Centos7 搭建 hadoop3.1.1 集群教程
配置环境要求:
- Centos7
- jdk 8
- Vmware 14 pro
- hadoop 3.1.1
Hadoop下载

安装4台虚拟机,如图所示
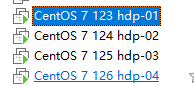
克隆之后需要更改网卡选项,ip,mac地址,uuid

- 重启网卡:
为了方便使用,操作时使用的root账户
设置机器名称

再使用hostname命令,观察是否更改
类似的,更改其他三台机器hdp-02、hdp-03、hdp-04。
在任意一台机器Centos7上修改域名映射
- vi /etc/hosts
- 修改如下
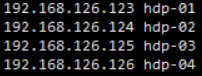
使用scp命令发送其他克隆机上 scp /etc/hosts 192.168.126.124:/etc/
给四台机器生成密钥文件
 确认生成。
确认生成。- 把每一台机器的密钥都发送到hdp-01上(包括自己)

 将所有密钥都复制到每一台机器上
将所有密钥都复制到每一台机器上
在每一台机器上测试
- 无需密码则成功,保证四台机器之间可以免密登录

安装Hadoop
- 在usr目录下创建Hadoop目录,以保证Hadoop生态圈在该目录下。
- 使用xsell+xFTP传输文
解压缩Hadoop

配置java与hadoop环境变量
export JAVA_HOME=/usr/jdk/jdk1..0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH export HADOOP_HOME=/usr/hadoop/hadoop-3.1./
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:以上四台机器都需要配置环境变量
修改etc/hadoop中的配置文件
注:除了个别提示,其余文件只用修改hdp-01中的即可
- 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 注意别的slave机需要识别master主机名,否则将不能与主机hdp-01沟通 -->
<value>hdfs://hdp-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 以下为存放临时文件的路径 -->
<value>/opt/hadoop/hadoop-3.1.1/data/tmp</value>
</property>
</configuration> 修改hadoop-env.sh
export JAVA_HOME=/usr/jdk/jdk1.8.0_131
注:该步骤需要四台都配置
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<!-- hserver1 修改为你的机器名或者ip -->
<value>hdp-01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>dfs.replication</name>
<!-- 备份次数 -->
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data</value>
</property> </configuration>修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改 workers
hdp-
hdp-
hdp-
hdp-修改yarn-site.xml文件
