Linux上安装Hadoop集群(CentOS7+hadoop-2.8.3)
https://blog.csdn.net/pucao_cug/article/details/71698903
2.5 在hserver1上创建authorized_keys文件
关键字:Linux CentOS Hadoop Java
版本: CentOS7 Hadoop2.8.0 JDK1.8
说明:Hadoop从版本2开始加入了Yarn这个资源管理器,Yarn并不需要单独安装。只要在机器上安装了JDK就可以直接安装Hadoop,单纯安装Hadoop并不依赖Zookeeper之类的其他东西。
1下载hadoop
本博文使用的hadoop是2.8.0
打开下载地址选择页面:
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
如图:

我使用的地址是:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
2安装3个虚拟机并实现ssh免密码登录
2.1安装3个机器
这里用的Linux系统是CentOS7(其实Ubuntu也很好,但是这里用的是CentOS7演示),安装方法就不多说了,如有需要请参考该博文:
http://blog.csdn.net/pucao_cug/article/details/71229416
安装3个机器,机器名称分别叫hserver1、hserver2、hserver3(说明机器名不这么叫可以,待会用hostname命令修改也行)。
如图:

说明:为了免去后面一系列授权的麻烦,这里直接使用root账户登录和操作了。
使用ifconfig命令,查看这3个机器的IP。我的机器名和ip的对应关系是:
192.168.119.128 hserver1
192.168.119.129 hserver2
192.168.119.130 hserver3
2.2检查机器名称
为了后续操作方便,确保机器的hostname是我们想要的。拿192.168.119.128这台机器为例,用root账户登录,然后使用hostname命令查看机器名称
如图:

发现,这个机器名称不是我们想要的。不过这个好办, 我给它改个名称,命令是:
hostname hserver1
如图:

执行完成后,在检查看,是否修改了,敲入hostname命令:
如图:

类似的,将其他两个机器,分别改名为hserver2和hserver3。
2.3 修改/etc/hosts文件
修改这3台机器的/etc/hosts文件,在文件中添加以下内容:
- 192.168.119.128 hserver1
- 192.168.119.129 hserver2
- 192.168.119.130 hserver3
如图:

说明:IP地址没必要和我的一样,这里只是做一个映射,只要映射是对的就可以,至于修改方法,可以用vim命令,也可以在你的本地机器上把hosts文件内容写好后,拿到Linux机器上去覆盖。
配置完成后使用ping命令检查这3个机器是否相互ping得通,以hserver1为例,在什么执行命令:
ping -c 3 hserver2
如图:

执行命令:
ping -c 3 hserver3
如图:

ping得通,说明机器是互联的,而且hosts配置也正确。
2.4给3个机器生成秘钥文件
以hserve1为例,执行命令,生成空字符串的秘钥(后面要使用公钥),命令是:
ssh-keygen -t rsa -P ''
(我安装博文这个命令执行最后无法root用户免密码登录成功,我改成了ssh-keygen然后多次回车生成)
如图:
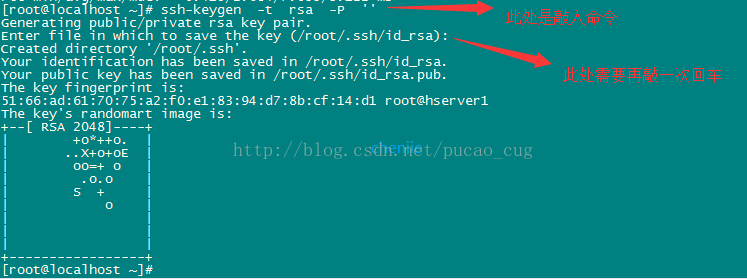
因为我现在用的是root账户,所以秘钥文件保存到了/root/.ssh/目录内,可以使用命令查看,命令是:
ls /root/.ssh/
如图:

