在 C/C++ 中使用 TensorFlow 预训练好的模型—— 间接调用 Python 实现
现在的深度学习框架一般都是基于 Python 来实现,构建、训练、保存和调用模型都可以很容易地在 Python 下完成。但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过 C/C++ 间接调用 Python 的方式来实现在 C/C++ 程序中调用 TensorFlow 预训练好的模型。
1. 环境配置
为了能在 C/C++ 中调用 Python,我们需要配置一下头文件和库的路径,本文以 Code::Blocks 为例介绍。
在 Build -> Project options 添加链接库 libpython3.5m.so 和头文件 Python.h 所在的路径,不同 Python 版本可以自己根据情况调整。
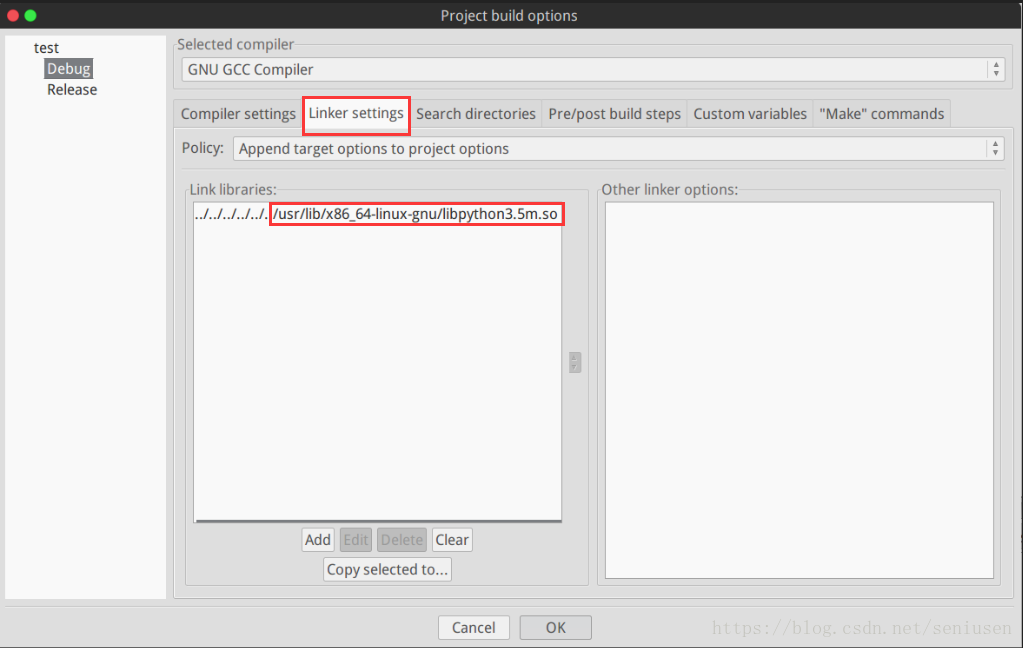
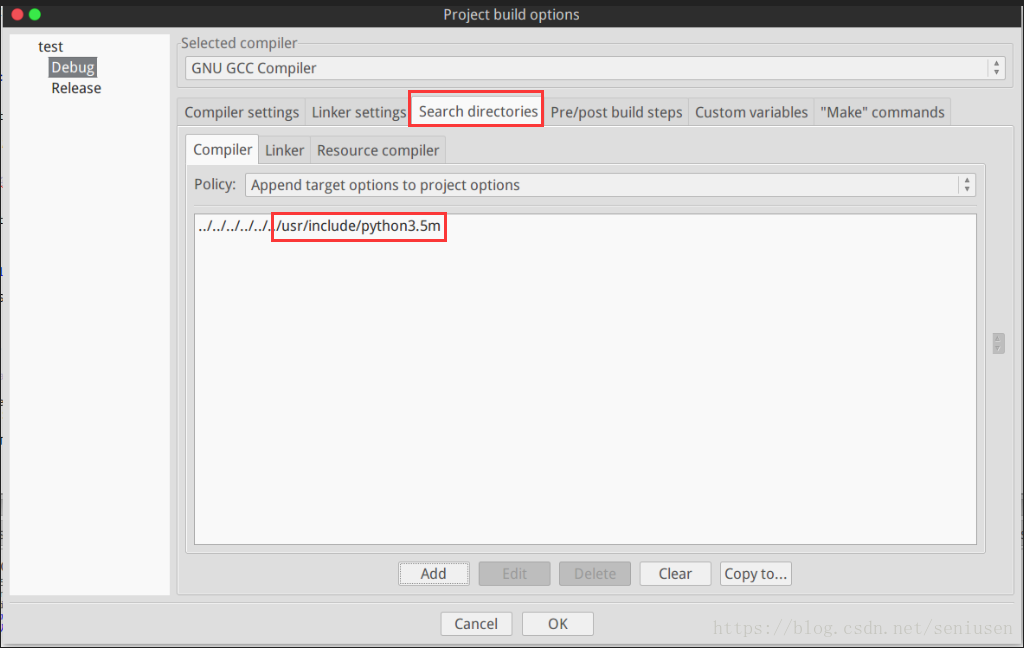
2. 初始化并导入 Python 模块及相关函数
void Initialize()
{
Py_Initialize();
if ( !Py_IsInitialized() )
{
printf("Initialize failed!");
}
// Path of the python file. 需要更改为 python 文件所在路径
PyRun_SimpleString("import sys");
PyRun_SimpleString("sys.path.append('/home/senius/python/c_python/test/')");
const char* modulName = "forward"; // Module name of python file.