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property> </configuration>注:可以把整个/usr/hadoop目录所有文件复制到其余三个机器上 还是通过scp 嫌麻烦的可以先整一台机器,然后再克隆
启动Hadoop
在namenode上初始化
因为hdp-01是namenode,hdp-02、hdp=03和hdp-04都是datanode,所以只需要对hdp-01进行初始化操作,也就是对hdfs进行格式化。
执行初始化脚本,也就是执行命令:hdfs namenode -format
等待一会后,不报错返回 “Exiting with status 0” 为成功,“Exiting with status 1”为失败
在namenode上执行启动命令
直接执行start-all.sh 观察是否报错,如报错执行一下内容
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh在空白位置加入
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh在空白位置加入
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
$ vim start-all.sh
$ vim stop-all.sh
TANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root配置完毕后执行start-all.sh
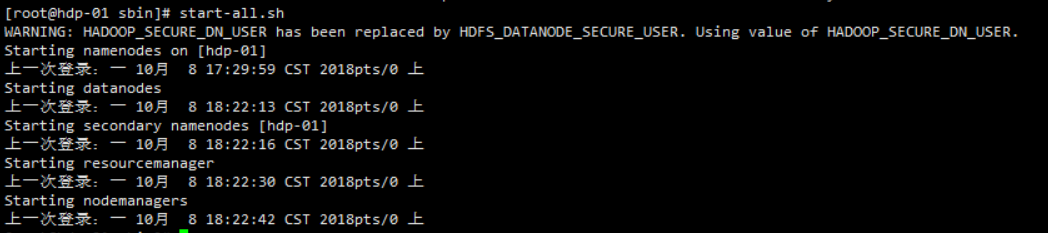
运行jps
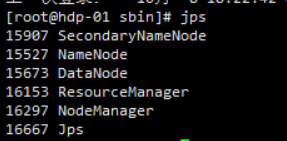
显示6个进程说明配置成功
- 去浏览器检测一下 http://hdp-01:50070
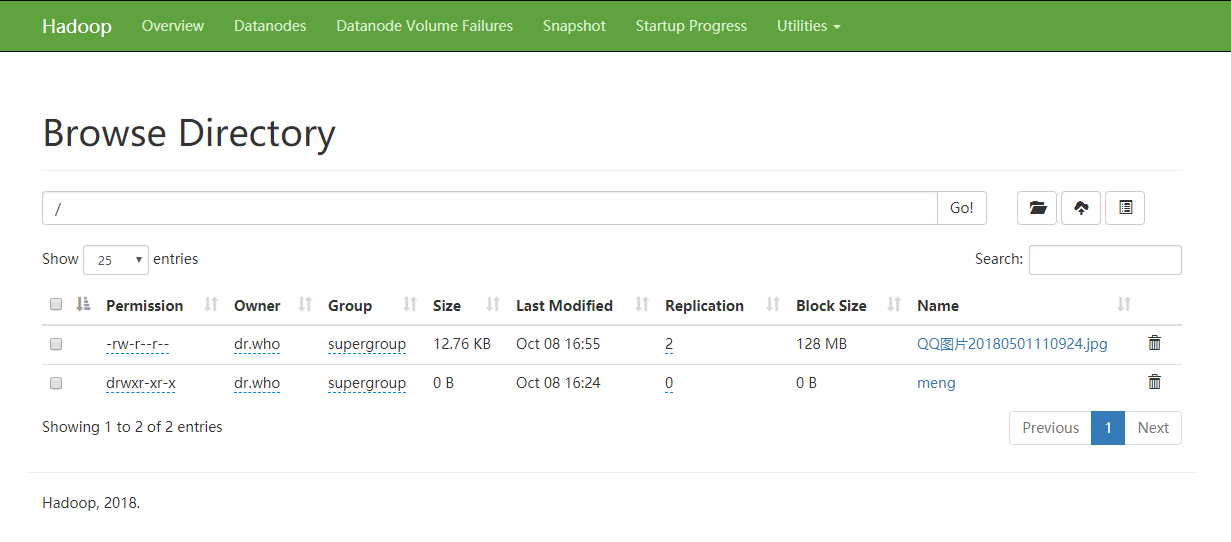
创建目录 上传不成功需要授权
hdfs dfs -chmod -R a+wr hdfs://hdp-01:9000/
//查看容量
hadoop fs -df -h /
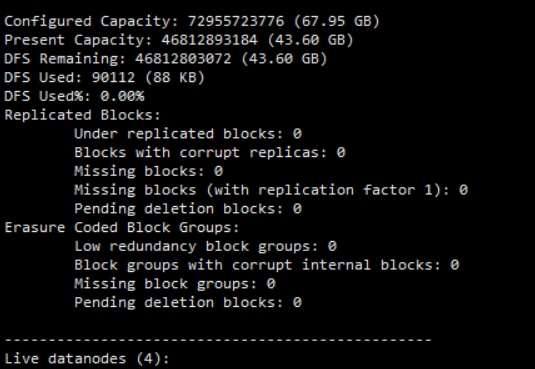
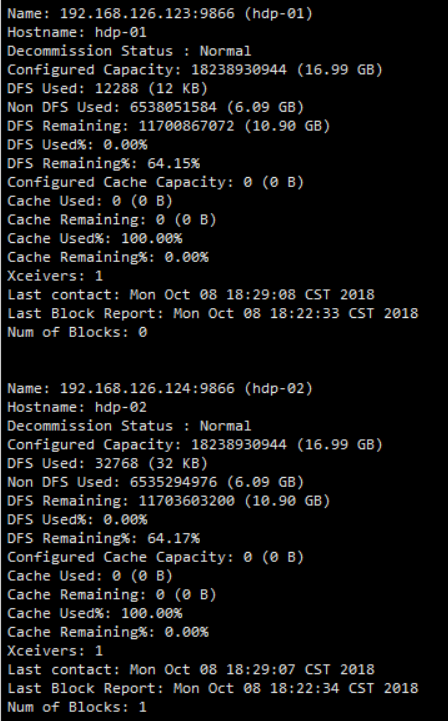
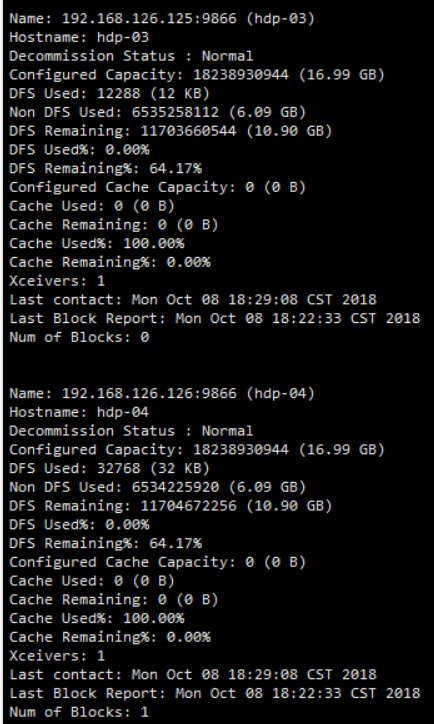
- 查看各个机器状态报告
hadoop dfsadmin -report
Centos7 搭建 hadoop3.1.1 集群教程的更多相关文章
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- 18-基于CentOS7搭建RabbitMQ3.10.7集群镜像队列+HaProxy+Keepalived高可用架构
集群架构 虚拟机规划 IP hostname 节点说明 端口 控制台地址 192.168.247.150 rabbitmq.master rabbitmq master 5672 http://192 ...
- CentOS7搭建Pacemaker高可用集群(1)
Pacemaker是Red Hat High Availability Add-on的一部分.在RHEL上进行试用的最简单方法是从Scientific Linux 或CentOS存储库中进行安装 环境 ...
- Storm(二)CentOS7.5搭建Storm1.2.2集群
一.Storm的下载 官网下载地址:http://storm.apache.org/downloads.html 这里下载最新的版本storm1.2.2,进入之后选择一个镜像下载 二.Storm伪分布 ...
- HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一.安装前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是j ...
- centos7下安装zookeeper&zookeeper集群的搭建
一.centos7下安装zookeeper 1.zookeeper 下载地址 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 2.安装步骤 ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
随机推荐
- SOL的补充
之前写过一些关于远程安装系统的文档,但是对于SOL还是糊涂不清. Serial Console 可以将输入输出转发到串行接口(com1, com2), 假如你有串行读取设备,就可以看到显示,控制输入. ...
- 解决Image在canvas以及audio、video在AudioContext下跨域问题
媒体元素嘛,在对应的标签或对象上加上 crossOrigin = 'anonymous' 即可. 例如 Image 在canvas 上绘制时会跨域: <img crossOrigin=" ...
- bootstrap时时提醒填入数据是否与数据库数据重复
standardcode: { group: '.col-sm-4',//对应前台input的class占用宽度 validators: { notEmpty: { message: '请输入标准代号 ...
- Zookeeper的集群配置和Java测试程序
Zookeeper是Apache下的项目之一,倾向于对大型应用的协同维护管理工作.IBM则给出了IBM对ZooKeeper的认知: Zookeeper 分布式服务框架是 Apache Hadoop 的 ...
- [图]Windows 10 Build 16273版本更新发布:新增可变式字体Bahnschrift
在经历了长达三周的等待之后,微软于今天终于面向Windows Insider项目的Fast通道用户发布了Windows 10 Build 16273版本更新.事实上,微软应该会在两周前就应该发布新版本 ...
- mif文件C语言生成
1:正弦波 用函数 sin (x * π/180°) /************************************************** 正弦波 mif 生成 ********** ...
- codeforces 611D New Year and Ancient Prophecy
f[i = 以i结尾][j = 长度为j] = 方案数. f[i][j] = sum{ f[i-j][k] , k < j || (k == j && s(i-j+1,j) &g ...
- UVALive 6261 Jewel heist
题意:珠宝大盗Arsen Lupin偷珠宝.在展厅内,每颗珠宝有个一个坐标为(xi,yi)和颜色ci. Arsen Lupin发明了一种设备,可以抓取平行x轴的一条线段下的所有珠宝而不触发警报, 唯一 ...
- 2018.11.24 struts2中的OGNL表达式及两者的结合
OGNL表达式 OGNL:对象视图导航语言. ${user.addr.name} 这种写法就叫对象视图导航. OGNL不仅仅可以视图导航.支持比EL表达式更加丰富的功能. 理解图示 使用OGNL准备工 ...
- mysql五种日期函数
create table timess( id int primary key auto_increment, YEARs ——” DATEs DATE ——” TIMEs TIME ::——::” ...