ubuntu14.04 安装 hadoop2.4.0
转载:ubuntu搭建hadoop-Ver2.6.0完全分布式环境笔记
2 先决条件
确保在你集群中的每个节点上都安装了所有必需软件:JDK ,ssh,Hadoop
3 实验环境搭建
3.1 准备工作
操作系统:Ubuntu
部署:Vmvare
在vmvare安装好一台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:
保证虚拟机的ip和主机的ip在同一个ip段,这样几个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同一个ip段,虚拟机连接设置为桥连。
准备机器:一台master,若干台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:
192.168.100.205 node1(master)
192.168.100.206 node2 (slave1)
192.168.100.207 node3 (slave2)
主机信息:
| 机器名 | IP地址 | 作用 |
| Node1 | 192.168.100.205 | NameNode、JobTracker |
| Node2 | 192.168.100.205 | DataNode、TaskTracker |
| Node3 | 192.168.100.205 | DataNode、TaskTracker |
为保证环境一致先安装好JDK和ssh:
3.2 安装JDK
3.2.1 JDK下载
本地选择的是 JDK 1.8.0_25下在地址为:http://www.oracle.com/technetwork/java/javase/downloads/index.html
3.2.2 JDK安装
下载好后放入指定位置(如/usr/java),使用如下命令安装
|
1
|
tar zxvf jdk-xxx-linux-xxx.tar.gz |
3.2.3 JDK配置
1.进入/etc目录
2.将JDK配置信息加入profile文件
|
1
2
3
4
|
# The following configuration is for Javaexport JAVA_HOME=/usr/java/jdk1.8.0_25export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:JAVA_HOME/lib:$JAVA_HOME/jre/lib |
3.使用下面组合命令使配置生效
|
1
2
|
chmod +x profile (这条命令需要超级权限)source profile |
4.使用下面,验证JDK安装
|
1
|
java -version |
如果安装版本信息显示则安装成功
3.3 配置ssh公钥秘钥自动登录
在hadoop集群环境中,nameNode节点,需要能够ssh无密码登录访问dataNode节点
进入SSH目录:
|
1
2
|
[root@node1 ~]# cd .ssh # 如果没有该目录,先执行一次ssh localhost[root@node2 .ssh]# # 一直按回车就可以,生成的密钥保存为.ssh/id_rsa |
生成公钥密钥对:
|
1
|
[root@nameNode /]# ssh-keygen -t rsa |
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
98:3c:31:5c:23:21:73:a0:a0:1f:c6:d3:c3:dc:58:32 root@gifer
The key's randomart image is:
+--[ RSA 2048]----+
|. E.=.o |
|.o = @ o . |
|. * * = |
| o o o = |
| . = S |
| . |
| |
| |
| |
+------------------+
看到上面输出,表示密钥生成成功,目录下多出两个文件:
私钥文件:id_raa
公钥文件:id_rsa.pub
将公钥文件id_rsa.pub内容放到authorized_keys文件中:
|
1
|
cat id_rsa.pub >> authorized_keys |
将公钥文件authorized_keys分发到各dataNode节点:
|
1
|
scp authorized_keys root@dataNode:/root/.ssh/ |
验证ssh无密码登录:
|
1
2
|
[root@node1 .ssh]# ssh root@node2 Last login: Sun Sep 21 11:38:05 2014 from 192.168.100.205 |
看到以上输出,表示配置成功!如果还提示需要输出密码访问,表示配置失败!
3.4 安装Hadoop(所有节点相同)
3.4.1 Hadoop下载
地址为:http://www.apache.org/dyn/closer.cgi/hadoop/common/
3.4.2 Hadoop安装
将下载下来的Hadoop放入指定目录(/usr/hadoop),使用如下命令安装
|
tar xzf hadoop-2.6.0.tar.gz |
3.4.3 Hadoop配置
1.linux profile(路径:/etc)配置,如下图
|
1
2
3
|
# The following configuration is for hadoopexport HADOOP_INSTALL=/usr/hadoop/hadoop-2.6.0export PATH=$PATH:$HADOOP_INSTALL/bin |
2.hadoop-env.sh(路径:$HADOOP_HOME/etc/hadoop)中把JAVA_HOME指向JDK安装根目录,如下
|
1
2
|
# The java implementation to use.export JAVA_HOME=/usr/java/jdk1.8.0_25 |
3.yarn-env.sh(路径:$HADOOP_HOME/etc/hadoop)中把JAVA_HOME指向JDK安装根目录,如下
|
1
2
|
# some Java parameters exportJAVA_HOME=/usr/java/jdk1.8.0_25 |
4.打开conf/core-site.xml(路径:$HADOOP_HOME/etc/hadoop)文件,编辑如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://node1:9000</value> </property></configuration> |
1)fs.defaultFS是NameNode的URL。hdfs://主机名:端口/
2)hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过 如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
5.打开conf/hdfs-site.xml(路径:$HADOOP_HOME/etc/hadoop)文件,编辑如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node1:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property></configuration> |