使用同样的方法为hserver2和hserver3生成秘钥(命令完全相同,不用做如何修改)。
2.5在hserver1上创建authorized_keys文件
接下来要做的事情是在3台机器的/root/.ssh/目录下都存入一个内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才为3台机器生成的公钥。为了方便,我下面的步骤是现在hserver1上生成authorized_keys文件,然后把3台机器刚才生成的公钥加入到这个hserver1的authorized_keys文件里,然后在将这个authorized_keys文件复制到hserver2和hserver3上面。
首先使用命令,在hserver1的/root/.ssh/目录中生成一个名为authorized_keys的文件,命令是:
touch /root/.ssh/authorized_keys
如图:

可以使用命令看,是否生成成功,命令是:
ls /root/.ssh/
如图:

其次将hserver1上的/root/.ssh/id_rsa.pub文件内容,hserver2上的/root/.ssh/id_rsa.pub文件内容,hserver3上的/root/.ssh/id_rsa.pub文件内容复制到这个authorized_keys文件中,复制的方法很多了,可以用cat命令和vim命令结合来弄,也可以直接把这3台机器上的/root/.ssh/id_rsa.pub文件下载到本地,在本地将authorized_keys文件编辑好在上载到这3台机器上。
hserver1机器上我的/root/.ssh/id_rsa.pub内容是:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD8fTIVorOxgDo81yCEgcJTstUcyfOBecL+NZ/OLXCEzaBMw5pLV0UNRX6SZnaAgu/erazkz4sw74zfRIMzEeKKCeNcZ6W78cg+ZNxDcj8+FGeYqY5+nc0YPhXFVI7AwFmfr7fH5hoIT14ClKfGklPgpEgUjDth0PeRwnUTvUy9A1x76npjAZrknQsnoLYle7cVJZ/zO3eGxS75YEdTYDMv+UMiwtcJg7UxOqR+9UT3TO+xLk0yOl8GIISXzMhdCZkmyAH+DmW56ejzsd+JWwCMm177DtOZULl7Osq+OGOtpbloj4HCfstpoiG58SM6Nba8WUXWLnbgqZuHPBag/Kqjroot@hserver1
hserver2机器上我的/root/.ssh/id_rsa.pub内容是:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC29kPkYz4c3bd9Qa1TV8kCR0bUNs4f7/dDcR1NKwrgIiecN7zPEWJpjILtlm3niNNx1j5R49QLTLBKKo8PE8mid47POvNypkVRGDeN2IVCivoAQ1T7S8bTJ4zDECGydFYyKQfS2nOAifAWECdgFFtIp52d+dLIAg1JC37pfER9f32rd7anhTHYKwnLwR/NDVGAw3tMkXOnFuFKUMdOJ3GSoVOZf3QHKykGIC2fz/lsXZHaCcQWvOU/Ecd9e0263Tvqh7zGWpF5WYEGjkLlY8v2sioeZxgzog1LWycUTMTqaO+fSdbvKqVj6W0qdy3Io8bJ29Q3S/6MxLa6xvFcBJEXroot@hserver2
hserver2机器上我的/root/.ssh/id_rsa.pub内容是:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1a2o10ttv2570GpuUZy7g9o7lIkkeed7ba25VvFEBcUroQIZ+NIAiVIMGPRiOqm7X4bTLWj5EOz5JXG2l8rwA6CFnWfW3U+ttD1COLOrv2tHTiJ1PhQy1jJR/LpC1iX3sNIDDs+I0txZFGTCTRMLmrbHVTl8j5Yy/CTYLuC7reIZjzpHP7aaS2ev0dlbQzeB08ncjA5Jh4X72qQMOGPUUc2C9oa/CeCvI0SJbt8mkHwqFanZz/IfhLJIKhupjtYsqwQMmzLIjHxbLRwUGoWU6X4e76OkUz/xyyHlzBg1Vu2F9hjoXPW80VmupIRSXFDliDBJ8NlXXQN47wwYBG28broot@hserver3
合并之后,我的hserver1机器上的/root/.ssh/authorized_keys文件内容是:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD8fTIVorOxgDo81yCEgcJTstUcyfOBecL+NZ/OLXCEzaBMw5pLV0UNRX6SZnaAgu/erazkz4sw74zfRIMzEeKKCeNcZ6W78cg+ZNxDcj8+FGeYqY5+nc0YPhXFVI7AwFmfr7fH5hoIT14ClKfGklPgpEgUjDth0PeRwnUTvUy9A1x76npjAZrknQsnoLYle7cVJZ/zO3eGxS75YEdTYDMv+UMiwtcJg7UxOqR+9UT3TO+xLk0yOl8GIISXzMhdCZkmyAH+DmW56ejzsd+JWwCMm177DtOZULl7Osq+OGOtpbloj4HCfstpoiG58SM6Nba8WUXWLnbgqZuHPBag/Kqjroot@hserver1
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC29kPkYz4c3bd9Qa1TV8kCR0bUNs4f7/dDcR1NKwrgIiecN7zPEWJpjILtlm3niNNx1j5R49QLTLBKKo8PE8mid47POvNypkVRGDeN2IVCivoAQ1T7S8bTJ4zDECGydFYyKQfS2nOAifAWECdgFFtIp52d+dLIAg1JC37pfER9f32rd7anhTHYKwnLwR/NDVGAw3tMkXOnFuFKUMdOJ3GSoVOZf3QHKykGIC2fz/lsXZHaCcQWvOU/Ecd9e0263Tvqh7zGWpF5WYEGjkLlY8v2sioeZxgzog1LWycUTMTqaO+fSdbvKqVj6W0qdy3Io8bJ29Q3S/6MxLa6xvFcBJEXroot@hserver2
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1a2o10ttv2570GpuUZy7g9o7lIkkeed7ba25VvFEBcUroQIZ+NIAiVIMGPRiOqm7X4bTLWj5EOz5JXG2l8rwA6CFnWfW3U+ttD1COLOrv2tHTiJ1PhQy1jJR/LpC1iX3sNIDDs+I0txZFGTCTRMLmrbHVTl8j5Yy/CTYLuC7reIZjzpHP7aaS2ev0dlbQzeB08ncjA5Jh4X72qQMOGPUUc2C9oa/CeCvI0SJbt8mkHwqFanZz/IfhLJIKhupjtYsqwQMmzLIjHxbLRwUGoWU6X4e76OkUz/xyyHlzBg1Vu2F9hjoXPW80VmupIRSXFDliDBJ8NlXXQN47wwYBG28broot@hserver3
如图:

