Python----支持向量机SVM
1.1. SVM介绍
SVM(Support Vector Machines)——支持向量机。其含义是通过支持向量运算的分类器。其中“机”的意思是机器,可以理解为分类器。
1.2. 工作原理
在最大化支持向量到超平面距离前,我们首先要定义我们的超平面f(x)(称为超平面的判别函数,也称给w和b的泛函间隔),其中w为权重向量,b为偏移向量:
核心思想:
- 首先通过两个分类的最近点,找到f(x)的约束条件。
- 有了约束条件,就可以通过拉格朗日乘子法和KKT条件来求解,这时,问题变成了求拉格朗日乘子αi和 b。
- 对于异常点的情况,加入松弛变量ξξ来处理。
- 使用SMO来求拉格朗日乘子αi和b。这时,我们会发现有些αi=0,这些点就可以不用在分类器中考虑了。
- 惊喜! 不用求w了,可以使用拉格朗日乘子αi和b作为分类器的参数。
- 非线性分类的问题:映射到高维度、使用核函数。
划分标准:最大间隔
找两个点p1,p2到直线最近的点,两点到直线距离的和叫,最小间隔。最小间隔距离值最大,及最小间隔最大化。
1.3. 实例
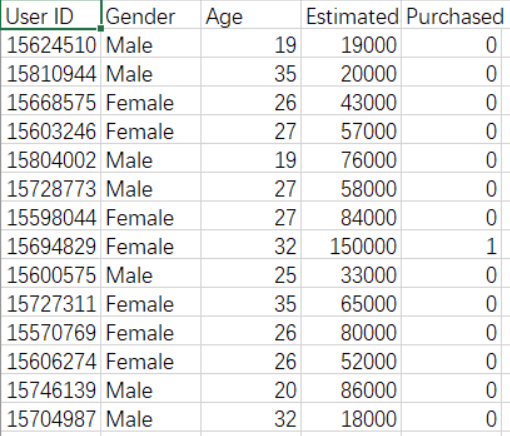
数据集:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2,3]].values
y = dataset.iloc[:, 4].values # Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test) # Fitting Logistic Regression to the Training set
#训练集拟合SVM的分类器
#从模型的标准库中导入SVM的类
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear', random_state = 0)
classifier.fit(X_train, y_train) # Predicting the Test set results
#运用拟合好的分类器预测测试集的结果情况
#创建变量(包含预测出的结果)
y_pred = classifier.predict(X_test) # Making the Confusion Matrix
#通过测试的结果评估分类器的性能
#用混淆矩阵,评估性能
#65,24对应着正确的预测个数;8,3对应错误预测个数;拟合好的分类器正确率:(65+24)/100
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred) # Visualising the Training set results
#在图像看分类结果
from matplotlib.colors import ListedColormap
#创建变量
X_set, y_set = X_train, y_train
#x1,x2对应图中的像素;最小值-1,最大值+1,-1和+1是为了让图的边缘留白,像素之间的距离0.01;第一行年龄,第二行年收入
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
#将不同像素点涂色,用拟合好的分类器预测每个点所属的分类并且根据分类值涂色
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
#标注最大值及最小值
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
#为了滑出实际观测的点(黄、蓝)
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('orange', 'blue'))(i), label = j)
plt.title('SVM (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
#显示不同的点对应的值
plt.legend()
#生成图像
plt.show() # Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('orange', 'blue'))(i), label = j)
plt.title('SVM (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
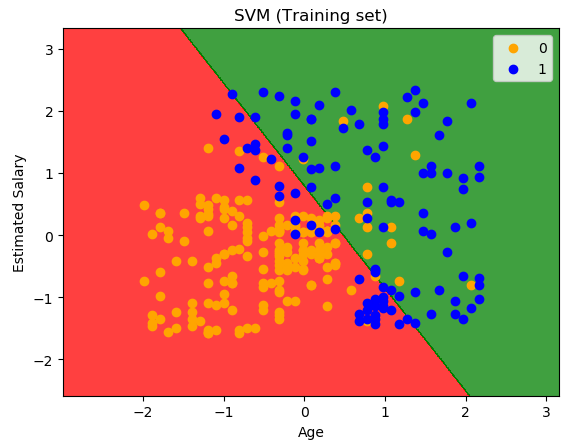
测试集图像显示结果
Python----支持向量机SVM的更多相关文章
- Python实现SVM(支持向量机)
Python实现SVM(支持向量机) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- python机器学习之支持向量机SVM
支持向量机SVM(Support Vector Machine) 关注公众号"轻松学编程"了解更多. [关键词]支持向量,最大几何间隔,拉格朗日乘子法 一.支持向量机的原理 Sup ...
