pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处。联系方式:460356155@qq.com
在前一篇中的ResNet-34残差网络,经过训练准确率只达到80%。
这里对网络做点小修改,在最开始的卷积层中用更小(3*3)的卷积核,并且不缩小图片尺寸,相应的最后的平均池化的核改为4*4。
具体修改如下:
class ResNet34(nn.Module):
def __init__(self, block):
super(ResNet34, self).__init__() # 初始卷积层核池化层
self.first = nn.Sequential(
# 卷基层1:3*3kernel,1stride,1padding,outmap:32-3+1*2 / 1 + 1,32*32
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True), # 最大池化,3*3kernel,1stride(保持尺寸),1padding,
# outmap:32-3+2*1 / 1 + 1,32*32
nn.MaxPool2d(3, 1, 1)
) # 第一层,通道数不变
self.layer1 = self.make_layer(block, 64, 64, 3, 1) # 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, 128, 4, 2) # 输出16*16
self.layer3 = self.make_layer(block, 128, 256, 6, 2) # 输出8*8
self.layer4 = self.make_layer(block, 256, 512, 3, 2) # 输出4*4 self.avg_pool = nn.AvgPool2d(4) # 输出512*1
self.fc = nn.Linear(512, 10)
运行结果:
Files already downloaded and verified
ResNet34(
(first): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(layer1): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
one epoch spend: 0:00:55.832303
EPOCH:1, ACC:53.05
one epoch spend: 0:00:54.158082
EPOCH:2, ACC:61.94
......
one epoch spend: 0:00:54.178677
EPOCH:199, ACC:85.37
one epoch spend: 0:00:53.657917
EPOCH:200, ACC:85.25
CIFAR10 pytorch ResNet34 Train: EPOCH:200, BATCH_SZ:128, LR:0.1, ACC:85.38
train spend time: 3:11:21.618257
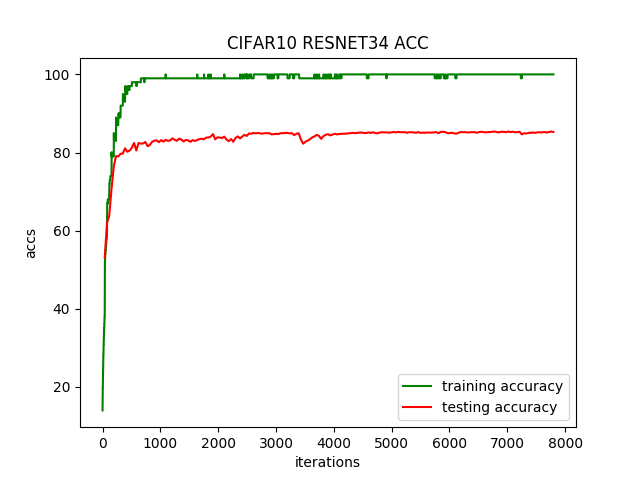
运行200个迭代,每个迭代耗时54秒,准确率提升了5%,达到85%。准确率变化曲线如下:
pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)的更多相关文章
- pytorch识别CIFAR10:训练ResNet-34(数据增强,准确率提升到92.6%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过减小卷积核训练准确率提升到85%. 这里对训练数据集做数据 ...
- pytorch识别CIFAR10:训练ResNet-34(准确率80%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com CNN的层数越多,能够提取到的特征越丰富,但是简单地增加卷积层数,训练时会导致梯度弥散或梯度爆炸. 何 ...
- pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 前面通过数据增强,ResNet-34残差网络识别CIFAR10,准确率达到了92.6. 这里对训练过程 ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(二)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com AlexNet在2012年ImageNet图像分类任务竞赛中获得冠军.网络结构如下图所示: 对CIFA ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com VGGNet在2014年ImageNet图像分类任务竞赛中有出色的表现.网络结构如下图所示: 同样的, ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- Caffe fine-tuning 微调网络
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ 目前呢,caffe,theano,torch是当下比较流行的De ...
- 用pytorch进行CIFAR-10数据集分类
CIFAR-10.(Canadian Institute for Advanced Research)是由 Alex Krizhevsky.Vinod Nair 与 Geoffrey Hinton 收 ...
- 【转】CNN+BLSTM+CTC的验证码识别从训练到部署
[转]CNN+BLSTM+CTC的验证码识别从训练到部署 转载地址:https://www.jianshu.com/p/80ef04b16efc 项目地址:https://github.com/ker ...
随机推荐
- 一个适合.NET Core的代码安全分析工具 - Security Code Scan
本文主要翻译自Security Code Scan的官方Github文档,结合自己的初步使用简单介绍一下这款工具,大家可以结合自己团队的情况参考使用.此外,对.NET Core开发团队来说,可以参考张 ...
- github仓库的使用
业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2103 远程仓库地址是:https://github.com/BinGuo66 ...
- Kafka、ActiveMQ、RabbitMQ、RocketMQ 区别以及高可用原理
为什么使用消息队列 其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么? 面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务 ...
- C++ 编译期封装-Pimpl技术
Pimpl技术——编译期封装 Pimpl 意思为“具体实现的指针”(Pointer to Implementation), 它通过一个私有的成员指针,将指针所指向的类的内部实现数据进行隐藏, 是隐藏实 ...
- 痞子衡嵌入式:第一本Git命令教程(0)- 索引
大家好,我是痞子衡,是正经搞技术的痞子.本系列痞子衡给大家讲的是Git命令汇编,共12篇文章,循序渐进地介绍Git操作的完整过程. 在开始Git课程之前,需要先跟大家普及2个重要概念(四度空间.四种状 ...
- Shell编程(week4_day4)--技术流ken
本节内容 1. shell函数 2. shell正则表达式 shell函数 shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数.给这段代码起个名字称为函数名,后续可以直 ...
- Flask的session使用
由于http是无状态保存的协议,session可以看作不同请求之间保存数据的一种机制.flask的session是基于cookie的会话保持. 流程 当客户端进行第一次请求的时候,客户端的HTTP r ...
- [MySQL] mysql的逻辑分层
mysql逻辑分层:1.client ==>连接层 ==>服务层==>引擎层==>存储层 server2.连接层: 提供与客户端连接的服务3.服务层: 1.提供各种用户使用的接 ...
- PHPCMS V9 添加二级导航
今天看了看phpcms 写到二级导航时发现点问题,查询导航栏的信息时返回的$r[arrchildid]与自己想象的不符,文档上说是返回子栏目id但是却有些不同. 开始的思路: <ul class ...
- 四、Snapman多人协作电子表格之——Exprtk脚本
Snapman多人协作电子表格是一个即时工作系统. Snapman中嵌入了Exprtk脚本进行公式数据运算.Exprtk是一种高性能的脚本,经测试它的数据运算性能只比C#和java底20%. 一.Ex ...