2.6将authorized_keys文件复制到其他机器
hserver1机器的/root/.ssh/目录下已经有authorized_keys这个文件了,该文件的内容也已经OK了,接下来要将该文件复制到hserver2的/root/.ssh/和hserver3的/root/.ssh/。
复制的方法有很多,最简单的就是用SecureFX可视化工具操作吧。
复制完成后,可以看到三台机器的/root/.ssh目录下都有了这样的文件
如图:
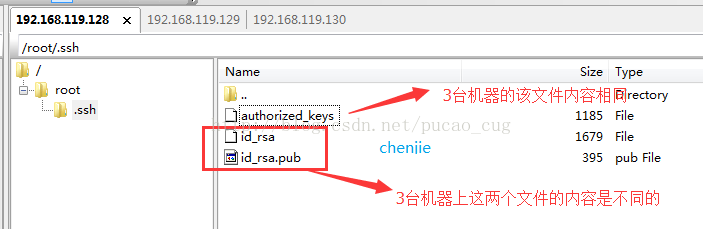
上图已经说得很清楚了,三台机器的/root/.ssh都有同名的文件,但是只有authorized_keys文件的内容是相同的。
2.7测试使用ssh进行无密码登录
2.7.1在hserver1上进行测试
输入命令:
ssh hserver2
如图:

输入命令:
exit回车
如图:

输入命令:
ssh hserver3
如图:

输入命令:
exit回车
如图:

2.7.2 在hserver2上进行测试
方法类似2.7.1,只不过命令变成了ssh hserver1和ssh hserver3,但是一定要注意的是,每次ssh完成后,都要执行exit,否则你的后续命令是在另外一台机器上执行的。
2.7.3 在hserver3上进行测试
方法类似2.7.1,只不过命令变成了ssh hserver1和ssh hserver2,但是一定要注意的是,每次ssh完成后,都要执行exit,否则你的后续命令是在另外一台机器上执行的。
我按照上面方法配置root免密码不成功,后来百度了一下发现还有以下问题需要注意:
我安装博文这个命令执行最后无法root用户免密码登录成功,我改成了ssh-keygen然后多次回车生成
authorized_keys:存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文件
know_hosts : 已知的主机公钥清单
如果希望ssh公钥生效需满足至少下面两个条件:
1) .ssh目录的权限必须是700
2) .ssh/authorized_keys文件权限必须是600
[root@master ~]# chmod 700 /root/.ssh
[root@master ~]# chmod 600 /root/.ssh/*
还需要检查每台机器的~/.ssh/known_hosts文件是否含有四个主机的信息,如下图所示:

如果没有的话,比如master没有,则需要在该机器上重新执行一下ssh master命令,让其生成以上信息即可。

查看/etc/ssh/sshd_config文件[vi /etc/ssh/sshd_config],开启ssh证书登录,即找到注释配置[#PubkeyAuthentication yes],把前面的“#"号去掉,如:
PubkeyAuthentication yes # The default is to check both .ssh/authorized_keys and .ssh/authorized_keys2
# but this is overridden so installations will only check .ssh/authorized_keys
AuthorizedKeysFile .ssh/authorized_keys
3安装jdk和hadoop
说明,为了省去一系列获取管理员权限,授权等繁琐操作,精简教程,这里都是使用root账户登录并且使用root权限进行操作。
3.1 安装JDK
安装jdk在这里不在细数,如果有需要可以参考该博文(虽然那篇博文用的是ubuntu,但是jdk安装在CentOS下也一样):
http://blog.csdn.net/pucao_cug/article/details/68948639
3.2 安装hadoop
注意: 3台机器上都需要重复下面所讲的步骤。
3.2.1 上载文件并解压缩
在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop-2.8.0.tar上载到该目录下,如图:
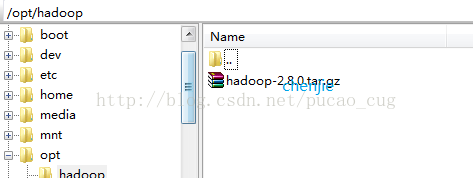
进入到该目录,执行命令:
cd /opt/hadoop
执行解压命令:
tar -xvf hadoop-2.8.3.tar.gz
先在hserver1上把后续的各个配置文件配置好了,然后打包传到hserver2和hserver3的/opt/hadoop/相同目录下就行了
3.2.2新建几个目录
在/root目录下新建几个目录,复制粘贴执行下面的命令:
- mkdir /root/hadoop
- mkdir /root/hadoop/tmp
- mkdir /root/hadoop/var
- mkdir /root/hadoop/dfs
- mkdir /root/hadoop/dfs/name
- mkdir /root/hadoop/dfs/data
3.2.3 修改etc/hadoop中的一系列配置文件
修改/opt/hadoop/hadoop-2.8.3/etc/hadoop目录内的一系列文件。
3.2.3.1 修改core-site.xml
修改/opt/hadoop/hadoop-2.8.3/etc/hadoop/core-site.xml文件
在<configuration>节点内加入配置:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hserver1:9000</value>
</property>
3.2.3.2 修改hadoop-env.sh
修改/opt/hadoop/hadoop-2.8.3/etc/hadoop/hadoop-env.sh文件
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/root/jdk1.8.0_131
说明:修改为自己的JDK路径
3.2.3.3 修改hdfs-site.xml
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xml文件
在<configuration>节点内加入配置:
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>need not permissions</description>
</property>
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
3.2.3.4 新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
- cp /opt/hadoop/hadoop-2.8.3/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.3/etc/hadoop/mapred-site.xml
修改这个新建的mapred-site.xml文件,在<configuration>节点内加入配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hserver1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hserver1:19888</value>
</property>
3.2.3.5 修改slaves文件
修改/opt/hadoop/hadoop-2.8.3/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:
- hserver2
- hserver3
3.2.3.6 修改yarn-site.xml文件
修改/opt/hadoop/hadoop-2.8.3/etc/hadoop/yarn-site.xml文件,
在<configuration>节点内加入配置(注意了,内存根据机器配置越大越好,我这里只配2个G是因为机器不行):
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hserver1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hserver1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hserver1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hserver1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hserver1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hserver1:8088</value>
</property>
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
4启动hadoop
4.1在namenode上执行初始化
hserver1的各个配置文件配置好后,打包scp传给hserver2和hserver3就可以了
检查一下centos7的防火墙是否关闭了
firewall-cmd --state
systemctl stop firewalld.service
systemctl disable firewalld.service
因为hserver1是namenode,hserver2和hserver3都是datanode,所以只需要对hserver1进行初始化操作,也就是对hdfs进行格式化。
进入到hserver1这台机器的/opt/hadoop/hadoop-2.8.3/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.3/bin
执行初始化脚本,也就是执行命令:
./hdfs namenode -format
如图:
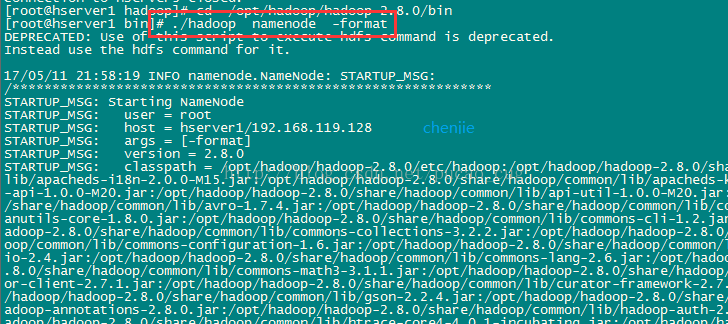
稍等几秒,不报错的话,即可执行成功,如图:
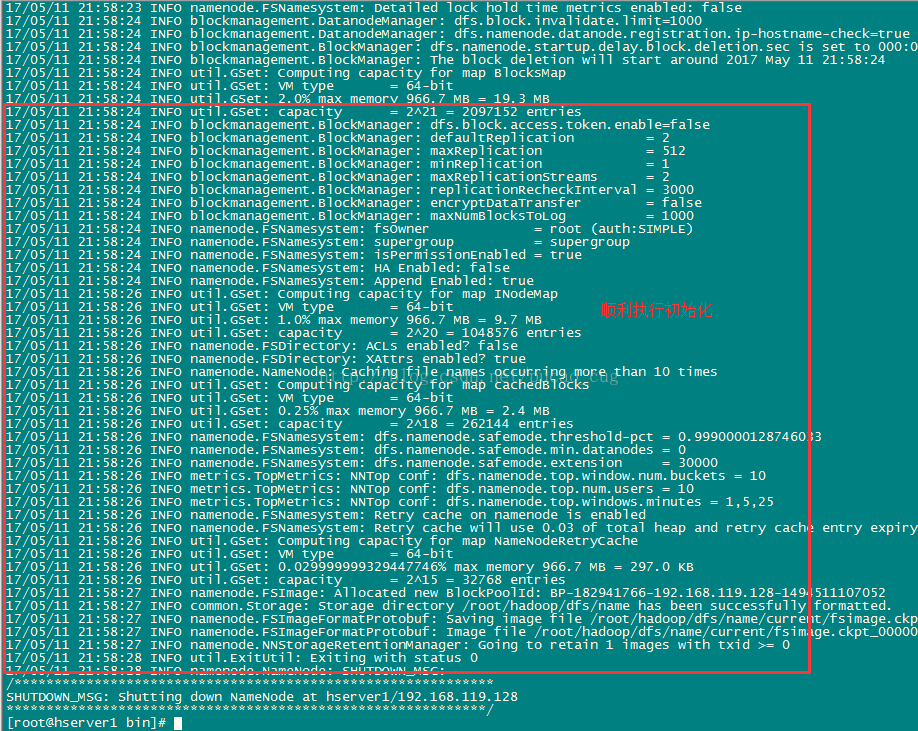
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件
如图:

4.2在namenode上执行启动命令
因为hserver1是namenode,hserver2和hserver3都是datanode,所以只需要再hserver1上执行启动命令即可。
进入到hserver1这台机器的/opt/hadoop/hadoop-2.8.3/sbin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.3/sbin
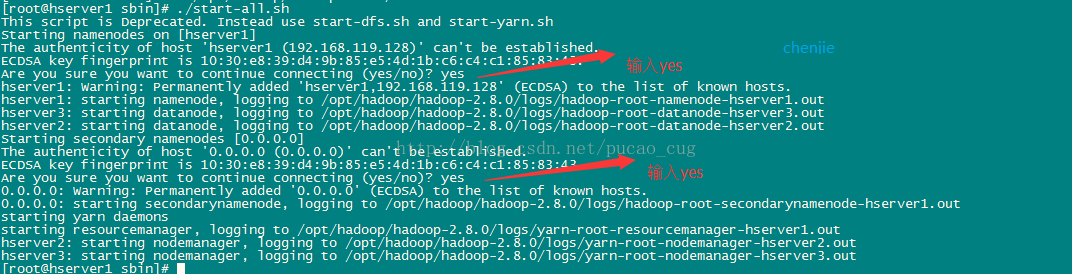
执行初始化脚本,也就是执行命令:
./start-all.sh
第一次执行上面的启动命令,会需要我们进行交互操作,在问答界面上输入yes回车
如图:
5测试hadoop
haddoop启动了,需要测试一下hadoop是否正常。
执行命令,关闭防火墙,CentOS7下,命令是:
systemctl stop firewalld.service
如图:

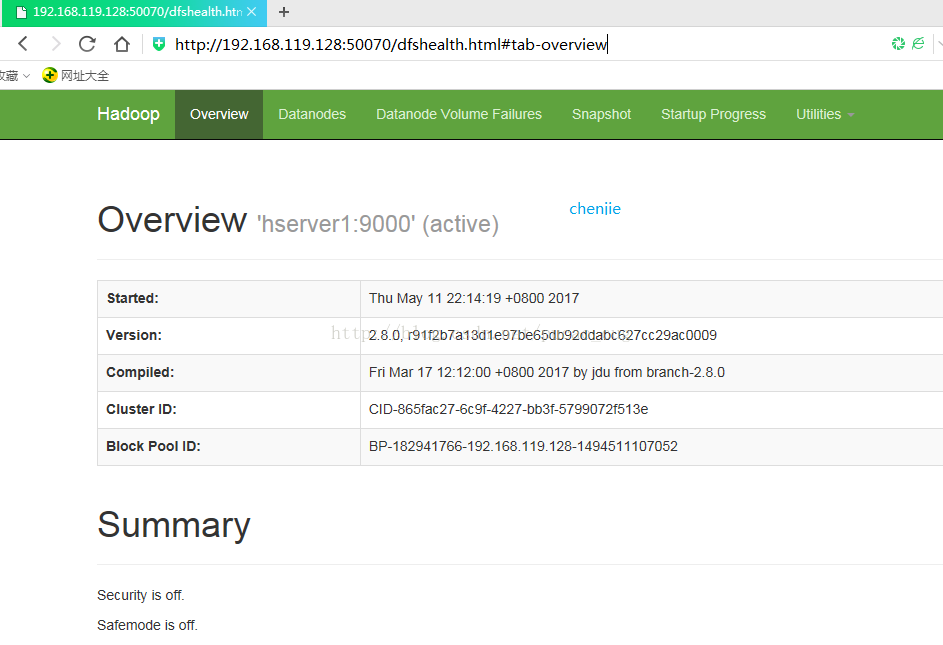
hserver1是我们的namanode,该机器的IP是192.168.0.168,在本地电脑访问如下地址:
自动跳转到了overview页面
如图:
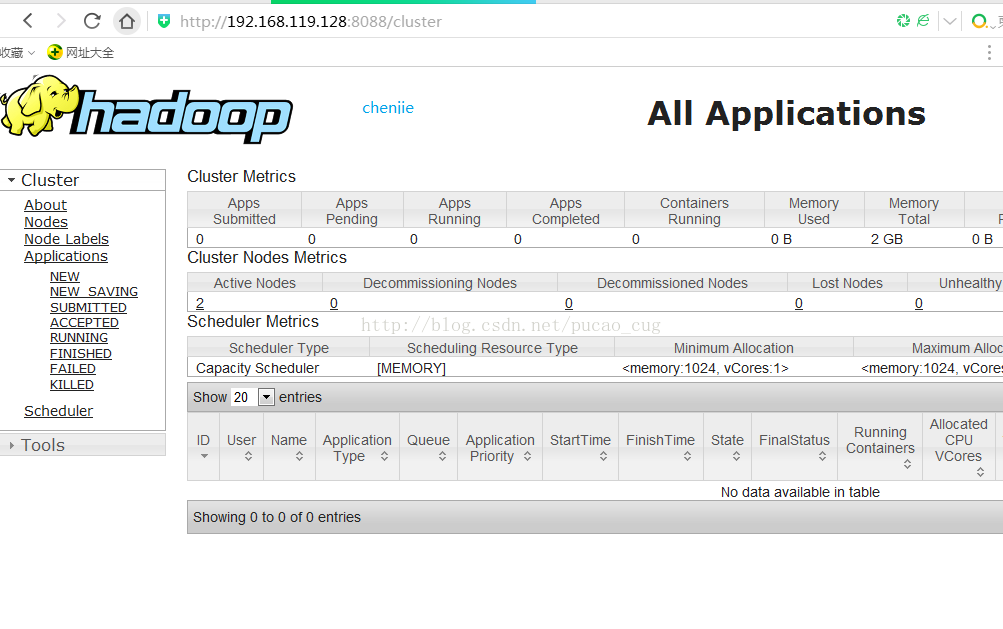
在本地浏览器里访问如下地址:
自动跳转到了cluster页面
如图:
Linux上安装Hadoop集群(CentOS7+hadoop-2.8.3)的更多相关文章
- 在Linux上安装Zookeeper集群
xl_echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.——这才是真正的堪称强大!! - ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)--------hadoop环境的搭建
Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)------https://blog.csdn.net/pucao_cug/article/details/71698903 ...
- 在CentOS上安装ZooKeeper集群
一共准备3个CentOS虚拟机 172.16.9.194 172.16.9.195 172.16.9.196 上传zookeeper-3.3.6.tar.gz到服务器并解压,3台服务器的目录结构如下 ...
- 大数据实操2 - hadoop集群访问——Hadoop客户端访问、Java API访问
上一篇中介绍了hadoop集群搭建方式,本文介绍集群的访问.集群的访问方式有两种:hadoop客户端访问,Java API访问. 一.集群客户端访问 Hadoop采用C/S架构,可以通过客户端对集群进 ...
- Hadoop集群(四) Hadoop升级
Hadoop前面安装的集群是2.6版本,现在升级到2.7版本. 注意,这个集群上有运行Hbase,所以,升级前后,需要启停Hbase. 更多安装步骤,请参考: Hadoop集群(一) Zookeepe ...
- 在windows远程提交任务给Hadoop集群(Hadoop 2.6)
我使用3台Centos虚拟机搭建了一个Hadoop2.6的集群.希望在windows7上面使用IDEA开发mapreduce程序,然后提交的远程的Hadoop集群上执行.经过不懈的google终于搞定 ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
1下载hadoop 2安装3个虚拟机并实现ssh免密码登录 2.1安装3个机器 2.2检查机器名称 2.3修改/etc/hosts文件 2.4 给3个机器生成秘钥文件 2.5 在hserver1上创建 ...
- Centos7上安装Kubernetes集群部署docker
一.安装前准备1.操作系统详情需要三台主机,都最小化安装 centos7.3,并update到最新 [root@master ~]# (Core) 角色 主机名 IPMaster master 192 ...
- CDH搭建Hadoop集群(Centos7)
