中国农产品信息网站scrapy-redis分布式爬取数据
---恢复内容开始---
基于scrapy_redis和mongodb的分布式爬虫
项目需求:
1:自动抓取每一个农产品的详细数据
2:对抓取的数据进行存储
第一步:
创建scrapy项目


创建爬虫文件

在items.py里面定义我们要爬取的数据
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NongcpspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 供求关系
supply = scrapy.Field()
# 标题
title = scrapy.Field()
# 发布时间
create_time = scrapy.Field()
# 发布单位
unit = scrapy.Field()
# 联系人
contact = scrapy.Field()
# 手机号码
phone_number = scrapy.Field()
# 地址
address = scrapy.Field()
# 详细地址
detail_address = scrapy.Field()
# 上市时间
market_time = scrapy.Field()
# 价格
price = scrapy.Field()
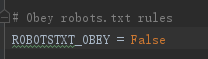
将settings.py改为false
写spider爬虫文件nongcp_spider.py,进行字段解析使用xpath,正则表达式
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import NongcpspiderItem
class NongcpSpiderSpider(scrapy.Spider):
name = 'nongcp_spider'
# allowed_domains = ['http://www.nongnet.com/']
start_urls = ['http://www.nongnet.com/']
def parse(self, response):
"""
解析详情页和下一页url
:param response:
:return:
"""
detail_urls = response.xpath('//li[@class="lileft"]/a/@href').extract()
for detail_url in detail_urls:
yield scrapy.Request(url=self.start_urls[0]+detail_url, callback=self.detail_parse)
next_url = response.xpath("//span[@id='ContentMain_lblPage']/a/@href").extract()
if next_url:
yield scrapy.Request(url=self.start_urls[0]+next_url[-2])
def detail_parse(self, response):
"""
解析具体的数据
:param response:
:return:
"""
items = NongcpspiderItem()
title_result = response.xpath('//h1[@class="h1class"]/text()').extract_first()
if title_result:
items['supply'] = title_result.strip()[1:2]
items['title'] = title_result.strip()[3:]
creatte_time = re.findall(r"<font color='999999'>时间:(\d+/\d+/\d+ \d+:\d+)  ", response.text)
if creatte_time:
items['create_time'] = creatte_time[0]
unit = re.findall(r"发布单位</div><div class='xinxisxr'><a href='.*?.aspx'>(.*?)</a>", response.text, re.S)
if unit:
items['unit'] = unit[0]
price = response.xpath('//div[@class="scdbj1"]/text()').extract()
if price:
items['price'] = ''.join(price)
yield items
编写pipelines.py,往mongodb里面存储数据
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class NongcpspiderPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
def __init__(self):
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.db = client['nong']
self.connection = self.db['Info']
self.dbinfo = self.db.authenticate('xxxx', 'xxxx')
def process_item(self, item, spider):
self.connection.save(dict(item))
return item
完成以上步骤就可以进行数据的爬取了,接下来我们来测试一下爬取的效果
编写启动脚本start.py
#encoding: utf-8
from scrapy import cmdline
# cmdline.execute("scrapy crawl qsbk_spider".split())
cmdline.execute(["scrapy", 'crawl', 'nongcp_spider'])
开启settings.py pipelines字段