1) dfs.namenode.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
2) dfs.datanode.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
3)dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
6.打开conf/mapred-site.xml(路径:$HADOOP_HOME/etc/hadoop)文件,编辑如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property></configuration> |
7.打开conf/yarn-site.xml(路径:$HADOOP_HOME/etc/hadoop)文件,编辑如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<configuration><!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node1:8032</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node1:8088</value> </property></configuration> |
3.5 配置masters和slaves主从结点
配置$HADOOP_HOME/etc/hadoop/slaves文件来设置从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
|
1
|
root@node1:/usr/hadoop/hadoop-2.6.0/etc/hadoop# vi slaves |
输入:
node2
node3
配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh
$ scp -r /home/hadoop/hadoop-2.6.0 root@node2: /home/hadoop/
4 hadoop启动
4.1 格式化一个新的分布式文件系统
先格式化一个新的分布式文件系统
$ cd hadoop-2.6.0
$ bin/hadoop namenode -format
成功情况下系统输出:
12/02/06 00:46:50 INFO namenode.NameNode:STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.203.0
STARTUP_MSG: build =http://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20-security-203-r 1099333; compiled by 'oom' on Wed May 4 07:57:50 PDT 2011
************************************************************/
12/02/0600:46:50 INFO namenode.FSNamesystem: fsOwner=root,root
12/02/06 00:46:50 INFO namenode.FSNamesystem:supergroup=supergroup
12/02/06 00:46:50 INFO namenode.FSNamesystem:isPermissionEnabled=true
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name1 has been successfully formatted.
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name2 has been successfully formatted.
12/02/06 00:46:50 INFO namenode.NameNode:SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode atv-jiwan-ubuntu-0/127.0.0.1
************************************************************/
查看输出保证分布式文件系统格式化成功
执行完后可以到master机器上看到/usr/hadoop/dfs/name目录。在主节点master上面启动hadoop,主节点会启动所有从节点的hadoop。
4.2 启动所有节点
$ sbin/start-all.sh (同时启动HDFS和Map/Reduce)
系统输出:
starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu.out
node2: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node3: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node1: starting secondarynamenode,logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu.out
starting jobtracker, logging to/usr/local/hadoop/logs/hadoop-hadoop-jobtracker-ubuntu.out
node2: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
node3: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
As you can see in slave's output above, it will automatically format it's storage directory(specified by dfs.data.dir) if it is not formattedalready. It will also create the directory
if it does not exist yet.
行完后可以到slave(node1,node2)机器上看到/usr/hadoop/dfs/data目录。
4.3 关闭所有节点
从主节点master关闭hadoop,主节点会关闭所有从节点的hadoop。
$ sbin/stop-all.sh
Hadoop守护进程的日志写入到 ${HADOOP_LOG_DIR} 目录 (默认是 ${HADOOP_HOME}/logs).
${HADOOP_HOME}就是安装路径.
5 测试
1)jps查看NameNode节点和DataNode节点服务
NameNode节点(node1)已开启如下守护进程表示正常:

DataNode(node2、node3)节点开启如下守护进程表示正常:

2)浏览NameNode和JobTracker的网络接口,它们的地址默认为:
NameNode - http://node1:50070/
ResourceManager - http://node1:8088/
NodeManager - http://node2:8042/
3) 使用netstat –nat查看端口:
NameNode节点(node1)启动端口如下:
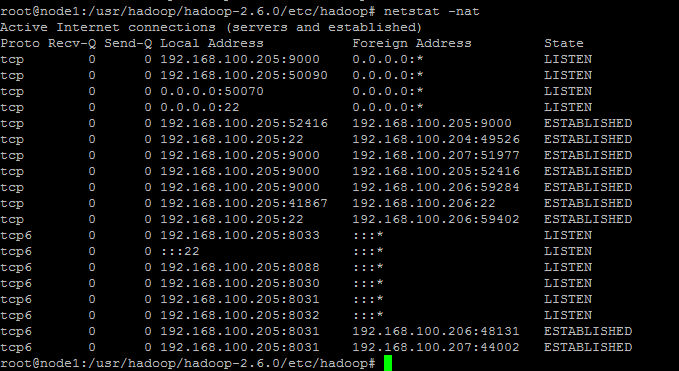
DataNode(node2、node3)节点启动端口如下:

备注:tcp6表示ipv6网络,Linux若禁止ipv6后将默认变更tcp无影响。
4)执行WordCount实例:
a、首先创建所需的几个目录
|
1
2
|
bin/hdfs dfs -mkdir /userbin/hdfs dfs -mkdir /user/hadoop |
b、将etc/hadoop中的文件作为输入文件复制到分布式文件系统中
|
1
|
bin/hdfs dfs -put etc/hadoop /user/hadoop/input |
通过查看DataNode的状态(占用大小有改变),输入文件确实复制到了DataNode中

c、接着就可以运行MapReduce作业了
|
1
|
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+' |
运行时的信息如下所示,显示Job的进度。可能会比较慢,但如果迟迟没有进度,比如10分钟都没看到进度,那不妨重启Hadoop再试试。

同样可以通过Web界面查看任务进度 http://192.168.100.205:8088/cluster

在 Web 界面点击 “Tracking UI” 这一列的 History,可能会提示网页无法打开,遇到这种情况需要手动开启 jobhistory server,开启之后刷新页面再点击就可以打开了。
|
1
|
sbin/mr-jobhistory-daemon.sh start historyserver |
注:执行上述语句后,jps查看JobHistoryServer进程已经开启,通过web(http://192.168.100.205:19888/jobhistory)访问JobHistoryServer没有问题。但是在上面ResourceManagerWeb界面中点击 “Tracking UI” 这一列的 History,依旧提示网页无法打开。
发现URL:http://node1:19888/jobhistory/job/job_1418203576437_0001/jobhistory/job/job_1418203576437_0001,使用的是机器名node1来访问。因为我用的是hadoop集群外部机器web访问。需要修改该机器(win7系统)的hosts文件,修改方法如下:
进入C:\Windows\System32\drivers\etc,修改hosts文件。文件中追加如下内容(注意后面需要一个回车换行):
|
192.168.100.205 node1 192.168.100.206 node2 192.168.100.207 node3 |
通过这些修改若上面ResourceManagerWeb界面中点击 “Tracking UI” 这一列的 History,依旧提示网页无法打开。则重启下hadoop(守护进程),重新执行测试程序后,History网页就可以打开了。
d、执行完毕后的输出结果:
|
1
|
bin/hdfs dfs -cat /user/hadoop/output/* |