一.说明 节点(CentOS7.5) Server || Agent CPU node11 Server || Agent 4G node12 Agent 2G node13 Agent 2G 二 ...
随机推荐
- div+css 左右两列自适应高度 ,以及父级div也跟着自适应子级的高度(兼容各大浏览器)
<style type="text/css" media="screen"> <!-- #main {width:500px;_height: ...
- Python基础学习三 文件操作(一)
文件读写 r,只读模式(默认). w,只写模式.[不可读:不存在则创建:存在则删除内容:] a,追加模式.[不可读: 不存在则创建:存在则只追加内容:] r+,[可读.可写:可追加,如果打开的文件不存 ...
- ThinkPHP5如何引用新建的配置文件?
1.在Application文件夹下建立extra 文件夹,并把新建的配置文件(例如字典配置文件dictConfig.php等)放入此文件夹: 2.在代码中使用 Config::get("d ...
- Collection Types
[Collection Types] 1.Arrays store ordered lists of values of the same type. Value必须是同一类型. 2.Array的原型 ...
- 在64位SQL Server中创建Oracle的链接服务器 Link Server
有时候我们希望在一个sqlserver下访问另一个sqlserver数据库上的数据,或者访问其他oracle数据库上的数据,要想完成这些操作,我们首要的是创建数据库链接. 数据库链接能够让本地的一个s ...
- zookeeper更进一步(数据模型、watcher及shell命令)
ZooKeeper数据模型 ZooKeeper 的数据模型,在结构上和标准文件系统的非常相似,拥有一个层次的命名空间,都是采用树形层次结构,ZooKeeper 树中的每个节点被称为—Znode.和文件 ...
- CF1073F Choosing Two Paths
发现从顶点入手不太方便,我们从这个“公共部分最长”开始考虑问题,因为要求这一条公共部分的链最长,可以联想到树的直径,那么本题就是要求一条类似于直径的东西使两个端点除了直径这一条链之外还有不少于两个的儿 ...
- swing中的分层
swing中的分层 摘自:https://blog.csdn.net/levelmini/article/details/26692205 2014年05月23日 12:42:56 阅读数:1244 ...
- [redis]redis-cluster的使用
1.为集群添加一个主节点 首先准备一个全新的redis文件夹,这里我们叫做为7007 [root@CentOS7 redis-cluster]# ls [root@CentOS7 redis-clus ...
- (转)通过Javascript得到URL中的参数(query string)
原文地址:http://www.cnblogs.com/season-huang/p/3322561.html 我们知道,"GET"请求中,通常把参数放在URL后面,比如这样htt ...