Deep Learning 学习笔记(5):Regularization 规则化
过拟合(overfitting):
实际操作过程中,无论是线性回归还是逻辑回归,其假设函数h(x)都是人为设定的(尽管可以通过实验选择最优)。
这样子就可能出线“欠拟合”或者“过拟合”现象。
所谓过拟合,就是模型复杂度过高,模型很好地拟合了训练样本却对未知样本的预测能力不足。(亦称"泛化"能力不足)
所谓欠拟合,就是模型复杂度过低,模型不能很好拟合不管是训练样本还是其他样本。
例子:
如果输出与输入大致成二次关系,
那么我们用一次函数去拟合,拟合结果过于平缓,跟不上变化,这就是“欠拟合”
用3、4次函数去拟合,则会出现过多的“抖动”,这就是“过拟合”
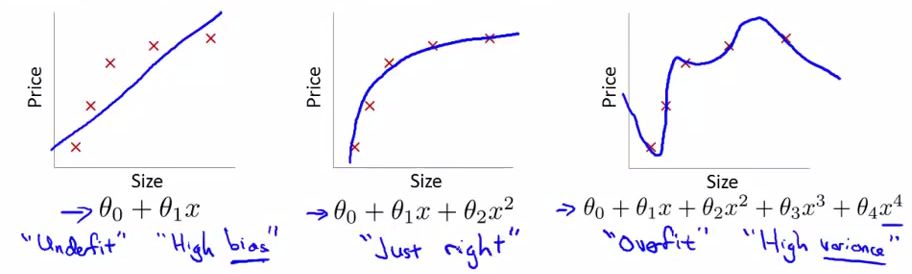
如图,
线性回归中的“欠拟合”和“过拟合”,可见"欠拟合"不能贴近数据的变化,而"过拟合"产生了过多的"抖动"
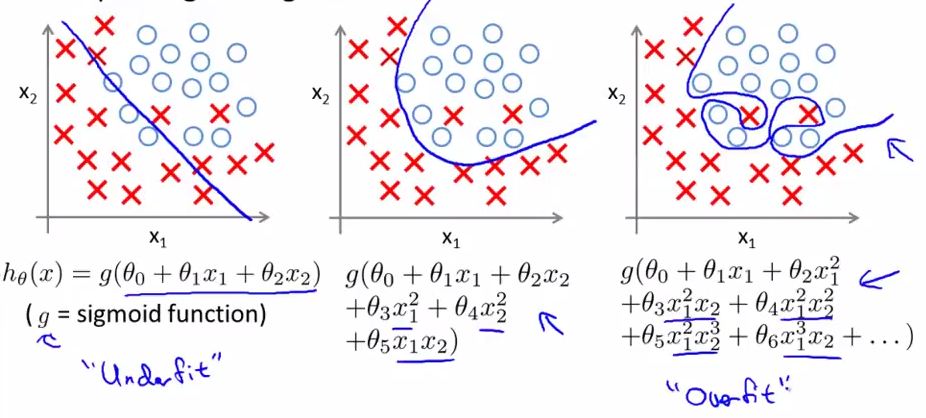
逻辑回归中的“欠拟合”和“过拟合”,“欠拟合”不能很好的进行分类,“过拟合”则过多地受到特例的影响,不能给出具有良好泛化能力的方程
实际操作当中,由于过拟合的影响可以通过增大训练数据量来减轻,和正则化
所以一般建模宁over不under。
Regularization(正则化):
正则化希望在代价函数中增加惩罚项来减少过拟合项的系数的大小,以减少过拟合项的影响。
惩罚因子 :
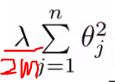 (好难看……)
(好难看……)
修改后的代价函数:
线性:
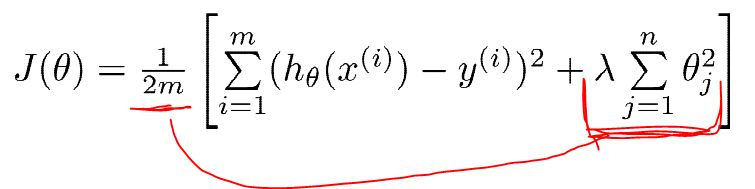
逻辑:
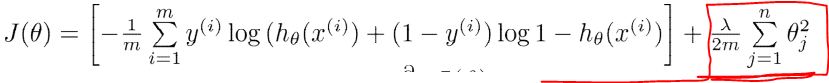
*用本专业的知识可以这么理解:对于一个模型,我们希望尽量用低次函数拟合得到良好效果,尽量少用高次函数(高频抖动囧rz)。
如果一个模型欠拟合,其前面的cost会过高;如果一个函数过拟合,高次函数系数较大,后面的正则惩罚项的cost又会过高。
所以学习过程会自动平衡模型的复杂程度,得到一个对训练样本和未知样本都能良好拟合的模型。(当然得调参)
然后用修改后的代价方程进行梯度下降的计算即可(加多了一项,偏导很容易算吧)
注意:常数项的系数我们并不进行“惩罚”,所以常数项的偏导与其他项的偏导计算有些许不同。
Deep Learning 学习笔记(5):Regularization 规则化的更多相关文章
- 【deep learning学习笔记】注释yusugomori的DA代码 --- dA.h
DA就是“Denoising Autoencoders”的缩写.继续给yusugomori做注释,边注释边学习.看了一些DA的材料,基本上都在前面“转载”了.学习中间总有个疑问:DA和RBM到底啥区别 ...