pMod = PyImport_ImportModule(modulName);
if(!pMod)
{
printf("Import Module failed!\n");
}
const char* funcName = "load_model"; // Function name in the python file.
load_model = PyObject_GetAttrString(pMod, funcName);
if(!load_model)
{
printf("Import load_model Function failed!\n");
}
funcName = "predict"; // Function name in the python file.
predict = PyObject_GetAttrString(pMod, funcName);
if(!predict)
{
printf("Import predict Function failed!\n");
}
PyEval_CallObject(load_model, NULL); // 导入预训练的模型
pParm = PyTuple_New(1); // 新建一个元组,参数只能通过元组传入 Python 程序
}
- 通过 PyImport_ImportModule 我们可以导入需要调用的 Python 文件,然后再通过 PyObject_GetAttrString 得到模块里面的函数,最后导入预训练的模型并新建一个元组作为参数的传入。
3. 构建从 C 传入 Python 的参数
void Read_data()
{
const char* txtdata_path = "/home/senius/python/c_python/test/04t30t00.npy";
//Path of the TXT file. 需要更改为txt文件所在路径
FILE *fp;
fp = fopen(txtdata_path, "rb");
if(fp == NULL)
{
printf("Unable to open the file!");
}
fread(data, num*SIZE, sizeof(float), fp);
fclose(fp);
// copying the data to the list
int j = 0;
pArgs = PyList_New(num * SIZE); // 新建一个列表,并填入数据
while(j < num * SIZE)
{
PyList_SET_ITEM(pArgs, j, Py_BuildValue("f", data[j]));
j++;
}
}
- 读入测试数据,并将数据填入到一个列表。
4. 将列表传入元组,然后作为参数传入 Python 中,并解析返回值
void Test()
{
PyTuple_SetItem(pParm, 0, pArgs);
pRetVal = PyEval_CallObject(predict, pParm);
int list_len = PyList_Size(pRetVal);
PyObject *list_item = NULL;
PyObject *tuple_item = NULL;
for (int i = 0; i < list_len; i++)
{
list_item = PyList_GetItem(pRetVal, i);
tuple_item = PyList_AsTuple(list_item);
PyArg_ParseTuple(tuple_item, "f", &iRetVal[i]);
}
}
- 传入元组到 Python 程序,调用 predict 函数得到返回值,然后进行解析。
5. 一些参数和主函数
#include <Python.h>
#include <stdio.h>
#define SIZE 41*41*41*3
#define NUM 100
PyObject* pMod = NULL;
PyObject* load_model = NULL;
PyObject* predict = NULL;
PyObject* pParm = NULL;
PyObject* pArgs = NULL;
PyObject* pRetVal = NULL;
float iRetVal[NUM*3] = {0};
float data[NUM * SIZE] = {0};
int num = 1; //实际的样本数100
void Initialize();
void Read_data();
void Test();
int main(int argc, char **argv)
{
Initialize(); // 初始化
Read_data(); // 读入数据
Test(); // 调用预测函数并解析返回值
int j = 0;
while(j < num*3)
{
printf("%f\n", iRetVal[j]);
j++;
}
printf("Done!\n");
Py_Finalize();
return 0;
}
获取更多精彩,请关注「seniusen」!