运行程序,爬取到的效果如下

接下来实现分布式去重爬取
先安装scrapy-redis

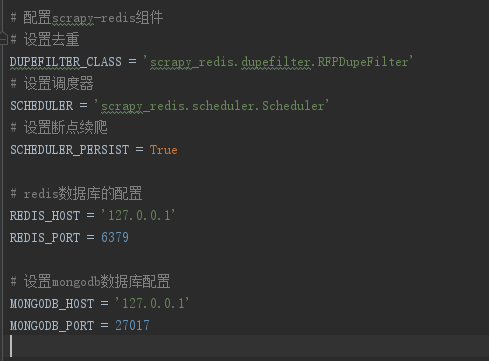
在settings.py里面配置scrapy-redis组件
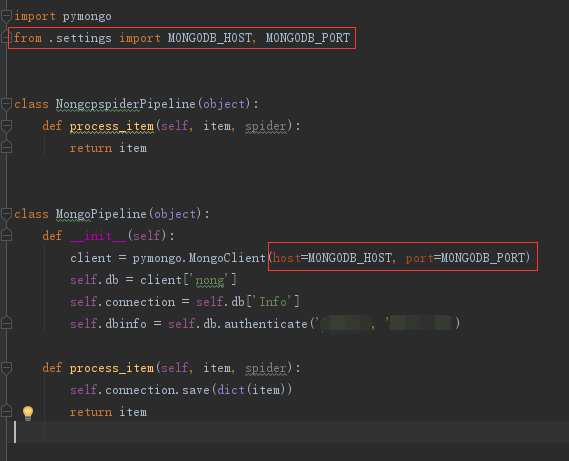
在pipelines.py引入mongdb配置
修改nongcp_spider.py文件
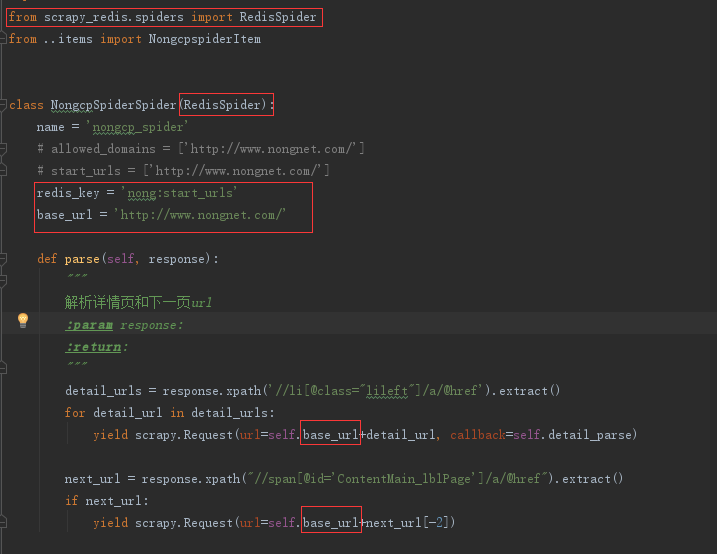
如果爬取过程中出现封ip的操作,我们可以设置middlewares.py,,在该文件设置代理
使用阿布云代理