- [置顶]
Deep Learning 学习笔记
一.文章来由 好久没写原创博客了,一直处于学习新知识的阶段.来新加坡也有一个星期,搞定签证.入学等杂事之后,今天上午与导师确定了接下来的研究任务,我平时基本也是把博客当作联机版的云笔记~~如果有写的不 ...
- Deep Learning 学习笔记(8):自编码器( Autoencoders )
之前的笔记,算不上是 Deep Learning, 只是为理解Deep Learning 而需要学习的基础知识, 从下面开始,我会把我学习UFDL的笔记写出来 #主要是给自己用的,所以其他人不一定看得 ...
- 【deep learning学习笔记】Recommending music on Spotify with deep learning
主要内容: Spotify是个类似酷我音乐的音乐站点.做个性化音乐推荐和音乐消费.作者利用deep learning结合协同过滤来做音乐推荐. 详细内容: 1. 协同过滤 基本原理:某两个用户听的歌曲 ...
- 【deep learning学习笔记】注释yusugomori的RBM代码 --- 头文件
百度了半天yusugomori,也不知道他是谁.不过这位老兄写了deep learning的代码,包括RBM.逻辑回归.DBN.autoencoder等,实现语言包括c.c++.java.python ...
- Neural Networks and Deep Learning学习笔记ch1 - 神经网络
近期開始看一些深度学习的资料.想学习一下深度学习的基础知识.找到了一个比較好的tutorial,Neural Networks and Deep Learning,认真看完了之后觉得收获还是非常多的. ...
- paper 149:Deep Learning 学习笔记(一)
1. 直接上手篇 台湾李宏毅教授写的,<1天搞懂深度学习> slideshare的链接: http://www.slideshare.net/tw_dsconf/ss-62245351? ...
- Deep Learning 学习笔记——第9章
总览: 本章所讲的知识点包括>>>> 1.描述卷积操作 2.解释使用卷积的原因 3.描述pooling操作 4.卷积在实践应用中的变化形式 5.卷积如何适应输入数据 6.CNN ...
- 【Deep Learning学习笔记】Dynamic Auto-Encoders for Semantic Indexing_Mirowski_NIPS2010
发表于NIPS2010 workshop on deep learning的一篇文章,看得半懂. 主要内容: 是针对文本表示的一种方法.文本表示可以进一步应用在文本分类和信息检索上面.通常,一篇文章表 ...
- 【deep learning学习笔记】最近读的几个ppt(四)
这几个ppt都是在微博上看到的,是百度的一个员工整理的. <Deep Belief Nets>,31页的一个ppt 1. 相关背景 还是在说deep learning好啦,如特征表示云云. ...
随机推荐
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- Makefile的补充学习2
Makefile中使用通配符(1)* 若干个任意字符(2)? 1个任意字符(3)[] 将[]中的字符依次去和外面的结合匹配 还有个%,也是通配符,表示任意多个字符,和*很相似,但是%一般只用于规则描述 ...
- IE中iframe兼容性问题
在使用iframe的时候,有时候想要让调用的iframe框架里面的不显示白背景,让它变得透明,在firefox是透明的,但是在IE浏览器却不透明. 这个其实比较容易解决,只需要增加一个属性即可. 就是 ...
- 2 秒杀系统模拟基础实现,使用Redis实现
这一篇,我们来使用redis进行数据存储. 新建一个redis的service实现类 package com.tianyalei.service; import com.tianyalei.model ...
- CodeForces - 662A:Gambling Nim (求有多少个子集其异或为S)(占位)
As you know, the game of "Nim" is played with n piles of stones, where the i-th pile initi ...
- eclipse导出文件上传服务器
[1]导出 选择项目 文件导出 输入导出路径如f盘ftp文件夹下 [2]利用scr上传服务器工具 上传到 home/tomcat/app/项目名称/ 不导入upload文件 [待完善]
- DataTable / DataSet 与 xml 的相互转换
之前做DataTable和DataSet转xml一直使用XmlSerializer 序列化完成.今天发现新方法,哇咔咔方便了很多.还不用担心Name为空时报错 static void Main(str ...
- LeetCode Split Concatenated Strings
原题链接在这里:https://leetcode.com/problems/split-concatenated-strings/description/ 题目: Given a list of st ...
- PHP数组排序和按数量分割
用PHP自带array_multisort函数排序 <?php $data = array(); $data[] = array('volume' => 67, 'editi ...
- 51nod 1362 搬箱子——[ 推式子+组合数计算方法 ] [ 拉格朗日插值 ]
题目:http://www.51nod.com/Challenge/Problem.html#!#problemId=1362 方法一: 设 a 是向下走的步数. b 是向右下走的步数. c 是向下走 ...