在 C/C++ 中使用 TensorFlow 预训练好的模型—— 间接调用 Python 实现的更多相关文章
- 在 C/C++ 中使用 TensorFlow 预训练好的模型—— 直接调用 C++ 接口实现
现在的深度学习框架一般都是基于 Python 来实现,构建.训练.保存和调用模型都可以很容易地在 Python 下完成.但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过直 ...
- TensorFlow 调用预训练好的模型—— Python 实现
1. 准备预训练好的模型 TensorFlow 预训练好的模型被保存为以下四个文件 data 文件是训练好的参数值,meta 文件是定义的神经网络图,checkpoint 文件是所有模型的保存路径,如 ...
- TensorFlow 同时调用多个预训练好的模型
在某些任务中,我们需要针对不同的情况训练多个不同的神经网络模型,这时候,在测试阶段,我们就需要调用多个预训练好的模型分别来进行预测. 调用单个预训练好的模型请点击此处 弄明白了如何调用单个模型,其实调 ...
- 【猫狗数据集】使用预训练的resnet18模型
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
- pytorch中如何使用预训练词向量
不涉及具体代码,只是记录一下自己的疑惑. 我们知道对于在pytorch中,我们通过构建一个词向量矩阵对象.这个时候对象矩阵是随机初始化的,然后我们的输入是单词的数值表达,也就是一些索引.那么我们会根据 ...
- 转载:tensorflow保存训练后的模型
训练完一个模型后,为了以后重复使用,通常我们需要对模型的结果进行保存.如果用Tensorflow去实现神经网络,所要保存的就是神经网络中的各项权重值.建议可以使用Saver类保存和加载模型的结果. 1 ...
- tensorflow 使用预训练好的模型的一部分参数
vars = tf.global_variables() net_var = [var for var in vars if 'bi-lstm_secondLayer' not in var.name ...
- Tensorflow 用训练好的模型预测
本节涉及点: 从命令行参数读取需要预测的数据 从文件中读取数据进行预测 从任意字符串中读取数据进行预测 一.从命令行参数读取需要预测的数据 训练神经网络是让神经网络具备可用性,真正使用神经网络时,需要 ...
- Tensorflow使用训练好的模型进行测试,发现计算速度越来越慢
实验时要对多个NN模型进行对比,依次加载直到第8个模型时,发现运行速度明显变慢而且电脑开始卡顿,查看内存占用90+%. 原因:使用过的NN模型还会保存在内存,继续加载一方面使新模型加载特别特别慢,另一 ...
随机推荐
- Ueditor插入script标签
对于这个问题.我想有的人会遇到有的人不会遇到,后面说为什么. 有的人会百度解决问题.百度官方文档这样回答 然而你去editor_config.js搜索根本找不到这个配置.(百度你该更新了.....) ...
- sql server 自增长显式添加值
如果想在自增列添加数据,会提示我们不能插入显式值 解决:
- ffmpeg一些filter用法、以及一些功能命令
来源:http://blog.csdn.net/dancing_night/article/details/46776903 1.加字幕 命令:ffmpeg -i <input> -fil ...
- js,h5页面判断客户端是ios还是安卓
$(function(){ var u = navigator.userAgent, app = navigator.appVersion; var isAndroid = u.indexOf('An ...
- Python学习之路——基础2(含深浅拷贝)
逻辑运算符:not and or 等同于c/c++中的 !.&&.||,除了写法上的不同,实际原理是一样的. 运算也遵循短路原则.由于Python本身不支持++/--操作符,所以避 ...
- A^B Mod C (51Nod - 1046 )(快速幂)
给出3个正整数A B C,求A^B Mod C. 例如,3 5 8,3^5 Mod 8 = 3. Input 3个正整数A B C,中间用空格分隔.(1 <= A,B,C <= 10^ ...
- PHPStorm+Xdebug断点远程调试PHP xdebug安装
一.xdebug安装 wget http://www.xdebug.org/files/xdebug-2.2.3.tgz #下载Xdebug tar xzf xdebug-2.2.3.tgz cd x ...
- CentOS7——网络配置
ip addr #查看当前IP地址信息.(contos7以下的为ifconfig) /etc/sysconfig/network-scripts/ifcfg-*** #***代表不一定的,需要进入该设 ...
- 构建高可靠hadoop集群之2-机栈
本文主要参考 http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/RackAwareness.html had ...
- Java OOP——第三章 多态
1.多态:(polymorphism): 是具有表现多种形态能力的特征: (专业化的说法:)同一个实现接口(引用类型),使用不同的实例而执行不同的操作 指一个引用(类型)在不同情况下的多种状态.也可以 ...