题,包括各大互联网企业.创业小公司,互联网企业.传统软件公司.对于刚毕业和想要跳槽的宝宝们,再适用不过啦,赶 ...
- 『线段树 Segment Tree』
更新了基础部分 更新了\(lazytag\)标记的讲解 线段树 Segment Tree 今天来讲一下经典的线段树. 线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间 ...
- JavaWeb 乱码问题终极解决方案!
经常有读者在公众号上问 JavaWeb 乱码的问题,昨天又有一个小伙伴问及此事,其实这个问题很简单,但是想要说清楚却并不容易,因为每个人乱码的原因都不一样,给每位小伙伴都把乱码的原因讲一遍也挺费时间的 ...
- java游戏开发杂谈 - 实现游戏主菜单
经常玩游戏的同学,大家都知道,游戏都会有个主菜单,里面有多个菜单选项:开始游戏.游戏设置.关于游戏.退出游戏等等,这个菜单是怎么实现的呢. 有一定桌面软件开发基础的同学可能会想到,用JButton组件 ...