- 支持向量机SVM
SVM(Support Vector Machine)有监督的机器学习方法,可以做分类也可以做回归.SVM把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类. 有好 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- 支持向量机SVM 参数选择
http://ju.outofmemory.cn/entry/119152 http://www.cnblogs.com/zhizhan/p/4412343.html 支持向量机SVM是从线性可分情况 ...
- 4、2支持向量机SVM算法实践
支持向量机SVM算法实践 利用Python构建一个完整的SVM分类器,包含SVM分类器的训练和利用SVM分类器对未知数据的分类, 一.训练SVM模型 首先构建SVM模型相关的类 class SVM: ...
- 机器学习第7周-炼数成金-支持向量机SVM
支持向量机SVM 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率源于Vapnik和Chervonenkis关于统计学习的早期工作(1971年),第一篇有关论文由Boser.Guyo ...
随机推荐
- Pycharm使用教程(四)-安装python依赖包(非常详细,非常实用)
简介 在做python开发时,需要很多依赖包,如果已经安装pip,安装依赖包,可以通过命令行:没有安装的,也可以通过PyCharm安装. 具体安装步骤 1.在File->Setting,如图: ...
- 微信小程序初体验,入门练手项目--通讯录,后台是阿里云服务器(一)
内容: 一.前言 二.相关概念 三.开始工作 四.启动项目起来 五.项目结构 六.设计理念 七.路由 八.部署线上后端服务 同步交流学习社区: https://www.mwcxs.top/page/4 ...
- Python:bs4的使用
概述 bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签. 一.初始化 from bs4 import BeautifulSoup soup ...
- c#如何声明数据结构类型为null?
可以通过如下两种方式声明可为空的类型:System.Nullable<T> variable;T?variable:eg:int值是-2,147,483,648 到 2,147,483,6 ...
- C#之使类型参数--泛型
1.泛型是什么 泛型的就是“通用类型”,它可以代替任何的数据类型,使类型参数化,从而达到只实现一个方法就可以操作多种数据类型的目的. 2.为什么使用泛型 举一个比较两个数大小的例子: 以上例子实现in ...
- 使用 DotNet CLI 创建自定义的 WPF 项目模板
描述 当我们安装完 DotNetCore 3.0 版本的 SDK 后,我们就可以创建基于 DotNetCore 的 WPF 项目模板,通过如下 CLI 可以方便快捷的创建并运行我们的项目: dotne ...
- 基于.net EF6 MVC5+WEB Api 的Web系统框架总结(1)-Web前端页面
本 Web 系统框架基于C# EF6+MVC+WebApi的快速应用开发平台.本节主要介绍Web前端页面设计与实现.Web前端页面主要分为普通列表页面.树状导航列表页面.普通编辑页面.数据导入页面.向 ...
- python turtle 书写新年快乐
文章链接:https://mp.weixin.qq.com/s/xYSKH_KLYfooIoelJH02Cg 农历2018年的最后一篇文章,踏上回家的征途前,推荐一个Python的三方库turtle, ...
- 碰到了通过Movie显示gif图片,有部分图片的duration为0导致gif只显示第一帧
解决办法,改为使用android-gif-drawable.jar来显示gif图片(需要配合com.android.support:support-v4:18.0.0使用) GifImageView ...
- MyDAL - .UpdateAsync() 之 .Set() 使用
索引: 目录索引 一.API 列表 1.Set<M, F>(Expression<Func<M, F>> propertyFunc, F newVal) 如: .S ...