先启动start.py文件,在运行redis-cli
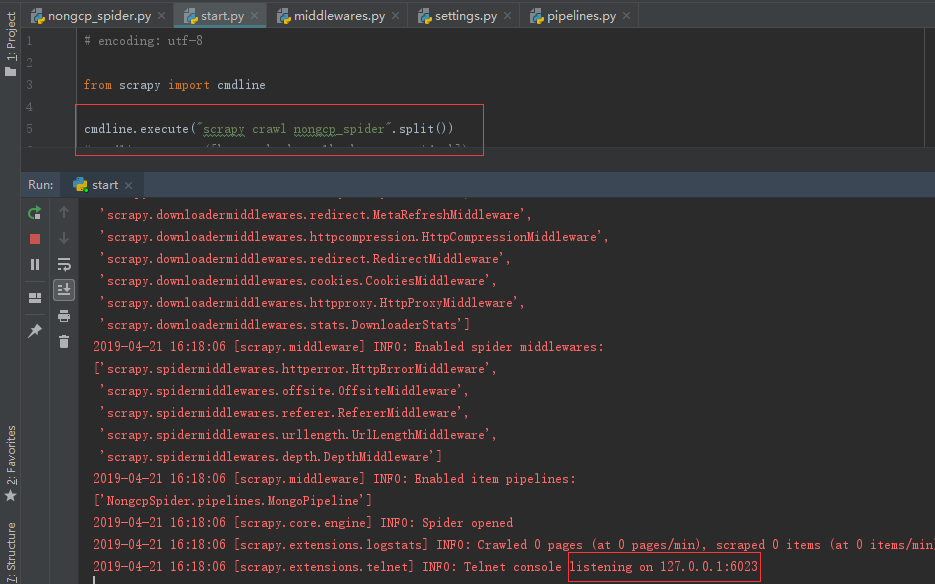

然后就可以抓取数据了到mongdb里面了
---恢复内容结束---
中国农产品信息网站scrapy-redis分布式爬取数据的更多相关文章
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Scrapy持久化存储-爬取数据转义
Scrapy持久化存储 爬虫爬取数据转义问题 使用这种格式,会自动帮我们转义 'insert into wen values(%s,%s)',(item['title'],item['content' ...
- scrapy使用PhantomJS爬取数据
环境:python2.7+scrapy+selenium+PhantomJS 内容:测试scrapy+PhantomJS 爬去内容:涉及到js加载更多的页面 原理:配置文件打开中间件+修改proces ...
- scrapy-redis + Bloom Filter分布式爬取tencent社招信息
scrapy-redis + Bloom Filter分布式爬取tencent社招信息 什么是scrapy-redis 什么是 Bloom Filter 为什么需要使用scrapy-redis + B ...
- scrapy-redis分布式爬取tencent社招信息
scrapy-redis分布式爬取tencent社招信息 什么是scrapy-redis 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/tencent.py 编写 pip ...
- Scrapy 分布式爬取
由于受到计算机能力和网络带宽的限制,单台计算机运行的爬虫咋爬取数据量较大时,需要耗费很长时间.分布式爬取的思想是“人多力量大”,在网络中的多台计算机同时运行程序,公童完成一个大型爬取任务, Scrap ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
- scrapy-redis分布式爬取知乎问答,使用docker布置多台机器。
先上结果: 问题: 答案: 可以看到现在答案文档有十万多,十万个为什么~hh 正文开始: 分布式爬虫应该是在多台服务器(A B C服务器)布置爬虫环境,让它们重复交叉爬取,这样的话需要用到状态管理器. ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
随机推荐
- 【Spring实战】—— 11 通过AOP为特定的类引入新的功能
如果有这样一个需求,为一个已知的API添加一个新的功能. 由于是已知的API,我们不能修改其类,只能通过外部包装.但是如果通过之前的AOP前置或后置通知,又不太合理,最简单的办法就是实现某个我们自定义 ...
- MyEclipse2015Stable3.0破解方法
原理大概是这样的(个人粗略分析):获取当前的日期,来设置证书失效日期,解析后生成码-->再转码,最后生成序列号. 1.新建一个Java工程,(不会安装jdk创建环境变量的,请前往传送门:链接.) ...
- 如何在SAP CRM里创建和消费Web service
Created by Wang, Jerry, last modified on Dec 19, 2014 The following steps demonstrates how to expose ...
- 浅析内存对齐与ANSI C中struct型数据的内存布局-内存对齐规则
这些问题或许对不少朋友来说还有点模糊,那么本文就试着探究它们背后的秘密. 首先,至少有一点可以肯定,那就是ANSI C保证结构体中各字段在内存中出现的位置是随它们的声明顺序依次递增的,并且第一个字段的 ...
- ACM-ICPC(11/9)
今天看了一下黑书,感觉很刘汝佳,是他的风格,题目挺好的~~~ 枚举 P12翻硬币 二进制枚举每一列的情况2^9种. 在每一种情况下然后对于每一行就是翻与不翻的两种情况~~~ 贪心 P13钓鱼问题 PO ...
- ACM-ICPC(10/21)
写一发后缀数组套路题,看起来简单,写起来要人命哦~~~ 总共13题. 分两天debug吧,有点累了~~~ suffix(后缀数组的应用) sa[i] :排名第 i 的后缀在哪(i 从 1 开始) ra ...
- P4722 【模板】最大流
P4722 [模板]最大流 加强版 / 预流推进 今日心血来潮,打算学习hlpp 然后学了一阵子.发现反向边建错了.容量并不是0.qwq 然后就荒废了一晚上. 算法流程的话.有时间补上 #includ ...
- P1800 software_NOI导刊2010提高(06)
P1800 software_NOI导刊2010提高(06) 题目描述 一个软件开发公司同时要开发两个软件,并且要同时交付给用户,现在公司为了尽快完成这一任务,将每个软件划分成m个模块,由公司里的技术 ...
- SpringBoot非官方教程 | 第七篇:springboot开启声明式事务
转载请标明出处: http://blog.csdn.net/forezp/article/details/70833629 本文出自方志朋的博客 springboot开启事务很简单,只需要一个注解@T ...
- JavaWeb项目中各个文件夹的作用
/WEB-INF/web.xml Web应用程序配置文件,描述了 servlet 和其他的应用组件配置及命名规则. /WEB-INF/classes/ 包含了站点所有用的 class 文件,包括 se ...