e)补充
Q: bin/hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'什么意思啊?
A: bin/hadoop jar(使用hadoop运行jar包)hadoop-mapreduce-examples-2.6.0.jar(jar包的名字) grep (要使用的类,后边的是参数)input output 'dfs[a-z.]+'
整个就是运行hadoop示例程序中的grep,对应的hdfs上的输入目录为input、输出目录为output。
Q: 什么是grep?
A: A map/reduce program that counts the matches of a regex in the input.
6 HDFS常用操作
hadoop dfs -ls 列出HDFS下的文件
hadoop dfs -ls in 列出HDFS下某个文档中的文件
hadoop dfs -put test1.txt test 上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功
hadoop dfs -get in getin 从HDFS获取文件并且重新命名为getin,同put一样可操作文件也可操作目录
hadoop dfs -rmr out 删除指定文件从HDFS上
hadoop dfs -cat in/* 查看HDFS上in目录的内容
hadoop dfsadmin -report 查看HDFS的基本统计信息,结果如下
hadoop dfsadmin -safemode leave 退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式
7 添加节点
可扩展性是HDFS的一个重要特性:
1)首先在新加的节点上安装hadoop
2)然后修改etc/hosts文件,加入 DataNode主机名
3)然后在NameNode节点上修改$HADOOP_HOME/conf/slaves文件,加入新加节点主机名
4)建立到新加节点无密码的SSH连接
5)NameNode节点上运行启动命令:start-all.sh
然后可以通过http://(Masternode的主机名):50070查看新添加的DataNode
8 负载均衡
start-balancer.sh,可以使DataNode节点上选择策略重新平衡DataNode上的数据块的分布
9 结束语
遇到问题时,先查看logs,很有帮助,查看log方法如下:
cat /usr/hadoop/hadoop-2.6.0/logs/*.log
如果日志在更新,如何实时查看 tail -f /usr/hadoop/hadoop-2.6.0/logs/*.log
还可以使用 watch -d -n 1 cat /usr/hadoop/hadoop-2.6.0/logs/*.log
-d表示高亮不同的地方,-n表示多少秒刷新一次。
该指令,不会直接返回命令行,而是实时打印日志文件中新增加的内容,这一特性,对于查看日志是非常有效的。如果想终止输出,按 Ctrl+C 即可。
ubuntu14.04 安装 hadoop2.4.0的更多相关文章
- ubuntu14.04安装hadoop2.6.0(伪分布模式)
版本:虚拟机下安装的ubuntu14.04(64位),hadoop-2.6.0 下面是hadoop2.6.0的官方英文教程: http://hadoop.apache.org/docs/r2.6.0/ ...
- ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境 本文主要参考 给力星的博文——Hadoop集群安 ...
- Ubuntu14.04 安装配置Opencv3.0和Python2.7
http://blog.csdn.NET/u010381648/article/details/49452023 Install OpenCV 3.0 and Python 2.7+ on Ubunt ...
- spark 1.6.0 安装与配置(spark1.6.0、Ubuntu14.04、hadoop2.6.0、scala2.10.6、jdk1.7)
前几天刚着实研究spark,spark安装与配置是入门的关键,本人也是根据网上各位大神的教程,尝试配置,发现版本对应最为关键.现将自己的安装与配置过程介绍如下,如有兴趣的同学可以尝试安装.所谓工欲善其 ...
- ubuntu14.04搭建Hadoop2.9.0伪分布式环境
本文主要参考 给力星的博文——Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04 一些准备工作的基本步骤和步骤具体说明本文不再列出,文章中提到的“见参考”均指以上 ...
- Ubuntu14.04下hadoop-2.6.0单机配置和伪分布式配置
需要重新编译的教程:http://blog.csdn.net/ggz631047367/article/details/42460589 在Ubuntu下创建hadoop用户组和用户 hadoop的管 ...
- 二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式)
在Ubuntu14.04下安装Hadoop2.4.0 (单机模式)基础上配置 一.配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml ...
- 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- ubuntu14.04 安装 tensorflow9.0
ubuntu14.04 安装 tensorflow9.0 文章目录 ubuntu14.04 安装 tensorflow9.0 安装pip(笔者的版本为9.0) 仅使用 CPU 的版本的tensorfl ...
随机推荐
- Feature Access
在ArcGIS Server中发布支持Feature Access地图服务,你需要知道的几点: 所绘制的mxd地图文件中包含的数据,必须来自企业级数据库链接: mxd中包含的所有图层的数据,必须来自同 ...
- Python: 利用Python进行数据分析 学习记录
-----15:18 2016/10/14----- 1. import numpy as np;import pandas as pd values = pd.Series(np.random.no ...
- [转]jquery mobile中redirect重定向问题
本文转自:http://www.cnblogs.com/freeliver54/p/3529813.html 在jquerymobile提交后如果要进行网页重定向时,一定要在form或<a> ...
- 【http】四种常见的 POST 提交数据方式
来源:http://www.cnblogs.com/aaronjs/p/4165049.html HTTP/1.1 协议规定的 HTTP 请求方法有 OPTIONS.GET.HEAD.POST.PUT ...
- js学习进阶中-bind()方法
有次面试遇到的,也是没说清楚具体的作用,感觉自己现在还是没有深刻的理解! bind():绑定事件类型和处理函数到DOM element(父元素上) live():绑定事件到根节点上,(document ...
- ios项目里扒出来的json文件
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Menlo; color: #000000 } p.p2 { margin: 0.0px 0. ...
- oh my zsh
简单使用oh my zsh 安装oh my Zsh 安装zsh 安装curl或者wget 下载并安装oh my zsh: curl 下载方式curl -L https://raw.github.com ...
- js 字符串操作函数
concat() – 将两个或多个字符的文本组合起来,返回一个新的字符串. indexOf() – 返回字符串中一个子串第一处出现的索引.如果没有匹配项,返回 -1 . charAt() – 返回指定 ...
- iOS - .a静态库的打包(包括打包的文件中用到了一些别人的三方库和分类的处理)
一.概念篇 什么是库? 库是程序代码的集合,是共享程序代码的一种方式 根据源代码的公开情况,库可以分为2种类型 开源库 公开源代码,能看到具体实现 比如SDWebImage.AFNetworking ...
- Python ToDo List
这是我在学习python过程中,想做又没来得及做的事情一览.最初只有寥寥几个字,我会尽力去消化,让它不会只增不减. 由于博客园奇怪的算法,明明是一篇非常没有含量的东西(连字数都没有达到),居然能荣登p ...